This work investigates the use of interactively updated label suggestions to improve upon the efficiency of gathering annotations on the task of opinion mining in German Covid-19 social media data. We develop guidelines to conduct a controlled annotation study with social science students and find that suggestions from a model trained on a small, expert-annotated dataset already lead to a substantial improvement – in terms of inter-annotator agreement (+.14 Fleiss’ κ) and annotation quality – compared to students that do not receive any label suggestions. We further find that label suggestions from interactively trained models do not lead to an improvement over suggestions from a static model. Nonetheless, our analysis of suggestion bias shows that annotators remain capable of reflecting upon the suggested label in general. Finally, we confirm the quality of the annotated data in transfer learning experiments between different annotator groups. To facilitate further research in opinion mining on social media data, we release our collected data consisting of 200 expert and 2,785 student annotations.
Humor is an important social phenomenon, serving complex social and psychological functions. However, despite being studied for millennia humor is computationally not well understood, often considered an AI-complete problem. In this work, we introduce a novel setting in humor mining: automatically detecting funny and unusual scientific papers. We are inspired by the Ig Nobel prize, a satirical prize awarded annually to celebrate funny scientific achievements (example past winner: “Are cows more likely to lie down the longer they stand?”). This challenging task has unique characteristics that make it particularly suitable for automatic learning. We construct a dataset containing thousands of funny papers and use it to learn classifiers, combining findings from psychology and linguistics with recent advances in NLP. We use our models to identify potentially funny papers in a large dataset of over 630,000 articles. The results demonstrate the potential of our methods, and more broadly the utility of integrating state-of-the-art NLP methods with insights from more traditional disciplines
This paper presents a novel task to generate poll questions for social media posts. It offers an easy way to hear the voice from the public and learn from their feelings to important social topics. While most related work tackles formal languages (e.g., exam papers), we generate poll questions for short and colloquial social media messages exhibiting severe data sparsity. To deal with that, we propose to encode user comments and discover latent topics therein as contexts. They are then incorporated into a sequence-to-sequence (S2S) architecture for question generation and its extension with dual decoders to additionally yield poll choices (answers). For experiments, we collect a large-scale Chinese dataset from Sina Weibo containing over 20K polls. The results show that our model outperforms the popular S2S models without exploiting topics from comments and the dual decoder design can further benefit the prediction of both questions and answers. Human evaluations further exhibit our superiority in yielding high-quality polls helpful to draw user engagements.
Detecting online hate is a difficult task that even state-of-the-art models struggle with. Typically, hate speech detection models are evaluated by measuring their performance on held-out test data using metrics such as accuracy and F1 score. However, this approach makes it difficult to identify specific model weak points. It also risks overestimating generalisable model performance due to increasingly well-evidenced systematic gaps and biases in hate speech datasets. To enable more targeted diagnostic insights, we introduce HateCheck, a suite of functional tests for hate speech detection models. We specify 29 model functionalities motivated by a review of previous research and a series of interviews with civil society stakeholders. We craft test cases for each functionality and validate their quality through a structured annotation process. To illustrate HateCheck’s utility, we test near-state-of-the-art transformer models as well as two popular commercial models, revealing critical model weaknesses.
Recent studies constructing direct interactions between the claim and each single user response (a comment or a relevant article) to capture evidence have shown remarkable success in interpretable claim verification. Owing to different single responses convey different cognition of individual users (i.e., audiences), the captured evidence belongs to the perspective of individual cognition. However, individuals’ cognition of social things is not always able to truly reflect the objective. There may be one-sided or biased semantics in their opinions on a claim. The captured evidence correspondingly contains some unobjective and biased evidence fragments, deteriorating task performance. In this paper, we propose a Dual-view model based on the views of Collective and Individual Cognition (CICD) for interpretable claim verification. From the view of the collective cognition, we not only capture the word-level semantics based on individual users, but also focus on sentence-level semantics (i.e., the overall responses) among all users and adjust the proportion between them to generate global evidence. From the view of individual cognition, we select the top-k articles with high degree of difference and interact with the claim to explore the local key evidence fragments. To weaken the bias of individual cognition-view evidence, we devise inconsistent loss to suppress the divergence between global and local evidence for strengthening the consistent shared evidence between the both. Experiments on three benchmark datasets confirm that CICD achieves state-of-the-art performance.
Rap generation, which aims to produce lyrics and corresponding singing beats, needs to model both rhymes and rhythms. Previous works for rap generation focused on rhyming lyrics, but ignored rhythmic beats, which are important for rap performance. In this paper, we develop DeepRapper, a Transformer-based rap generation system that can model both rhymes and rhythms. Since there is no available rap datasets with rhythmic beats, we develop a data mining pipeline to collect a large-scale rap dataset, which includes a large number of rap songs with aligned lyrics and rhythmic beats. Second, we design a Transformer-based autoregressive language model which carefully models rhymes and rhythms. Specifically, we generate lyrics in the reverse order with rhyme representation and constraint for rhyme enhancement, and insert a beat symbol into lyrics for rhythm/beat modeling. To our knowledge, DeepRapper is the first system to generate rap with both rhymes and rhythms. Both objective and subjective evaluations demonstrate that DeepRapper generates creative and high-quality raps with rhymes and rhythms.
In this paper, we formulate the personalized news headline generation problem whose goal is to output a user-specific title based on both a user’s reading interests and a candidate news body to be exposed to her. To build up a benchmark for this problem, we publicize a large-scale dataset named PENS (PErsonalized News headlineS). The training set is collected from user impressions logs of Microsoft News, and the test set is manually created by hundreds of native speakers to enable a fair testbed for evaluating models in an offline mode. We propose a generic framework as a preparatory solution to our problem. At its heart, user preference is learned by leveraging the user behavioral data, and three kinds of user preference injections are proposed to personalize a text generator and establish personalized headlines. We investigate our dataset by implementing several state-of-the-art user modeling methods in our framework to demonstrate a benchmark score for the proposed dataset. The dataset is available at https://msnews.github.io/pens.html.
Text style transfer aims to alter the style (e.g., sentiment) of a sentence while preserving its content. A common approach is to map a given sentence to content representation that is free of style, and the content representation is fed to a decoder with a target style. Previous methods in filtering style completely remove tokens with style at the token level, which incurs the loss of content information. In this paper, we propose to enhance content preservation by implicitly removing the style information of each token with reverse attention, and thereby retain the content. Furthermore, we fuse content information when building the target style representation, making it dynamic with respect to the content. Our method creates not only style-independent content representation, but also content-dependent style representation in transferring style. Empirical results show that our method outperforms the state-of-the-art baselines by a large margin in terms of content preservation. In addition, it is also competitive in terms of style transfer accuracy and fluency.
This paper focuses on Seq2Seq (S2S) constrained text generation where the text generator is constrained to mention specific words which are inputs to the encoder in the generated outputs. Pre-trained S2S models or a Copy Mechanism are trained to copy the surface tokens from encoders to decoders, but they cannot guarantee constraint satisfaction. Constrained decoding algorithms always produce hypotheses satisfying all constraints. However, they are computationally expensive and can lower the generated text quality. In this paper, we propose Mention Flags (MF), which traces whether lexical constraints are satisfied in the generated outputs in an S2S decoder. The MF models can be trained to generate tokens in a hypothesis until all constraints are satisfied, guaranteeing high constraint satisfaction. Our experiments on the Common Sense Generation task (CommonGen) (Lin et al., 2020), End2end Restaurant Dialog task (E2ENLG) (Duˇsek et al., 2020) and Novel Object Captioning task (nocaps) (Agrawal et al., 2019) show that the MF models maintain higher constraint satisfaction and text quality than the baseline models and other constrained decoding algorithms, achieving state-of-the-art performance on all three tasks. These results are achieved with a much lower run-time than constrained decoding algorithms. We also show that the MF models work well in the low-resource setting.
Concept-to-text Natural Language Generation is the task of expressing an input meaning representation in natural language. Previous approaches in this task have been able to generalise to rare or unseen instances by relying on a delexicalisation of the input. However, this often requires that the input appears verbatim in the output text. This poses challenges in multilingual settings, where the task expands to generate the output text in multiple languages given the same input. In this paper, we explore the application of multilingual models in concept-to-text and propose Language Agnostic Delexicalisation, a novel delexicalisation method that uses multilingual pretrained embeddings, and employs a character-level post-editing model to inflect words in their correct form during relexicalisation. Our experiments across five datasets and five languages show that multilingual models outperform monolingual models in concept-to-text and that our framework outperforms previous approaches, especially in low resource conditions.
Nowadays, open-domain dialogue models can generate acceptable responses according to the historical context based on the large-scale pre-trained language models. However, they generally concatenate the dialogue history directly as the model input to predict the response, which we named as the flat pattern and ignores the dynamic information flow across dialogue utterances. In this work, we propose the DialoFlow model, in which we introduce a dynamic flow mechanism to model the context flow, and design three training objectives to capture the information dynamics across dialogue utterances by addressing the semantic influence brought about by each utterance in large-scale pre-training. Experiments on the multi-reference Reddit Dataset and DailyDialog Dataset demonstrate that our DialoFlow significantly outperforms the DialoGPT on the dialogue generation task. Besides, we propose the Flow score, an effective automatic metric for evaluating interactive human-bot conversation quality based on the pre-trained DialoFlow, which presents high chatbot-level correlation (r=0.9) with human ratings among 11 chatbots. Code and pre-trained models will be public.
The goal of dialogue state tracking (DST) is to predict the current dialogue state given all previous dialogue contexts. Existing approaches generally predict the dialogue state at every turn from scratch. However, the overwhelming majority of the slots in each turn should simply inherit the slot values from the previous turn. Therefore, the mechanism of treating slots equally in each turn not only is inefficient but also may lead to additional errors because of the redundant slot value generation. To address this problem, we devise the two-stage DSS-DST which consists of the Dual Slot Selector based on the current turn dialogue, and the Slot Value Generator based on the dialogue history. The Dual Slot Selector determines each slot whether to update slot value or to inherit the slot value from the previous turn from two aspects: (1) if there is a strong relationship between it and the current turn dialogue utterances; (2) if a slot value with high reliability can be obtained for it through the current turn dialogue. The slots selected to be updated are permitted to enter the Slot Value Generator to update values by a hybrid method, while the other slots directly inherit the values from the previous turn. Empirical results show that our method achieves 56.93%, 60.73%, and 58.04% joint accuracy on MultiWOZ 2.0, MultiWOZ 2.1, and MultiWOZ 2.2 datasets respectively and achieves a new state-of-the-art performance with significant improvements.
One of the difficulties in training dialogue systems is the lack of training data. We explore the possibility of creating dialogue data through the interaction between a dialogue system and a user simulator. Our goal is to develop a modelling framework that can incorporate new dialogue scenarios through self-play between the two agents. In this framework, we first pre-train the two agents on a collection of source domain dialogues, which equips the agents to converse with each other via natural language. With further fine-tuning on a small amount of target domain data, the agents continue to interact with the aim of improving their behaviors using reinforcement learning with structured reward functions. In experiments on the MultiWOZ dataset, two practical transfer learning problems are investigated: 1) domain adaptation and 2) single-to-multiple domain transfer. We demonstrate that the proposed framework is highly effective in bootstrapping the performance of the two agents in transfer learning. We also show that our method leads to improvements in dialogue system performance on complete datasets.
Maintaining a consistent persona is essential for dialogue agents. Although tremendous advancements have been brought, the limited-scale of annotated personalized dialogue datasets is still a barrier towards training robust and consistent persona-based dialogue models. This work shows how this challenge can be addressed by disentangling persona-based dialogue generation into two sub-tasks with a novel BERT-over-BERT (BoB) model. Specifically, the model consists of a BERT-based encoder and two BERT-based decoders, where one decoder is for response generation, and another is for consistency understanding. In particular, to learn the ability of consistency understanding from large-scale non-dialogue inference data, we train the second decoder in an unlikelihood manner. Under different limited data settings, both automatic and human evaluations demonstrate that the proposed model outperforms strong baselines in response quality and persona consistency.
Multi-intent SLU can handle multiple intents in an utterance, which has attracted increasing attention. However, the state-of-the-art joint models heavily rely on autoregressive approaches, resulting in two issues: slow inference speed and information leakage. In this paper, we explore a non-autoregressive model for joint multiple intent detection and slot filling, achieving more fast and accurate. Specifically, we propose a Global-Locally Graph Interaction Network (GL-GIN) where a local slot-aware graph interaction layer is proposed to model slot dependency for alleviating uncoordinated slots problem while a global intent-slot graph interaction layer is introduced to model the interaction between multiple intents and all slots in the utterance. Experimental results on two public datasets show that our framework achieves state-of-the-art performance while being 11.5 times faster.
Both performance and efficiency are crucial factors for sequence labeling tasks in many real-world scenarios. Although the pre-trained models (PTMs) have significantly improved the performance of various sequence labeling tasks, their computational cost is expensive. To alleviate this problem, we extend the recent successful early-exit mechanism to accelerate the inference of PTMs for sequence labeling tasks. However, existing early-exit mechanisms are specifically designed for sequence-level tasks, rather than sequence labeling. In this paper, we first propose a simple extension of sentence-level early-exit for sequence labeling tasks. To further reduce the computational cost, we also propose a token-level early-exit mechanism that allows partial tokens to exit early at different layers. Considering the local dependency inherent in sequence labeling, we employed a window-based criterion to decide for a token whether or not to exit. The token-level early-exit brings the gap between training and inference, so we introduce an extra self-sampling fine-tuning stage to alleviate it. The extensive experiments on three popular sequence labeling tasks show that our approach can save up to 66%∼75% inference cost with minimal performance degradation. Compared with competitive compressed models such as DistilBERT, our approach can achieve better performance under the same speed-up ratios of 2×, 3×, and 4×.
Although the existing Named Entity Recognition (NER) models have achieved promising performance, they suffer from certain drawbacks. The sequence labeling-based NER models do not perform well in recognizing long entities as they focus only on word-level information, while the segment-based NER models which focus on processing segment instead of single word are unable to capture the word-level dependencies within the segment. Moreover, as boundary detection and type prediction may cooperate with each other for the NER task, it is also important for the two sub-tasks to mutually reinforce each other by sharing their information. In this paper, we propose a novel Modularized Interaction Network (MIN) model which utilizes both segment-level information and word-level dependencies, and incorporates an interaction mechanism to support information sharing between boundary detection and type prediction to enhance the performance for the NER task. We have conducted extensive experiments based on three NER benchmark datasets. The performance results have shown that the proposed MIN model has outperformed the current state-of-the-art models.
Capturing interactions among event arguments is an essential step towards robust event argument extraction (EAE). However, existing efforts in this direction suffer from two limitations: 1) The argument role type information of contextual entities is mainly utilized as training signals, ignoring the potential merits of directly adopting it as semantically rich input features; 2) The argument-level sequential semantics, which implies the overall distribution pattern of argument roles over an event mention, is not well characterized. To tackle the above two bottlenecks, we formalize EAE as a Seq2Seq-like learning problem for the first time, where a sentence with a specific event trigger is mapped to a sequence of event argument roles. A neural architecture with a novel Bi-directional Entity-level Recurrent Decoder (BERD) is proposed to generate argument roles by incorporating contextual entities’ argument role predictions, like a word-by-word text generation process, thereby distinguishing implicit argument distribution patterns within an event more accurately.
Many joint entity relation extraction models setup two separated label spaces for the two sub-tasks (i.e., entity detection and relation classification). We argue that this setting may hinder the information interaction between entities and relations. In this work, we propose to eliminate the different treatment on the two sub-tasks’ label spaces. The input of our model is a table containing all word pairs from a sentence. Entities and relations are represented by squares and rectangles in the table. We apply a unified classifier to predict each cell’s label, which unifies the learning of two sub-tasks. For testing, an effective (yet fast) approximate decoder is proposed for finding squares and rectangles from tables. Experiments on three benchmarks (ACE04, ACE05, SciERC) show that, using only half the number of parameters, our model achieves competitive accuracy with the best extractor, and is faster.
Continual learning has gained increasing attention in recent years, thanks to its biological interpretation and efficiency in many real-world applications. As a typical task of continual learning, continual relation extraction (CRE) aims to extract relations between entities from texts, where the samples of different relations are delivered into the model continuously. Some previous works have proved that storing typical samples of old relations in memory can help the model keep a stable understanding of old relations and avoid forgetting them. However, most methods heavily depend on the memory size in that they simply replay these memorized samples in subsequent tasks. To fully utilize memorized samples, in this paper, we employ relation prototype to extract useful information of each relation. Specifically, the prototype embedding for a specific relation is computed based on memorized samples of this relation, which is collected by K-means algorithm. The prototypes of all observed relations at current learning stage are used to re-initialize a memory network to refine subsequent sample embeddings, which ensures the model’s stable understanding on all observed relations when learning a new task. Compared with previous CRE models, our model utilizes the memory information sufficiently and efficiently, resulting in enhanced CRE performance. Our experiments show that the proposed model outperforms the state-of-the-art CRE models and has great advantage in avoiding catastrophic forgetting. The code and datasets are released on https://github.com/fd2014cl/RP-CRE.
Existing multilingual machine translation approaches mainly focus on English-centric directions, while the non-English directions still lag behind. In this work, we aim to build a many-to-many translation system with an emphasis on the quality of non-English language directions. Our intuition is based on the hypothesis that a universal cross-language representation leads to better multilingual translation performance. To this end, we propose mRASP2, a training method to obtain a single unified multilingual translation model. mRASP2 is empowered by two techniques: a) a contrastive learning scheme to close the gap among representations of different languages, and b) data augmentation on both multiple parallel and monolingual data to further align token representations. For English-centric directions, mRASP2 achieves competitive or even better performance than a strong pre-trained model mBART on tens of WMT benchmarks. For non-English directions, mRASP2 achieves an improvement of average 10+ BLEU compared with the multilingual baseline
Neural Machine Translation (NMT) currently exhibits biases such as producing translations that are too short and overgenerating frequent words, and shows poor robustness to copy noise in training data or domain shift. Recent work has tied these shortcomings to beam search – the de facto standard inference algorithm in NMT – and Eikema & Aziz (2020) propose to use Minimum Bayes Risk (MBR) decoding on unbiased samples instead. In this paper, we empirically investigate the properties of MBR decoding on a number of previously reported biases and failure cases of beam search. We find that MBR still exhibits a length and token frequency bias, owing to the MT metrics used as utility functions, but that MBR also increases robustness against copy noise in the training data and domain shift.
One of the reasons Transformer translation models are popular is that self-attention networks for context modelling can be easily parallelized at sequence level. However, the computational complexity of a self-attention network is O(n2), increasing quadratically with sequence length. By contrast, the complexity of LSTM-based approaches is only O(n). In practice, however, LSTMs are much slower to train than self-attention networks as they cannot be parallelized at sequence level: to model context, the current LSTM state relies on the full LSTM computation of the preceding state. This has to be computed n times for a sequence of length n. The linear transformations involved in the LSTM gate and state computations are the major cost factors in this. To enable sequence-level parallelization of LSTMs, we approximate full LSTM context modelling by computing hidden states and gates with the current input and a simple bag-of-words representation of the preceding tokens context. This allows us to compute each input step efficiently in parallel, avoiding the formerly costly sequential linear transformations. We then connect the outputs of each parallel step with computationally cheap element-wise computations. We call this the Highly Parallelized LSTM. To further constrain the number of LSTM parameters, we compute several small HPLSTMs in parallel like multi-head attention in the Transformer. The experiments show that our MHPLSTM decoder achieves significant BLEU improvements, while being even slightly faster than the self-attention network in training, and much faster than the standard LSTM.
Word alignment and machine translation are two closely related tasks. Neural translation models, such as RNN-based and Transformer models, employ a target-to-source attention mechanism which can provide rough word alignments, but with a rather low accuracy. High-quality word alignment can help neural machine translation in many different ways, such as missing word detection, annotation transfer and lexicon injection. Existing methods for learning word alignment include statistical word aligners (e.g. GIZA++) and recently neural word alignment models. This paper presents a bidirectional Transformer based alignment (BTBA) model for unsupervised learning of the word alignment task. Our BTBA model predicts the current target word by attending the source context and both left-side and right-side target context to produce accurate target-to-source attention (alignment). We further fine-tune the target-to-source attention in the BTBA model to obtain better alignments using a full context based optimization method and self-supervised training. We test our method on three word alignment tasks and show that our method outperforms both previous neural word alignment approaches and the popular statistical word aligner GIZA++.
Multilingual neural machine translation aims at learning a single translation model for multiple languages. These jointly trained models often suffer from performance degradationon rich-resource language pairs. We attribute this degeneration to parameter interference. In this paper, we propose LaSS to jointly train a single unified multilingual MT model. LaSS learns Language Specific Sub-network (LaSS) for each language pair to counter parameter interference. Comprehensive experiments on IWSLT and WMT datasets with various Transformer architectures show that LaSS obtains gains on 36 language pairs by up to 1.2 BLEU. Besides, LaSS shows its strong generalization performance at easy adaptation to new language pairs and zero-shot translation. LaSS boosts zero-shot translation with an average of 8.3 BLEU on 30 language pairs. Codes and trained models are available at https://github.com/NLP-Playground/LaSS.
While state-of-the-art NLP models have been achieving the excellent performance of a wide range of tasks in recent years, important questions are being raised about their robustness and their underlying sensitivity to systematic biases that may exist in their training and test data. Such issues come to be manifest in performance problems when faced with out-of-distribution data in the field. One recent solution has been to use counterfactually augmented datasets in order to reduce any reliance on spurious patterns that may exist in the original data. Producing high-quality augmented data can be costly and time-consuming as it usually needs to involve human feedback and crowdsourcing efforts. In this work, we propose an alternative by describing and evaluating an approach to automatically generating counterfactual data for the purpose of data augmentation and explanation. A comprehensive evaluation on several different datasets and using a variety of state-of-the-art benchmarks demonstrate how our approach can achieve significant improvements in model performance when compared to models training on the original data and even when compared to models trained with the benefit of human-generated augmented data.
As a fine-grained task, the annotation cost of aspect term extraction is extremely high. Recent attempts alleviate this issue using domain adaptation that transfers common knowledge across domains. Since most aspect terms are domain-specific, they cannot be transferred directly. Existing methods solve this problem by associating aspect terms with pivot words (we call this passive domain adaptation because the transfer of aspect terms relies on the links to pivots). However, all these methods need either manually labeled pivot words or expensive computing resources to build associations. In this paper, we propose a novel active domain adaptation method. Our goal is to transfer aspect terms by actively supplementing transferable knowledge. To this end, we construct syntactic bridges by recognizing syntactic roles as pivots instead of as links to pivots. We also build semantic bridges by retrieving transferable semantic prototypes. Extensive experiments show that our method significantly outperforms previous approaches.
With the popularity of smartphones, we have witnessed the rapid proliferation of multimodal posts on various social media platforms. We observe that the multimodal sentiment expression has specific global characteristics, such as the interdependencies of objects or scenes within the image. However, most previous studies only considered the representation of a single image-text post and failed to capture the global co-occurrence characteristics of the dataset. In this paper, we propose Multi-channel Graph Neural Networks with Sentiment-awareness (MGNNS) for image-text sentiment detection. Specifically, we first encode different modalities to capture hidden representations. Then, we introduce multi-channel graph neural networks to learn multimodal representations based on the global characteristics of the dataset. Finally, we implement multimodal in-depth fusion with the multi-head attention mechanism to predict the sentiment of image-text pairs. Extensive experiments conducted on three publicly available datasets demonstrate the effectiveness of our approach for multimodal sentiment detection.
Product reviews contain a large number of implicit aspects and implicit opinions. However, most of the existing studies in aspect-based sentiment analysis ignored this problem. In this work, we introduce a new task, named Aspect-Category-Opinion-Sentiment (ACOS) Quadruple Extraction, with the goal to extract all aspect-category-opinion-sentiment quadruples in a review sentence and provide full support for aspect-based sentiment analysis with implicit aspects and opinions. We furthermore construct two new datasets, Restaurant-ACOS and Laptop-ACOS, for this new task, both of which contain the annotations of not only aspect-category-opinion-sentiment quadruples but also implicit aspects and opinions. The former is an extension of the SemEval Restaurant dataset; the latter is a newly collected and annotated Laptop dataset, twice the size of the SemEval Laptop dataset. We finally benchmark the task with four baseline systems. Experiments demonstrate the feasibility of the new task and its effectiveness in extracting and describing implicit aspects and implicit opinions. The two datasets and source code of four systems are publicly released at https://github.com/NUSTM/ACOS.
The product reviews summarization task aims to automatically produce a short summary for a set of reviews of a given product. Such summaries are expected to aggregate a range of different opinions in a concise, coherent and informative manner. This challenging task gives rise to two shortcomings in existing work. First, summarizers tend to favor generic content that appears in reviews for many different products, resulting in template-like, less informative summaries. Second, as reviewers often disagree on the pros and cons of a given product, summarizers sometimes yield inconsistent, self-contradicting summaries. We propose the PASS system (Perturb-and-Select Summarizer) that employs a large pre-trained Transformer-based model (T5 in our case), which follows a few-shot fine-tuning scheme. A key component of the PASS system relies on applying systematic perturbations to the model’s input during inference, which allows it to generate multiple different summaries per product. We develop a method for ranking these summaries according to desired criteria, coherence in our case, enabling our system to almost entirely avoid the problem of self-contradiction. We compare our system against strong baselines on publicly available datasets, and show that it produces summaries which are more informative, diverse and coherent.
For sentence-level extractive summarization, there is a disproportionate ratio of selected and unselected sentences, leading to flatting the summary features when maximizing the accuracy. The imbalanced classification of summarization is inherent, which can’t be addressed by common algorithms easily. In this paper, we conceptualize the single-document extractive summarization as a rebalance problem and present a deep differential amplifier framework. Specifically, we first calculate and amplify the semantic difference between each sentence and all other sentences, and then apply the residual unit as the second item of the differential amplifier to deepen the architecture. Finally, to compensate for the imbalance, the corresponding objective loss of minority class is boosted by a weighted cross-entropy. In contrast to previous approaches, this model pays more attention to the pivotal information of one sentence, instead of all the informative context modeling by recurrent or Transformer architecture. We demonstrate experimentally on two benchmark datasets that our summarizer performs competitively against state-of-the-art methods. Our source code will be available on Github.
In this paper, we address a novel task, Multiple TimeLine Summarization (MTLS), which extends the flexibility and versatility of Time-Line Summarization (TLS). Given any collection of time-stamped news articles, MTLS automatically discovers important yet different stories and generates a corresponding time-line for each story.To achieve this, we propose a novel unsupervised summarization framework based on two-stage affinity propagation. We also introduce a quantitative evaluation measure for MTLS based on previousTLS evaluation methods. Experimental results show that our MTLS framework demonstrates high effectiveness and MTLS task can give bet-ter results than TLS.
Recently, opinion summarization, which is the generation of a summary from multiple reviews, has been conducted in a self-supervised manner by considering a sampled review as a pseudo summary. However, non-text data such as image and metadata related to reviews have been considered less often. To use the abundant information contained in non-text data, we propose a self-supervised multimodal opinion summarization framework called MultimodalSum. Our framework obtains a representation of each modality using a separate encoder for each modality, and the text decoder generates a summary. To resolve the inherent heterogeneity of multimodal data, we propose a multimodal training pipeline. We first pretrain the text encoder–decoder based solely on text modality data. Subsequently, we pretrain the non-text modality encoders by considering the pretrained text decoder as a pivot for the homogeneous representation of multimodal data. Finally, to fuse multimodal representations, we train the entire framework in an end-to-end manner. We demonstrate the superiority of MultimodalSum by conducting experiments on Yelp and Amazon datasets.
In recent years, reference-based and supervised summarization evaluation metrics have been widely explored. However, collecting human-annotated references and ratings are costly and time-consuming. To avoid these limitations, we propose a training-free and reference-free summarization evaluation metric. Our metric consists of a centrality-weighted relevance score and a self-referenced redundancy score. The relevance score is computed between the pseudo reference built from the source document and the given summary, where the pseudo reference content is weighted by the sentence centrality to provide importance guidance. Besides an F1-based relevance score, we also design an F𝛽-based variant that pays more attention to the recall score. As for the redundancy score of the summary, we compute a self-masked similarity score with the summary itself to evaluate the redundant information in the summary. Finally, we combine the relevance and redundancy scores to produce the final evaluation score of the given summary. Extensive experiments show that our methods can significantly outperform existing methods on both multi-document and single-document summarization evaluation. The source code is released at https://github.com/Chen-Wang-CUHK/Training-Free-and-Ref-Free-Summ-Evaluation.
Short textual descriptions of entities provide summaries of their key attributes and have been shown to be useful sources of background knowledge for tasks such as entity linking and question answering. However, generating entity descriptions, especially for new and long-tail entities, can be challenging since relevant information is often scattered across multiple sources with varied content and style. We introduce DESCGEN: given mentions spread over multiple documents, the goal is to generate an entity summary description. DESCGEN consists of 37K entity descriptions from Wikipedia and Fandom, each paired with nine evidence documents on average. The documents were collected using a combination of entity linking and hyperlinks into the entity pages, which together provide high-quality distant supervision. Compared to other multi-document summarization tasks, our task is entity-centric, more abstractive, and covers a wide range of domains. We also propose a two-stage extract-then-generate baseline and show that there exists a large gap (19.9% in ROUGE-L) between state-of-art models and human performance, suggesting that the data will support significant future work.
With the recent success of pre-trained models in NLP, a significant focus was put on interpreting their representations. One of the most prominent approaches is structural probing (Hewitt and Manning, 2019), where a linear projection of word embeddings is performed in order to approximate the topology of dependency structures. In this work, we introduce a new type of structural probing, where the linear projection is decomposed into 1. iso-morphic space rotation; 2. linear scaling that identifies and scales the most relevant dimensions. In addition to syntactic dependency, we evaluate our method on two novel tasks (lexical hypernymy and position in a sentence). We jointly train the probes for multiple tasks and experimentally show that lexical and syntactic information is separated in the representations. Moreover, the orthogonal constraint makes the Structural Probes less vulnerable to memorization.
Backdoor attacks are a kind of insidious security threat against machine learning models. After being injected with a backdoor in training, the victim model will produce adversary-specified outputs on the inputs embedded with predesigned triggers but behave properly on normal inputs during inference. As a sort of emergent attack, backdoor attacks in natural language processing (NLP) are investigated insufficiently. As far as we know, almost all existing textual backdoor attack methods insert additional contents into normal samples as triggers, which causes the trigger-embedded samples to be detected and the backdoor attacks to be blocked without much effort. In this paper, we propose to use the syntactic structure as the trigger in textual backdoor attacks. We conduct extensive experiments to demonstrate that the syntactic trigger-based attack method can achieve comparable attack performance (almost 100% success rate) to the insertion-based methods but possesses much higher invisibility and stronger resistance to defenses. These results also reveal the significant insidiousness and harmfulness of textual backdoor attacks. All the code and data of this paper can be obtained at https://github.com/thunlp/HiddenKiller.
Since language models are used to model a wide variety of languages, it is natural to ask whether the neural architectures used for the task have inductive biases towards modeling particular types of languages. Investigation of these biases has proved complicated due to the many variables that appear in the experimental setup. Languages vary in many typological dimensions, and it is difficult to single out one or two to investigate without the others acting as confounders. We propose a novel method for investigating the inductive biases of language models using artificial languages. These languages are constructed to allow us to create parallel corpora across languages that differ only in the typological feature being investigated, such as word order. We then use them to train and test language models. This constitutes a fully controlled causal framework, and demonstrates how grammar engineering can serve as a useful tool for analyzing neural models. Using this method, we find that commonly used neural architectures exhibit different inductive biases: LSTMs display little preference with respect to word ordering, while transformers display a clear preference for some orderings over others. Further, we find that neither the inductive bias of the LSTM nor that of the transformer appear to reflect any tendencies that we see in attested natural languages.
Despite the success of contextualized language models on various NLP tasks, it is still unclear what these models really learn. In this paper, we contribute to the current efforts of explaining such models by exploring the continuum between function and content words with respect to contextualization in BERT, based on linguistically-informed insights. In particular, we utilize scoring and visual analytics techniques: we use an existing similarity-based score to measure contextualization and integrate it into a novel visual analytics technique, presenting the model’s layers simultaneously and highlighting intra-layer properties and inter-layer differences. We show that contextualization is neither driven by polysemy nor by pure context variation. We also provide insights on why BERT fails to model words in the middle of the functionality continuum.
Neural network architectures in natural language processing often use attention mechanisms to produce probability distributions over input token representations. Attention has empirically been demonstrated to improve performance in various tasks, while its weights have been extensively used as explanations for model predictions. Recent studies (Jain and Wallace, 2019; Serrano and Smith, 2019; Wiegreffe and Pinter, 2019) have showed that it cannot generally be considered as a faithful explanation (Jacovi and Goldberg, 2020) across encoders and tasks. In this paper, we seek to improve the faithfulness of attention-based explanations for text classification. We achieve this by proposing a new family of Task-Scaling (TaSc) mechanisms that learn task-specific non-contextualised information to scale the original attention weights. Evaluation tests for explanation faithfulness, show that the three proposed variants of TaSc improve attention-based explanations across two attention mechanisms, five encoders and five text classification datasets without sacrificing predictive performance. Finally, we demonstrate that TaSc consistently provides more faithful attention-based explanations compared to three widely-used interpretability techniques.
Car-focused navigation services are based on turns and distances of named streets, whereas navigation instructions naturally used by humans are centered around physical objects called landmarks. We present a neural model that takes OpenStreetMap representations as input and learns to generate navigation instructions that contain visible and salient landmarks from human natural language instructions. Routes on the map are encoded in a location- and rotation-invariant graph representation that is decoded into natural language instructions. Our work is based on a novel dataset of 7,672 crowd-sourced instances that have been verified by human navigation in Street View. Our evaluation shows that the navigation instructions generated by our system have similar properties as human-generated instructions, and lead to successful human navigation in Street View.
Vision-language pre-training (VLP) on large-scale image-text pairs has achieved huge success for the cross-modal downstream tasks. The most existing pre-training methods mainly adopt a two-step training procedure, which firstly employs a pre-trained object detector to extract region-based visual features, then concatenates the image representation and text embedding as the input of Transformer to train. However, these methods face problems of using task-specific visual representation of the specific object detector for generic cross-modal understanding, and the computation inefficiency of two-stage pipeline. In this paper, we propose the first end-to-end vision-language pre-trained model for both V+L understanding and generation, namely E2E-VLP, where we build a unified Transformer framework to jointly learn visual representation, and semantic alignments between image and text. We incorporate the tasks of object detection and image captioning into pre-training with a unified Transformer encoder-decoder architecture for enhancing visual learning. An extensive set of experiments have been conducted on well-established vision-language downstream tasks to demonstrate the effectiveness of this novel VLP paradigm.
Despite the achievements of large-scale multimodal pre-training approaches, cross-modal retrieval, e.g., image-text retrieval, remains a challenging task. To bridge the semantic gap between the two modalities, previous studies mainly focus on word-region alignment at the object level, lacking the matching between the linguistic relation among the words and the visual relation among the regions. The neglect of such relation consistency impairs the contextualized representation of image-text pairs and hinders the model performance and the interpretability. In this paper, we first propose a novel metric, Intra-modal Self-attention Distance (ISD), to quantify the relation consistency by measuring the semantic distance between linguistic and visual relations. In response, we present Inter-modal Alignment on Intra-modal Self-attentions (IAIS), a regularized training method to optimize the ISD and calibrate intra-modal self-attentions from the two modalities mutually via inter-modal alignment. The IAIS regularizer boosts the performance of prevailing models on Flickr30k and MS COCO datasets by a considerable margin, which demonstrates the superiority of our approach.
We present Knowledge Enhanced Multimodal BART (KM-BART), which is a Transformer-based sequence-to-sequence model capable of reasoning about commonsense knowledge from multimodal inputs of images and texts. We adapt the generative BART architecture (Lewis et al., 2020) to a multimodal model with visual and textual inputs. We further develop novel pretraining tasks to improve the model performance on the Visual Commonsense Generation (VCG) task. In particular, our pretraining task of Knowledge-based Commonsense Generation (KCG) boosts model performance on the VCG task by leveraging commonsense knowledge from a large language model pretrained on external commonsense knowledge graphs. To the best of our knowledge, we are the first to propose a dedicated task for improving model performance on the VCG task. Experimental results show that our model reaches state-of-the-art performance on the VCG task (Park et al., 2020) by applying these novel pretraining tasks.
Transformers have advanced the field of natural language processing (NLP) on a variety of important tasks. At the cornerstone of the Transformer architecture is the multi-head attention (MHA) mechanism which models pairwise interactions between the elements of the sequence. Despite its massive success, the current framework ignores interactions among different heads, leading to the problem that many of the heads are redundant in practice, which greatly wastes the capacity of the model. To improve parameter efficiency, we re-formulate the MHA as a latent variable model from a probabilistic perspective. We present cascaded head-colliding attention (CODA) which explicitly models the interactions between attention heads through a hierarchical variational distribution. We conduct extensive experiments and demonstrate that CODA outperforms the transformer baseline, by 0.6 perplexity on Wikitext-103 in language modeling, and by 0.6 BLEU on WMT14 EN-DE in machine translation, due to its improvements on the parameter efficiency.
Knowledge distillation is a critical technique to transfer knowledge between models, typically from a large model (the teacher) to a more fine-grained one (the student). The objective function of knowledge distillation is typically the cross-entropy between the teacher and the student’s output distributions. However, for structured prediction problems, the output space is exponential in size; therefore, the cross-entropy objective becomes intractable to compute and optimize directly. In this paper, we derive a factorized form of the knowledge distillation objective for structured prediction, which is tractable for many typical choices of the teacher and student models. In particular, we show the tractability and empirical effectiveness of structural knowledge distillation between sequence labeling and dependency parsing models under four different scenarios: 1) the teacher and student share the same factorization form of the output structure scoring function; 2) the student factorization produces more fine-grained substructures than the teacher factorization; 3) the teacher factorization produces more fine-grained substructures than the student factorization; 4) the factorization forms from the teacher and the student are incompatible.
State-of-the-art parameter-efficient fine-tuning methods rely on introducing adapter modules between the layers of a pretrained language model. However, such modules are trained separately for each task and thus do not enable sharing information across tasks. In this paper, we show that we can learn adapter parameters for all layers and tasks by generating them using shared hypernetworks, which condition on task, adapter position, and layer id in a transformer model. This parameter-efficient multi-task learning framework allows us to achieve the best of both worlds by sharing knowledge across tasks via hypernetworks while enabling the model to adapt to each individual task through task-specific adapters. Experiments on the well-known GLUE benchmark show improved performance in multi-task learning while adding only 0.29% parameters per task. We additionally demonstrate substantial performance improvements in few-shot domain generalization across a variety of tasks. Our code is publicly available in https://github.com/rabeehk/hyperformer.
Pre-trained multilingual language models, e.g., multilingual-BERT, are widely used in cross-lingual tasks, yielding the state-of-the-art performance. However, such models suffer from a large performance gap between source and target languages, especially in the zero-shot setting, where the models are fine-tuned only on English but tested on other languages for the same task. We tackle this issue by incorporating language-agnostic information, specifically, universal syntax such as dependency relations and POS tags, into language models, based on the observation that universal syntax is transferable across different languages. Our approach, called COunterfactual SYntax (COSY), includes the design of SYntax-aware networks as well as a COunterfactual training method to implicitly force the networks to learn not only the semantics but also the syntax. To evaluate COSY, we conduct cross-lingual experiments on natural language inference and question answering using mBERT and XLM-R as network backbones. Our results show that COSY achieves the state-of-the-art performance for both tasks, without using auxiliary training data.
Recent studies on neural networks with pre-trained weights (i.e., BERT) have mainly focused on a low-dimensional subspace, where the embedding vectors computed from input words (or their contexts) are located. In this work, we propose a new approach, called OoMMix, to finding and regularizing the remainder of the space, referred to as out-of-manifold, which cannot be accessed through the words. Specifically, we synthesize the out-of-manifold embeddings based on two embeddings obtained from actually-observed words, to utilize them for fine-tuning the network. A discriminator is trained to detect whether an input embedding is located inside the manifold or not, and simultaneously, a generator is optimized to produce new embeddings that can be easily identified as out-of-manifold by the discriminator. These two modules successfully collaborate in a unified and end-to-end manner for regularizing the out-of-manifold. Our extensive evaluation on various text classification benchmarks demonstrates the effectiveness of our approach, as well as its good compatibility with existing data augmentation techniques which aim to enhance the manifold.
Stereotypical language expresses widely-held beliefs about different social categories. Many stereotypes are overtly negative, while others may appear positive on the surface, but still lead to negative consequences. In this work, we present a computational approach to interpreting stereotypes in text through the Stereotype Content Model (SCM), a comprehensive causal theory from social psychology. The SCM proposes that stereotypes can be understood along two primary dimensions: warmth and competence. We present a method for defining warmth and competence axes in semantic embedding space, and show that the four quadrants defined by this subspace accurately represent the warmth and competence concepts, according to annotated lexicons. We then apply our computational SCM model to textual stereotype data and show that it compares favourably with survey-based studies in the psychological literature. Furthermore, we explore various strategies to counter stereotypical beliefs with anti-stereotypes. It is known that countering stereotypes with anti-stereotypical examples is one of the most effective ways to reduce biased thinking, yet the problem of generating anti-stereotypes has not been previously studied. Thus, a better understanding of how to generate realistic and effective anti-stereotypes can contribute to addressing pressing societal concerns of stereotyping, prejudice, and discrimination.
Misinformation has recently become a well-documented matter of public concern. Existing studies on this topic have hitherto adopted a coarse concept of misinformation, which incorporates a broad spectrum of story types ranging from political conspiracies to misinterpreted pranks. This paper aims to structurize these misinformation stories by leveraging fact-check articles. Our intuition is that key phrases in a fact-check article that identify the misinformation type(s) (e.g., doctored images, urban legends) also act as rationales that determine the verdict of the fact-check (e.g., false). We experiment on rationalized models with domain knowledge as weak supervision to extract these phrases as rationales, and then cluster semantically similar rationales to summarize prevalent misinformation types. Using archived fact-checks from Snopes.com, we identify ten types of misinformation stories. We discuss how these types have evolved over the last ten years and compare their prevalence between the 2016/2020 US presidential elections and the H1N1/COVID-19 pandemics.
While there is an abundance of advice to podcast creators on how to speak in ways that engage their listeners, there has been little data-driven analysis of podcasts that relates linguistic style with engagement. In this paper, we investigate how various factors – vocabulary diversity, distinctiveness, emotion, and syntax, among others – correlate with engagement, based on analysis of the creators’ written descriptions and transcripts of the audio. We build models with different textual representations, and show that the identified features are highly predictive of engagement. Our analysis tests popular wisdom about stylistic elements in high-engagement podcasts, corroborating some pieces of advice and adding new perspectives on others.
People debate on a variety of topics on online platforms such as Reddit, or Facebook. Debates can be lengthy, with users exchanging a wealth of information and opinions. However, conversations do not always go smoothly, and users sometimes engage in unsound argumentation techniques to prove a claim. These techniques are called fallacies. Fallacies are persuasive arguments that provide insufficient or incorrect evidence to support the claim. In this paper, we study the most frequent fallacies on Reddit, and we present them using the pragma-dialectical theory of argumentation. We construct a new annotated dataset of fallacies, using user comments containing fallacy mentions as noisy labels, and cleaning the data via crowdsourcing. Finally, we study the task of classifying fallacies using neural models. We find that generally the models perform better in the presence of conversational context.We have released the data and the code at github.com/sahaisaumya/informal_fallacies.
Inferring social relations from dialogues is vital for building emotionally intelligent robots to interpret human language better and act accordingly. We model the social network as an And-or Graph, named SocAoG, for the consistency of relations among a group and leveraging attributes as inference cues. Moreover, we formulate a sequential structure prediction task, and propose an 𝛼-𝛽-𝛾 strategy to incrementally parse SocAoG for the dynamic inference upon any incoming utterance: (i) an 𝛼 process predicting attributes and relations conditioned on the semantics of dialogues, (ii) a 𝛽 process updating the social relations based on related attributes, and (iii) a 𝛾 process updating individual’s attributes based on interpersonal social relations. Empirical results on DialogRE and MovieGraph show that our model infers social relations more accurately than the state-of-the-art methods. Moreover, the ablation study shows the three processes complement each other, and the case study demonstrates the dynamic relational inference.
We present a data-driven, end-to-end approach to transaction-based dialog systems that performs at near-human levels in terms of verbal response quality and factual grounding accuracy. We show that two essential components of the system produce these results: a sufficiently large and diverse, in-domain labeled dataset, and a neural network-based, pre-trained model that generates both verbal responses and API call predictions. In terms of data, we introduce TicketTalk, a movie ticketing dialog dataset with 23,789 annotated conversations. The conversations range from completely open-ended and unrestricted to more structured, both in terms of their knowledge base, discourse features, and number of turns. In qualitative human evaluations, model-generated responses trained on just 10,000 TicketTalk dialogs were rated to “make sense” 86.5% of the time, almost the same as human responses in the same contexts. Our simple, API-focused annotation schema results in a much easier labeling task making it faster and more cost effective. It is also the key component for being able to predict API calls accurately. We handle factual grounding by incorporating API calls in the training data, allowing our model to learn which actions to take and when. Trained on the same 10,000-dialog set, the model’s API call predictions were rated to be correct 93.9% of the time in our evaluations, surpassing the ratings for the corresponding human labels. We show how API prediction and response generation scores improve as the dataset size incrementally increases from 5000 to 21,000 dialogs. Our analysis also clearly illustrates the benefits of pre-training. To facilitate future work on transaction-based dialog systems, we are publicly releasing the TicketTalk dataset at https://git.io/JL8an.
In this paper, we explore the ability to model and infer personality types of opponents, predict their responses, and use this information to adapt a dialog agent’s high-level strategy in negotiation tasks. Inspired by the idea of incorporating a theory of mind (ToM) into machines, we introduce a probabilistic formulation to encapsulate the opponent’s personality type during both learning and inference. We test our approach on the CraigslistBargain dataset (He et al. 2018) and show that our method using ToM inference achieves a 20% higher dialog agreement rate compared to baselines on a mixed population of opponents. We also demonstrate that our model displays diverse negotiation behavior with different types of opponents.
In this paper, we propose Inverse Adversarial Training (IAT) algorithm for training neural dialogue systems to avoid generic responses and model dialogue history better. In contrast to standard adversarial training algorithms, IAT encourages the model to be sensitive to the perturbation in the dialogue history and therefore learning from perturbations. By giving higher rewards for responses whose output probability reduces more significantly when dialogue history is perturbed, the model is encouraged to generate more diverse and consistent responses. By penalizing the model when generating the same response given perturbed dialogue history, the model is forced to better capture dialogue history and generate more informative responses. Experimental results on two benchmark datasets show that our approach can better model dialogue history and generate more diverse and consistent responses. In addition, we point out a problem of the widely used maximum mutual information (MMI) based methods for improving the diversity of dialogue response generation models and demonstrate it empirically.
Knowledge-grounded dialogue systems are intended to convey information that is based on evidence provided in a given source text. We discuss the challenges of training a generative neural dialogue model for such systems that is controlled to stay faithful to the evidence. Existing datasets contain a mix of conversational responses that are faithful to selected evidence as well as more subjective or chit-chat style responses. We propose different evaluation measures to disentangle these different styles of responses by quantifying the informativeness and objectivity. At training time, additional inputs based on these evaluation measures are given to the dialogue model. At generation time, these additional inputs act as stylistic controls that encourage the model to generate responses that are faithful to the provided evidence. We also investigate the usage of additional controls at decoding time using resampling techniques. In addition to automatic metrics, we perform a human evaluation study where raters judge the output of these controlled generation models to be generally more objective and faithful to the evidence compared to baseline dialogue systems.
Automatically extracting key information from scientific documents has the potential to help scientists work more efficiently and accelerate the pace of scientific progress. Prior work has considered extracting document-level entity clusters and relations end-to-end from raw scientific text, which can improve literature search and help identify methods and materials for a given problem. Despite the importance of this task, most existing works on scientific information extraction (SciIE) consider extraction solely based on the content of an individual paper, without considering the paper’s place in the broader literature. In contrast to prior work, we augment our text representations by leveraging a complementary source of document context: the citation graph of referential links between citing and cited papers. On a test set of English-language scientific documents, we show that simple ways of utilizing the structure and content of the citation graph can each lead to significant gains in different scientific information extraction tasks. When these tasks are combined, we observe a sizable improvement in end-to-end information extraction over the state-of-the-art, suggesting the potential for future work along this direction. We release software tools to facilitate citation-aware SciIE development.
Current event-centric knowledge graphs highly rely on explicit connectives to mine relations between events. Unfortunately, due to the sparsity of connectives, these methods severely undermine the coverage of EventKGs. The lack of high-quality labelled corpora further exacerbates that problem. In this paper, we propose a knowledge projection paradigm for event relation extraction: projecting discourse knowledge to narratives by exploiting the commonalities between them. Specifically, we propose Multi-tier Knowledge Projection Network (MKPNet), which can leverage multi-tier discourse knowledge effectively for event relation extraction. In this way, the labelled data requirement is significantly reduced, and implicit event relations can be effectively extracted. Intrinsic experimental results show that MKPNet achieves the new state-of-the-art performance and extrinsic experimental results verify the value of the extracted event relations.
Neural methods have been shown to achieve high performance in Named Entity Recognition (NER), but rely on costly high-quality labeled data for training, which is not always available across languages. While previous works have shown that unlabeled data in a target language can be used to improve cross-lingual model performance, we propose a novel adversarial approach (AdvPicker) to better leverage such data and further improve results. We design an adversarial learning framework in which an encoder learns entity domain knowledge from labeled source-language data and better shared features are captured via adversarial training - where a discriminator selects less language-dependent target-language data via similarity to the source language. Experimental results on standard benchmark datasets well demonstrate that the proposed method benefits strongly from this data selection process and outperforms existing state-of-the-art methods; without requiring any additional external resources (e.g., gazetteers or via machine translation).
Nowadays, fake news detection, which aims to verify whether a news document is trusted or fake, has become urgent and important. Most existing methods rely heavily on linguistic and semantic features from the news content, and fail to effectively exploit external knowledge which could help determine whether the news document is trusted. In this paper, we propose a novel end-to-end graph neural model called CompareNet, which compares the news to the knowledge base (KB) through entities for fake news detection. Considering that fake news detection is correlated with topics, we also incorporate topics to enrich the news representation. Specifically, we first construct a directed heterogeneous document graph for each news incorporating topics and entities. Based on the graph, we develop a heterogeneous graph attention network for learning the topic-enriched news representation as well as the contextual entity representations that encode the semantics of the news content. The contextual entity representations are then compared to the corresponding KB-based entity representations through a carefully designed entity comparison network, to capture the consistency between the news content and KB. Finally, the topic-enriched news representation combining the entity comparison features is fed into a fake news classifier. Experimental results on two benchmark datasets demonstrate that CompareNet significantly outperforms state-of-the-art methods.
Named entity recognition (NER) remains challenging when entity mentions can be discontinuous. Existing methods break the recognition process into several sequential steps. In training, they predict conditioned on the golden intermediate results, while at inference relying on the model output of the previous steps, which introduces exposure bias. To solve this problem, we first construct a segment graph for each sentence, in which each node denotes a segment (a continuous entity on its own, or a part of discontinuous entities), and an edge links two nodes that belong to the same entity. The nodes and edges can be generated respectively in one stage with a grid tagging scheme and learned jointly using a novel architecture named Mac. Then discontinuous NER can be reformulated as a non-parametric process of discovering maximal cliques in the graph and concatenating the spans in each clique. Experiments on three benchmarks show that our method outperforms the state-of-the-art (SOTA) results, with up to 3.5 percentage points improvement on F1, and achieves 5x speedup over the SOTA model.
Entity linking (EL) is the task of disambiguating mentions appearing in text by linking them to entities in a knowledge graph, a crucial task for text understanding, question answering or conversational systems. In the special case of short-text EL, which poses additional challenges due to limited context, prior approaches have reached good performance by employing heuristics-based methods or purely neural approaches. Here, we take a different, neuro-symbolic approach that combines the advantages of using interpretable rules based on first-order logic with the performance of neural learning. Even though constrained to use rules, we show that we reach competitive or better performance with SoTA black-box neural approaches. Furthermore, our framework has the benefits of extensibility and transferability. We show that we can easily blend existing rule templates given by a human expert, with multiple types of features (priors, BERT encodings, box embeddings, etc), and even with scores resulting from previous EL methods, thus improving on such methods. As an example of improvement, on the LC-QuAD-1.0 dataset, we show more than 3% increase in F1 score relative to previous SoTA. Finally, we show that the inductive bias offered by using logic results in a set of learned rules that transfers from one dataset to another, sometimes without finetuning, while still having high accuracy.
Context-aware machine translation models are designed to leverage contextual information, but often fail to do so. As a result, they inaccurately disambiguate pronouns and polysemous words that require context for resolution. In this paper, we ask several questions: What contexts do human translators use to resolve ambiguous words? Are models paying large amounts of attention to the same context? What if we explicitly train them to do so? To answer these questions, we introduce SCAT (Supporting Context for Ambiguous Translations), a new English-French dataset comprising supporting context words for 14K translations that professional translators found useful for pronoun disambiguation. Using SCAT, we perform an in-depth analysis of the context used to disambiguate, examining positional and lexical characteristics of the supporting words. Furthermore, we measure the degree of alignment between the model’s attention scores and the supporting context from SCAT, and apply a guided attention strategy to encourage agreement between the two.
The scarcity of parallel data is a major obstacle for training high-quality machine translation systems for low-resource languages. Fortunately, some low-resource languages are linguistically related or similar to high-resource languages; these related languages may share many lexical or syntactic structures. In this work, we exploit this linguistic overlap to facilitate translating to and from a low-resource language with only monolingual data, in addition to any parallel data in the related high-resource language. Our method, NMT-Adapt, combines denoising autoencoding, back-translation and adversarial objectives to utilize monolingual data for low-resource adaptation. We experiment on 7 languages from three different language families and show that our technique significantly improves translation into low-resource language compared to other translation baselines.
Bilingual lexicons map words in one language to their translations in another, and are typically induced by learning linear projections to align monolingual word embedding spaces. In this paper, we show it is possible to produce much higher quality lexicons with methods that combine (1) unsupervised bitext mining and (2) unsupervised word alignment. Directly applying a pipeline that uses recent algorithms for both subproblems significantly improves induced lexicon quality and further gains are possible by learning to filter the resulting lexical entries, with both unsupervised and semi-supervised schemes. Our final model outperforms the state of the art on the BUCC 2020 shared task by 14 F1 points averaged over 12 language pairs, while also providing a more interpretable approach that allows for rich reasoning of word meaning in context. Further analysis of our output and the standard reference lexicons suggests they are of comparable quality, and new benchmarks may be needed to measure further progress on this task.
We present a simple yet effective approach to build multilingual speech-to-text (ST) translation through efficient transfer learning from a pretrained speech encoder and text decoder. Our key finding is that a minimalistic LNA (LayerNorm and Attention) finetuning can achieve zero-shot crosslingual and cross-modality transfer ability by only finetuning 10 50% of the pretrained parameters. This effectively leverages large pretrained models at low training cost such as wav2vec 2.0 for acoustic modeling, and mBART for multilingual text generation. This sets a new state-of-the-art for 36 translation directions (and surpassing cascaded ST for 26 of them) on the large-scale multilingual ST benchmark CoVoST 2 (+6.4 BLEU on average for En-X directions and +6.7 BLEU for X-En directions). Our approach demonstrates strong zero-shot performance in a many-to-many multilingual model (+5.6 BLEU on average across 28 non-English directions), making it an appealing approach for attaining high-quality speech translation with improved parameter and data efficiency.
Learning contextual text embeddings that represent causal graphs has been useful in improving the performance of downstream tasks like causal treatment effect estimation. However, existing causal embeddings which are trained to predict direct causal links, fail to capture other indirect causal links of the graph, thus leading to spurious correlations in downstream tasks. In this paper, we define the faithfulness property of contextual embeddings to capture geometric distance-based properties of directed acyclic causal graphs. By incorporating these faithfulness properties, we learn text embeddings that are 31.3% more faithful to human validated causal graphs with about 800K and 200K causal links and achieve 21.1% better Precision-Recall AUC in a link prediction fine-tuning task. Further, in a crowdsourced causal question-answering task on Yahoo! Answers with questions of the form “What causes X?”, our faithful embeddings achieved a precision of the first ranked answer (P@1) of 41.07%, outperforming the existing baseline by 10.2%.
Transformer-based language models benefit from conditioning on contexts of hundreds to thousands of previous tokens. What aspects of these contexts contribute to accurate model prediction? We describe a series of experiments that measure usable information by selectively ablating lexical and structural information in transformer language models trained on English Wikipedia. In both mid- and long-range contexts, we find that several extremely destructive context manipulations—including shuffling word order within sentences and deleting all words other than nouns—remove less than 15% of the usable information. Our results suggest that long contexts, but not their detailed syntactic and propositional content, are important for the low perplexity of current transformer language models.
In this paper, we introduce Integrated Directional Gradients (IDG), a method for attributing importance scores to groups of features, indicating their relevance to the output of a neural network model for a given input. The success of Deep Neural Networks has been attributed to their ability to capture higher level feature interactions. Hence, in the last few years capturing the importance of these feature interactions has received increased prominence in ML interpretability literature. In this paper, we formally define the feature group attribution problem and outline a set of axioms that any intuitive feature group attribution method should satisfy. Earlier, cooperative game theory inspired axiomatic methods only borrowed axioms from solution concepts (such as Shapley value) for individual feature attributions and introduced their own extensions to model interactions. In contrast, our formulation is inspired by axioms satisfied by characteristic functions as well as solution concepts in cooperative game theory literature. We believe that characteristic functions are much better suited to model importance of groups compared to just solution concepts. We demonstrate that our proposed method, IDG, satisfies all the axioms. Using IDG we analyze two state-of-the-art text classifiers on three benchmark datasets for sentiment analysis. Our experiments show that IDG is able to effectively capture semantic interactions in linguistic models via negations and conjunctions.
Sentence embeddings are an important component of many natural language processing (NLP) systems. Like word embeddings, sentence embeddings are typically learned on large text corpora and then transferred to various downstream tasks, such as clustering and retrieval. Unlike word embeddings, the highest performing solutions for learning sentence embeddings require labelled data, limiting their usefulness to languages and domains where labelled data is abundant. In this paper, we present DeCLUTR: Deep Contrastive Learning for Unsupervised Textual Representations. Inspired by recent advances in deep metric learning (DML), we carefully design a self-supervised objective for learning universal sentence embeddings that does not require labelled training data. When used to extend the pretraining of transformer-based language models, our approach closes the performance gap between unsupervised and supervised pretraining for universal sentence encoders. Importantly, our experiments suggest that the quality of the learned embeddings scale with both the number of trainable parameters and the amount of unlabelled training data. Our code and pretrained models are publicly available and can be easily adapted to new domains or used to embed unseen text.
Due to the scarcity of annotated data, Abstract Meaning Representation (AMR) research is relatively limited and challenging for languages other than English. Upon the availability of English AMR dataset and English-to- X parallel datasets, in this paper we propose a novel cross-lingual pre-training approach via multi-task learning (MTL) for both zeroshot AMR parsing and AMR-to-text generation. Specifically, we consider three types of relevant tasks, including AMR parsing, AMR-to-text generation, and machine translation. We hope that knowledge gained while learning for English AMR parsing and text generation can be transferred to the counterparts of other languages. With properly pretrained models, we explore four different finetuning methods, i.e., vanilla fine-tuning with a single task, one-for-all MTL fine-tuning, targeted MTL fine-tuning, and teacher-studentbased MTL fine-tuning. Experimental results on AMR parsing and text generation of multiple non-English languages demonstrate that our approach significantly outperforms a strong baseline of pre-training approach, and greatly advances the state of the art. In detail, on LDC2020T07 we have achieved 70.45%, 71.76%, and 70.80% in Smatch F1 for AMR parsing of German, Spanish, and Italian, respectively, while for AMR-to-text generation of the languages, we have obtained 25.69, 31.36, and 28.42 in BLEU respectively. We make our code available on github https://github.com/xdqkid/XLPT-AMR.
Despite the success of sequence-to-sequence (seq2seq) models in semantic parsing, recent work has shown that they fail in compositional generalization, i.e., the ability to generalize to new structures built of components observed during training. In this work, we posit that a span-based parser should lead to better compositional generalization. we propose SpanBasedSP, a parser that predicts a span tree over an input utterance, explicitly encoding how partial programs compose over spans in the input. SpanBasedSP extends Pasupat et al. (2019) to be comparable to seq2seq models by (i) training from programs, without access to gold trees, treating trees as latent variables, (ii) parsing a class of non-projective trees through an extension to standard CKY. On GeoQuery, SCAN and CLOSURE datasets, SpanBasedSP performs similarly to strong seq2seq baselines on random splits, but dramatically improves performance compared to baselines on splits that require compositional generalization: from 61.0 → 88.9 average accuracy.
Sequence-to-sequence models excel at handling natural language variation, but have been shown to struggle with out-of-distribution compositional generalization. This has motivated new specialized architectures with stronger compositional biases, but most of these approaches have only been evaluated on synthetically-generated datasets, which are not representative of natural language variation. In this work we ask: can we develop a semantic parsing approach that handles both natural language variation and compositional generalization? To better assess this capability, we propose new train and test splits of non-synthetic datasets. We demonstrate that strong existing approaches do not perform well across a broad set of evaluations. We also propose NQG-T5, a hybrid model that combines a high-precision grammar-based approach with a pre-trained sequence-to-sequence model. It outperforms existing approaches across several compositional generalization challenges on non-synthetic data, while also being competitive with the state-of-the-art on standard evaluations. While still far from solving this problem, our study highlights the importance of diverse evaluations and the open challenge of handling both compositional generalization and natural language variation in semantic parsing.
We present a targeted, scaled-up comparison of incremental processing in humans and neural language models by collecting by-word reaction time data for sixteen different syntactic test suites across a range of structural phenomena. Human reaction time data comes from a novel online experimental paradigm called the Interpolated Maze task. We compare human reaction times to by-word probabilities for four contemporary language models, with different architectures and trained on a range of data set sizes. We find that across many phenomena, both humans and language models show increased processing difficulty in ungrammatical sentence regions with human and model ‘accuracy’ scores a la Marvin and Linzen (2018) about equal. However, although language model outputs match humans in direction, we show that models systematically under-predict the difference in magnitude of incremental processing difficulty between grammatical and ungrammatical sentences. Specifically, when models encounter syntactic violations they fail to accurately predict the longer reading times observed in the human data. These results call into question whether contemporary language models are approaching human-like performance for sensitivity to syntactic violations.
Modality is the linguistic ability to describe vents with added information such as how desirable, plausible, or feasible they are. Modality is important for many NLP downstream tasks such as the detection of hedging, uncertainty, speculation, and more. Previous studies that address modality detection in NLP often restrict modal expressions to a closed syntactic class, and the modal sense labels are vastly different across different studies, lacking an accepted standard. Furthermore, these senses are often analyzed independently of the events that they modify. This work builds on the theoretical foundations of the Georgetown Gradable Modal Expressions (GME) work by Rubinstein et al. (2013) to propose an event-based modality detection task where modal expressions can be words of any syntactic class and sense labels are drawn from a comprehensive taxonomy which harmonizes the modal concepts contributed by the different studies. We present experiments on the GME corpus aiming to detect and classify fine-grained modal concepts and associate them with their modified events. We show that detecting and classifying modal expressions is not only feasible, it also improves the detection of modal events in their own right.
Part-of-Speech (POS) tags are routinely included as features in many NLP tasks. However, the importance and usefulness of POS tags needs to be examined as NLP expands to low-resource languages because linguists who provide many annotated resources do not place priority on early identification and tagging of POS. This paper describes an empirical study about the effect that POS tags have on two computational morphological tasks with the Transformer architecture. Each task is tested twice on identical data except for the presence/absence of POS tags, using published data in ten high- to low-resource languages or unpublished linguistic field data in five low-resource languages. We find that the presence or absence of POS tags does not have a significant bearing on performance. In joint segmentation and glossing, the largest average difference is an .09 improvement in F1-scores by removing POS tags. In reinflection, the greatest average difference is 1.2% in accuracy for published data and 5% for unpublished and noisy field data.
Parsing spoken dialogue poses unique difficulties, including disfluencies and unmarked boundaries between sentence-like units. Previous work has shown that prosody can help with parsing disfluent speech (Tran et al. 2018), but has assumed that the input to the parser is already segmented into sentence-like units (SUs), which isn’t true in existing speech applications. We investigate how prosody affects a parser that receives an entire dialogue turn as input (a turn-based model), instead of gold standard pre-segmented SUs (an SU-based model). In experiments on the English Switchboard corpus, we find that when using transcripts alone, the turn-based model has trouble segmenting SUs, leading to worse parse performance than the SU-based model. However, prosody can effectively replace gold standard SU boundaries: with prosody, the turn-based model performs as well as the SU-based model (91.38 vs. 91.06 F1 score, respectively), despite performing two tasks (SU segmentation and parsing) rather than one (parsing alone). Analysis shows that pitch and intensity features are the most important for this corpus, since they allow the model to correctly distinguish an SU boundary from a speech disfluency – a distinction that the model otherwise struggles to make.
We introduce VoxPopuli, a large-scale multilingual corpus providing 400K hours of unlabeled speech data in 23 languages. It is the largest open data to date for unsupervised representation learning as well as semi-supervised learning. VoxPopuli also contains 1.8K hours of transcribed speeches in 15 languages and their aligned oral interpretations into 15 target languages totaling 17.3K hours. We provide speech recognition (ASR) baselines and validate the versatility of VoxPopuli unlabeled data in semi-supervised ASR and speech-to-text translation under challenging out-of-domain settings. The corpus is available at https://github.com/facebookresearch/voxpopuli.
Auditing NLP systems for computational harms like surfacing stereotypes is an elusive goal. Several recent efforts have focused on benchmark datasets consisting of pairs of contrastive sentences, which are often accompanied by metrics that aggregate an NLP system’s behavior on these pairs into measurements of harms. We examine four such benchmarks constructed for two NLP tasks: language modeling and coreference resolution. We apply a measurement modeling lens—originating from the social sciences—to inventory a range of pitfalls that threaten these benchmarks’ validity as measurement models for stereotyping. We find that these benchmarks frequently lack clear articulations of what is being measured, and we highlight a range of ambiguities and unstated assumptions that affect how these benchmarks conceptualize and operationalize stereotyping.
Knowledge Graph (KG) completion research usually focuses on densely connected benchmark datasets that are not representative of real KGs. We curate two KG datasets that include biomedical and encyclopedic knowledge and use an existing commonsense KG dataset to explore KG completion in the more realistic setting where dense connectivity is not guaranteed. We develop a deep convolutional network that utilizes textual entity representations and demonstrate that our model outperforms recent KG completion methods in this challenging setting. We find that our model’s performance improvements stem primarily from its robustness to sparsity. We then distill the knowledge from the convolutional network into a student network that re-ranks promising candidate entities. This re-ranking stage leads to further improvements in performance and demonstrates the effectiveness of entity re-ranking for KG completion.
Computing precise evidences, namely minimal sets of sentences that support or refute a given claim, rather than larger evidences is crucial in fact verification (FV), since larger evidences may contain conflicting pieces some of which support the claim while the other refute, thereby misleading FV. Despite being important, precise evidences are rarely studied by existing methods for FV. It is challenging to find precise evidences due to a large search space with lots of local optimums. Inspired by the strong exploration ability of the deep Q-learning network (DQN), we propose a DQN-based approach to retrieval of precise evidences. In addition, to tackle the label bias on Q-values computed by DQN, we design a post-processing strategy which seeks best thresholds for determining the true labels of computed evidences. Experimental results confirm the effectiveness of DQN in computing precise evidences and demonstrate improvements in achieving accurate claim verification.
In selective prediction, a classifier is allowed to abstain from making predictions on low-confidence examples. Though this setting is interesting and important, selective prediction has rarely been examined in natural language processing (NLP) tasks. To fill this void in the literature, we study in this paper selective prediction for NLP, comparing different models and confidence estimators. We further propose a simple error regularization trick that improves confidence estimation without substantially increasing the computation budget. We show that recent pre-trained transformer models simultaneously improve both model accuracy and confidence estimation effectiveness. We also find that our proposed regularization improves confidence estimation and can be applied to other relevant scenarios, such as using classifier cascades for accuracy–efficiency trade-offs. Source code for this paper can be found at https://github.com/castorini/transformers-selective.
Deployed real-world machine learning applications are often subject to uncontrolled and even potentially malicious inputs. Those out-of-domain inputs can lead to unpredictable outputs and sometimes catastrophic safety issues. Prior studies on out-of-domain detection require in-domain task labels and are limited to supervised classification scenarios. Our work tackles the problem of detecting out-of-domain samples with only unsupervised in-domain data. We utilize the latent representations of pre-trained transformers and propose a simple yet effective method to transform features across all layers to construct out-of-domain detectors efficiently. Two domain-specific fine-tuning approaches are further proposed to boost detection accuracy. Our empirical evaluations of related methods on two datasets validate that our method greatly improves out-of-domain detection ability in a more general scenario.
The advent of large pre-trained language models has given rise to rapid progress in the field of Natural Language Processing (NLP). While the performance of these models on standard benchmarks has scaled with size, compression techniques such as knowledge distillation have been key in making them practical. We present MATE-KD, a novel text-based adversarial training algorithm which improves the performance of knowledge distillation. MATE-KD first trains a masked language model-based generator to perturb text by maximizing the divergence between teacher and student logits. Then using knowledge distillation a student is trained on both the original and the perturbed training samples. We evaluate our algorithm, using BERT-based models, on the GLUE benchmark and demonstrate that MATE-KD outperforms competitive adversarial learning and data augmentation baselines. On the GLUE test set our 6 layer RoBERTa based model outperforms BERT-large.
Language model fine-tuning is essential for modern natural language processing, but is computationally expensive and time-consuming. Further, the effectiveness of fine-tuning is limited by the inclusion of training examples that negatively affect performance. Here we present a general fine-tuning method that we call information gain filtration for improving the overall training efficiency and final performance of language model fine-tuning. We define the information gain of an example as the improvement on a validation metric after training on that example. A secondary learner is then trained to approximate this quantity. During fine-tuning, this learner selects informative examples and skips uninformative ones. We show that our method has consistent improvement across datasets, fine-tuning tasks, and language model architectures. For example, we achieve a median perplexity of 54.0 on a books dataset compared to 57.3 for standard fine-tuning. We present statistical evidence that offers insight into the improvements of our method over standard fine-tuning. The generality of our method leads us to propose a new paradigm for language model fine-tuning — we encourage researchers to release pretrained secondary learners on common corpora to promote efficient and effective fine-tuning, thereby improving the performance and reducing the overall energy footprint of language model fine-tuning.
Text simplification reduces the language complexity of professional content for accessibility purposes. End-to-end neural network models have been widely adopted to directly generate the simplified version of input text, usually functioning as a blackbox. We show that text simplification can be decomposed into a compact pipeline of tasks to ensure the transparency and explainability of the process. The first two steps in this pipeline are often neglected: 1) to predict whether a given piece of text needs to be simplified, and 2) if yes, to identify complex parts of the text. The two tasks can be solved separately using either lexical or deep learning methods, or solved jointly. Simply applying explainable complexity prediction as a preliminary step, the out-of-sample text simplification performance of the state-of-the-art, black-box simplification models can be improved by a large margin.
Retrieving relevant contexts from a large corpus is a crucial step for tasks such as open-domain question answering and fact checking. Although neural retrieval outperforms traditional methods like tf-idf and BM25, its performance degrades considerably when applied to out-of-domain data. Driven by the question of whether a neural retrieval model can be _universal_ and perform robustly on a wide variety of problems, we propose a multi-task trained model. Our approach not only outperforms previous methods in the few-shot setting, but also rivals specialised neural retrievers, even when in-domain training data is abundant. With the help of our retriever, we improve existing models for downstream tasks and closely match or improve the state of the art on multiple benchmarks.
NLP is currently dominated by language models like RoBERTa which are pretrained on billions of words. But what exact knowledge or skills do Transformer LMs learn from large-scale pretraining that they cannot learn from less data? To explore this question, we adopt five styles of evaluation: classifier probing, information-theoretic probing, unsupervised relative acceptability judgments, unsupervised language model knowledge probing, and fine-tuning on NLU tasks. We then draw learning curves that track the growth of these different measures of model ability with respect to pretraining data volume using the MiniBERTas, a group of RoBERTa models pretrained on 1M, 10M, 100M and 1B words. We find that these LMs require only about 10M to 100M words to learn to reliably encode most syntactic and semantic features we test. They need a much larger quantity of data in order to acquire enough commonsense knowledge and other skills required to master typical downstream NLU tasks. The results suggest that, while the ability to encode linguistic features is almost certainly necessary for language understanding, it is likely that other, unidentified, forms of knowledge are the major drivers of recent improvements in language understanding among large pretrained models.
In Neural Machine Translation (and, more generally, conditional language modeling), the generation of a target token is influenced by two types of context: the source and the prefix of the target sequence. While many attempts to understand the internal workings of NMT models have been made, none of them explicitly evaluates relative source and target contributions to a generation decision. We argue that this relative contribution can be evaluated by adopting a variant of Layerwise Relevance Propagation (LRP). Its underlying ‘conservation principle’ makes relevance propagation unique: differently from other methods, it evaluates not an abstract quantity reflecting token importance, but the proportion of each token’s influence. We extend LRP to the Transformer and conduct an analysis of NMT models which explicitly evaluates the source and target relative contributions to the generation process. We analyze changes in these contributions when conditioning on different types of prefixes, when varying the training objective or the amount of training data, and during the training process. We find that models trained with more data tend to rely on source information more and to have more sharp token contributions; the training process is non-monotonic with several stages of different nature.
Recent years have seen numerous NLP datasets introduced to evaluate the performance of fine-tuned models on natural language understanding tasks. Recent results from large pretrained models, though, show that many of these datasets are largely saturated and unlikely to be able to detect further progress. What kind of datasets are still effective at discriminating among strong models, and what kind of datasets should we expect to be able to detect future improvements? To measure this uniformly across datasets, we draw on Item Response Theory and evaluate 29 datasets using predictions from 18 pretrained Transformer models on individual test examples. We find that Quoref, HellaSwag, and MC-TACO are best suited for distinguishing among state-of-the-art models, while SNLI, MNLI, and CommitmentBank seem to be saturated for current strong models. We also observe span selection task format, which is used for QA datasets like QAMR or SQuAD2.0, is effective in differentiating between strong and weak models.
A growing body of literature has focused on detailing the linguistic knowledge embedded in large, pretrained language models. Existing work has shown that non-linguistic biases in models can drive model behavior away from linguistic generalizations. We hypothesized that competing linguistic processes within a language, rather than just non-linguistic model biases, could obscure underlying linguistic knowledge. We tested this claim by exploring a single phenomenon in four languages: English, Chinese, Spanish, and Italian. While human behavior has been found to be similar across languages, we find cross-linguistic variation in model behavior. We show that competing processes in a language act as constraints on model behavior and demonstrate that targeted fine-tuning can re-weight the learned constraints, uncovering otherwise dormant linguistic knowledge in models. Our results suggest that models need to learn both the linguistic constraints in a language and their relative ranking, with mismatches in either producing non-human-like behavior.
Interpretability is an important aspect of the trustworthiness of a model’s predictions. Transformer’s predictions are widely explained by the attention weights, i.e., a probability distribution generated at its self-attention unit (head). Current empirical studies provide shreds of evidence that attention weights are not explanations by proving that they are not unique. A recent study showed theoretical justifications to this observation by proving the non-identifiability of attention weights. For a given input to a head and its output, if the attention weights generated in it are unique, we call the weights identifiable. In this work, we provide deeper theoretical analysis and empirical observations on the identifiability of attention weights. Ignored in the previous works, we find the attention weights are more identifiable than we currently perceive by uncovering the hidden role of the key vector. However, the weights are still prone to be non-unique attentions that make them unfit for interpretation. To tackle this issue, we provide a variant of the encoder layer that decouples the relationship between key and value vector and provides identifiable weights up to the desired length of the input. We prove the applicability of such variations by providing empirical justifications on varied text classification tasks. The implementations are available at https://github.com/declare-lab/identifiable-transformers.
Natural Language Generation (NLG) is a key component in a task-oriented dialogue system, which converts the structured meaning representation (MR) to the natural language. For large-scale conversational systems, where it is common to have over hundreds of intents and thousands of slots, neither template-based approaches nor model-based approaches are scalable. Recently, neural NLGs started leveraging transfer learning and showed promising results in few-shot settings. This paper proposes AugNLG, a novel data augmentation approach that combines a self-trained neural retrieval model with a few-shot learned NLU model, to automatically create MR-to-Text data from open-domain texts. The proposed system mostly outperforms the state-of-the-art methods on the FewshotWOZ data in both BLEU and Slot Error Rate. We further confirm improved results on the FewshotSGD data and provide comprehensive analysis results on key components of our system. Our code and data are available at https://github.com/XinnuoXu/AugNLG.
In this paper we implement and compare 7 different data augmentation strategies for the task of automatic scoring of children’s ability to understand others’ thoughts, feelings, and desires (or “mindreading”). We recruit in-domain experts to re-annotate augmented samples and determine to what extent each strategy preserves the original rating. We also carry out multiple experiments to measure how much each augmentation strategy improves the performance of automatic scoring systems. To determine the capabilities of automatic systems to generalize to unseen data, we create UK-MIND-20 - a new corpus of children’s performance on tests of mindreading, consisting of 10,320 question-answer pairs. We obtain a new state-of-the-art performance on the MIND-CA corpus, improving macro-F1-score by 6 points. Results indicate that both the number of training examples and the quality of the augmentation strategies affect the performance of the systems. The task-specific augmentations generally outperform task-agnostic augmentations. Automatic augmentations based on vectors (GloVe, FastText) perform the worst. We find that systems trained on MIND-CA generalize well to UK-MIND-20. We demonstrate that data augmentation strategies also improve the performance on unseen data.
Reply suggestion models help users process emails and chats faster. Previous work only studies English reply suggestion. Instead, we present MRS, a multilingual reply suggestion dataset with ten languages. MRS can be used to compare two families of models: 1) retrieval models that select the reply from a fixed set and 2) generation models that produce the reply from scratch. Therefore, MRS complements existing cross-lingual generalization benchmarks that focus on classification and sequence labeling tasks. We build a generation model and a retrieval model as baselines for MRS. The two models have different strengths in the monolingual setting, and they require different strategies to generalize across languages. MRS is publicly available at https://github.com/zhangmozhi/mrs.
Crowdsourcing is widely used to create data for common natural language understanding tasks. Despite the importance of these datasets for measuring and refining model understanding of language, there has been little focus on the crowdsourcing methods used for collecting the datasets. In this paper, we compare the efficacy of interventions that have been proposed in prior work as ways of improving data quality. We use multiple-choice question answering as a testbed and run a randomized trial by assigning crowdworkers to write questions under one of four different data collection protocols. We find that asking workers to write explanations for their examples is an ineffective stand-alone strategy for boosting NLU example difficulty. However, we find that training crowdworkers, and then using an iterative process of collecting data, sending feedback, and qualifying workers based on expert judgments is an effective means of collecting challenging data. But using crowdsourced, instead of expert judgments, to qualify workers and send feedback does not prove to be effective. We observe that the data from the iterative protocol with expert assessments is more challenging by several measures. Notably, the human–model gap on the unanimous agreement portion of this data is, on average, twice as large as the gap for the baseline protocol data.
Ideology of legislators is typically estimated by ideal point models from historical records of votes. It represents legislators and legislation as points in a latent space and shows promising results for modeling voting behavior. However, it fails to capture more specific attitudes of legislators toward emerging issues and is unable to model newly-elected legislators without voting histories. In order to mitigate these two problems, we explore to incorporate both voting behavior and public statements on Twitter to jointly model legislators. In addition, we propose a novel task, namely hashtag usage prediction to model the ideology of legislators on Twitter. In practice, we construct a heterogeneous graph for the legislative context and use relational graph neural networks to learn the representation of legislators with the guidance of historical records of their voting and hashtag usage. Experiment results indicate that our model yields significant improvements for the task of roll call vote prediction. Further analysis further demonstrates that legislator representation we learned captures nuances in statements.
Languages are dynamic systems: word usage may change over time, reflecting various societal factors. However, all languages do not evolve identically: the impact of an event, the influence of a trend or thinking, can differ between communities. In this paper, we propose to track these divergences by comparing the evolution of a word and its translation across two languages. We investigate several methods of building time-varying and bilingual word embeddings, using contextualised and non-contextualised embeddings. We propose a set of scenarios to characterize semantic divergence across two languages, along with a setup to differentiate them in a bilingual corpus. We evaluate the different methods by generating a corpus of synthetic semantic change across two languages, English and French, before applying them to newspaper corpora to detect bilingual semantic divergence and provide qualitative insight for the task. We conclude that BERT embeddings coupled with a clustering step lead to the best performance on synthetic corpora; however, the performance of CBOW embeddings is very competitive and more adapted to an exploratory analysis on a large corpus.
Multilingual neural machine translation has shown the capability of directly translating between language pairs unseen in training, i.e. zero-shot translation. Despite being conceptually attractive, it often suffers from low output quality. The difficulty of generalizing to new translation directions suggests the model representations are highly specific to those language pairs seen in training. We demonstrate that a main factor causing the language-specific representations is the positional correspondence to input tokens. We show that this can be easily alleviated by removing residual connections in an encoder layer. With this modification, we gain up to 18.5 BLEU points on zero-shot translation while retaining quality on supervised directions. The improvements are particularly prominent between related languages, where our proposed model outperforms pivot-based translation. Moreover, our approach allows easy integration of new languages, which substantially expands translation coverage. By thorough inspections of the hidden layer outputs, we show that our approach indeed leads to more language-independent representations.
Commonsense reasoning research has so far been limited to English. We aim to evaluate and improve popular multilingual language models (ML-LMs) to help advance commonsense reasoning (CSR) beyond English. We collect the Mickey corpus, consisting of 561k sentences in 11 different languages, which can be used for analyzing and improving ML-LMs. We propose Mickey Probe, a language-general probing task for fairly evaluating the common sense of popular ML-LMs across different languages. In addition, we also create two new datasets, X-CSQA and X-CODAH, by translating their English versions to 14 other languages, so that we can evaluate popular ML-LMs for cross-lingual commonsense reasoning. To improve the performance beyond English, we propose a simple yet effective method — multilingual contrastive pretraining (MCP). It significantly enhances sentence representations, yielding a large performance gain on both benchmarks (e.g., +2.7% accuracy for X-CSQA over XLM-R_L).
Attention mechanisms have achieved substantial improvements in neural machine translation by dynamically selecting relevant inputs for different predictions. However, recent studies have questioned the attention mechanisms’ capability for discovering decisive inputs. In this paper, we propose to calibrate the attention weights by introducing a mask perturbation model that automatically evaluates each input’s contribution to the model outputs. We increase the attention weights assigned to the indispensable tokens, whose removal leads to a dramatic performance decrease. The extensive experiments on the Transformer-based translation have demonstrated the effectiveness of our model. We further find that the calibrated attention weights are more uniform at lower layers to collect multiple information while more concentrated on the specific inputs at higher layers. Detailed analyses also show a great need for calibration in the attention weights with high entropy where the model is unconfident about its decision.
We propose a new architecture for adapting a sentence-level sequence-to-sequence transformer by incorporating multiple pre-trained document context signals and assess the impact on translation performance of (1) different pretraining approaches for generating these signals, (2) the quantity of parallel data for which document context is available, and (3) conditioning on source, target, or source and target contexts. Experiments on the NIST Chinese-English, and IWSLT and WMT English-German tasks support four general conclusions: that using pre-trained context representations markedly improves sample efficiency, that adequate parallel data resources are crucial for learning to use document context, that jointly conditioning on multiple context representations outperforms any single representation, and that source context is more valuable for translation performance than target side context. Our best multi-context model consistently outperforms the best existing context-aware transformers.
Recent research in multilingual language models (LM) has demonstrated their ability to effectively handle multiple languages in a single model. This holds promise for low web-resource languages (LRL) as multilingual models can enable transfer of supervision from high resource languages to LRLs. However, incorporating a new language in an LM still remains a challenge, particularly for languages with limited corpora and in unseen scripts. In this paper we argue that relatedness among languages in a language family may be exploited to overcome some of the corpora limitations of LRLs, and propose RelateLM. We focus on Indian languages, and exploit relatedness along two dimensions: (1) script (since many Indic scripts originated from the Brahmic script), and (2) sentence structure. RelateLM uses transliteration to convert the unseen script of limited LRL text into the script of a Related Prominent Language (RPL) (Hindi in our case). While exploiting similar sentence structures, RelateLM utilizes readily available bilingual dictionaries to pseudo translate RPL text into LRL corpora. Experiments on multiple real-world benchmark datasets provide validation to our hypothesis that using a related language as pivot, along with transliteration and pseudo translation based data augmentation, can be an effective way to adapt LMs for LRLs, rather than direct training or pivoting through English.
The connection between the maximum spanning tree in a directed graph and the best dependency tree of a sentence has been exploited by the NLP community. However, for many dependency parsing schemes, an important detail of this approach is that the spanning tree must have exactly one edge emanating from the root. While work has been done to efficiently solve this problem for finding the one-best dependency tree, no research has attempted to extend this solution to finding the K-best dependency trees. This is arguably a more important extension as a larger proportion of decoded trees will not be subject to the root constraint of dependency trees. Indeed, we show that the rate of root constraint violations increases by an average of 13 times when decoding with K=50 as opposed to K=1. In this paper, we provide a simplification of the K-best spanning tree algorithm of Camerini et al. (1980). Our simplification allows us to obtain a constant time speed-up over the original algorithm. Furthermore, we present a novel extension of the algorithm for decoding the K-best dependency trees of a graph which are subject to a root constraint.
This survey builds an interdisciplinary picture of Argument Mining (AM), with a strong focus on its potential to address issues related to Social and Political Science. More specifically, we focus on AM challenges related to its applications to social media and in the multilingual domain, and then proceed to the widely debated notion of argument quality. We propose a novel definition of argument quality which is integrated with that of deliberative quality from the Social Science literature. Under our definition, the quality of a contribution needs to be assessed at multiple levels: the contribution itself, its preceding context, and the consequential effect on the development of the upcoming discourse. The latter has not received the deserved attention within the community. We finally define an application of AM for Social Good: (semi-)automatic moderation, a highly integrative application which (a) represents a challenging testbed for the integrated notion of quality we advocate, (b) allows the empirical quantification of argument/deliberative quality to benefit from the developments in other NLP fields (i.e. hate speech detection, fact checking, debiasing), and (c) has a clearly beneficial potential at the level of its societal thanks to its real-world application (even if extremely ambitious).
Research on the application of NLP in symbol-based Augmentative and Alternative Communication (AAC) tools for improving social interaction support is scarce. We contribute a novel method for generating context-related vocabulary from photographs of personally relevant events aimed at supporting people with language impairments in retelling their past experiences. Performance was calculated with information retrieval concepts on the relevance of vocabulary generated for communicating a corpus of 9730 narrative phrases about events depicted in 1946 photographs. In comparison to a baseline generation composed of frequent English words, our method generated vocabulary with a 4.6 gain in mean average precision, regardless of the level of contextual information in the input photographs, and 6.9 for photographs in which contextual information was extracted correctly. We conclude by discussing how our findings provide insights for system optimization and usage.
Continuity of care is crucial to ensuring positive health outcomes for patients discharged from an inpatient hospital setting, and improved information sharing can help. To share information, caregivers write discharge notes containing action items to share with patients and their future caregivers, but these action items are easily lost due to the lengthiness of the documents. In this work, we describe our creation of a dataset of clinical action items annotated over MIMIC-III, the largest publicly available dataset of real clinical notes. This dataset, which we call CLIP, is annotated by physicians and covers 718 documents representing 100K sentences. We describe the task of extracting the action items from these documents as multi-aspect extractive summarization, with each aspect representing a type of action to be taken. We evaluate several machine learning models on this task, and show that the best models exploit in-domain language model pre-training on 59K unannotated documents, and incorporate context from neighboring sentences. We also propose an approach to pre-training data selection that allows us to explore the trade-off between size and domain-specificity of pre-training datasets for this task.
Emojis have become ubiquitous in digital communication, due to their visual appeal as well as their ability to vividly convey human emotion, among other factors. This also leads to an increased need for systems and tools to operate on text containing emojis. In this study, we assess this support by considering test sets of tweets with emojis, based on which we perform a series of experiments investigating the ability of prominent NLP and text processing tools to adequately process them. In particular, we consider tokenization, part-of-speech tagging, dependency parsing, as well as sentiment analysis. Our findings show that many systems still have notable shortcomings when operating on text containing emojis.
Natural language processing techniques have demonstrated promising results in keyphrase generation. However, one of the major challenges in neural keyphrase generation is processing long documents using deep neural networks. Generally, documents are truncated before given as inputs to neural networks. Consequently, the models may miss essential points conveyed in the target document. To overcome this limitation, we propose SEG-Net, a neural keyphrase generation model that is composed of two major components, (1) a selector that selects the salient sentences in a document and (2) an extractor-generator that jointly extracts and generates keyphrases from the selected sentences. SEG-Net uses Transformer, a self-attentive architecture, as the basic building block with a novel layer-wise coverage attention to summarize most of the points discussed in the document. The experimental results on seven keyphrase generation benchmarks from scientific and web documents demonstrate that SEG-Net outperforms the state-of-the-art neural generative methods by a large margin.
We propose a method for generating paraphrases of English questions that retain the original intent but use a different surface form. Our model combines a careful choice of training objective with a principled information bottleneck, to induce a latent encoding space that disentangles meaning and form. We train an encoder-decoder model to reconstruct a question from a paraphrase with the same meaning and an exemplar with the same surface form, leading to separated encoding spaces. We use a Vector-Quantized Variational Autoencoder to represent the surface form as a set of discrete latent variables, allowing us to use a classifier to select a different surface form at test time. Crucially, our method does not require access to an external source of target exemplars. Extensive experiments and a human evaluation show that we are able to generate paraphrases with a better tradeoff between semantic preservation and syntactic novelty compared to previous methods.
We present AggGen (pronounced ‘again’) a data-to-text model which re-introduces two explicit sentence planning stages into neural data-to-text systems: input ordering and input aggregation. In contrast to previous work using sentence planning, our model is still end-to-end: AggGen performs sentence planning at the same time as generating text by learning latent alignments (via semantic facts) between input representation and target text. Experiments on the WebNLG and E2E challenge data show that by using fact-based alignments our approach is more interpretable, expressive, robust to noise, and easier to control, while retaining the advantages of end-to-end systems in terms of fluency. Our code is available at https://github.com/XinnuoXu/AggGen.
Publicly available, large pretrained Language Models (LMs) generate text with remarkable quality, but only sequentially from left to right. As a result, they are not immediately applicable to generation tasks that break the unidirectional assumption, such as paraphrasing or text-infilling, necessitating task-specific supervision. In this paper, we present Reflective Decoding, a novel unsupervised algorithm that allows for direct application of unidirectional LMs to non-sequential tasks. Our 2-step approach requires no supervision or even parallel corpora, only two off-the-shelf pretrained LMs in opposite directions: forward and backward. First, in the contextualization step, we use LMs to generate ensembles of past and future contexts which collectively capture the input (e.g. the source sentence for paraphrasing). Second, in the reflection step, we condition on these “context ensembles”, generating outputs that are compatible with them. Comprehensive empirical results demonstrate that Reflective Decoding outperforms strong unsupervised baselines on both paraphrasing and abductive text infilling, significantly narrowing the gap between unsupervised and supervised methods. Reflective Decoding surpasses multiple supervised baselines on various metrics including human evaluation.
Recent neural text generation models have shown significant improvement in generating descriptive text from structured data such as table formats. One of the remaining important challenges is generating more analytical descriptions that can be inferred from facts in a data source. The use of a template-based generator and a pointer-generator is among the potential alternatives for table-to-text generators. In this paper, we propose a framework consisting of a pre-trained model and a copy mechanism. The pre-trained models are fine-tuned to produce fluent text that is enriched with numerical reasoning. However, it still lacks fidelity to the table contents. The copy mechanism is incorporated in the fine-tuning step by using general placeholders to avoid producing hallucinated phrases that are not supported by a table while preserving high fluency. In summary, our contributions are (1) a new dataset for numerical table-to-text generation using pairs of a table and a paragraph of a table description with richer inference from scientific papers, and (2) a table-to-text generation framework enriched with numerical reasoning.
In this paper, we focus on the problem of citing sentence generation, which entails generating a short text to capture the salient information in a cited paper and the connection between the citing and cited paper. We present BACO, a BAckground knowledge- and COntent-based framework for citing sentence generation, which considers two types of information: (1) background knowledge by leveraging structural information from a citation network; and (2) content, which represents in-depth information about what to cite and why to cite. First, a citation network is encoded to provide background knowledge. Second, we apply salience estimation to identify what to cite by estimating the importance of sentences in the cited paper. During the decoding stage, both types of information are combined to facilitate the text generation, and then we conduct a joint training for the generator and citation function classification to make the model aware of why to cite. Our experimental results show that our framework outperforms comparative baselines.
Current dialogue summarization systems usually encode the text with a number of general semantic features (e.g., keywords and topics) to gain more powerful dialogue modeling capabilities. However, these features are obtained via open-domain toolkits that are dialog-agnostic or heavily relied on human annotations. In this paper, we show how DialoGPT, a pre-trained model for conversational response generation, can be developed as an unsupervised dialogue annotator, which takes advantage of dialogue background knowledge encoded in DialoGPT. We apply DialoGPT to label three types of features on two dialogue summarization datasets, SAMSum and AMI, and employ pre-trained and non pre-trained models as our summarizers. Experimental results show that our proposed method can obtain remarkable improvements on both datasets and achieves new state-of-the-art performance on the SAMSum dataset.
Recent pretrained language models “solved” many reading comprehension benchmarks, where questions are written with access to the evidence document. However, datasets containing information-seeking queries where evidence documents are provided after the queries are written independently remain challenging. We analyze why answering information-seeking queries is more challenging and where their prevalent unanswerabilities arise, on Natural Questions and TyDi QA. Our controlled experiments suggest two headrooms – paragraph selection and answerability prediction, i.e. whether the paired evidence document contains the answer to the query or not. When provided with a gold paragraph and knowing when to abstain from answering, existing models easily outperform a human annotator. However, predicting answerability itself remains challenging. We manually annotate 800 unanswerable examples across six languages on what makes them challenging to answer. With this new data, we conduct per-category answerability prediction, revealing issues in the current dataset collection as well as task formulation. Together, our study points to avenues for future research in information-seeking question answering, both for dataset creation and model development. Our code and annotated data is publicly available at https://github.com/AkariAsai/unanswerable_qa.
Users of medical question answering systems often submit long and detailed questions, making it hard to achieve high recall in answer retrieval. To alleviate this problem, we propose a novel Multi-Task Learning (MTL) method with data augmentation for medical question understanding. We first establish an equivalence between the tasks of question summarization and Recognizing Question Entailment (RQE) using their definitions in the medical domain. Based on this equivalence, we propose a data augmentation algorithm to use just one dataset to optimize for both tasks, with a weighted MTL loss. We introduce gradually soft parameter-sharing: a constraint for decoder parameters to be close, that is gradually loosened as we move to the highest layer. We show through ablation studies that our proposed novelties improve performance. Our method outperforms existing MTL methods across 4 datasets of medical question pairs, in ROUGE scores, RQE accuracy and human evaluation. Finally, we show that our method fares better than single-task learning under 4 low-resource settings.
A common issue in real-world applications of named entity recognition and classification (NERC) is the absence of annotated data for the target entity classes during training. Zero-shot learning approaches address this issue by learning models from classes with training data that can predict classes without it. This paper presents the first approach for zero-shot NERC, introducing novel architectures that leverage the fact that textual descriptions for many entity classes occur naturally. We address the zero-shot NERC specific challenge that the not-an-entity class is not well defined as different entity classes are considered in training and testing. For evaluation, we adapt two datasets, OntoNotes and MedMentions, emulating the difficulty of real-world zero-shot learning by testing models on the rarest entity classes. Our proposed approach outperforms baselines adapted from machine reading comprehension and zero-shot text classification. Furthermore, we assess the effect of different class descriptions for this task.
Recently, word enhancement has become very popular for Chinese Named Entity Recognition (NER), reducing segmentation errors and increasing the semantic and boundary information of Chinese words. However, these methods tend to ignore the information of the Chinese character structure after integrating the lexical information. Chinese characters have evolved from pictographs since ancient times, and their structure often reflects more information about the characters. This paper presents a novel Multi-metadata Embedding based Cross-Transformer (MECT) to improve the performance of Chinese NER by fusing the structural information of Chinese characters. Specifically, we use multi-metadata embedding in a two-stream Transformer to integrate Chinese character features with the radical-level embedding. With the structural characteristics of Chinese characters, MECT can better capture the semantic information of Chinese characters for NER. The experimental results obtained on several well-known benchmarking datasets demonstrate the merits and superiority of the proposed MECT method.
As the sources of information that we consume everyday rapidly diversify, it is becoming increasingly important to develop NLP tools that help to evaluate the credibility of the information we receive. A critical step towards this goal is to determine the factuality of events in text. In this paper, we frame factuality assessment as a modal dependency parsing task that identifies the events and their sources, formally known as conceivers, and then determine the level of certainty that the sources are asserting with respect to the events. We crowdsource the first large-scale data set annotated with modal dependency structures that consists of 353 Covid-19 related news articles, 24,016 events, and 2,938 conceivers. We also develop the first modal dependency parser that jointly extracts events, conceivers and constructs the modal dependency structure of a text. We evaluate the joint model against a pipeline model and demonstrate the advantage of the joint model in conceiver extraction and modal dependency structure construction when events and conceivers are automatically extracted. We believe the dataset and the models will be a valuable resource for a whole host of NLP applications such as fact checking and rumor detection.
The modeling of conversational context plays a vital role in emotion recognition from conversation (ERC). In this paper, we put forward a novel idea of encoding the utterances with a directed acyclic graph (DAG) to better model the intrinsic structure within a conversation, and design a directed acyclic neural network, namely DAG-ERC, to implement this idea. In an attempt to combine the strengths of conventional graph-based neural models and recurrence-based neural models, DAG-ERC provides a more intuitive way to model the information flow between long-distance conversation background and nearby context. Extensive experiments are conducted on four ERC benchmarks with state-of-the-art models employed as baselines for comparison. The empirical results demonstrate the superiority of this new model and confirm the motivation of the directed acyclic graph architecture for ERC.
Models pre-trained on large-scale regular text corpora often do not work well for user-generated data where the language styles differ significantly from the mainstream text. Here we present Context-Aware Rule Injection (CARI), an innovative method for formality style transfer (FST) by injecting multiple rules into an end-to-end BERT-based encoder and decoder model. CARI is able to learn to select optimal rules based on context. The intrinsic evaluation showed that CARI achieved the new highest performance on the FST benchmark dataset. Our extrinsic evaluation showed that CARI can greatly improve the regular pre-trained models’ performance on several tweet sentiment analysis tasks. Our contributions are as follows: 1.We propose a new method, CARI, to integrate rules for pre-trained language models. CARI is context-aware and can trained end-to-end with the downstream NLP applications. 2.We have achieved new state-of-the-art results for FST on the benchmark GYAFC dataset. 3.We are the first to evaluate FST methods with extrinsic evaluation and specifically on sentiment classification tasks. We show that CARI outperformed existing rule-based FST approaches for sentiment classification.
Emotion detection in dialogues is challenging as it often requires the identification of thematic topics underlying a conversation, the relevant commonsense knowledge, and the intricate transition patterns between the affective states. In this paper, we propose a Topic-Driven Knowledge-Aware Transformer to handle the challenges above. We firstly design a topic-augmented language model (LM) with an additional layer specialized for topic detection. The topic-augmented LM is then combined with commonsense statements derived from a knowledge base based on the dialogue contextual information. Finally, a transformer-based encoder-decoder architecture fuses the topical and commonsense information, and performs the emotion label sequence prediction. The model has been experimented on four datasets in dialogue emotion detection, demonstrating its superiority empirically over the existing state-of-the-art approaches. Quantitative and qualitative results show that the model can discover topics which help in distinguishing emotion categories.
Approaches to computational argumentation tasks such as stance detection and aspect detection have largely focused on the text of independent claims, losing out on potentially valuable context provided by the rest of the collection. We introduce a general approach to these tasks motivated by syntopical reading, a reading process that emphasizes comparing and contrasting viewpoints in order to improve topic understanding. To capture collection-level context, we introduce the syntopical graph, a data structure for linking claims within a collection. A syntopical graph is a typed multi-graph where nodes represent claims and edges represent different possible pairwise relationships, such as entailment, paraphrase, or support. Experiments applying syntopical graphs to the problems of detecting stance and aspects demonstrate state-of-the-art performance in each domain, significantly outperforming approaches that do not utilize collection-level information.
The prevalence of the COVID-19 pandemic in day-to-day life has yielded large amounts of stance detection data on social media sites, as users turn to social media to share their views regarding various issues related to the pandemic, e.g. stay at home mandates and wearing face masks when out in public. We set out to make use of this data by collecting the stance expressed by Twitter users, with respect to topics revolving around the pandemic. We annotate a new stance detection dataset, called COVID-19-Stance. Using this newly annotated dataset, we train several established stance detection models to ascertain a baseline performance for this specific task. To further improve the performance, we employ self-training and domain adaptation approaches to take advantage of large amounts of unlabeled data and existing stance detection datasets. The dataset, code, and other resources are available on GitHub.
Fact verification is a challenging task that requires simultaneously reasoning and aggregating over multiple retrieved pieces of evidence to evaluate the truthfulness of a claim. Existing approaches typically (i) explore the semantic interaction between the claim and evidence at different granularity levels but fail to capture their topical consistency during the reasoning process, which we believe is crucial for verification; (ii) aggregate multiple pieces of evidence equally without considering their implicit stances to the claim, thereby introducing spurious information. To alleviate the above issues, we propose a novel topic-aware evidence reasoning and stance-aware aggregation model for more accurate fact verification, with the following four key properties: 1) checking topical consistency between the claim and evidence; 2) maintaining topical coherence among multiple pieces of evidence; 3) ensuring semantic similarity between the global topic information and the semantic representation of evidence; 4) aggregating evidence based on their implicit stances to the claim. Extensive experiments conducted on the two benchmark datasets demonstrate the superiority of the proposed model over several state-of-the-art approaches for fact verification. The source code can be obtained from https://github.com/jasenchn/TARSA.
We introduce the well-established social scientific concept of social solidarity and its contestation, anti-solidarity, as a new problem setting to supervised machine learning in NLP to assess how European solidarity discourses changed before and after the COVID-19 outbreak was declared a global pandemic. To this end, we annotate 2.3k English and German tweets for (anti-)solidarity expressions, utilizing multiple human annotators and two annotation approaches (experts vs. crowds). We use these annotations to train a BERT model with multiple data augmentation strategies. Our augmented BERT model that combines both expert and crowd annotations outperforms the baseline BERT classifier trained with expert annotations only by over 25 points, from 58% macro-F1 to almost 85%. We use this high-quality model to automatically label over 270k tweets between September 2019 and December 2020. We then assess the automatically labeled data for how statements related to European (anti-)solidarity discourses developed over time and in relation to one another, before and during the COVID-19 crisis. Our results show that solidarity became increasingly salient and contested during the crisis. While the number of solidarity tweets remained on a higher level and dominated the discourse in the scrutinized time frame, anti-solidarity tweets initially spiked, then decreased to (almost) pre-COVID-19 values before rising to a stable higher level until the end of 2020.
In conversation, uptake happens when a speaker builds on the contribution of their interlocutor by, for example, acknowledging, repeating or reformulating what they have said. In education, teachers’ uptake of student contributions has been linked to higher student achievement. Yet measuring and improving teachers’ uptake at scale is challenging, as existing methods require expensive annotation by experts. We propose a framework for computationally measuring uptake, by (1) releasing a dataset of student-teacher exchanges extracted from US math classroom transcripts annotated for uptake by experts; (2) formalizing uptake as pointwise Jensen-Shannon Divergence (pJSD), estimated via next utterance classification; (3) conducting a linguistically-motivated comparison of different unsupervised measures and (4) correlating these measures with educational outcomes. We find that although repetition captures a significant part of uptake, pJSD outperforms repetition-based baselines, as it is capable of identifying a wider range of uptake phenomena like question answering and reformulation. We apply our uptake measure to three different educational datasets with outcome indicators. Unlike baseline measures, pJSD correlates significantly with instruction quality in all three, providing evidence for its generalizability and for its potential to serve as an automated professional development tool for teachers.
The analysis of data in which multiple languages are represented has gained popularity among computational linguists in recent years. So far, much of this research focuses mainly on the improvement of computational methods and largely ignores linguistic and social aspects of C-S discussed across a wide range of languages within the long-established literature in linguistics. To fill this gap, we offer a survey of code-switching (C-S) covering the literature in linguistics with a reflection on the key issues in language technologies. From the linguistic perspective, we provide an overview of structural and functional patterns of C-S focusing on the literature from European and Indian contexts as highly multilingual areas. From the language technologies perspective, we discuss how massive language models fail to represent diverse C-S types due to lack of appropriate training data, lack of robust evaluation benchmarks for C-S (across multilingual situations and types of C-S) and lack of end-to- end systems that cover sociolinguistic aspects of C-S as well. Our survey will be a step to- wards an outcome of mutual benefit for computational scientists and linguists with a shared interest in multilingualism and C-S.
We present a human-and-model-in-the-loop process for dynamically generating datasets and training better performing and more robust hate detection models. We provide a new dataset of 40,000 entries, generated and labelled by trained annotators over four rounds of dynamic data creation. It includes 15,000 challenging perturbations and each hateful entry has fine-grained labels for the type and target of hate. Hateful entries make up 54% of the dataset, which is substantially higher than comparable datasets. We show that model performance is substantially improved using this approach. Models trained on later rounds of data collection perform better on test sets and are harder for annotators to trick. They also have better performance on HateCheck, a suite of functional tests for online hate detection. We provide the code, dataset and annotation guidelines for other researchers to use.
To defend against machine-generated fake news, an effective mechanism is urgently needed. We contribute a novel benchmark for fake news detection at the knowledge element level, as well as a solution for this task which incorporates cross-media consistency checking to detect the fine-grained knowledge elements making news articles misinformative. Due to training data scarcity, we also formulate a novel data synthesis method by manipulating knowledge elements within the knowledge graph to generate noisy training data with specific, hard to detect, known inconsistencies. Our detection approach outperforms the state-of-the-art (up to 16.8% accuracy gain), and more critically, yields fine-grained explanations.
To quantify how well natural language understanding models can capture consistency in a general conversation, we introduce the DialoguE COntradiction DEtection task (DECODE) and a new conversational dataset containing both human-human and human-bot contradictory dialogues. We show that: (i) our newly collected dataset is notably more effective at providing supervision for the dialogue contradiction detection task than existing NLI data including those aimed to cover the dialogue domain; (ii) Transformer models that explicitly hinge on utterance structures for dialogue contradiction detection are more robust and generalize well on both analysis and out-of-distribution dialogues than standard (unstructured) Transformers. We also show that our best contradiction detection model correlates well with human judgments and further provide evidence for its usage in both automatically evaluating and improving the consistency of state-of-the-art generative chatbots.
This paper is concerned with dialogue state tracking (DST) in a task-oriented dialogue system. Building a DST module that is highly effective is still a challenging issue, although significant progresses have been made recently. This paper proposes a new approach to dialogue state tracking, referred to as Seq2Seq-DU, which formalizes DST as a sequence-to-sequence problem. Seq2Seq-DU employs two BERT-based encoders to respectively encode the utterances in the dialogue and the descriptions of schemas, an attender to calculate attentions between the utterance embeddings and the schema embeddings, and a decoder to generate pointers to represent the current state of dialogue. Seq2Seq-DU has the following advantages. It can jointly model intents, slots, and slot values; it can leverage the rich representations of utterances and schemas based on BERT; it can effectively deal with categorical and non-categorical slots, and unseen schemas. In addition, Seq2Seq-DU can also be used in the NLU (natural language understanding) module of a dialogue system. Experimental results on benchmark datasets in different settings (SGD, MultiWOZ2.2, MultiWOZ2.1, WOZ2.0, DSTC2, M2M, SNIPS, and ATIS) show that Seq2Seq-DU outperforms the existing methods.
Learning discrete dialog structure graph from human-human dialogs yields basic insights into the structure of conversation, and also provides background knowledge to facilitate dialog generation. However, this problem is less studied in open-domain dialogue. In this paper, we conduct unsupervised discovery of discrete dialog structure from chitchat corpora, and then leverage it to facilitate coherent dialog generation in downstream systems. To this end, we present an unsupervised model, Discrete Variational Auto-Encoder with Graph Neural Network (DVAE-GNN), to discover discrete hierarchical latent dialog states (at the level of both session and utterance) and their transitions from corpus as a dialog structure graph. Then we leverage it as background knowledge to facilitate dialog management in a RL based dialog system. Experimental results on two benchmark corpora confirm that DVAE-GNN can discover meaningful dialog structure graph, and the use of dialog structure as background knowledge can significantly improve multi-turn coherence.
We study the learning of a matching model for dialogue response selection. Motivated by the recent finding that models trained with random negative samples are not ideal in real-world scenarios, we propose a hierarchical curriculum learning framework that trains the matching model in an “easy-to-difficult” scheme. Our learning framework consists of two complementary curricula: (1) corpus-level curriculum (CC); and (2) instance-level curriculum (IC). In CC, the model gradually increases its ability in finding the matching clues between the dialogue context and a response candidate. As for IC, it progressively strengthens the model’s ability in identifying the mismatching information between the dialogue context and a response candidate. Empirical studies on three benchmark datasets with three state-of-the-art matching models demonstrate that the proposed learning framework significantly improves the model performance across various evaluation metrics.
In this paper, we present a neural model for joint dropped pronoun recovery (DPR) and conversational discourse parsing (CDP) in Chinese conversational speech. We show that DPR and CDP are closely related, and a joint model benefits both tasks. We refer to our model as DiscProReco, and it first encodes the tokens in each utterance in a conversation with a directed Graph Convolutional Network (GCN). The token states for an utterance are then aggregated to produce a single state for each utterance. The utterance states are then fed into a biaffine classifier to construct a conversational discourse graph. A second (multi-relational) GCN is then applied to the utterance states to produce a discourse relation-augmented representation for the utterances, which are then fused together with token states in each utterance as input to a dropped pronoun recovery layer. The joint model is trained and evaluated on a new Structure Parsing-enhanced Dropped Pronoun Recovery (SPDPR) data set that we annotated with both two types of information. Experimental results on the SPDPR dataset and other benchmarks show that DiscProReco significantly outperforms the state-of-the-art baselines of both tasks.
Knowledge bases (KBs) and text often contain complementary knowledge: KBs store structured knowledge that can support long range reasoning, while text stores more comprehensive and timely knowledge in an unstructured way. Separately embedding the individual knowledge sources into vector spaces has demonstrated tremendous successes in encoding the respective knowledge, but how to jointly embed and reason with both knowledge sources to fully leverage the complementary information is still largely an open problem. We conduct a large-scale, systematic investigation of aligning KB and text embeddings for joint reasoning. We set up a novel evaluation framework with two evaluation tasks, few-shot link prediction and analogical reasoning, and evaluate an array of KB-text embedding alignment methods. We also demonstrate how such alignment can infuse textual information into KB embeddings for more accurate link prediction on emerging entities and events, using COVID-19 as a case study.
Weak supervision has shown promising results in many natural language processing tasks, such as Named Entity Recognition (NER). Existing work mainly focuses on learning deep NER models only with weak supervision, i.e., without any human annotation, and shows that by merely using weakly labeled data, one can achieve good performance, though still underperforms fully supervised NER with manually/strongly labeled data. In this paper, we consider a more practical scenario, where we have both a small amount of strongly labeled data and a large amount of weakly labeled data. Unfortunately, we observe that weakly labeled data does not necessarily improve, or even deteriorate the model performance (due to the extensive noise in the weak labels) when we train deep NER models over a simple or weighted combination of the strongly labeled and weakly labeled data. To address this issue, we propose a new multi-stage computational framework – NEEDLE with three essential ingredients: (1) weak label completion, (2) noise-aware loss function, and (3) final fine-tuning over the strongly labeled data. Through experiments on E-commerce query NER and Biomedical NER, we demonstrate that NEEDLE can effectively suppress the noise of the weak labels and outperforms existing methods. In particular, we achieve new SOTA F1-scores on 3 Biomedical NER datasets: BC5CDR-chem 93.74, BC5CDR-disease 90.69, NCBI-disease 92.28.
Recently, there is an effort to extend fine-grained entity typing by using a richer and ultra-fine set of types, and labeling noun phrases including pronouns and nominal nouns instead of just named entity mentions. A key challenge for this ultra-fine entity typing task is that human annotated data are extremely scarce, and the annotation ability of existing distant or weak supervision approaches is very limited. To remedy this problem, in this paper, we propose to obtain training data for ultra-fine entity typing by using a BERT Masked Language Model (MLM). Given a mention in a sentence, our approach constructs an input for the BERT MLM so that it predicts context dependent hypernyms of the mention, which can be used as type labels. Experimental results demonstrate that, with the help of these automatically generated labels, the performance of an ultra-fine entity typing model can be improved substantially. We also show that our approach can be applied to improve traditional fine-grained entity typing after performing simple type mapping.
Recent advances in Named Entity Recognition (NER) show that document-level contexts can significantly improve model performance. In many application scenarios, however, such contexts are not available. In this paper, we propose to find external contexts of a sentence by retrieving and selecting a set of semantically relevant texts through a search engine, with the original sentence as the query. We find empirically that the contextual representations computed on the retrieval-based input view, constructed through the concatenation of a sentence and its external contexts, can achieve significantly improved performance compared to the original input view based only on the sentence. Furthermore, we can improve the model performance of both input views by Cooperative Learning, a training method that encourages the two input views to produce similar contextual representations or output label distributions. Experiments show that our approach can achieve new state-of-the-art performance on 8 NER data sets across 5 domains.
Does the effectiveness of neural language models derive entirely from accurate modeling of surface word co-occurrence statistics, or do these models represent and reason about the world they describe? In BART and T5 transformer language models, we identify contextual word representations that function as *models of entities and situations* as they evolve throughout a discourse. These neural representations have functional similarities to linguistic models of dynamic semantics: they support a linear readout of each entity’s current properties and relations, and can be manipulated with predictable effects on language generation. Our results indicate that prediction in pretrained neural language models is supported, at least in part, by dynamic representations of meaning and implicit simulation of entity state, and that this behavior can be learned with only text as training data.
Targeted syntactic evaluations have demonstrated the ability of language models to perform subject-verb agreement given difficult contexts. To elucidate the mechanisms by which the models accomplish this behavior, this study applies causal mediation analysis to pre-trained neural language models. We investigate the magnitude of models’ preferences for grammatical inflections, as well as whether neurons process subject-verb agreement similarly across sentences with different syntactic structures. We uncover similarities and differences across architectures and model sizes—notably, that larger models do not necessarily learn stronger preferences. We also observe two distinct mechanisms for producing subject-verb agreement depending on the syntactic structure of the input sentence. Finally, we find that language models rely on similar sets of neurons when given sentences with similar syntactic structure.
NLP has a rich history of representing our prior understanding of language in the form of graphs. Recent work on analyzing contextualized text representations has focused on hand-designed probe models to understand how and to what extent do these representations encode a particular linguistic phenomenon. However, due to the inter-dependence of various phenomena and randomness of training probe models, detecting how these representations encode the rich information in these linguistic graphs remains a challenging problem. In this paper, we propose a new information-theoretic probe, Bird’s Eye, which is a fairly simple probe method for detecting if and how these representations encode the information in these linguistic graphs. Instead of using model performance, our probe takes an information-theoretic view of probing and estimates the mutual information between the linguistic graph embedded in a continuous space and the contextualized word representations. Furthermore, we also propose an approach to use our probe to investigate localized linguistic information in the linguistic graphs using perturbation analysis. We call this probing setup Worm’s Eye. Using these probes, we analyze the BERT models on its ability to encode a syntactic and a semantic graph structure, and find that these models encode to some degree both syntactic as well as semantic information; albeit syntactic information to a greater extent.
Previous literatures show that pre-trained masked language models (MLMs) such as BERT can achieve competitive factual knowledge extraction performance on some datasets, indicating that MLMs can potentially be a reliable knowledge source. In this paper, we conduct a rigorous study to explore the underlying predicting mechanisms of MLMs over different extraction paradigms. By investigating the behaviors of MLMs, we find that previous decent performance mainly owes to the biased prompts which overfit dataset artifacts. Furthermore, incorporating illustrative cases and external contexts improve knowledge prediction mainly due to entity type guidance and golden answer leakage. Our findings shed light on the underlying predicting mechanisms of MLMs, and strongly question the previous conclusion that current MLMs can potentially serve as reliable factual knowledge bases.
We study the problem of generating data poisoning attacks against Knowledge Graph Embedding (KGE) models for the task of link prediction in knowledge graphs. To poison KGE models, we propose to exploit their inductive abilities which are captured through the relationship patterns like symmetry, inversion and composition in the knowledge graph. Specifically, to degrade the model’s prediction confidence on target facts, we propose to improve the model’s prediction confidence on a set of decoy facts. Thus, we craft adversarial additions that can improve the model’s prediction confidence on decoy facts through different inference patterns. Our experiments demonstrate that the proposed poisoning attacks outperform state-of-art baselines on four KGE models for two publicly available datasets. We also find that the symmetry pattern based attacks generalize across all model-dataset combinations which indicates the sensitivity of KGE models to this pattern.
A common factor in bias measurement methods is the use of hand-curated seed lexicons, but there remains little guidance for their selection. We gather seeds used in prior work, documenting their common sources and rationales, and in case studies of three English-language corpora, we enumerate the different types of social biases and linguistic features that, once encoded in the seeds, can affect subsequent bias measurements. Seeds developed in one context are often re-used in other contexts, but documentation and evaluation remain necessary precursors to relying on seeds for sensitive measurements.
Despite inextricable ties between race and language, little work has considered race in NLP research and development. In this work, we survey 79 papers from the ACL anthology that mention race. These papers reveal various types of race-related bias in all stages of NLP model development, highlighting the need for proactive consideration of how NLP systems can uphold racial hierarchies. However, persistent gaps in research on race and NLP remain: race has been siloed as a niche topic and remains ignored in many NLP tasks; most work operationalizes race as a fixed single-dimensional variable with a ground-truth label, which risks reinforcing differences produced by historical racism; and the voices of historically marginalized people are nearly absent in NLP literature. By identifying where and how NLP literature has and has not considered race, especially in comparison to related fields, our work calls for inclusion and racial justice in NLP research practices.
Natural Language Processing (NLP) systems learn harmful societal biases that cause them to amplify inequality as they are deployed in more and more situations. To guide efforts at debiasing these systems, the NLP community relies on a variety of metrics that quantify bias in models. Some of these metrics are intrinsic, measuring bias in word embedding spaces, and some are extrinsic, measuring bias in downstream tasks that the word embeddings enable. Do these intrinsic and extrinsic metrics correlate with each other? We compare intrinsic and extrinsic metrics across hundreds of trained models covering different tasks and experimental conditions. Our results show no reliable correlation between these metrics that holds in all scenarios across tasks and languages. We urge researchers working on debiasing to focus on extrinsic measures of bias, and to make using these measures more feasible via creation of new challenge sets and annotated test data. To aid this effort, we release code, a new intrinsic metric, and an annotated test set focused on gender bias in hate speech.
Text representation models are prone to exhibit a range of societal biases, reflecting the non-controlled and biased nature of the underlying pretraining data, which consequently leads to severe ethical issues and even bias amplification. Recent work has predominantly focused on measuring and mitigating bias in pretrained language models. Surprisingly, the landscape of bias measurements and mitigation resources and methods for conversational language models is still very scarce: it is limited to only a few types of bias, artificially constructed resources, and completely ignores the impact that debiasing methods may have on the final perfor mance in dialog tasks, e.g., conversational response generation. In this work, we present REDDITBIAS, the first conversational data set grounded in the actual human conversations from Reddit, allowing for bias measurement and mitigation across four important bias dimensions: gender,race,religion, and queerness. Further, we develop an evaluation framework which simultaneously 1)measures bias on the developed REDDITBIAS resource, and 2)evaluates model capability in dialog tasks after model debiasing. We use the evaluation framework to benchmark the widely used conversational DialoGPT model along with the adaptations of four debiasing methods. Our results indicate that DialoGPT is biased with respect to religious groups and that some debiasing techniques can remove this bias while preserving downstream task performance.
This paper studies the relative importance of attention heads in Transformer-based models to aid their interpretability in cross-lingual and multi-lingual tasks. Prior research has found that only a few attention heads are important in each mono-lingual Natural Language Processing (NLP) task and pruning the remaining heads leads to comparable or improved performance of the model. However, the impact of pruning attention heads is not yet clear in cross-lingual and multi-lingual tasks. Through extensive experiments, we show that (1) pruning a number of attention heads in a multi-lingual Transformer-based model has, in general, positive effects on its performance in cross-lingual and multi-lingual tasks and (2) the attention heads to be pruned can be ranked using gradients and identified with a few trial experiments. Our experiments focus on sequence labeling tasks, with potential applicability on other cross-lingual and multi-lingual tasks. For comprehensiveness, we examine two pre-trained multi-lingual models, namely multi-lingual BERT (mBERT) and XLM-R, on three tasks across 9 languages each. We also discuss the validity of our findings and their extensibility to truly resource-scarce languages and other task settings.
Effective adversary generation for neural machine translation (NMT) is a crucial prerequisite for building robust machine translation systems. In this work, we investigate veritable evaluations of NMT adversarial attacks, and propose a novel method to craft NMT adversarial examples. We first show the current NMT adversarial attacks may be improperly estimated by the commonly used mono-directional translation, and we propose to leverage the round-trip translation technique to build valid metrics for evaluating NMT adversarial attacks. Our intuition is that an effective NMT adversarial example, which imposes minor shifting on the source and degrades the translation dramatically, would naturally lead to a semantic-destroyed round-trip translation result. We then propose a promising black-box attack method called Word Saliency speedup Local Search (WSLS) that could effectively attack the mainstream NMT architectures. Comprehensive experiments demonstrate that the proposed metrics could accurately evaluate the attack effectiveness, and the proposed WSLS could significantly break the state-of-art NMT models with small perturbation. Besides, WSLS exhibits strong transferability on attacking Baidu and Bing online translators.
Transfer learning has yielded state-of-the-art (SoTA) results in many supervised NLP tasks. However, annotated data for every target task in every target language is rare, especially for low-resource languages. We propose UXLA, a novel unsupervised data augmentation framework for zero-resource transfer learning scenarios. In particular, UXLA aims to solve cross-lingual adaptation problems from a source language task distribution to an unknown target language task distribution, assuming no training label in the target language. At its core, UXLA performs simultaneous self-training with data augmentation and unsupervised sample selection. To show its effectiveness, we conduct extensive experiments on three diverse zero-resource cross-lingual transfer tasks. UXLA achieves SoTA results in all the tasks, outperforming the baselines by a good margin. With an in-depth framework dissection, we demonstrate the cumulative contributions of different components to its success.
Recent work on non-autoregressive neural machine translation (NAT) aims at improving the efficiency by parallel decoding without sacrificing the quality. However, existing NAT methods are either inferior to Transformer or require multiple decoding passes, leading to reduced speedup. We propose the Glancing Language Model (GLM) for single-pass parallel generation models. With GLM, we develop Glancing Transformer (GLAT) for machine translation. With only single-pass parallel decoding, GLAT is able to generate high-quality translation with 8×-15× speedup. Note that GLAT does not modify the network architecture, which is a training method to learn word interdependency. Experiments on multiple WMT language directions show that GLAT outperforms all previous single pass non-autoregressive methods, and is nearly comparable to Transformer, reducing the gap to 0.25-0.9 BLEU points.
Dense video event captioning aims to generate a sequence of descriptive captions for each event in a long untrimmed video. Video-level context provides important information and facilities the model to generate consistent and less redundant captions between events. In this paper, we introduce a novel Hierarchical Context-aware Network for dense video event captioning (HCN) to capture context from various aspects. In detail, the model leverages local and global context with different mechanisms to jointly learn to generate coherent captions. The local context module performs full interaction between neighbor frames and the global context module selectively attends to previous or future events. According to our extensive experiment on both Youcook2 and Activitynet Captioning datasets, the video-level HCN model outperforms the event-level context-agnostic model by a large margin. The code is available at https://github.com/KirkGuo/HCN.
Generating image captions with user intention is an emerging need. The recently published Localized Narratives dataset takes mouse traces as another input to the image captioning task, which is an intuitive and efficient way for a user to control what to describe in the image. However, how to effectively employ traces to improve generation quality and controllability is still under exploration. This paper aims to solve this problem by proposing a novel model called LoopCAG, which connects Contrastive constraints and Attention Guidance in a Loop manner, engaged explicit spatial and temporal constraints to the generating process. Precisely, each generated sentence is temporally aligned to the corresponding trace sequence through a contrastive learning strategy. Besides, each generated text token is supervised to attend to the correct visual objects under heuristic spatial attention guidance. Comprehensive experimental results demonstrate that our LoopCAG model learns better correspondence among the three modalities (vision, language, and traces) and achieves SOTA performance on trace-controlled image captioning task. Moreover, the controllability and explainability of LoopCAG are validated by analyzing spatial and temporal sensitivity during the generation process.
Understanding manipulated media, from automatically generated ‘deepfakes’ to manually edited ones, raises novel research challenges. Because the vast majority of edited or manipulated images are benign, such as photoshopped images for visual enhancements, the key challenge is to understand the complex layers of underlying intents of media edits and their implications with respect to disinformation. In this paper, we study Edited Media Frames, a new formalism to understand visual media manipulation as structured annotations with respect to the intents, emotional reactions, attacks on individuals, and the overall implications of disinformation. We introduce a dataset for our task, EMU, with 56k question-answer pairs written in rich natural language. We evaluate a wide variety of vision-and-language models for our task, and introduce a new model PELICAN, which builds upon recent progress in pretrained multimodal representations. Our model obtains promising results on our dataset, with humans rating its answers as accurate 48.2% of the time. At the same time, there is still much work to be done – and we provide analysis that highlights areas for further progress.
We propose PIGLeT: a model that learns physical commonsense knowledge through interaction, and then uses this knowledge to ground language. We factorize PIGLeT into a physical dynamics model, and a separate language model. Our dynamics model learns not just what objects are but also what they do: glass cups break when thrown, plastic ones don’t. We then use it as the interface to our language model, giving us a unified model of linguistic form and grounded meaning. PIGLeT can read a sentence, simulate neurally what might happen next, and then communicate that result through a literal symbolic representation, or natural language. Experimental results show that our model effectively learns world dynamics, along with how to communicate them. It is able to correctly forecast what happens next given an English sentence over 80% of the time, outperforming a 100x larger, text-to-text approach by over 10%. Likewise, its natural language summaries of physical interactions are also judged by humans as more accurate than LM alternatives. We present comprehensive analysis showing room for future work.
Neural entity typing models typically represent fine-grained entity types as vectors in a high-dimensional space, but such spaces are not well-suited to modeling these types’ complex interdependencies. We study the ability of box embeddings, which embed concepts as d-dimensional hyperrectangles, to capture hierarchies of types even when these relationships are not defined explicitly in the ontology. Our model represents both types and entity mentions as boxes. Each mention and its context are fed into a BERT-based model to embed that mention in our box space; essentially, this model leverages typological clues present in the surface text to hypothesize a type representation for the mention. Box containment can then be used to derive both the posterior probability of a mention exhibiting a given type and the conditional probability relations between types themselves. We compare our approach with a vector-based typing model and observe state-of-the-art performance on several entity typing benchmarks. In addition to competitive typing performance, our box-based model shows better performance in prediction consistency (predicting a supertype and a subtype together) and confidence (i.e., calibration), demonstrating that the box-based model captures the latent type hierarchies better than the vector-based model does.
Recent pretraining models in Chinese neglect two important aspects specific to the Chinese language: glyph and pinyin, which carry significant syntax and semantic information for language understanding. In this work, we propose ChineseBERT, which incorporates both the glyph and pinyin information of Chinese characters into language model pretraining. The glyph embedding is obtained based on different fonts of a Chinese character, being able to capture character semantics from the visual features, and the pinyin embedding characterizes the pronunciation of Chinese characters, which handles the highly prevalent heteronym phenomenon in Chinese (the same character has different pronunciations with different meanings). Pretrained on large-scale unlabeled Chinese corpus, the proposed ChineseBERT model yields significant performance boost over baseline models with fewer training steps. The proposed model achieves new SOTA performances on a wide range of Chinese NLP tasks, including machine reading comprehension, natural language inference, text classification, sentence pair matching, and competitive performances in named entity recognition and word segmentation.
Knowledge distillation has been proven to be effective in model acceleration and compression. It transfers knowledge from a large neural network to a small one by using the large neural network predictions as targets of the small neural network. But this way ignores the knowledge inside the large neural networks, e.g., parameters. Our preliminary study as well as the recent success in pre-training suggests that transferring parameters are more effective in distilling knowledge. In this paper, we propose Weight Distillation to transfer the knowledge in parameters of a large neural network to a small neural network through a parameter generator. On the WMT16 En-Ro, NIST12 Zh-En, and WMT14 En-De machine translation tasks, our experiments show that weight distillation learns a small network that is 1.88 2.94x faster than the large network but with competitive BLEU performance. When fixing the size of small networks, weight distillation outperforms knowledge distillation by 0.51 1.82 BLEU points.
It is a common belief that training deep transformers from scratch requires large datasets. Consequently, for small datasets, people usually use shallow and simple additional layers on top of pre-trained models during fine-tuning. This work shows that this does not always need to be the case: with proper initialization and optimization, the benefits of very deep transformers can carry over to challenging tasks with small datasets, including Text-to-SQL semantic parsing and logical reading comprehension. In particular, we successfully train 48 layers of transformers, comprising 24 fine-tuned layers from pre-trained RoBERTa and 24 relation-aware layers trained from scratch. With fewer training steps and no task-specific pre-training, we obtain the state of the art performance on the challenging cross-domain Text-to-SQL parsing benchmark Spider. We achieve this by deriving a novel Data dependent Transformer Fixed-update initialization scheme (DT-Fixup), inspired by the prior T-Fixup work. Further error analysis shows that increasing depth can help improve generalization on small datasets for hard cases that require reasoning and structural understanding.
Transformer-based language models (TLMs), such as BERT, ALBERT and GPT-3, have shown strong performance in a wide range of NLP tasks and currently dominate the field of NLP. However, many researchers wonder whether these models can maintain their dominance forever. Of course, we do not have answers now, but, as an attempt to find better neural architectures and training schemes, we pretrain a simple CNN using a GAN-style learning scheme and Wikipedia data, and then integrate it with standard TLMs. We show that on the GLUE tasks, the combination of our pretrained CNN with ALBERT outperforms the original ALBERT and achieves a similar performance to that of SOTA. Furthermore, on open-domain QA (Quasar-T and SearchQA), the combination of the CNN with ALBERT or RoBERTa achieved stronger performance than SOTA and the original TLMs. We hope that this work provides a hint for developing a novel strong network architecture along with its training scheme. Our source code and models are available at https://github.com/nict-wisdom/bertac.
We introduce a FEVER-like dataset COVID-Fact of 4,086 claims concerning the COVID-19 pandemic. The dataset contains claims, evidence for the claims, and contradictory claims refuted by the evidence. Unlike previous approaches, we automatically detect true claims and their source articles and then generate counter-claims using automatic methods rather than employing human annotators. Along with our constructed resource, we formally present the task of identifying relevant evidence for the claims and verifying whether the evidence refutes or supports a given claim. In addition to scientific claims, our data contains simplified general claims from media sources, making it better suited for detecting general misinformation regarding COVID-19. Our experiments indicate that COVID-Fact will provide a challenging testbed for the development of new systems and our approach will reduce the costs of building domain-specific datasets for detecting misinformation.
We address the task of explaining relationships between two scientific documents using natural language text. This task requires modeling the complex content of long technical documents, deducing a relationship between these documents, and expressing the details of that relationship in text. In addition to the theoretical interest of this task, successful solutions can help improve researcher efficiency in search and review. In this paper we establish a dataset of 622K examples from 154K documents. We pretrain a large language model to serve as the foundation for autoregressive approaches to the task. We explore the impact of taking different views on the two documents, including the use of dense representations extracted with scientific IE systems. We provide extensive automatic and human evaluations which show the promise of such models, but make clear challenges for future work.
Existing software-based energy measurements of NLP models are not accurate because they do not consider the complex interactions between energy consumption and model execution. We present IrEne, an interpretable and extensible energy prediction system that accurately predicts the inference energy consumption of a wide range of Transformer-based NLP models. IrEne constructs a model tree graph that breaks down the NLP model into modules that are further broken down into low-level machine learning (ML) primitives. IrEne predicts the inference energy consumption of the ML primitives as a function of generalizable features and fine-grained runtime resource usage. IrEne then aggregates these low-level predictions recursively to predict the energy of each module and finally of the entire model. Experiments across multiple Transformer models show IrEne predicts inference energy consumption of transformer models with an error of under 7% compared to the ground truth. In contrast, existing energy models see an error of over 50%. We also show how IrEne can be used to conduct energy bottleneck analysis and to easily evaluate the energy impact of different architectural choices. We release the code and data at https://github.com/StonyBrookNLP/irene.
The element of repetition in cyberbullying behavior has directed recent computational studies toward detecting cyberbullying based on a social media session. In contrast to a single text, a session may consist of an initial post and an associated sequence of comments. Yet, emerging efforts to enhance the performance of session-based cyberbullying detection have largely overlooked unintended social biases in existing cyberbullying datasets. For example, a session containing certain demographic-identity terms (e.g., “gay” or “black”) is more likely to be classified as an instance of cyberbullying. In this paper, we first show evidence of such bias in models trained on sessions collected from different social media platforms (e.g., Instagram). We then propose a context-aware and model-agnostic debiasing strategy that leverages a reinforcement learning technique, without requiring any extra resources or annotations apart from a pre-defined set of sensitive triggers commonly used for identifying cyberbullying instances. Empirical evaluations show that the proposed strategy can simultaneously alleviate the impacts of the unintended biases and improve the detection performance.
Creating effective visualization is an important part of data analytics. While there are many libraries for creating visualization, writing such code remains difficult given the myriad of parameters that users need to provide. In this paper, we propose the new task of synthesizing visualization programs from a combination of natural language utterances and code context. To tackle the learning problem, we introduce PlotCoder, a new hierarchical encoder-decoder architecture that models both the code context and the input utterance. We use PlotCoder to first determine the template of the visualization code, followed by predicting the data to be plotted. We use Jupyter notebooks containing visualization programs crawled from GitHub to train PlotCoder. On a comprehensive set of test samples from those notebooks, we show that PlotCoder correctly predicts the plot type of about 70% samples, and synthesizes the correct programs for 35% samples, performing 3-4.5% better than the baselines.
NLP community is currently investing a lot more research and resources into development of deep learning models than training data. While we have made a lot of progress, it is now clear that our models learn all kinds of spurious patterns, social biases, and annotation artifacts. Algorithmic solutions have so far had limited success. An alternative that is being actively discussed is more careful design of datasets so as to deliver specific signals. This position paper maps out the arguments for and against data curation, and argues that fundamentally the point is moot: curation already is and will be happening, and it is changing the world. The question is only how much thought we want to invest into that process.
Heavily overparameterized language models such as BERT, XLNet and T5 have achieved impressive success in many NLP tasks. However, their high model complexity requires enormous computation resources and extremely long training time for both pre-training and fine-tuning. Many works have studied model compression on large NLP models, but only focusing on reducing inference time while still requiring an expensive training process. Other works use extremely large batch sizes to shorten the pre-training time, at the expense of higher computational resource demands. In this paper, inspired by the Early-Bird Lottery Tickets recently studied for computer vision tasks, we propose EarlyBERT, a general computationally-efficient training algorithm applicable to both pre-training and fine-tuning of large-scale language models. By slimming the self-attention and fully-connected sub-layers inside a transformer, we are the first to identify structured winning tickets in the early stage of BERT training. We apply those tickets towards efficient BERT training, and conduct comprehensive pre-training and fine-tuning experiments on GLUE and SQuAD downstream tasks. Our results show that EarlyBERT achieves comparable performance to standard BERT, with 35 45% less training time. Code is available at https://github.com/VITA-Group/EarlyBERT.
Adapter-based tuning has recently arisen as an alternative to fine-tuning. It works by adding light-weight adapter modules to a pretrained language model (PrLM) and only updating the parameters of adapter modules when learning on a downstream task. As such, it adds only a few trainable parameters per new task, allowing a high degree of parameter sharing. Prior studies have shown that adapter-based tuning often achieves comparable results to fine-tuning. However, existing work only focuses on the parameter-efficient aspect of adapter-based tuning while lacking further investigation on its effectiveness. In this paper, we study the latter. We first show that adapter-based tuning better mitigates forgetting issues than fine-tuning since it yields representations with less deviation from those generated by the initial PrLM. We then empirically compare the two tuning methods on several downstream NLP tasks and settings. We demonstrate that 1) adapter-based tuning outperforms fine-tuning on low-resource and cross-lingual tasks; 2) it is more robust to overfitting and less sensitive to changes in learning rates.
Data augmentation is an effective way to improve the performance of many neural text generation models. However, current data augmentation methods need to define or choose proper data mapping functions that map the original samples into the augmented samples. In this work, we derive an objective to formulate the problem of data augmentation on text generation tasks without any use of augmented data constructed by specific mapping functions. Our proposed objective can be efficiently optimized and applied to popular loss functions on text generation tasks with a convergence rate guarantee. Experiments on five datasets of two text generation tasks show that our approach can approximate or even surpass popular data augmentation methods.
With the need of fast retrieval speed and small memory footprint, document hashing has been playing a crucial role in large-scale information retrieval. To generate high-quality hashing code, both semantics and neighborhood information are crucial. However, most existing methods leverage only one of them or simply combine them via some intuitive criteria, lacking a theoretical principle to guide the integration process. In this paper, we encode the neighborhood information with a graph-induced Gaussian distribution, and propose to integrate the two types of information with a graph-driven generative model. To deal with the complicated correlations among documents, we further propose a tree-structured approximation method for learning. Under the approximation, we prove that the training objective can be decomposed into terms involving only singleton or pairwise documents, enabling the model to be trained as efficiently as uncorrelated ones. Extensive experimental results on three benchmark datasets show that our method achieves superior performance over state-of-the-art methods, demonstrating the effectiveness of the proposed model for simultaneously preserving semantic and neighborhood information.
The open-ended nature of visual captioning makes it a challenging area for evaluation. The majority of proposed models rely on specialized training to improve human-correlation, resulting in limited adoption, generalizability, and explainabilty. We introduce “typicality”, a new formulation of evaluation rooted in information theory, which is uniquely suited for problems lacking a definite ground truth. Typicality serves as our framework to develop a novel semantic comparison, SPARCS, as well as referenceless fluency evaluation metrics. Over the course of our analysis, two separate dimensions of fluency naturally emerge: style, captured by metric SPURTS, and grammar, captured in the form of grammatical outlier penalties. Through extensive experiments and ablation studies on benchmark datasets, we show how these decomposed dimensions of semantics and fluency provide greater system-level insight into captioner differences. Our proposed metrics along with their combination, SMURF, achieve state-of-the-art correlation with human judgment when compared with other rule-based evaluation metrics.
The goal of database question answering is to enable natural language querying of real-life relational databases in diverse application domains. Recently, large-scale datasets such as Spider and WikiSQL facilitated novel modeling techniques for text-to-SQL parsing, improving zero-shot generalization to unseen databases. In this work, we examine the challenges that still prevent these techniques from practical deployment. First, we present KaggleDBQA, a new cross-domain evaluation dataset of real Web databases, with domain-specific data types, original formatting, and unrestricted questions. Second, we re-examine the choice of evaluation tasks for text-to-SQL parsers as applied in real-life settings. Finally, we augment our in-domain evaluation task with database documentation, a naturally occurring source of implicit domain knowledge. We show that KaggleDBQA presents a challenge to state-of-the-art zero-shot parsers but a more realistic evaluation setting and creative use of associated database documentation boosts their accuracy by over 13.2%, doubling their performance.
We introduce the largest transcribed Arabic speech corpus, QASR, collected from the broadcast domain. This multi-dialect speech dataset contains 2,000 hours of speech sampled at 16kHz crawled from Aljazeera news channel. The dataset is released with lightly supervised transcriptions, aligned with the audio segments. Unlike previous datasets, QASR contains linguistically motivated segmentation, punctuation, speaker information among others. QASR is suitable for training and evaluating speech recognition systems, acoustics- and/or linguistics- based Arabic dialect identification, punctuation restoration, speaker identification, speaker linking, and potentially other NLP modules for spoken data. In addition to QASR transcription, we release a dataset of 130M words to aid in designing and training a better language model. We show that end-to-end automatic speech recognition trained on QASR reports a competitive word error rate compared to the previous MGB-2 corpus. We report baseline results for downstream natural language processing tasks such as named entity recognition using speech transcript. We also report the first baseline for Arabic punctuation restoration. We make the corpus available for the research community.
The performance of fine-tuning pre-trained language models largely depends on the hyperparameter configuration. In this paper, we investigate the performance of modern hyperparameter optimization methods (HPO) on fine-tuning pre-trained language models. First, we study and report three HPO algorithms’ performances on fine-tuning two state-of-the-art language models on the GLUE dataset. We find that using the same time budget, HPO often fails to outperform grid search due to two reasons: insufficient time budget and overfitting. We propose two general strategies and an experimental procedure to systematically troubleshoot HPO’s failure cases. By applying the procedure, we observe that HPO can succeed with more appropriate settings in the search space and time budget; however, in certain cases overfitting remains. Finally, we make suggestions for future work. Our implementation can be found in https://github.com/microsoft/FLAML/tree/main/flaml/nlp/
Evaluation in NLP is usually done by comparing the scores of competing systems independently averaged over a common set of test instances. In this work, we question the use of averages for aggregating evaluation scores into a final number used to decide which system is best, since the average, as well as alternatives such as the median, ignores the pairing arising from the fact that systems are evaluated on the same test instances. We illustrate the importance of taking the instancelevel pairing of evaluation scores into account and demonstrate, both theoretically and empirically, the advantages of aggregation methods based on pairwise comparisons, such as the Bradley–Terry (BT) model, a mechanism based on the estimated probability that a given system scores better than another on the test set. By re-evaluating 296 real NLP evaluation setups across four tasks and 18 evaluation metrics, we show that the choice of aggregation mechanism matters and yields different conclusions as to which systems are state of the art in about 30% of the setups. To facilitate the adoption of pairwise evaluation, we release a practical tool for performing the full analysis of evaluation scores with the mean, median, BT, and two variants of BT (Elo and TrueSkill), alongside functionality for appropriate statistical testing.
The cross-database context-dependent Text-to-SQL (XDTS) problem has attracted considerable attention in recent years due to its wide range of potential applications. However, we identify two biases in existing datasets for XDTS: (1) a high proportion of context-independent questions and (2) a high proportion of easy SQL queries. These biases conceal the major challenges in XDTS to some extent. In this work, we present Chase, a large-scale and pragmatic Chinese dataset for XDTS. It consists of 5,459 coherent question sequences (17,940 questions with their SQL queries annotated) over 280 databases, in which only 35% of questions are context-independent, and 28% of SQL queries are easy. We experiment on Chase with three state-of-the-art XDTS approaches. The best approach only achieves an exact match accuracy of 40% over all questions and 16% over all question sequences, indicating that Chase highlights the challenging problems of XDTS. We believe that XDTS can provide fertile soil for addressing the problems.
Despite pre-trained language models have proven useful for learning high-quality semantic representations, these models are still vulnerable to simple perturbations. Recent works aimed to improve the robustness of pre-trained models mainly focus on adversarial training from perturbed examples with similar semantics, neglecting the utilization of different or even opposite semantics. Different from the image processing field, the text is discrete and few word substitutions can cause significant semantic changes. To study the impact of semantics caused by small perturbations, we conduct a series of pilot experiments and surprisingly find that adversarial training is useless or even harmful for the model to detect these semantic changes. To address this problem, we propose Contrastive Learning with semantIc Negative Examples (CLINE), which constructs semantic negative examples unsupervised to improve the robustness under semantically adversarial attacking. By comparing with similar and opposite semantic examples, the model can effectively perceive the semantic changes caused by small perturbations. Empirical results show that our approach yields substantial improvements on a range of sentiment analysis, reasoning, and reading comprehension tasks. And CLINE also ensures the compactness within the same semantics and separability across different semantics in sentence-level.
Topic modeling has been widely used for discovering the latent semantic structure of documents, but most existing methods learn topics with a flat structure. Although probabilistic models can generate topic hierarchies by introducing nonparametric priors like Chinese restaurant process, such methods have data scalability issues. In this study, we develop a tree-structured topic model by leveraging nonparametric neural variational inference. Particularly, the latent components of the stick-breaking process are first learned for each document, then the affiliations of latent components are modeled by the dependency matrices between network layers. Utilizing this network structure, we can efficiently extract a tree-structured topic hierarchy with reasonable structure, low redundancy, and adaptable widths. Experiments on real-world datasets validate the effectiveness of our method.
Prior work infers the causation between events mainly based on the knowledge induced from the annotated causal event pairs. However, additional evidence information intermediate to the cause and effect remains unexploited. By incorporating such information, the logical law behind the causality can be unveiled, and the interpretability and stability of the causal reasoning system can be improved. To facilitate this, we present an Event graph knowledge enhanced explainable CAusal Reasoning framework (ExCAR). ExCAR first acquires additional evidence information from a large-scale causal event graph as logical rules for causal reasoning. To learn the conditional probabilistic of logical rules, we propose the Conditional Markov Neural Logic Network (CMNLN) that combines the representation learning and structure learning of logical rules in an end-to-end differentiable manner. Experimental results demonstrate that ExCAR outperforms previous state-of-the-art methods. Adversarial evaluation shows the improved stability of ExCAR over baseline systems. Human evaluation shows that ExCAR can achieve a promising explainable performance.
Emotion category is usually divided into different ones by human beings, but it is indeed difficult to clearly distinguish and define the boundaries between different emotion categories. The existing studies working on emotion detection usually focus on how to improve the performance of model prediction, in which emotions are represented with one-hot vectors. However, emotion relations are ignored in one-hot representations. In this article, we first propose a general framework to learn the distributed representations for emotion categories in emotion space from a given emotion classification dataset. Furthermore, based on the soft labels predicted by the pre-trained neural network model, we derive a simple and effective algorithm. Experiments have validated that the proposed representations in emotion space can express emotion relations much better than word vectors in semantic space.
Every natural text is written in some style. Style is formed by a complex combination of different stylistic factors, including formality markers, emotions, metaphors, etc. One cannot form a complete understanding of a text without considering these factors. The factors combine and co-vary in complex ways to form styles. Studying the nature of the covarying combinations sheds light on stylistic language in general, sometimes called cross-style language understanding. This paper provides the benchmark corpus (XSLUE) that combines existing datasets and collects a new one for sentence-level cross-style language understanding and evaluation. The benchmark contains text in 15 different styles under the proposed four theoretical groupings: figurative, personal, affective, and interpersonal groups. For valid evaluation, we collect an additional diagnostic set by annotating all 15 styles on the same text. Using XSLUE, we propose three interesting cross-style applications in classification, correlation, and generation. First, our proposed cross-style classifier trained with multiple styles together helps improve overall classification performance against individually-trained style classifiers. Second, our study shows that some styles are highly dependent on each other in human-written text. Finally, we find that combinations of some contradictive styles likely generate stylistically less appropriate text. We believe our benchmark and case studies help explore interesting future directions for cross-style research. The preprocessed datasets and code are publicly available.
We introduce DynaSent (‘Dynamic Sentiment’), a new English-language benchmark task for ternary (positive/negative/neutral) sentiment analysis. DynaSent combines naturally occurring sentences with sentences created using the open-source Dynabench Platform, which facilities human-and-model-in-the-loop dataset creation. DynaSent has a total of 121,634 sentences, each validated by five crowdworkers, and its development and test splits are designed to produce chance performance for even the best models we have been able to develop; when future models solve this task, we will use them to create DynaSent version 2, continuing the dynamic evolution of this benchmark. Here, we report on the dataset creation effort, focusing on the steps we took to increase quality and reduce artifacts. We also present evidence that DynaSent’s Neutral category is more coherent than the comparable category in other benchmarks, and we motivate training models from scratch for each round over successive fine-tuning.
In this digital age, online users expect personalized content. To cater to diverse group of audiences across online platforms it is necessary to generate multiple variants of same content with differing degree of characteristics (sentiment, style, formality, etc.). Though text-style transfer is a well explored related area, it focuses on flipping the style attribute polarity instead of regulating a fine-grained attribute transfer. In this paper we propose a hierarchical architecture for finer control over the at- tribute, preserving content using attribute dis- entanglement. We demonstrate the effective- ness of the generative process for two different attributes with varied complexity, namely sentiment and formality. With extensive experiments and human evaluation on five real-world datasets, we show that the framework can generate natural looking sentences with finer degree of control of intensity of a given attribute.
Aspect-based Sentiment Analysis (ABSA) aims to identify the aspect terms, their corresponding sentiment polarities, and the opinion terms. There exist seven subtasks in ABSA. Most studies only focus on the subsets of these subtasks, which leads to various complicated ABSA models while hard to solve these subtasks in a unified framework. In this paper, we redefine every subtask target as a sequence mixed by pointer indexes and sentiment class indexes, which converts all ABSA subtasks into a unified generative formulation. Based on the unified formulation, we exploit the pre-training sequence-to-sequence model BART to solve all ABSA subtasks in an end-to-end framework. Extensive experiments on four ABSA datasets for seven subtasks demonstrate that our framework achieves substantial performance gain and provides a real unified end-to-end solution for the whole ABSA subtasks, which could benefit multiple tasks.
Task-oriented dialogue systems typically require manual annotation of dialogue slots in training data, which is costly to obtain. We propose a method that eliminates this requirement: We use weak supervision from existing linguistic annotation models to identify potential slot candidates, then automatically identify domain-relevant slots by using clustering algorithms. Furthermore, we use the resulting slot annotation to train a neural-network-based tagger that is able to perform slot tagging with no human intervention. This tagger is trained solely on the outputs of our method and thus does not rely on any labeled data. Our model demonstrates state-of-the-art performance in slot tagging without labeled training data on four different dialogue domains. Moreover, we find that slot annotations discovered by our model significantly improve the performance of an end-to-end dialogue response generation model, compared to using no slot annotation at all.
Intent classification is a major task in spoken language understanding (SLU). Since most models are built with pre-collected in-domain (IND) training utterances, their ability to detect unsupported out-of-domain (OOD) utterances has a critical effect in practical use. Recent works have shown that using extra data and labels can improve the OOD detection performance, yet it could be costly to collect such data. This paper proposes to train a model with only IND data while supporting both IND intent classification and OOD detection. Our method designs a novel domain-regularized module (DRM) to reduce the overconfident phenomenon of a vanilla classifier, achieving a better generalization in both cases. Besides, DRM can be used as a drop-in replacement for the last layer in any neural network-based intent classifier, providing a low-cost strategy for a significant improvement. The evaluation on four datasets shows that our method built on BERT and RoBERTa models achieves state-of-the-art performance against existing approaches and the strong baselines we created for the comparisons.
Recent research considers few-shot intent detection as a meta-learning problem: the model is learning to learn from a consecutive set of small tasks named episodes. In this work, we propose ProtAugment, a meta-learning algorithm for short texts classification (the intent detection task). ProtAugment is a novel extension of Prototypical Networks, that limits overfitting on the bias introduced by the few-shots classification objective at each episode. It relies on diverse paraphrasing: a conditional language model is first fine-tuned for paraphrasing, and diversity is later introduced at the decoding stage at each meta-learning episode. The diverse paraphrasing is unsupervised as it is applied to unlabelled data, and then fueled to the Prototypical Network training objective as a consistency loss. ProtAugment is the state-of-the-art method for intent detection meta-learning, at no extra labeling efforts and without the need to fine-tune a conditional language model on a given application domain.
Most language understanding models in task-oriented dialog systems are trained on a small amount of annotated training data, and evaluated in a small set from the same distribution. However, these models can lead to system failure or undesirable output when being exposed to natural language perturbation or variation in practice. In this paper, we conduct comprehensive evaluation and analysis with respect to the robustness of natural language understanding models, and introduce three important aspects related to language understanding in real-world dialog systems, namely, language variety, speech characteristics, and noise perturbation. We propose a model-agnostic toolkit LAUG to approximate natural language perturbations for testing the robustness issues in task-oriented dialog. Four data augmentation approaches covering the three aspects are assembled in LAUG, which reveals critical robustness issues in state-of-the-art models. The augmented dataset through LAUG can be used to facilitate future research on the robustness testing of language understanding in task-oriented dialog.
Dialogue state tracking (DST) plays a key role in task-oriented dialogue systems to monitor the user’s goal. In general, there are two strategies to track a dialogue state: predicting it from scratch and updating it from previous state. The scratch-based strategy obtains each slot value by inquiring all the dialogue history, and the previous-based strategy relies on the current turn dialogue to update the previous dialogue state. However, it is hard for the scratch-based strategy to correctly track short-dependency dialogue state because of noise; meanwhile, the previous-based strategy is not very useful for long-dependency dialogue state tracking. Obviously, it plays different roles for the context information of different granularity to track different kinds of dialogue states. Thus, in this paper, we will study and discuss how the context information of different granularity affects dialogue state tracking. First, we explore how greatly different granularities affect dialogue state tracking. Then, we further discuss how to combine multiple granularities for dialogue state tracking. Finally, we apply the findings about context granularity to few-shot learning scenario. Besides, we have publicly released all codes.
Mixed initiative in open-domain dialogue requires a system to pro-actively introduce new topics. The one-turn topic transition task explores how a system connects two topics in a cooperative and coherent manner. The goal of the task is to generate a “bridging” utterance connecting the new topic to the topic of the previous conversation turn. We are especially interested in commonsense explanations of how a new topic relates to what has been mentioned before. We first collect a new dataset of human one-turn topic transitions, which we callOTTers. We then explore different strategies used by humans when asked to complete such a task, and notice that the use of a bridging utterance to connect the two topics is the approach used the most. We finally show how existing state-of-the-art text generation models can be adapted to this task and examine the performance of these baselines on different splits of the OTTers data.
Recently, there has been significant progress in studying neural networks to translate text descriptions into SQL queries. Despite achieving good performance on some public benchmarks, existing text-to-SQL models typically rely on the lexical matching between words in natural language (NL) questions and tokens in table schemas, which may render the models vulnerable to attacks that break the schema linking mechanism. In this work, we investigate the robustness of text-to-SQL models to synonym substitution. In particular, we introduce Spider-Syn, a human-curated dataset based on the Spider benchmark for text-to-SQL translation. NL questions in Spider-Syn are modified from Spider, by replacing their schema-related words with manually selected synonyms that reflect real-world question paraphrases. We observe that the accuracy dramatically drops by eliminating such explicit correspondence between NL questions and table schemas, even if the synonyms are not adversarially selected to conduct worst-case attacks. Finally, we present two categories of approaches to improve the model robustness. The first category of approaches utilizes additional synonym annotations for table schemas by modifying the model input, while the second category is based on adversarial training. We demonstrate that both categories of approaches significantly outperform their counterparts without the defense, and the first category of approaches are more effective.
In order to better understand the reason behind model behaviors (i.e., making predictions), most recent works have exploited generative models to provide complementary explanations. However, existing approaches in NLP mainly focus on “WHY A” rather than contrastive “WHY A NOT B”, which is shown to be able to better distinguish confusing candidates and improve data efficiency in other research fields.In this paper, we focus on generating contrastive explanations with counterfactual examples in NLI and propose a novel Knowledge-Aware Contrastive Explanation generation framework (KACE).Specifically, we first identify rationales (i.e., key phrases) from input sentences, and use them as key perturbations for generating counterfactual examples. After obtaining qualified counterfactual examples, we take them along with original examples and external knowledge as input, and employ a knowledge-aware generative pre-trained language model to generate contrastive explanations. Experimental results show that contrastive explanations are beneficial to fit the scenarios by clarifying the difference between the predicted answer and other possible wrong ones. Moreover, we train an NLI model enhanced with contrastive explanations and achieves an accuracy of 91.9% on SNLI, gaining improvements of 5.7% against ETPA (“Explain-Then-Predict-Attention”) and 0.6% against NILE (“WHY A”).
Although BERT and its variants have reshaped the NLP landscape, it still remains unclear how best to derive sentence embeddings from such pre-trained Transformers. In this work, we propose a contrastive learning method that utilizes self-guidance for improving the quality of BERT sentence representations. Our method fine-tunes BERT in a self-supervised fashion, does not rely on data augmentation, and enables the usual [CLS] token embeddings to function as sentence vectors. Moreover, we redesign the contrastive learning objective (NT-Xent) and apply it to sentence representation learning. We demonstrate with extensive experiments that our approach is more effective than competitive baselines on diverse sentence-related tasks. We also show it is efficient at inference and robust to domain shifts.
This work aims to tackle the challenging heterogeneous graph encoding problem in the text-to-SQL task. Previous methods are typically node-centric and merely utilize different weight matrices to parameterize edge types, which 1) ignore the rich semantics embedded in the topological structure of edges, and 2) fail to distinguish local and non-local relations for each node. To this end, we propose a Line Graph Enhanced Text-to-SQL (LGESQL) model to mine the underlying relational features without constructing meta-paths. By virtue of the line graph, messages propagate more efficiently through not only connections between nodes, but also the topology of directed edges. Furthermore, both local and non-local relations are integrated distinctively during the graph iteration. We also design an auxiliary task called graph pruning to improve the discriminative capability of the encoder. Our framework achieves state-of-the-art results (62.8% with Glove, 72.0% with Electra) on the cross-domain text-to-SQL benchmark Spider at the time of writing.
Multimodal pre-training models, such as LXMERT, have achieved excellent results in downstream tasks. However, current pre-trained models require large amounts of training data and have huge model sizes, which make them impossible to apply in low-resource situations. How to obtain similar or even better performance than a larger model under the premise of less pre-training data and smaller model size has become an important problem. In this paper, we propose a new Multi-stage Pre-training (MSP) method, which uses information at different granularities from word, phrase to sentence in both texts and images to pre-train a model in stages. We also design several different pre-training tasks suitable for the information granularity in different stage in order to efficiently capture the diverse knowledge from a limited corpus. We take a Simplified LXMERT (LXMERT-S) which is with 45.9% parameters of the original LXMERT model and only 11.44% of the original pre-training data as the testbed of our MSP method. Experimental results show that our method achieves comparable performance to the original LXMERT model in all downstream tasks, and even outperforms the original model in Image-Text Retrieval task.
Document-level contextual information has shown benefits to text-based machine translation, but whether and how context helps end-to-end (E2E) speech translation (ST) is still under-studied. We fill this gap through extensive experiments using a simple concatenation-based context-aware ST model, paired with adaptive feature selection on speech encodings for computational efficiency. We investigate several decoding approaches, and introduce in-model ensemble decoding which jointly performs document- and sentence-level translation using the same model. Our results on the MuST-C benchmark with Transformer demonstrate the effectiveness of context to E2E ST. Compared to sentence-level ST, context-aware ST obtains better translation quality (+0.18-2.61 BLEU), improves pronoun and homophone translation, shows better robustness to (artificial) audio segmentation errors, and reduces latency and flicker to deliver higher quality for simultaneous translation.
Pre-training of text and layout has proved effective in a variety of visually-rich document understanding tasks due to its effective model architecture and the advantage of large-scale unlabeled scanned/digital-born documents. We propose LayoutLMv2 architecture with new pre-training tasks to model the interaction among text, layout, and image in a single multi-modal framework. Specifically, with a two-stream multi-modal Transformer encoder, LayoutLMv2 uses not only the existing masked visual-language modeling task but also the new text-image alignment and text-image matching tasks, which make it better capture the cross-modality interaction in the pre-training stage. Meanwhile, it also integrates a spatial-aware self-attention mechanism into the Transformer architecture so that the model can fully understand the relative positional relationship among different text blocks. Experiment results show that LayoutLMv2 outperforms LayoutLM by a large margin and achieves new state-of-the-art results on a wide variety of downstream visually-rich document understanding tasks, including FUNSD (0.7895 to 0.8420), CORD (0.9493 to 0.9601), SROIE (0.9524 to 0.9781), Kleister-NDA (0.8340 to 0.8520), RVL-CDIP (0.9443 to 0.9564), and DocVQA (0.7295 to 0.8672).
Existed pre-training methods either focus on single-modal tasks or multi-modal tasks, and cannot effectively adapt to each other. They can only utilize single-modal data (i.e., text or image) or limited multi-modal data (i.e., image-text pairs). In this work, we propose a UNIfied-MOdal pre-training architecture, namely UNIMO, which can effectively adapt to both single-modal and multi-modal understanding and generation tasks. Large scale of free text corpus and image collections are utilized to improve the capability of visual and textual understanding, and cross-modal contrastive learning (CMCL) is leveraged to align the textual and visual information into a unified semantic space, over a corpus of image-text pairs augmented with related images and texts. With the help of rich non-paired single-modal data, our model is able to learn more generalizable representations, by allowing textual knowledge and visual knowledge to enhance each other in the unified semantic space. The experimental results show that UNIMO greatly improves the performance of several single-modal and multi-modal downstream tasks. Our code and pre-trained models are public at https://github.com/PaddlePaddle/Research/tree/master/NLP/UNIMO.
Multimodal fusion has been proved to improve emotion recognition performance in previous works. However, in real-world applications, we often encounter the problem of missing modality, and which modalities will be missing is uncertain. It makes the fixed multimodal fusion fail in such cases. In this work, we propose a unified model, Missing Modality Imagination Network (MMIN), to deal with the uncertain missing modality problem. MMIN learns robust joint multimodal representations, which can predict the representation of any missing modality given available modalities under different missing modality conditions.Comprehensive experiments on two benchmark datasets demonstrate that the unified MMIN model significantly improves emotion recognition performance under both uncertain missing-modality testing conditions and full-modality ideal testing condition. The code will be available at https://github.com/AIM3-RUC/MMIN.
Encoder pre-training is promising in end-to-end Speech Translation (ST), given the fact that speech-to-translation data is scarce. But ST encoders are not simple instances of Automatic Speech Recognition (ASR) or Machine Translation (MT) encoders. For example, we find that ASR encoders lack the global context representation, which is necessary for translation, whereas MT encoders are not designed to deal with long but locally attentive acoustic sequences. In this work, we propose a Stacked Acoustic-and-Textual Encoding (SATE) method for speech translation. Our encoder begins with processing the acoustic sequence as usual, but later behaves more like an MT encoder for a global representation of the input sequence. In this way, it is straightforward to incorporate the pre-trained models into the system. Also, we develop an adaptor module to alleviate the representation inconsistency between the pre-trained ASR encoder and MT encoder, and develop a multi-teacher knowledge distillation method to preserve the pre-training knowledge. Experimental results on the LibriSpeech En-Fr and MuST-C En-De ST tasks show that our method achieves state-of-the-art BLEU scores of 18.3 and 25.2. To our knowledge, we are the first to develop an end-to-end ST system that achieves comparable or even better BLEU performance than the cascaded ST counterpart when large-scale ASR and MT data is available.
In this paper, we study the task of graph-based constituent parsing in the setting that binarization is not conducted as a pre-processing step, where a constituent tree may consist of nodes with more than two children. Previous graph-based methods on this setting typically generate hidden nodes with the dummy label inside the n-ary nodes, in order to transform the tree into a binary tree for prediction. The limitation is that the hidden nodes break the sibling relations of the n-ary node’s children. Consequently, the dependencies of such sibling constituents might not be accurately modeled and is being ignored. To solve this limitation, we propose a novel graph-based framework, which is called “recursive semi-Markov model”. The main idea is to utilize 1-order semi-Markov model to predict the immediate children sequence of a constituent candidate, which then recursively serves as a child candidate of its parent. In this manner, the dependencies of sibling constituents can be described by 1-order transition features, which solves the above limitation. Through experiments, the proposed framework obtains the F1 of 95.92% and 92.50% on the datasets of PTB and CTB 5.1 respectively. Specially, the recursive semi-Markov model shows advantages in modeling nodes with more than two children, whose average F1 can be improved by 0.3-1.1 points in PTB and 2.3-6.8 points in CTB 5.1.
Pretrained contextualized embeddings are powerful word representations for structured prediction tasks. Recent work found that better word representations can be obtained by concatenating different types of embeddings. However, the selection of embeddings to form the best concatenated representation usually varies depending on the task and the collection of candidate embeddings, and the ever-increasing number of embedding types makes it a more difficult problem. In this paper, we propose Automated Concatenation of Embeddings (ACE) to automate the process of finding better concatenations of embeddings for structured prediction tasks, based on a formulation inspired by recent progress on neural architecture search. Specifically, a controller alternately samples a concatenation of embeddings, according to its current belief of the effectiveness of individual embedding types in consideration for a task, and updates the belief based on a reward. We follow strategies in reinforcement learning to optimize the parameters of the controller and compute the reward based on the accuracy of a task model, which is fed with the sampled concatenation as input and trained on a task dataset. Empirical results on 6 tasks and 21 datasets show that our approach outperforms strong baselines and achieves state-of-the-art performance with fine-tuned embeddings in all the evaluations.
In structured prediction problems, cross-lingual transfer learning is an efficient way to train quality models for low-resource languages, and further improvement can be obtained by learning from multiple source languages. However, not all source models are created equal and some may hurt performance on the target language. Previous work has explored the similarity between source and target sentences as an approximate measure of strength for different source models. In this paper, we propose a multi-view framework, by leveraging a small number of labeled target sentences, to effectively combine multiple source models into an aggregated source view at different granularity levels (language, sentence, or sub-structure), and transfer it to a target view based on a task-specific model. By encouraging the two views to interact with each other, our framework can dynamically adjust the confidence level of each source model and improve the performance of both views during training. Experiments for three structured prediction tasks on sixteen data sets show that our framework achieves significant improvement over all existing approaches, including these with access to additional source language data.
Incorporating syntax into neural approaches in NLP has a multitude of practical and scientific benefits. For instance, a language model that is syntax-aware is likely to be able to produce better samples; even a discriminative model like BERT with a syntax module could be used for core NLP tasks like unsupervised syntactic parsing. Rapid progress in recent years was arguably spurred on by the empirical success of the Parsing-Reading-Predict architecture of (Shen et al., 2018a), later simplified by the Order Neuron LSTM of (Shen et al., 2019). Most notably, this is the first time neural approaches were able to successfully perform unsupervised syntactic parsing (evaluated by various metrics like F-1 score). However, even heuristic (much less fully mathematical) understanding of why and when these architectures work is lagging severely behind. In this work, we answer representational questions raised by the architectures in (Shen et al., 2018a, 2019), as well as some transition-based syntax-aware language models (Dyer et al., 2016): what kind of syntactic structure can current neural approaches to syntax represent? Concretely, we ground this question in the sandbox of probabilistic context-free-grammars (PCFGs), and identify a key aspect of the representational power of these approaches: the amount and directionality of context that the predictor has access to when forced to make parsing decision. We show that with limited context (either bounded, or unidirectional), there are PCFGs, for which these approaches cannot represent the max-likelihood parse; conversely, if the context is unlimited, they can represent the max-likelihood parse of any PCFG.
Neural lexicalized PCFGs (L-PCFGs) have been shown effective in grammar induction. However, to reduce computational complexity, they make a strong independence assumption on the generation of the child word and thus bilexical dependencies are ignored. In this paper, we propose an approach to parameterize L-PCFGs without making implausible independence assumptions. Our approach directly models bilexical dependencies and meanwhile reduces both learning and representation complexities of L-PCFGs. Experimental results on the English WSJ dataset confirm the effectiveness of our approach in improving both running speed and unsupervised parsing performance.
On social media platforms, hateful and offensive language negatively impact the mental well-being of users and the participation of people from diverse backgrounds. Automatic methods to detect offensive language have largely relied on datasets with categorical labels. However, comments can vary in their degree of offensiveness. We create the first dataset of English language Reddit comments that has fine-grained, real-valued scores between -1 (maximally supportive) and 1 (maximally offensive). The dataset was annotated using Best–Worst Scaling, a form of comparative annotation that has been shown to alleviate known biases of using rating scales. We show that the method produces highly reliable offensiveness scores. Finally, we evaluate the ability of widely-used neural models to predict offensiveness scores on this new dataset.
Automatic dialogue coherence evaluation has attracted increasing attention and is crucial for developing promising dialogue systems. However, existing metrics have two major limitations: (a) they are mostly trained in a simplified two-level setting (coherent vs. incoherent), while humans give Likert-type multi-level coherence scores, dubbed as “quantifiable”; (b) their predicted coherence scores cannot align with the actual human rating standards due to the absence of human guidance during training. To address these limitations, we propose Quantifiable Dialogue Coherence Evaluation (QuantiDCE), a novel framework aiming to train a quantifiable dialogue coherence metric that can reflect the actual human rating standards. Specifically, QuantiDCE includes two training stages, Multi-Level Ranking (MLR) pre-training and Knowledge Distillation (KD) fine-tuning. During MLR pre-training, a new MLR loss is proposed for enabling the model to learn the coarse judgement of coherence degrees. Then, during KD fine-tuning, the pretrained model is further finetuned to learn the actual human rating standards with only very few human-annotated data. To advocate the generalizability even with limited fine-tuning data, a novel KD regularization is introduced to retain the knowledge learned at the pre-training stage. Experimental results show that the model trained by QuantiDCE presents stronger correlations with human judgements than the other state-of-the-art metrics.
Accurate assessment of the ability of embedding models to capture idiomaticity may require evaluation at token rather than type level, to account for degrees of idiomaticity and possible ambiguity between literal and idiomatic usages. However, most existing resources with annotation of idiomaticity include ratings only at type level. This paper presents the Noun Compound Type and Token Idiomaticity (NCTTI) dataset, with human annotations for 280 noun compounds in English and 180 in Portuguese at both type and token level. We compiled 8,725 and 5,091 token level annotations for English and Portuguese, respectively, which are strongly correlated with the corresponding scores obtained at type level. The NCTTI dataset is used to explore how vector space models reflect the variability of idiomaticity across sentences. Several experiments using state-of-the-art contextualised models suggest that their representations are not capturing the noun compounds idiomaticity as human annotators. This new multilingual resource also contains suggestions for paraphrases of the noun compounds both at type and token levels, with uses for lexical substitution or disambiguation in context.
Statutory reasoning is the task of determining whether a legal statute, stated in natural language, applies to the text description of a case. Prior work introduced a resource that approached statutory reasoning as a monolithic textual entailment problem, with neural baselines performing nearly at-chance. To address this challenge, we decompose statutory reasoning into four types of language-understanding challenge problems, through the introduction of concepts and structure found in Prolog programs. Augmenting an existing benchmark, we provide annotations for the four tasks, and baselines for three of them. Models for statutory reasoning are shown to benefit from the additional structure, improving on prior baselines. Further, the decomposition into subtasks facilitates finer-grained model diagnostics and clearer incremental progress.
Ordinal Classification (OC) is an important classification task where the classes are ordinal. For example, an OC task for sentiment analysis could have the following classes: highly positive, positive, neutral, negative, highly negative. Clearly, evaluation measures for an OC task should penalise misclassifications by considering the ordinal nature of the classes. Ordinal Quantification (OQ) is a related task where the gold data is a distribution over ordinal classes, and the system is required to estimate this distribution. Evaluation measures for an OQ task should also take the ordinal nature of the classes into account. However, for both OC and OQ, there are only a small number of known evaluation measures that meet this basic requirement. In the present study, we utilise data from the SemEval and NTCIR communities to clarify the properties of nine evaluation measures in the context of OC tasks, and six measures in the context of OQ tasks.
Entity Matching (EM) aims at recognizing entity records that denote the same real-world object. Neural EM models learn vector representation of entity descriptions and match entities end-to-end. Though robust, these methods require many annotated resources for training, and lack of interpretability. In this paper, we propose a novel EM framework that consists of Heterogeneous Information Fusion (HIF) and Key Attribute Tree (KAT) Induction to decouple feature representation from matching decision. Using self-supervised learning and mask mechanism in pre-trained language modeling, HIF learns the embeddings of noisy attribute values by inter-attribute attention with unlabeled data. Using a set of comparison features and a limited amount of annotated data, KAT Induction learns an efficient decision tree that can be interpreted by generating entity matching rules whose structure is advocated by domain experts. Experiments on 6 public datasets and 3 industrial datasets show that our method is highly efficient and outperforms SOTA EM models in most cases. We will release the codes upon acceptance.
Named entity recognition (NER) is a well-studied task in natural language processing. Traditional NER research only deals with flat entities and ignores nested entities. The span-based methods treat entity recognition as a span classification task. Although these methods have the innate ability to handle nested NER, they suffer from high computational cost, ignorance of boundary information, under-utilization of the spans that partially match with entities, and difficulties in long entity recognition. To tackle these issues, we propose a two-stage entity identifier. First we generate span proposals by filtering and boundary regression on the seed spans to locate the entities, and then label the boundary-adjusted span proposals with the corresponding categories. Our method effectively utilizes the boundary information of entities and partially matched spans during training. Through boundary regression, entities of any length can be covered theoretically, which improves the ability to recognize long entities. In addition, many low-quality seed spans are filtered out in the first stage, which reduces the time complexity of inference. Experiments on nested NER datasets demonstrate that our proposed method outperforms previous state-of-the-art models.
Event extraction is challenging due to the complex structure of event records and the semantic gap between text and event. Traditional methods usually extract event records by decomposing the complex structure prediction task into multiple subtasks. In this paper, we propose Text2Event, a sequence-to-structure generation paradigm that can directly extract events from the text in an end-to-end manner. Specifically, we design a sequence-to-structure network for unified event extraction, a constrained decoding algorithm for event knowledge injection during inference, and a curriculum learning algorithm for efficient model learning. Experimental results show that, by uniformly modeling all tasks in a single model and universally predicting different labels, our method can achieve competitive performance using only record-level annotations in both supervised learning and transfer learning settings.
In this paper, we aim to explore an uncharted territory, which is Chinese multimodal named entity recognition (NER) with both textual and acoustic contents. To achieve this, we construct a large-scale human-annotated Chinese multimodal NER dataset, named CNERTA. Our corpus totally contains 42,987 annotated sentences accompanying by 71 hours of speech data. Based on this dataset, we propose a family of strong and representative baseline models, which can leverage textual features or multimodal features. Upon these baselines, to capture the natural monotonic alignment between the textual modality and the acoustic modality, we further propose a simple multimodal multitask model by introducing a speech-to-text alignment auxiliary task. Through extensive experiments, we observe that: (1) Progressive performance boosts as we move from unimodal to multimodal, verifying the necessity of integrating speech clues into Chinese NER. (2) Our proposed model yields state-of-the-art (SoTA) results on CNERTA, demonstrating its effectiveness. For further research, the annotated dataset is publicly available at http://github.com/DianboWork/CNERTA.
Disease is one of the fundamental entities in biomedical research. Recognizing such entities from biomedical text and then normalizing them to a standardized disease vocabulary offer a tremendous opportunity for many downstream applications. Previous studies have demonstrated that joint modeling of the two sub-tasks has superior performance than the pipelined counterpart. Although the neural joint model based on multi-task learning framework has achieved state-of-the-art performance, it suffers from the boundary inconsistency problem due to the separate decoding procedures. Moreover, it ignores the rich information (e.g., the text surface form) of each candidate concept in the vocabulary, which is quite essential for entity normalization. In this work, we propose a neural transition-based joint model to alleviate these two issues. We transform the end-to-end disease recognition and normalization task as an action sequence prediction task, which not only jointly learns the model with shared representations of the input, but also jointly searches the output by state transitions in one search space. Moreover, we introduce attention mechanisms to take advantage of the text surface form of each candidate concept for better normalization performance. Experimental results conducted on two publicly available datasets show the effectiveness of the proposed method.
Event Detection (ED) aims to identify event trigger words from a given text and classify it into an event type. Most current methods to ED rely heavily on training instances, and almost ignore the correlation of event types. Hence, they tend to suffer from data scarcity and fail to handle new unseen event types. To address these problems, we formulate ED as a process of event ontology population: linking event instances to pre-defined event types in event ontology, and propose a novel ED framework entitled OntoED with ontology embedding. We enrich event ontology with linkages among event types, and further induce more event-event correlations. Based on the event ontology, OntoED can leverage and propagate correlation knowledge, particularly from data-rich to data-poor event types. Furthermore, OntoED can be applied to new unseen event types, by establishing linkages to existing ones. Experiments indicate that OntoED is more predominant and robust than previous approaches to ED, especially in data-scarce scenarios.
Self-training has proven effective for improving NMT performance by augmenting model training with synthetic parallel data. The common practice is to construct synthetic data based on a randomly sampled subset of large-scale monolingual data, which we empirically show is sub-optimal. In this work, we propose to improve the sampling procedure by selecting the most informative monolingual sentences to complement the parallel data. To this end, we compute the uncertainty of monolingual sentences using the bilingual dictionary extracted from the parallel data. Intuitively, monolingual sentences with lower uncertainty generally correspond to easy-to-translate patterns which may not provide additional gains. Accordingly, we design an uncertainty-based sampling strategy to efficiently exploit the monolingual data for self-training, in which monolingual sentences with higher uncertainty would be sampled with higher probability. Experimental results on large-scale WMT English⇒German and English⇒Chinese datasets demonstrate the effectiveness of the proposed approach. Extensive analyses suggest that emphasizing the learning on uncertain monolingual sentences by our approach does improve the translation quality of high-uncertainty sentences and also benefits the prediction of low-frequency words at the target side.
Context-aware neural machine translation (NMT) remains challenging due to the lack of large-scale document-level parallel corpora. To break the corpus bottleneck, in this paper we aim to improve context-aware NMT by taking the advantage of the availability of both large-scale sentence-level parallel dataset and source-side monolingual documents. To this end, we propose two pre-training tasks. One learns to translate a sentence from source language to target language on the sentence-level parallel dataset while the other learns to translate a document from deliberately noised to original on the monolingual documents. Importantly, the two pre-training tasks are jointly and simultaneously learned via the same model, thereafter fine-tuned on scale-limited parallel documents from both sentence-level and document-level perspectives. Experimental results on four translation tasks show that our approach significantly improves translation performance. One nice property of our approach is that the fine-tuned model can be used to translate both sentences and documents.
Although teacher forcing has become the main training paradigm for neural machine translation, it usually makes predictions only conditioned on past information, and hence lacks global planning for the future. To address this problem, we introduce another decoder, called seer decoder, into the encoder-decoder framework during training, which involves future information in target predictions. Meanwhile, we force the conventional decoder to simulate the behaviors of the seer decoder via knowledge distillation. In this way, at test the conventional decoder can perform like the seer decoder without the attendance of it. Experiment results on the Chinese-English, English-German and English-Romanian translation tasks show our method can outperform competitive baselines significantly and achieves greater improvements on the bigger data sets. Besides, the experiments also prove knowledge distillation the best way to transfer knowledge from the seer decoder to the conventional decoder compared to adversarial learning and L2 regularization.
Five years after the first published proofs of concept, direct approaches to speech translation (ST) are now competing with traditional cascade solutions. In light of this steady progress, can we claim that the performance gap between the two is closed? Starting from this question, we present a systematic comparison between state-of-the-art systems representative of the two paradigms. Focusing on three language directions (English-German/Italian/Spanish), we conduct automatic and manual evaluations, exploiting high-quality professional post-edits and annotations. Our multi-faceted analysis on one of the few publicly available ST benchmarks attests for the first time that: i) the gap between the two paradigms is now closed, and ii) the subtle differences observed in their behavior are not sufficient for humans neither to distinguish them nor to prefer one over the other.
Unsupervised machine translation, which utilizes unpaired monolingual corpora as training data, has achieved comparable performance against supervised machine translation. However, it still suffers from data-scarce domains. To address this issue, this paper presents a novel meta-learning algorithm for unsupervised neural machine translation (UNMT) that trains the model to adapt to another domain by utilizing only a small amount of training data. We assume that domain-general knowledge is a significant factor in handling data-scarce domains. Hence, we extend the meta-learning algorithm, which utilizes knowledge learned from high-resource domains, to boost the performance of low-resource UNMT. Our model surpasses a transfer learning-based approach by up to 2-3 BLEU scores. Extensive experimental results show that our proposed algorithm is pertinent for fast adaptation and consistently outperforms other baselines.
Large-scale models for learning fixed-dimensional cross-lingual sentence representations like LASER (Artetxe and Schwenk, 2019b) lead to significant improvement in performance on downstream tasks. However, further increases and modifications based on such large-scale models are usually impractical due to memory limitations. In this work, we introduce a lightweight dual-transformer architecture with just 2 layers for generating memory-efficient cross-lingual sentence representations. We explore different training tasks and observe that current cross-lingual training tasks leave a lot to be desired for this shallow architecture. To ameliorate this, we propose a novel cross-lingual language model, which combines the existing single-word masked language model with the newly proposed cross-lingual token-level reconstruction task. We further augment the training task by the introduction of two computationally-lite sentence-level contrastive learning tasks to enhance the alignment of cross-lingual sentence representation space, which compensates for the learning bottleneck of the lightweight transformer for generative tasks. Our comparisons with competing models on cross-lingual sentence retrieval and multilingual document classification confirm the effectiveness of the newly proposed training tasks for a shallow model.
Transformers are not suited for processing long documents, due to their quadratically increasing memory and time consumption. Simply truncating a long document or applying the sparse attention mechanism will incur the context fragmentation problem or lead to an inferior modeling capability against comparable model sizes. In this paper, we propose ERNIE-Doc, a document-level language pretraining model based on Recurrence Transformers. Two well-designed techniques, namely the retrospective feed mechanism and the enhanced recurrence mechanism, enable ERNIE-Doc, which has a much longer effective context length, to capture the contextual information of a complete document. We pretrain ERNIE-Doc to explicitly learn the relationships among segments with an additional document-aware segment-reordering objective. Various experiments were conducted on both English and Chinese document-level tasks. ERNIE-Doc improved the state-of-the-art language modeling result of perplexity to 16.8 on WikiText-103. Moreover, it outperformed competitive pretraining models by a large margin on most language understanding tasks, such as text classification and question answering.
Recently, knowledge distillation (KD) has shown great success in BERT compression. Instead of only learning from the teacher’s soft label as in conventional KD, researchers find that the rich information contained in the hidden layers of BERT is conducive to the student’s performance. To better exploit the hidden knowledge, a common practice is to force the student to deeply mimic the teacher’s hidden states of all the tokens in a layer-wise manner. In this paper, however, we observe that although distilling the teacher’s hidden state knowledge (HSK) is helpful, the performance gain (marginal utility) diminishes quickly as more HSK is distilled. To understand this effect, we conduct a series of analysis. Specifically, we divide the HSK of BERT into three dimensions, namely depth, length and width. We first investigate a variety of strategies to extract crucial knowledge for each single dimension and then jointly compress the three dimensions. In this way, we show that 1) the student’s performance can be improved by extracting and distilling the crucial HSK, and 2) using a tiny fraction of HSK can achieve the same performance as extensive HSK distillation. Based on the second finding, we further propose an efficient KD paradigm to compress BERT, which does not require loading the teacher during the training of student. For two kinds of student models and computing devices, the proposed KD paradigm gives rise to training speedup of 2.7x 3.4x.
Lifelong learning (LL) aims to train a neural network on a stream of tasks while retaining knowledge from previous tasks. However, many prior attempts in NLP still suffer from the catastrophic forgetting issue, where the model completely forgets what it just learned in the previous tasks. In this paper, we introduce Rational LAMOL, a novel end-to-end LL framework for language models. In order to alleviate catastrophic forgetting, Rational LAMOL enhances LAMOL, a recent LL model, by applying critical freezing guided by human rationales. When the human rationales are not available, we propose exploiting unsupervised generated rationales as substitutions. In the experiment, we tested Rational LAMOL on permutations of three datasets from the ERASER benchmark. The results show that our proposed framework outperformed vanilla LAMOL on most permutations. Furthermore, unsupervised rationale generation was able to consistently improve the overall LL performance from the baseline without relying on human-annotated rationales.
Natural language processing (NLP) often faces the problem of data diversity such as different domains, themes, styles, and so on. Therefore, a single language model (LM) is insufficient to learn all knowledge from diverse samples. To solve this problem, we firstly propose an autoencoding topic model with a mixture prior (mATM) to perform clustering for the data, where the clusters defined in semantic space describes the data diversity. Having obtained the clustering assignment for each sample, we develop the ensemble LM (EnsLM) with the technique of weight modulation. Specifically, EnsLM contains a backbone that is adjusted by a few modulated weights to fit for different sample clusters. As a result, the backbone learns the shared knowledge among all clusters while modulated weights extract the cluster-specific features. EnsLM can be trained jointly with mATM with a flexible LM backbone. We evaluate the effectiveness of both mATM and EnsLM on various tasks.
Pre-trained language models like BERT are performant in a wide range of natural language tasks. However, they are resource exhaustive and computationally expensive for industrial scenarios. Thus, early exits are adopted at each layer of BERT to perform adaptive computation by predicting easier samples with the first few layers to speed up the inference. In this work, to improve efficiency without performance drop, we propose a novel training scheme called Learned Early Exit for BERT (LeeBERT). First, we ask each exit to learn from each other, rather than learning only from the last layer. Second, the weights of different loss terms are learned, thus balancing off different objectives. We formulate the optimization of LeeBERT as a bi-level optimization problem, and we propose a novel cross-level optimization (CLO) algorithm to improve the optimization results. Experiments on the GLUE benchmark show that our proposed methods improve the performance of the state-of-the-art (SOTA) early exit methods for pre-trained models.
We pioneer the first extractive summarization-based collaborative filtering model called ESCOFILT. Our proposed model specifically produces extractive summaries for each item and user. Unlike other types of explanations, summary-level explanations closely resemble real-life explanations. The strength of ESCOFILT lies in the fact that it unifies representation and explanation. In other words, extractive summaries both represent and explain the items and users. Our model uniquely integrates BERT, K-Means embedding clustering, and multilayer perceptron to learn sentence embeddings, representation-explanations, and user-item interactions, respectively. We argue that our approach enhances both rating prediction accuracy and user/item explainability. Our experiments illustrate that ESCOFILT’s prediction accuracy is better than the other state-of-the-art recommender models. Furthermore, we propose a comprehensive set of criteria that assesses the real-life explainability of explanations. Our explainability study demonstrates the superiority of and preference for summary-level explanations over other explanation types.
Chinese spelling correction (CSC) is a task to detect and correct spelling errors in texts. CSC is essentially a linguistic problem, thus the ability of language understanding is crucial to this task. In this paper, we propose a Pre-trained masked Language model with Misspelled knowledgE (PLOME) for CSC, which jointly learns how to understand language and correct spelling errors. To this end, PLOME masks the chosen tokens with similar characters according to a confusion set rather than the fixed token “[MASK]” as in BERT. Besides character prediction, PLOME also introduces pronunciation prediction to learn the misspelled knowledge on phonic level. Moreover, phonological and visual similarity knowledge is important to this task. PLOME utilizes GRU networks to model such knowledge based on characters’ phonics and strokes. Experiments are conducted on widely used benchmarks. Our method achieves superior performance against state-of-the-art approaches by a remarkable margin. We release the source code and pre-trained model for further use by the community (https://github.com/liushulinle/PLOME).
Medical report generation task, which targets to produce long and coherent descriptions of medical images, has attracted growing research interests recently. Different from the general image captioning tasks, medical report generation is more challenging for data-driven neural models. This is mainly due to 1) the serious data bias and 2) the limited medical data. To alleviate the data bias and make best use of available data, we propose a Competence-based Multimodal Curriculum Learning framework (CMCL). Specifically, CMCL simulates the learning process of radiologists and optimizes the model in a step by step manner. Firstly, CMCL estimates the difficulty of each training instance and evaluates the competence of current model; Secondly, CMCL selects the most suitable batch of training instances considering current model competence. By iterating above two steps, CMCL can gradually improve the model’s performance. The experiments on the public IU-Xray and MIMIC-CXR datasets show that CMCL can be incorporated into existing models to improve their performance.
Deep learning models for automatic readability assessment generally discard linguistic features traditionally used in machine learning models for the task. We propose to incorporate linguistic features into neural network models by learning syntactic dense embeddings based on linguistic features. To cope with the relationships between the features, we form a correlation graph among features and use it to learn their embeddings so that similar features will be represented by similar embeddings. Experiments with six data sets of two proficiency levels demonstrate that our proposed methodology can complement BERT-only model to achieve significantly better performances for automatic readability assessment.
Pre-trained language models have been applied to various NLP tasks with considerable performance gains. However, the large model sizes, together with the long inference time, limit the deployment of such models in real-time applications. One line of model compression approaches considers knowledge distillation to distill large teacher models into small student models. Most of these studies focus on single-domain only, which ignores the transferable knowledge from other domains. We notice that training a teacher with transferable knowledge digested across domains can achieve better generalization capability to help knowledge distillation. Hence we propose a Meta-Knowledge Distillation (Meta-KD) framework to build a meta-teacher model that captures transferable knowledge across domains and passes such knowledge to students. Specifically, we explicitly force the meta-teacher to capture transferable knowledge at both instance-level and feature-level from multiple domains, and then propose a meta-distillation algorithm to learn single-domain student models with guidance from the meta-teacher. Experiments on public multi-domain NLP tasks show the effectiveness and superiority of the proposed Meta-KD framework. Further, we also demonstrate the capability of Meta-KD in the settings where the training data is scarce.
Unsupervised commonsense question answering is appealing since it does not rely on any labeled task data. Among existing work, a popular solution is to use pre-trained language models to score candidate choices directly conditioned on the question or context. However, such scores from language models can be easily affected by irrelevant factors, such as word frequencies, sentence structures, etc. These distracting factors may not only mislead the model to choose a wrong answer but also make it oversensitive to lexical perturbations in candidate answers. In this paper, we present a novel SEmantic-based Question Answering method (SEQA) for unsupervised commonsense question answering. Instead of directly scoring each answer choice, our method first generates a set of plausible answers with generative models (e.g., GPT-2), and then uses these plausible answers to select the correct choice by considering the semantic similarity between each plausible answer and each choice. We devise a simple, yet sound formalism for this idea and verify its effectiveness and robustness with extensive experiments. We evaluate the proposed method on four benchmark datasets, and our method achieves the best results in unsupervised settings. Moreover, when attacked by TextFooler with synonym replacement, SEQA demonstrates much less performance drops than baselines, thereby indicating stronger robustness.
CommonsenseQA (CQA) (Talmor et al., 2019) dataset was recently released to advance the research on common-sense question answering (QA) task. Whereas the prior work has mostly focused on proposing QA models for this dataset, our aim is to retrieve as well as generate explanation for a given (question, correct answer choice, incorrect answer choices) tuple from this dataset. Our explanation definition is based on certain desiderata, and translates an explanation into a set of positive and negative common-sense properties (aka facts) which not only explain the correct answer choice but also refute the incorrect ones. We human-annotate a first-of-its-kind dataset (called ECQA) of positive and negative properties, as well as free-flow explanations, for 11K QA pairs taken from the CQA dataset. We propose a latent representation based property retrieval model as well as a GPT-2 based property generation model with a novel two step fine-tuning procedure. We also propose a free-flow explanation generation model. Extensive experiments show that our retrieval model beats BM25 baseline by a relative gain of 100% in F1 score, property generation model achieves a respectable F1 score of 36.4, and free-flow generation model achieves a similarity score of 61.9, where last two scores are based on a human correlated semantic similarity metric.
In several question answering benchmarks, pretrained models have reached human parity through fine-tuning on an order of 100,000 annotated questions and answers. We explore the more realistic few-shot setting, where only a few hundred training examples are available, and observe that standard models perform poorly, highlighting the discrepancy between current pretraining objectives and question answering. We propose a new pretraining scheme tailored for question answering: recurring span selection. Given a passage with multiple sets of recurring spans, we mask in each set all recurring spans but one, and ask the model to select the correct span in the passage for each masked span. Masked spans are replaced with a special token, viewed as a question representation, that is later used during fine-tuning to select the answer span. The resulting model obtains surprisingly good results on multiple benchmarks (e.g., 72.7 F1 on SQuAD with only 128 training examples), while maintaining competitive performance in the high-resource setting.
To date, most of recent work under the retrieval-reader framework for open-domain QA focuses on either extractive or generative reader exclusively. In this paper, we study a hybrid approach for leveraging the strengths of both models. We apply novel techniques to enhance both extractive and generative readers built upon recent pretrained neural language models, and find that proper training methods can provide large improvement over previous state-of-the-art models. We demonstrate that a simple hybrid approach by combining answers from both readers can efficiently take advantages of extractive and generative answer inference strategies and outperforms single models as well as homogeneous ensembles. Our approach outperforms previous state-of-the-art models by 3.3 and 2.7 points in exact match on NaturalQuestions and TriviaQA respectively.
Neural models have shown impressive performance gains in answering queries from natural language text. However, existing works are unable to support database queries, such as “List/Count all female athletes who were born in 20th century”, which require reasoning over sets of relevant facts with operations such as join, filtering and aggregation. We show that while state-of-the-art transformer models perform very well for small databases, they exhibit limitations in processing noisy data, numerical operations, and queries that aggregate facts. We propose a modular architecture to answer these database-style queries over multiple spans from text and aggregating these at scale. We evaluate the architecture using WikiNLDB, a novel dataset for exploring such queries. Our architecture scales to databases containing thousands of facts whereas contemporary models are limited by how many facts can be encoded. In direct comparison on small databases, our approach increases overall answer accuracy from 85% to 90%. On larger databases, our approach retains its accuracy whereas transformer baselines could not encode the context.
In Machine Translation, assessing the quality of a large amount of automatic translations can be challenging. Automatic metrics are not reliable when it comes to high performing systems. In addition, resorting to human evaluators can be expensive, especially when evaluating multiple systems. To overcome the latter challenge, we propose a novel application of online learning that, given an ensemble of Machine Translation systems, dynamically converges to the best systems, by taking advantage of the human feedback available. Our experiments on WMT’19 datasets show that our online approach quickly converges to the top-3 ranked systems for the language pairs considered, despite the lack of human feedback for many translations.
In this work, we provide a systematic and comprehensive empirical comparison of pretrained multilingual language models versus their monolingual counterparts with regard to their monolingual task performance. We study a set of nine typologically diverse languages with readily available pretrained monolingual models on a set of five diverse monolingual downstream tasks. We first aim to establish, via fair and controlled comparisons, if a gap between the multilingual and the corresponding monolingual representation of that language exists, and subsequently investigate the reason for any performance difference. To disentangle conflating factors, we train new monolingual models on the same data, with monolingually and multilingually trained tokenizers. We find that while the pretraining data size is an important factor, a designated monolingual tokenizer plays an equally important role in the downstream performance. Our results show that languages that are adequately represented in the multilingual model’s vocabulary exhibit negligible performance decreases over their monolingual counterparts. We further find that replacing the original multilingual tokenizer with the specialized monolingual tokenizer improves the downstream performance of the multilingual model for almost every task and language.
Cross-lingual transfer has improved greatly through multi-lingual language model pretraining, reducing the need for parallel data and increasing absolute performance. However, this progress has also brought to light the differences in performance across languages. Specifically, certain language families and typologies seem to consistently perform worse in these models. In this paper, we address what effects morphological typology has on zero-shot cross-lingual transfer for two tasks: Part-of-speech tagging and sentiment analysis. We perform experiments on 19 languages from four language typologies (fusional, isolating, agglutinative, and introflexive) and find that transfer to another morphological type generally implies a higher loss than transfer to another language with the same morphological typology. Furthermore, POS tagging is more sensitive to morphological typology than sentiment analysis and, on this task, models perform much better on fusional languages than on the other typologies.
Generating code-switched text is a problem of growing interest, especially given the scarcity of corpora containing large volumes of real code-switched text. In this work, we adapt a state-of-the-art neural machine translation model to generate Hindi-English code-switched sentences starting from monolingual Hindi sentences. We outline a carefully designed curriculum of pretraining steps, including the use of synthetic code-switched text, that enable the model to generate high-quality code-switched text. Using text generated from our model as data augmentation, we show significant reductions in perplexity on a language modeling task, compared to using text from other generative models of CS text. We also show improvements using our text for a downstream code-switched natural language inference task. Our generated text is further subjected to a rigorous evaluation using a human evaluation study and a range of objective metrics, where we show performance comparable (and sometimes even superior) to code-switched text obtained via crowd workers who are native Hindi speakers.
It is generally believed that a translation memory (TM) should be beneficial for machine translation tasks. Unfortunately, existing wisdom demonstrates the superiority of TM-based neural machine translation (NMT) only on the TM-specialized translation tasks rather than general tasks, with a non-negligible computational overhead. In this paper, we propose a fast and accurate approach to TM-based NMT within the Transformer framework: the model architecture is simple and employs a single bilingual sentence as its TM, leading to efficient training and inference; and its parameters are effectively optimized through a novel training criterion. Extensive experiments on six TM-specialized tasks show that the proposed approach substantially surpasses several strong baselines that use multiple TMs, in terms of BLEU and running time. In particular, the proposed approach also advances the strong baselines on two general tasks (WMT news Zh->En and En->De).
Online misogyny, a category of online abusive language, has serious and harmful social consequences. Automatic detection of misogynistic language online, while imperative, poses complicated challenges to both data gathering, data annotation, and bias mitigation, as this type of data is linguistically complex and diverse. This paper makes three contributions in this area: Firstly, we describe the detailed design of our iterative annotation process and codebook. Secondly, we present a comprehensive taxonomy of labels for annotating misogyny in natural written language, and finally, we introduce a high-quality dataset of annotated posts sampled from social media posts.
Recently, considerable literature has grown up around the theme of few-shot named entity recognition (NER), but little published benchmark data specifically focused on the practical and challenging task. Current approaches collect existing supervised NER datasets and re-organize them to the few-shot setting for empirical study. These strategies conventionally aim to recognize coarse-grained entity types with few examples, while in practice, most unseen entity types are fine-grained. In this paper, we present Few-NERD, a large-scale human-annotated few-shot NER dataset with a hierarchy of 8 coarse-grained and 66 fine-grained entity types. Few-NERD consists of 188,238 sentences from Wikipedia, 4,601,160 words are included and each is annotated as context or a part of the two-level entity type. To the best of our knowledge, this is the first few-shot NER dataset and the largest human-crafted NER dataset. We construct benchmark tasks with different emphases to comprehensively assess the generalization capability of models. Extensive empirical results and analysis show that Few-NERD is challenging and the problem requires further research. The Few-NERD dataset and the baselines will be publicly available to facilitate the research on this problem.
Metaphor involves not only a linguistic phenomenon, but also a cognitive phenomenon structuring human thought, which makes understanding it challenging. As a means of cognition, metaphor is rendered by more than texts alone, and multimodal information in which vision/audio content is integrated with the text can play an important role in expressing and understanding metaphor. However, previous metaphor processing and understanding has focused on texts, partly due to the unavailability of large-scale datasets with ground truth labels of multimodal metaphor. In this paper, we introduce MultiMET, a novel multimodal metaphor dataset to facilitate understanding metaphorical information from multimodal text and image. It contains 10,437 text-image pairs from a range of sources with multimodal annotations of the occurrence of metaphors, domain relations, sentiments metaphors convey, and author intents. MultiMET opens the door to automatic metaphor understanding by investigating multimodal cues and their interplay. Moreover, we propose a range of strong baselines and show the importance of combining multimodal cues for metaphor understanding. MultiMET will be released publicly for research.
Undermining the impact of hateful content with informed and non-aggressive responses, called counter narratives, has emerged as a possible solution for having healthier online communities. Thus, some NLP studies have started addressing the task of counter narrative generation. Although such studies have made an effort to build hate speech / counter narrative (HS/CN) datasets for neural generation, they fall short in reaching either high-quality and/or high-quantity. In this paper, we propose a novel human-in-the-loop data collection methodology in which a generative language model is refined iteratively by using its own data from the previous loops to generate new training samples that experts review and/or post-edit. Our experiments comprised several loops including diverse dynamic variations. Results show that the methodology is scalable and facilitates diverse, novel, and cost-effective data collection. To our knowledge, the resulting dataset is the only expert-based multi-target HS/CN dataset available to the community.
Recent work has investigated the interesting question using pre-trained language models (PLMs) as knowledge bases for answering open questions. However, existing work is limited in using small benchmarks with high test-train overlaps. We construct a new dataset of closed-book QA using SQuAD, and investigate the performance of BART. Experiments show that it is challenging for BART to remember training facts in high precision, and also challenging to answer closed-book questions even if relevant knowledge is retained. Some promising directions are found, including decoupling the knowledge memorizing process and the QA finetune process, forcing the model to recall relevant knowledge when question answering.
This paper studies joint models for selecting correct answer sentences among the top k provided by answer sentence selection (AS2) modules, which are core components of retrieval-based Question Answering (QA) systems. Our work shows that a critical step to effectively exploiting an answer set regards modeling the interrelated information between pair of answers. For this purpose, we build a three-way multi-classifier, which decides if an answer supports, refutes, or is neutral with respect to another one. More specifically, our neural architecture integrates a state-of-the-art AS2 module with the multi-classifier, and a joint layer connecting all components. We tested our models on WikiQA, TREC-QA, and a real-world dataset. The results show that our models obtain the new state of the art in AS2.
In open-domain question answering, questions are highly likely to be ambiguous because users may not know the scope of relevant topics when formulating them. Therefore, a system needs to find possible interpretations of the question, and predict one or multiple plausible answers. When multiple plausible answers are found, the system should rewrite the question for each answer to resolve the ambiguity. In this paper, we present a model that aggregates and combines evidence from multiple passages to adaptively predict a single answer or a set of question-answer pairs for ambiguous questions. In addition, we propose a novel round-trip prediction approach to iteratively generate additional interpretations that our model fails to find in the first pass, and then verify and filter out the incorrect question-answer pairs to arrive at the final disambiguated output. Our model, named Refuel, achieves a new state-of-the-art performance on the AmbigQA dataset, and shows competitive performance on NQ-Open and TriviaQA. The proposed round-trip prediction is a model-agnostic general approach for answering ambiguous open-domain questions, which improves our Refuel as well as several baseline models. We release source code for our models and experiments at https://github.com/amzn/refuel-open-domain-qa.
Hybrid data combining both tabular and textual content (e.g., financial reports) are quite pervasive in the real world. However, Question Answering (QA) over such hybrid data is largely neglected in existing research. In this work, we extract samples from real financial reports to build a new large-scale QA dataset containing both Tabular And Textual data, named TAT-QA, where numerical reasoning is usually required to infer the answer, such as addition, subtraction, multiplication, division, counting, comparison/sorting, and the compositions. We further propose a novel QA model termed TAGOP, which is capable of reasoning over both tables and text. It adopts sequence tagging to extract relevant cells from the table along with relevant spans from the text to infer their semantics, and then applies symbolic reasoning over them with a set of aggregation operators to arrive at the final answer. TAGOP achieves 58.0% inF1, which is an 11.1% absolute increase over the previous best baseline model, according to our experiments on TAT-QA. But this result still lags far behind performance of expert human, i.e.90.8% in F1. It is demonstrated that our TAT-QA is very challenging and can serve as a benchmark for training and testing powerful QA models that address hybrid form data.
Conversational KBQA is about answering a sequence of questions related to a KB. Follow-up questions in conversational KBQA often have missing information referring to entities from the conversation history. In this paper, we propose to model these implied entities, which we refer to as the focal entities of the conversation. We propose a novel graph-based model to capture the transitions of focal entities and apply a graph neural network to derive a probability distribution of focal entities for each question, which is then combined with a standard KBQA module to perform answer ranking. Our experiments on two datasets demonstrate the effectiveness of our proposed method.
This paper introduces the task of factual error correction: performing edits to a claim so that the generated rewrite is better supported by evidence. This extends the well-studied task of fact verification by providing a mechanism to correct written texts that are refuted or only partially supported by evidence. We demonstrate that it is feasible to train factual error correction systems from existing fact checking datasets which only contain labeled claims accompanied by evidence, but not the correction. We achieve this by employing a two-stage distant supervision approach that incorporates evidence into masked claims when generating corrections. Our approach, based on the T5 transformer and using retrieved evidence, achieved better results than existing work which used a pointer copy network and gold evidence, producing accurate factual error corrections for 5x more instances in human evaluation and a .125 increase in SARI score. The evaluation is conducted on a dataset of 65,000 instances based on a recent fact verification shared task and we release it to enable further work on the task.
We present algorithms for aligning components of Abstract Meaning Representation (AMR) graphs to spans in English sentences. We leverage unsupervised learning in combination with heuristics, taking the best of both worlds from previous AMR aligners. Our unsupervised models, however, are more sensitive to graph substructures, without requiring a separate syntactic parse. Our approach covers a wider variety of AMR substructures than previously considered, achieves higher coverage of nodes and edges, and does so with higher accuracy. We will release our LEAMR datasets and aligner for use in research on AMR parsing, generation, and evaluation.
Natural language is compositional; the meaning of a sentence is a function of the meaning of its parts. This property allows humans to create and interpret novel sentences, generalizing robustly outside their prior experience. Neural networks have been shown to struggle with this kind of generalization, in particular performing poorly on tasks designed to assess compositional generalization (i.e. where training and testing distributions differ in ways that would be trivial for a compositional strategy to resolve). Their poor performance on these tasks may in part be due to the nature of supervised learning which assumes training and testing data to be drawn from the same distribution. We implement a meta-learning augmented version of supervised learning whose objective directly optimizes for out-of-distribution generalization. We construct pairs of tasks for meta-learning by sub-sampling existing training data. Each pair of tasks is constructed to contain relevant examples, as determined by a similarity metric, in an effort to inhibit models from memorizing their input. Experimental results on the COGS and SCAN datasets show that our similarity-driven meta-learning can improve generalization performance.
Large pre-trained models such as BERT are known to improve different downstream NLP tasks, even when such a model is trained on a generic domain. Moreover, recent studies have shown that when large domain-specific corpora are available, continued pre-training on domain-specific data can further improve the performance of in-domain tasks. However, this practice requires significant domain-specific data and computational resources which may not always be available. In this paper, we aim to adapt a generic pretrained model with a relatively small amount of domain-specific data. We demonstrate that by explicitly incorporating multi-granularity information of unseen and domain-specific words via the adaptation of (word based) n-grams, the performance of a generic pretrained model can be greatly improved. Specifically, we introduce a Transformer-based Domain-aware N-gram Adaptor, T-DNA, to effectively learn and incorporate the semantic representation of different combinations of words in the new domain. Experimental results illustrate the effectiveness of T-DNA on eight low-resource downstream tasks from four domains. We show that T-DNA is able to achieve significant improvements compared to existing methods on most tasks using limited data with lower computational costs. Moreover, further analyses demonstrate the importance and effectiveness of both unseen words and the information of different granularities. Our code is available at https://github.com/shizhediao/T-DNA.
Pre-trained Language Models (PLMs) have shown superior performance on various downstream Natural Language Processing (NLP) tasks. However, conventional pre-training objectives do not explicitly model relational facts in text, which are crucial for textual understanding. To address this issue, we propose a novel contrastive learning framework ERICA to obtain a deep understanding of the entities and their relations in text. Specifically, we define two novel pre-training tasks to better understand entities and relations: (1) the entity discrimination task to distinguish which tail entity can be inferred by the given head entity and relation; (2) the relation discrimination task to distinguish whether two relations are close or not semantically, which involves complex relational reasoning. Experimental results demonstrate that ERICA can improve typical PLMs (BERT and RoBERTa) on several language understanding tasks, including relation extraction, entity typing and question answering, especially under low-resource settings.
The Emotion Cause Extraction (ECE) task aims to identify clauses which contain emotion-evoking information for a particular emotion expressed in text. We observe that a widely-used ECE dataset exhibits a bias that the majority of annotated cause clauses are either directly before their associated emotion clauses or are the emotion clauses themselves. Existing models for ECE tend to explore such relative position information and suffer from the dataset bias. To investigate the degree of reliance of existing ECE models on clause relative positions, we propose a novel strategy to generate adversarial examples in which the relative position information is no longer the indicative feature of cause clauses. We test the performance of existing models on such adversarial examples and observe a significant performance drop. To address the dataset bias, we propose a novel graph-based method to explicitly model the emotion triggering paths by leveraging the commonsense knowledge to enhance the semantic dependencies between a candidate clause and an emotion clause. Experimental results show that our proposed approach performs on par with the existing state-of-the-art methods on the original ECE dataset, and is more robust against adversarial attacks compared to existing models.
Previous work on review summarization focused on measuring the sentiment toward the main aspects of the reviewed product or business, or on creating a textual summary. These approaches provide only a partial view of the data: aspect-based sentiment summaries lack sufficient explanation or justification for the aspect rating, while textual summaries do not quantify the significance of each element, and are not well-suited for representing conflicting views. Recently, Key Point Analysis (KPA) has been proposed as a summarization framework that provides both textual and quantitative summary of the main points in the data. We adapt KPA to review data by introducing Collective Key Point Mining for better key point extraction; integrating sentiment analysis into KPA; identifying good key point candidates for review summaries; and leveraging the massive amount of available reviews and their metadata. We show empirically that these novel extensions of KPA substantially improve its performance. We demonstrate that promising results can be achieved without any domain-specific annotation, while human supervision can lead to further improvement.
Structured sentiment analysis attempts to extract full opinion tuples from a text, but over time this task has been subdivided into smaller and smaller sub-tasks, e.g., target extraction or targeted polarity classification. We argue that this division has become counterproductive and propose a new unified framework to remedy the situation. We cast the structured sentiment problem as dependency graph parsing, where the nodes are spans of sentiment holders, targets and expressions, and the arcs are the relations between them. We perform experiments on five datasets in four languages (English, Norwegian, Basque, and Catalan) and show that this approach leads to strong improvements over state-of-the-art baselines. Our analysis shows that refining the sentiment graphs with syntactic dependency information further improves results.
Fine-tuning pre-trained cross-lingual language models can transfer task-specific supervision from one language to the others. In this work, we propose to improve cross-lingual fine-tuning with consistency regularization. Specifically, we use example consistency regularization to penalize the prediction sensitivity to four types of data augmentations, i.e., subword sampling, Gaussian noise, code-switch substitution, and machine translation. In addition, we employ model consistency to regularize the models trained with two augmented versions of the same training set. Experimental results on the XTREME benchmark show that our method significantly improves cross-lingual fine-tuning across various tasks, including text classification, question answering, and sequence labeling.
The cross-lingual language models are typically pretrained with masked language modeling on multilingual text or parallel sentences. In this paper, we introduce denoising word alignment as a new cross-lingual pre-training task. Specifically, the model first self-label word alignments for parallel sentences. Then we randomly mask tokens in a bitext pair. Given a masked token, the model uses a pointer network to predict the aligned token in the other language. We alternately perform the above two steps in an expectation-maximization manner. Experimental results show that our method improves cross-lingual transferability on various datasets, especially on the token-level tasks, such as question answering, and structured prediction. Moreover, the model can serve as a pretrained word aligner, which achieves reasonably low error rate on the alignment benchmarks. The code and pretrained parameters are available at github.com/CZWin32768/XLM-Align.
Knowledge distillation (KD) is commonly used to construct synthetic data for training non-autoregressive translation (NAT) models. However, there exists a discrepancy on low-frequency words between the distilled and the original data, leading to more errors on predicting low-frequency words. To alleviate the problem, we directly expose the raw data into NAT by leveraging pretraining. By analyzing directed alignments, we found that KD makes low-frequency source words aligned with targets more deterministically but fails to align sufficient low-frequency words from target to source. Accordingly, we propose reverse KD to rejuvenate more alignments for low-frequency target words. To make the most of authentic and synthetic data, we combine these complementary approaches as a new training strategy for further boosting NAT performance. We conduct experiments on five translation benchmarks over two advanced architectures. Results demonstrate that the proposed approach can significantly and universally improve translation quality by reducing translation errors on low-frequency words. Encouragingly, our approach achieves 28.2 and 33.9 BLEU points on the WMT14 English-German and WMT16 Romanian-English datasets, respectively. Our code, data, and trained models are available at https://github.com/longyuewangdcu/RLFW-NAT.
Document-level MT models are still far from satisfactory. Existing work extend translation unit from single sentence to multiple sentences. However, study shows that when we further enlarge the translation unit to a whole document, supervised training of Transformer can fail. In this paper, we find such failure is not caused by overfitting, but by sticking around local minima during training. Our analysis shows that the increased complexity of target-to-source attention is a reason for the failure. As a solution, we propose G-Transformer, introducing locality assumption as an inductive bias into Transformer, reducing the hypothesis space of the attention from target to source. Experiments show that G-Transformer converges faster and more stably than Transformer, achieving new state-of-the-art BLEU scores for both nonpretraining and pre-training settings on three benchmark datasets.
The Neural Machine Translation (NMT) model is essentially a joint language model conditioned on both the source sentence and partial translation. Therefore, the NMT model naturally involves the mechanism of the Language Model (LM) that predicts the next token only based on partial translation. Despite its success, NMT still suffers from the hallucination problem, generating fluent but inadequate translations. The main reason is that NMT pays excessive attention to the partial translation while neglecting the source sentence to some extent, namely overconfidence of the LM. Accordingly, we define the Margin between the NMT and the LM, calculated by subtracting the predicted probability of the LM from that of the NMT model for each token. The Margin is negatively correlated to the overconfidence degree of the LM. Based on the property, we propose a Margin-based Token-level Objective (MTO) and a Margin-based Sentence-level Objective (MSO) to maximize the Margin for preventing the LM from being overconfident. Experiments on WMT14 English-to-German, WMT19 Chinese-to-English, and WMT14 English-to-French translation tasks demonstrate the effectiveness of our approach, with 1.36, 1.50, and 0.63 BLEU improvements, respectively, compared to the Transformer baseline. The human evaluation further verifies that our approaches improve translation adequacy as well as fluency.
Emotional support is a crucial ability for many conversation scenarios, including social interactions, mental health support, and customer service chats. Following reasonable procedures and using various support skills can help to effectively provide support. However, due to the lack of a well-designed task and corpora of effective emotional support conversations, research on building emotional support into dialog systems remains lacking. In this paper, we define the Emotional Support Conversation (ESC) task and propose an ESC Framework, which is grounded on the Helping Skills Theory. We construct an Emotion Support Conversation dataset (ESConv) with rich annotation (especially support strategy) in a help-seeker and supporter mode. To ensure a corpus of high-quality conversations that provide examples of effective emotional support, we take extensive effort to design training tutorials for supporters and several mechanisms for quality control during data collection. Finally, we evaluate state-of-the-art dialog models with respect to the ability to provide emotional support. Our results show the importance of support strategies in providing effective emotional support and the utility of ESConv in training more emotional support systems.
Existing slot filling models can only recognize pre-defined in-domain slot types from a limited slot set. In the practical application, a reliable dialogue system should know what it does not know. In this paper, we introduce a new task, Novel Slot Detection (NSD), in the task-oriented dialogue system. NSD aims to discover unknown or out-of-domain slot types to strengthen the capability of a dialogue system based on in-domain training data. Besides, we construct two public NSD datasets, propose several strong NSD baselines, and establish a benchmark for future work. Finally, we conduct exhaustive experiments and qualitative analysis to comprehend key challenges and provide new guidance for future directions.
Generating some appealing questions in open-domain conversations is an effective way to improve human-machine interactions and lead the topic to a broader or deeper direction. To avoid dull or deviated questions, some researchers tried to utilize answer, the “future” information, to guide question generation. However, they separate a post-question-answer (PQA) triple into two parts: post-question (PQ) and question-answer (QA) pairs, which may hurt the overall coherence. Besides, the QA relationship is modeled as a one-to-one mapping that is not reasonable in open-domain conversations. To tackle these problems, we propose a generative triple-wise model with hierarchical variations for open-domain conversational question generation (CQG). Latent variables in three hierarchies are used to represent the shared background of a triple and one-to-many semantic mappings in both PQ and QA pairs. Experimental results on a large-scale CQG dataset show that our method significantly improves the quality of questions in terms of fluency, coherence and diversity over competitive baselines.
Neural dialogue generation models trained with the one-hot target distribution suffer from the over-confidence issue, which leads to poor generation diversity as widely reported in the literature. Although existing approaches such as label smoothing can alleviate this issue, they fail to adapt to diverse dialog contexts. In this paper, we propose an Adaptive Label Smoothing (AdaLabel) approach that can adaptively estimate a target label distribution at each time step for different contexts. The maximum probability in the predicted distribution is used to modify the soft target distribution produced by a novel light-weight bi-directional decoder module. The resulting target distribution is aware of both previous and future contexts and is adjusted to avoid over-training the dialogue model. Our model can be trained in an endto-end manner. Extensive experiments on two benchmark datasets show that our approach outperforms various competitive baselines in producing diverse responses.
Out-of-scope intent detection is of practical importance in task-oriented dialogue systems. Since the distribution of outlier utterances is arbitrary and unknown in the training stage, existing methods commonly rely on strong assumptions on data distribution such as mixture of Gaussians to make inference, resulting in either complex multi-step training procedures or hand-crafted rules such as confidence threshold selection for outlier detection. In this paper, we propose a simple yet effective method to train an out-of-scope intent classifier in a fully end-to-end manner by simulating the test scenario in training, which requires no assumption on data distribution and no additional post-processing or threshold setting. Specifically, we construct a set of pseudo outliers in the training stage, by generating synthetic outliers using inliner features via self-supervision and sampling out-of-scope sentences from easily available open-domain datasets. The pseudo outliers are used to train a discriminative classifier that can be directly applied to and generalize well on the test task. We evaluate our method extensively on four benchmark dialogue datasets and observe significant improvements over state-of-the-art approaches. Our code has been released at https://github.com/liam0949/DCLOOS.
Document-level event extraction aims to recognize event information from a whole piece of article. Existing methods are not effective due to two challenges of this task: a) the target event arguments are scattered across sentences; b) the correlation among events in a document is non-trivial to model. In this paper, we propose Heterogeneous Graph-based Interaction Model with a Tracker (GIT) to solve the aforementioned two challenges. For the first challenge, GIT constructs a heterogeneous graph interaction network to capture global interactions among different sentences and entity mentions. For the second, GIT introduces a Tracker module to track the extracted events and hence capture the interdependency among the events. Experiments on a large-scale dataset (Zheng et al, 2019) show GIT outperforms the previous methods by 2.8 F1. Further analysis reveals is effective in extracting multiple correlated events and event arguments that scatter across the document.
This paper presents a novel method for nested named entity recognition. As a layered method, our method extends the prior second-best path recognition method by explicitly excluding the influence of the best path. Our method maintains a set of hidden states at each time step and selectively leverages them to build a different potential function for recognition at each level. In addition, we demonstrate that recognizing innermost entities first results in better performance than the conventional outermost entities first scheme. We provide extensive experimental results on ACE2004, ACE2005, and GENIA datasets to show the effectiveness and efficiency of our proposed method.
Modern models for event causality identification (ECI) are mainly based on supervised learning, which are prone to the data lacking problem. Unfortunately, the existing NLP-related augmentation methods cannot directly produce available data required for this task. To solve the data lacking problem, we introduce a new approach to augment training data for event causality identification, by iteratively generating new examples and classifying event causality in a dual learning framework. On the one hand, our approach is knowledge guided, which can leverage existing knowledge bases to generate well-formed new sentences. On the other hand, our approach employs a dual mechanism, which is a learnable augmentation framework, and can interactively adjust the generation process to generate task-related sentences. Experimental results on two benchmarks EventStoryLine and Causal-TimeBank show that 1) our method can augment suitable task-related training data for ECI; 2) our method outperforms previous methods on EventStoryLine and Causal-TimeBank (+2.5 and +2.1 points on F1 value respectively).
Distantly supervision automatically generates plenty of training samples for relation extraction. However, it also incurs two major problems: noisy labels and imbalanced training data. Previous works focus more on reducing wrongly labeled relations (false positives) while few explore the missing relations that are caused by incompleteness of knowledge base (false negatives). Furthermore, the quantity of negative labels overwhelmingly surpasses the positive ones in previous problem formulations. In this paper, we first provide a thorough analysis of the above challenges caused by negative data. Next, we formulate the problem of relation extraction into as a positive unlabeled learning task to alleviate false negative problem. Thirdly, we propose a pipeline approach, dubbed ReRe, that first performs sentence classification with relational labels and then extracts the subjects/objects. Experimental results show that the proposed method consistently outperforms existing approaches and remains excellent performance even learned with a large quantity of false positive samples. Source code is available online at https://github.com/redreamality/RERE-relation-extraction.
This paper studies a new problem setting of entity alignment for knowledge graphs (KGs). Since KGs possess different sets of entities, there could be entities that cannot find alignment across them, leading to the problem of dangling entities. As the first attempt to this problem, we construct a new dataset and design a multi-task learning framework for both entity alignment and dangling entity detection. The framework can opt to abstain from predicting alignment for the detected dangling entities. We propose three techniques for dangling entity detection that are based on the distribution of nearest-neighbor distances, i.e., nearest neighbor classification, marginal ranking and background ranking. After detecting and removing dangling entities, an incorporated entity alignment model in our framework can provide more robust alignment for remaining entities. Comprehensive experiments and analyses demonstrate the effectiveness of our framework. We further discover that the dangling entity detection module can, in turn, improve alignment learning and the final performance. The contributed resource is publicly available to foster further research.
How does the input segmentation of pretrained language models (PLMs) affect their interpretations of complex words? We present the first study investigating this question, taking BERT as the example PLM and focusing on its semantic representations of English derivatives. We show that PLMs can be interpreted as serial dual-route models, i.e., the meanings of complex words are either stored or else need to be computed from the subwords, which implies that maximally meaningful input tokens should allow for the best generalization on new words. This hypothesis is confirmed by a series of semantic probing tasks on which DelBERT (Derivation leveraging BERT), a model with derivational input segmentation, substantially outperforms BERT with WordPiece segmentation. Our results suggest that the generalization capabilities of PLMs could be further improved if a morphologically-informed vocabulary of input tokens were used.
Analogies play a central role in human commonsense reasoning. The ability to recognize analogies such as “eye is to seeing what ear is to hearing”, sometimes referred to as analogical proportions, shape how we structure knowledge and understand language. Surprisingly, however, the task of identifying such analogies has not yet received much attention in the language model era. In this paper, we analyze the capabilities of transformer-based language models on this unsupervised task, using benchmarks obtained from educational settings, as well as more commonly used datasets. We find that off-the-shelf language models can identify analogies to a certain extent, but struggle with abstract and complex relations, and results are highly sensitive to model architecture and hyperparameters. Overall the best results were obtained with GPT-2 and RoBERTa, while configurations using BERT were not able to outperform word embedding models. Our results raise important questions for future work about how, and to what extent, pre-trained language models capture knowledge about abstract semantic relations.
This paper presents a multilingual study of word meaning representations in context. We assess the ability of both static and contextualized models to adequately represent different lexical-semantic relations, such as homonymy and synonymy. To do so, we created a new multilingual dataset that allows us to perform a controlled evaluation of several factors such as the impact of the surrounding context or the overlap between words, conveying the same or different senses. A systematic assessment on four scenarios shows that the best monolingual models based on Transformers can adequately disambiguate homonyms in context. However, as they rely heavily on context, these models fail at representing words with different senses when occurring in similar sentences. Experiments are performed in Galician, Portuguese, English, and Spanish, and both the dataset (with more than 3,000 evaluation items) and new models are freely released with this study.
We propose to measure fine-grained domain relevance– the degree that a term is relevant to a broad (e.g., computer science) or narrow (e.g., deep learning) domain. Such measurement is crucial for many downstream tasks in natural language processing. To handle long-tail terms, we build a core-anchored semantic graph, which uses core terms with rich description information to bridge the vast remaining fringe terms semantically. To support a fine-grained domain without relying on a matching corpus for supervision, we develop hierarchical core-fringe learning, which learns core and fringe terms jointly in a semi-supervised manner contextualized in the hierarchy of the domain. To reduce expensive human efforts, we employ automatic annotation and hierarchical positive-unlabeled learning. Our approach applies to big or small domains, covers head or tail terms, and requires little human effort. Extensive experiments demonstrate that our methods outperform strong baselines and even surpass professional human performance.
Open-domain dialog systems have a user-centric goal: to provide humans with an engaging conversation experience. User engagement is one of the most important metrics for evaluating open-domain dialog systems, and could also be used as real-time feedback to benefit dialog policy learning. Existing work on detecting user disengagement typically requires hand-labeling many dialog samples. We propose HERALD, an efficient annotation framework that reframes the training data annotation process as a denoising problem. Specifically, instead of manually labeling training samples, we first use a set of labeling heuristics to label training samples automatically. We then denoise the weakly labeled data using the Shapley algorithm. Finally, we use the denoised data to train a user engagement detector. Our experiments show that HERALD improves annotation efficiency significantly and achieves 86% user disengagement detection accuracy in two dialog corpora.
Conversational semantic parsers map user utterances to executable programs given dialogue histories composed of previous utterances, programs, and system responses. Existing parsers typically condition on rich representations of history that include the complete set of values and computations previously discussed. We propose a model that abstracts over values to focus prediction on type- and function-level context. This approach provides a compact encoding of dialogue histories and predicted programs, improving generalization and computational efficiency. Our model incorporates several other components, including an atomic span copy operation and structural enforcement of well-formedness constraints on predicted programs, that are particularly advantageous in the low-data regime. Trained on the SMCalFlow and TreeDST datasets, our model outperforms prior work by 7.3% and 10.6% respectively in terms of absolute accuracy. Trained on only a thousand examples from each dataset, it outperforms strong baselines by 12.4% and 6.4%. These results indicate that simple representations are key to effective generalization in conversational semantic parsing.
Recently, various neural models for multi-party conversation (MPC) have achieved impressive improvements on a variety of tasks such as addressee recognition, speaker identification and response prediction. However, these existing methods on MPC usually represent interlocutors and utterances individually and ignore the inherent complicated structure in MPC which may provide crucial interlocutor and utterance semantics and would enhance the conversation understanding process. To this end, we present MPC-BERT, a pre-trained model for MPC understanding that considers learning who says what to whom in a unified model with several elaborated self-supervised tasks. Particularly, these tasks can be generally categorized into (1) interlocutor structure modeling including reply-to utterance recognition, identical speaker searching and pointer consistency distinction, and (2) utterance semantics modeling including masked shared utterance restoration and shared node detection. We evaluate MPC-BERT on three downstream tasks including addressee recognition, speaker identification and response selection. Experimental results show that MPC-BERT outperforms previous methods by large margins and achieves new state-of-the-art performance on all three downstream tasks at two benchmarks.
While Transformer-based text classifiers pre-trained on large volumes of text have yielded significant improvements on a wide range of computational linguistics tasks, their implementations have been unsuitable for live incremental processing thus far, operating only on the level of complete sentence inputs. We address the challenge of introducing methods for word-by-word left-to-right incremental processing to Transformers such as BERT, models without an intrinsic sense of linear order. We modify the training method and live decoding of non-incremental models to detect speech disfluencies with minimum latency and without pre-segmentation of dialogue acts. We experiment with several decoding methods to predict the rightward context of the word currently being processed using a GPT-2 language model and apply a BERT-based disfluency detector to sequences, including predicted words. We show our method of incrementalising Transformers maintains most of their high non-incremental performance while operating strictly incrementally. We also evaluate our models’ incremental performance to establish the trade-off between incremental performance and final performance, using different prediction strategies. We apply our system to incremental speech recognition results as they arrive into a live system and achieve state-of-the-art results in this setting.
We propose NeuralWOZ, a novel dialogue collection framework that uses model-based dialogue simulation. NeuralWOZ has two pipelined models, Collector and Labeler. Collector generates dialogues from (1) user’s goal instructions, which are the user context and task constraints in natural language, and (2) system’s API call results, which is a list of possible query responses for user requests from the given knowledge base. Labeler annotates the generated dialogue by formulating the annotation as a multiple-choice problem, in which the candidate labels are extracted from goal instructions and API call results. We demonstrate the effectiveness of the proposed method in the zero-shot domain transfer learning for dialogue state tracking. In the evaluation, the synthetic dialogue corpus generated from NeuralWOZ achieves a new state-of-the-art with improvements of 4.4% point joint goal accuracy on average across domains, and improvements of 5.7% point of zero-shot coverage against the MultiWOZ 2.1 dataset.
The human mind is a dynamical system, yet many analysis techniques used to study it are limited in their ability to capture the complex dynamics that may characterize mental processes. This study proposes the continuous-time deconvolutional regressive neural network (CDRNN), a deep neural extension of continuous-time deconvolutional regression (Shain & Schuler, 2021) that jointly captures time-varying, non-linear, and delayed influences of predictors (e.g. word surprisal) on the response (e.g. reading time). Despite this flexibility, CDRNN is interpretable and able to illuminate patterns in human cognition that are otherwise difficult to study. Behavioral and fMRI experiments reveal detailed and plausible estimates of human language processing dynamics that generalize better than CDR and other baselines, supporting a potential role for CDRNN in studying human language processing.
Transformer-based language models pre-trained on large amounts of text data have proven remarkably successful in learning generic transferable linguistic representations. Here we study whether structural guidance leads to more human-like systematic linguistic generalization in Transformer language models without resorting to pre-training on very large amounts of data. We explore two general ideas. The “Generative Parsing” idea jointly models the incremental parse and word sequence as part of the same sequence modeling task. The “Structural Scaffold” idea guides the language model’s representation via additional structure loss that separately predicts the incremental constituency parse. We train the proposed models along with a vanilla Transformer language model baseline on a 14 million-token and a 46 million-token subset of the BLLIP dataset, and evaluate models’ syntactic generalization performances on SG Test Suites and sized BLiMP. Experiment results across two benchmarks suggest converging evidence that generative structural supervisions can induce more robust and humanlike linguistic generalization in Transformer language models without the need for data intensive pre-training.
While the use of character models has been popular in NLP applications, it has not been explored much in the context of psycholinguistic modeling. This paper presents a character model that can be applied to a structural parser-based processing model to calculate word generation probabilities. Experimental results show that surprisal estimates from a structural processing model using this character model deliver substantially better fits to self-paced reading, eye-tracking, and fMRI data than those from large-scale language models trained on much more data. This may suggest that the proposed processing model provides a more humanlike account of sentence processing, which assumes a larger role of morphology, phonotactics, and orthographic complexity than was previously thought.
Most previous studies integrate cognitive language processing signals (e.g., eye-tracking or EEG data) into neural models of natural language processing (NLP) just by directly concatenating word embeddings with cognitive features, ignoring the gap between the two modalities (i.e., textual vs. cognitive) and noise in cognitive features. In this paper, we propose a CogAlign approach to these issues, which learns to align textual neural representations to cognitive features. In CogAlign, we use a shared encoder equipped with a modality discriminator to alternatively encode textual and cognitive inputs to capture their differences and commonalities. Additionally, a text-aware attention mechanism is proposed to detect task-related information and to avoid using noise in cognitive features. Experimental results on three NLP tasks, namely named entity recognition, sentiment analysis and relation extraction, show that CogAlign achieves significant improvements with multiple cognitive features over state-of-the-art models on public datasets. Moreover, our model is able to transfer cognitive information to other datasets that do not have any cognitive processing signals.
Despite their impressive performance in NLP, self-attention networks were recently proved to be limited for processing formal languages with hierarchical structure, such as Dyck-k, the language consisting of well-nested parentheses of k types. This suggested that natural language can be approximated well with models that are too weak for formal languages, or that the role of hierarchy and recursion in natural language might be limited. We qualify this implication by proving that self-attention networks can process Dyck-(k, D), the subset of Dyck-k with depth bounded by D, which arguably better captures the bounded hierarchical structure of natural language. Specifically, we construct a hard-attention network with D+1 layers and O(log k) memory size (per token per layer) that recognizes Dyck-(k, D), and a soft-attention network with two layers and O(log k) memory size that generates Dyck-(k, D). Experiments show that self-attention networks trained on Dyck-(k, D) generalize to longer inputs with near-perfect accuracy, and also verify the theoretical memory advantage of self-attention networks over recurrent networks.
We present a novel approach to the problem of text style transfer. Unlike previous approaches requiring style-labeled training data, our method makes use of readily-available unlabeled text by relying on the implicit connection in style between adjacent sentences, and uses labeled data only at inference time. We adapt T5 (Raffel et al., 2020), a strong pretrained text-to-text model, to extract a style vector from text and use it to condition the decoder to perform style transfer. As our label-free training results in a style vector space encoding many facets of style, we recast transfers as “targeted restyling” vector operations that adjust specific attributes of the input while preserving others. We demonstrate that training on unlabeled Amazon reviews data results in a model that is competitive on sentiment transfer, even compared to models trained fully on labeled data. Furthermore, applying our novel method to a diverse corpus of unlabeled web text results in a single model capable of transferring along multiple dimensions of style (dialect, emotiveness, formality, politeness, sentiment) despite no additional training and using only a handful of exemplars at inference time.
We describe an efficient hierarchical method to compute attention in the Transformer architecture. The proposed attention mechanism exploits a matrix structure similar to the Hierarchical Matrix (H-Matrix) developed by the numerical analysis community, and has linear run time and memory complexity. We perform extensive experiments to show that the inductive bias embodied by our hierarchical attention is effective in capturing the hierarchical structure in the sequences typical for natural language and vision tasks. Our method is superior to alternative sub-quadratic proposals by over +6 points on average on the Long Range Arena benchmark. It also sets a new SOTA test perplexity on One-Billion Word dataset with 5x fewer model parameters than that of the previous-best Transformer-based models.
The recent GPT-3 model (Brown et al., 2020) achieves remarkable few-shot performance solely by leveraging a natural-language prompt and a few task demonstrations as input context. Inspired by their findings, we study few-shot learning in a more practical scenario, where we use smaller language models for which fine-tuning is computationally efficient. We present LM-BFF—better few-shot fine-tuning of language models—a suite of simple and complementary techniques for fine-tuning language models on a small number of annotated examples. Our approach includes (1) prompt-based fine-tuning together with a novel pipeline for automating prompt generation; and (2) a refined strategy for dynamically and selectively incorporating demonstrations into each context. Finally, we present a systematic evaluation for analyzing few-shot performance on a range of NLP tasks, including classification and regression. Our experiments demonstrate that our methods combine to dramatically outperform standard fine-tuning procedures in this low resource setting, achieving up to 30% absolute improvement, and 11% on average across all tasks. Our approach makes minimal assumptions on task resources and domain expertise, and hence constitutes a strong task-agnostic method for few-shot learning.
The Universal Trigger (UniTrigger) is a recently-proposed powerful adversarial textual attack method. Utilizing a learning-based mechanism, UniTrigger generates a fixed phrase that, when added to any benign inputs, can drop the prediction accuracy of a textual neural network (NN) model to near zero on a target class. To defend against this attack that can cause significant harm, in this paper, we borrow the “honeypot” concept from the cybersecurity community and propose DARCY, a honeypot-based defense framework against UniTrigger. DARCY greedily searches and injects multiple trapdoors into an NN model to “bait and catch” potential attacks. Through comprehensive experiments across four public datasets, we show that DARCY detects UniTrigger’s adversarial attacks with up to 99% TPR and less than 2% FPR in most cases, while maintaining the prediction accuracy (in F1) for clean inputs within a 1% margin. We also demonstrate that DARCY with multiple trapdoors is also robust to a diverse set of attack scenarios with attackers’ varying levels of knowledge and skills. We release the source code of DARCY at: https://github.com/lethaiq/ACL2021-DARCY-HoneypotDefenseNLP.
Detecting rumors on social media is a very critical task with significant implications to the economy, public health, etc. Previous works generally capture effective features from texts and the propagation structure. However, the uncertainty caused by unreliable relations in the propagation structure is common and inevitable due to wily rumor producers and the limited collection of spread data. Most approaches neglect it and may seriously limit the learning of features. Towards this issue, this paper makes the first attempt to explore propagation uncertainty for rumor detection. Specifically, we propose a novel Edge-enhanced Bayesian Graph Convolutional Network (EBGCN) to capture robust structural features. The model adaptively rethinks the reliability of latent relations by adopting a Bayesian approach. Besides, we design a new edge-wise consistency training framework to optimize the model by enforcing consistency on relations. Experiments on three public benchmark datasets demonstrate that the proposed model achieves better performance than baseline methods on both rumor detection and early rumor detection tasks.
Multi-label text classification is one of the fundamental tasks in natural language processing. Previous studies have difficulties to distinguish similar labels well because they learn the same document representations for different labels, that is they do not explicitly extract label-specific semantic components from documents. Moreover, they do not fully explore the high-order interactions among these semantic components, which is very helpful to predict tail labels. In this paper, we propose a novel label-specific dual graph neural network (LDGN), which incorporates category information to learn label-specific components from documents, and employs dual Graph Convolution Network (GCN) to model complete and adaptive interactions among these components based on the statistical label co-occurrence and dynamic reconstruction graph in a joint way. Experimental results on three benchmark datasets demonstrate that LDGN significantly outperforms the state-of-the-art models, and also achieves better performance with respect to tail labels.
Topic models have been widely used to learn text representations and gain insight into document corpora. To perform topic discovery, most existing neural models either take document bag-of-words (BoW) or sequence of tokens as input followed by variational inference and BoW reconstruction to learn topic-word distribution. However, leveraging topic-word distribution for learning better features during document encoding has not been explored much. To this end, we develop a framework TAN-NTM, which processes document as a sequence of tokens through a LSTM whose contextual outputs are attended in a topic-aware manner. We propose a novel attention mechanism which factors in topic-word distribution to enable the model to attend on relevant words that convey topic related cues. The output of topic attention module is then used to carry out variational inference. We perform extensive ablations and experiments resulting in ~9-15 percentage improvement over score of existing SOTA topic models in NPMI coherence on several benchmark datasets - 20Newsgroups, Yelp Review Polarity and AGNews. Further, we show that our method learns better latent document-topic features compared to existing topic models through improvement on two downstream tasks: document classification and topic guided keyphrase generation.
This paper proposes an approach to cross-language sentence selection in a low-resource setting. It uses data augmentation and negative sampling techniques on noisy parallel sentence data to directly learn a cross-lingual embedding-based query relevance model. Results show that this approach performs as well as or better than multiple state-of-the-art machine translation + monolingual retrieval systems trained on the same parallel data. Moreover, when a rationale training secondary objective is applied to encourage the model to match word alignment hints from a phrase-based statistical machine translation model, consistent improvements are seen across three language pairs (English-Somali, English-Swahili and English-Tagalog) over a variety of state-of-the-art baselines.
Question answering (QA) systems for large document collections typically use pipelines that (i) retrieve possibly relevant documents, (ii) re-rank them, (iii) rank paragraphs or other snippets of the top-ranked documents, and (iv) select spans of the top-ranked snippets as exact answers. Pipelines are conceptually simple, but errors propagate from one component to the next, without later components being able to revise earlier decisions. We present an architecture for joint document and snippet ranking, the two middle stages, which leverages the intuition that relevant documents have good snippets and good snippets come from relevant documents. The architecture is general and can be used with any neural text relevance ranker. We experiment with two main instantiations of the architecture, based on POSIT-DRMM (PDRMM) and a BERT-based ranker. Experiments on biomedical data from BIOASQ show that our joint models vastly outperform the pipelines in snippet retrieval, the main goal for QA, with fewer trainable parameters, also remaining competitive in document retrieval. Furthermore, our joint PDRMM-based model is competitive with BERT-based models, despite using orders of magnitude fewer parameters. These claims are also supported by human evaluation on two test batches of BIOASQ. To test our key findings on another dataset, we modified the Natural Questions dataset so that it can also be used for document and snippet retrieval. Our joint PDRMM-based model again outperforms the corresponding pipeline in snippet retrieval on the modified Natural Questions dataset, even though it performs worse than the pipeline in document retrieval. We make our code and the modified Natural Questions dataset publicly available.
Aiming for a better integration of data-driven and linguistically-inspired approaches, we explore whether RST Nuclearity, assigning a binary assessment of importance between text segments, can be replaced by automatically generated, real-valued scores, in what we call a Weighted-RST framework. In particular, we find that weighted discourse trees from auxiliary tasks can benefit key NLP downstream applications, compared to nuclearity-centered approaches. We further show that real-valued importance distributions partially and interestingly align with the assessment and uncertainty of human annotators.
Atomic clauses are fundamental text units for understanding complex sentences. Identifying the atomic sentences within complex sentences is important for applications such as summarization, argument mining, discourse analysis, discourse parsing, and question answering. Previous work mainly relies on rule-based methods dependent on parsing. We propose a new task to decompose each complex sentence into simple sentences derived from the tensed clauses in the source, and a novel problem formulation as a graph edit task. Our neural model learns to Accept, Break, Copy or Drop elements of a graph that combines word adjacency and grammatical dependencies. The full processing pipeline includes modules for graph construction, graph editing, and sentence generation from the output graph. We introduce DeSSE, a new dataset designed to train and evaluate complex sentence decomposition, and MinWiki, a subset of MinWikiSplit. ABCD achieves comparable performance as two parsing baselines on MinWiki. On DeSSE, which has a more even balance of complex sentence types, our model achieves higher accuracy on the number of atomic sentences than an encoder-decoder baseline. Results include a detailed error analysis.
Many Question-Answering (QA) datasets contain unanswerable questions, but their treatment in QA systems remains primitive. Our analysis of the Natural Questions (Kwiatkowski et al. 2019) dataset reveals that a substantial portion of unanswerable questions (~21%) can be explained based on the presence of unverifiable presuppositions. Through a user preference study, we demonstrate that the oracle behavior of our proposed system—which provides responses based on presupposition failure—is preferred over the oracle behavior of existing QA systems. Then, we present a novel framework for implementing such a system in three steps: presupposition generation, presupposition verification, and explanation generation, reporting progress on each. Finally, we show that a simple modification of adding presuppositions and their verifiability to the input of a competitive end-to-end QA system yields modest gains in QA performance and unanswerability detection, demonstrating the promise of our approach.
Text-level discourse rhetorical structure (DRS) parsing is known to be challenging due to the notorious lack of training data. Although recent top-down DRS parsers can better leverage global document context and have achieved certain success, the performance is still far from perfect. To our knowledge, all previous DRS parsers make local decisions for either bottom-up node composition or top-down split point ranking at each time step, and largely ignore DRS parsing from the global view point. Obviously, it is not sufficient to build an entire DRS tree only through these local decisions. In this work, we present our insight on evaluating the pros and cons of the entire DRS tree for global optimization. Specifically, based on recent well-performing top-down frameworks, we introduce a novel method to transform both gold standard and predicted constituency trees into tree diagrams with two color channels. After that, we learn an adversarial bot between gold and fake tree diagrams to estimate the generated DRS trees from a global perspective. We perform experiments on both RST-DT and CDTB corpora and use the original Parseval for performance evaluation. The experimental results show that our parser can substantially improve the performance when compared with previous state-of-the-art parsers.
Discourse relations among arguments reveal logical structures of a debate conversation. However, no prior work has explicitly studied how the sequence of discourse relations influence a claim’s impact. This paper empirically shows that the discourse relations between two arguments along the context path are essential factors for identifying the persuasive power of an argument. We further propose DisCOC to inject and fuse the sentence-level structural discourse information with contextualized features derived from large-scale language models. Experimental results and extensive analysis show that the attention and gate mechanisms that explicitly model contexts and texts can indeed help the argument impact classification task defined by Durmus et al. (2019), and discourse structures among the context path of the claim to be classified can further boost the performance.
This paper proposes a sophisticated neural architecture to incorporate bilingual dictionaries into Neural Machine Translation (NMT) models. By introducing three novel components: Pointer, Disambiguator, and Copier, our method PDC achieves the following merits inherently compared with previous efforts: (1) Pointer leverages the semantic information from bilingual dictionaries, for the first time, to better locate source words whose translation in dictionaries can potentially be used; (2) Disambiguator synthesizes contextual information from the source view and the target view, both of which contribute to distinguishing the proper translation of a specific source word from multiple candidates in dictionaries; (3) Copier systematically connects Pointer and Disambiguator based on a hierarchical copy mechanism seamlessly integrated with Transformer, thereby building an end-to-end architecture that could avoid error propagation problems in alternative pipe-line methods. The experimental results on Chinese-English and English-Japanese benchmarks demonstrate the PDC’s overall superiority and effectiveness of each component.
Existing work in multilingual pretraining has demonstrated the potential of cross-lingual transferability by training a unified Transformer encoder for multiple languages. However, much of this work only relies on the shared vocabulary and bilingual contexts to encourage the correlation across languages, which is loose and implicit for aligning the contextual representations between languages. In this paper, we plug a cross-attention module into the Transformer encoder to explicitly build the interdependence between languages. It can effectively avoid the degeneration of predicting masked words only conditioned on the context in its own language. More importantly, when fine-tuning on downstream tasks, the cross-attention module can be plugged in or out on-demand, thus naturally benefiting a wider range of cross-lingual tasks, from language understanding to generation. As a result, the proposed cross-lingual model delivers new state-of-the-art results on various cross-lingual understanding tasks of the XTREME benchmark, covering text classification, sequence labeling, question answering, and sentence retrieval. For cross-lingual generation tasks, it also outperforms all existing cross-lingual models and state-of-the-art Transformer variants on WMT14 English-to-German and English-to-French translation datasets, with gains of up to 1 2 BLEU.
The sentence is a fundamental unit of text processing. Yet sentences in the wild are commonly encountered not in isolation, but unsegmented within larger paragraphs and documents. Therefore, the first step in many NLP pipelines is sentence segmentation. Despite its importance, this step is the subject of relatively little research. There are no standard test sets or even methods for evaluation, leaving researchers and engineers without a clear footing for evaluating and selecting models for the task. Existing tools have relatively small language coverage, and efforts to extend them to other languages are often ad hoc. We introduce a modern context-based modeling approach that provides a solution to the problem of segmenting punctuated text in many languages, and show how it can be trained on noisily-annotated data. We also establish a new 23-language multilingual evaluation set. Our approach exceeds high baselines set by existing methods on prior English corpora (WSJ and Brown corpora), and also performs well on average on our new evaluation set. We release our tool, ersatz, as open source.
A good translation should not only translate the original content semantically, but also incarnate personal traits of the original text. For a real-world neural machine translation (NMT) system, these user traits (e.g., topic preference, stylistic characteristics and expression habits) can be preserved in user behavior (e.g., historical inputs). However, current NMT systems marginally consider the user behavior due to: 1) the difficulty of modeling user portraits in zero-shot scenarios, and 2) the lack of user-behavior annotated parallel dataset. To fill this gap, we introduce a novel framework called user-driven NMT. Specifically, a cache-based module and a user-driven contrastive learning method are proposed to offer NMT the ability to capture potential user traits from their historical inputs under a zero-shot learning fashion. Furthermore, we contribute the first Chinese-English parallel corpus annotated with user behavior called UDT-Corpus. Experimental results confirm that the proposed user-driven NMT can generate user-specific translations.
Lexically constrained machine translation allows the user to manipulate the output sentence by enforcing the presence or absence of certain words and phrases. Although current approaches can enforce terms to appear in the translation, they often struggle to make the constraint word form agree with the rest of the generated output. Our manual analysis shows that 46% of the errors in the output of a baseline constrained model for English to Czech translation are related to agreement. We investigate mechanisms to allow neural machine translation to infer the correct word inflection given lemmatized constraints. In particular, we focus on methods based on training the model with constraints provided as part of the input sequence. Our experiments on English-Czech language pair show that this approach improves translation of constrained terms in both automatic and manual evaluation by reducing errors in agreement. Our approach thus eliminates inflection errors, without introducing new errors or decreasing overall quality of the translation.
Technical logbooks are a challenging and under-explored text type in automated event identification. These texts are typically short and written in non-standard yet technical language, posing challenges to off-the-shelf NLP pipelines. The granularity of issue types described in these datasets additionally leads to class imbalance, making it challenging for models to accurately predict which issue each logbook entry describes. In this paper we focus on the problem of technical issue classification by considering logbook datasets from the automotive, aviation, and facilities maintenance domains. We adapt a feedback strategy from computer vision for handling extreme class imbalance, which resamples the training data based on its error in the prediction process. Our experiments show that with statistical significance this feedback strategy provides the best results for four different neural network models trained across a suite of seven different technical logbook datasets from distinct technical domains. The feedback strategy is also generic and could be applied to any learning problem with substantial class imbalances.
An automated system that could assist a judge in predicting the outcome of a case would help expedite the judicial process. For such a system to be practically useful, predictions by the system should be explainable. To promote research in developing such a system, we introduce ILDC (Indian Legal Documents Corpus). ILDC is a large corpus of 35k Indian Supreme Court cases annotated with original court decisions. A portion of the corpus (a separate test set) is annotated with gold standard explanations by legal experts. Based on ILDC, we propose the task of Court Judgment Prediction and Explanation (CJPE). The task requires an automated system to predict an explainable outcome of a case. We experiment with a battery of baseline models for case predictions and propose a hierarchical occlusion based model for explainability. Our best prediction model has an accuracy of 78% versus 94% for human legal experts, pointing towards the complexity of the prediction task. The analysis of explanations by the proposed algorithm reveals a significant difference in the point of view of the algorithm and legal experts for explaining the judgments, pointing towards scope for future research.
We present an annotation approach to capturing emotional and cognitive empathy in student-written peer reviews on business models in German. We propose an annotation scheme that allows us to model emotional and cognitive empathy scores based on three types of review components. Also, we conducted an annotation study with three annotators based on 92 student essays to evaluate our annotation scheme. The obtained inter-rater agreement of α=0.79 for the components and the multi-π=0.41 for the empathy scores indicate that the proposed annotation scheme successfully guides annotators to a substantial to moderate agreement. Moreover, we trained predictive models to detect the annotated empathy structures and embedded them in an adaptive writing support system for students to receive individual empathy feedback independent of an instructor, time, and location. We evaluated our tool in a peer learning exercise with 58 students and found promising results for perceived empathy skill learning, perceived feedback accuracy, and intention to use. Finally, we present our freely available corpus of 500 empathy-annotated, student-written peer reviews on business models and our annotation guidelines to encourage future research on the design and development of empathy support systems.
The current state-of-the-art generative models for open-domain question answering (ODQA) have focused on generating direct answers from unstructured textual information. However, a large amount of world’s knowledge is stored in structured databases, and need to be accessed using query languages such as SQL. Furthermore, query languages can answer questions that require complex reasoning, as well as offering full explainability. In this paper, we propose a hybrid framework that takes both textual and tabular evidences as input and generates either direct answers or SQL queries depending on which form could better answer the question. The generated SQL queries can then be executed on the associated databases to obtain the final answers. To the best of our knowledge, this is the first paper that applies Text2SQL to ODQA tasks. Empirically, we demonstrate that on several ODQA datasets, the hybrid methods consistently outperforms the baseline models that only takes homogeneous input by a large margin. Specifically we achieve the state-of-the-art performance on OpenSQuAD dataset using a T5-base model. In a detailed analysis, we demonstrate that the being able to generate structural SQL queries can always bring gains, especially for those questions that requires complex reasoning.
We propose Generation-Augmented Retrieval (GAR) for answering open-domain questions, which augments a query through text generation of heuristically discovered relevant contexts without external resources as supervision. We demonstrate that the generated contexts substantially enrich the semantics of the queries and GAR with sparse representations (BM25) achieves comparable or better performance than state-of-the-art dense retrieval methods such as DPR. We show that generating diverse contexts for a query is beneficial as fusing their results consistently yields better retrieval accuracy. Moreover, as sparse and dense representations are often complementary, GAR can be easily combined with DPR to achieve even better performance. GAR achieves state-of-the-art performance on Natural Questions and TriviaQA datasets under the extractive QA setup when equipped with an extractive reader, and consistently outperforms other retrieval methods when the same generative reader is used.
While sophisticated neural-based models have achieved remarkable success in Visual Question Answering (VQA), these models tend to answer questions only according to superficial correlations between question and answer. Several recent approaches have been developed to address this language priors problem. However, most of them predict the correct answer according to one best output without checking the authenticity of answers. Besides, they only explore the interaction between image and question, ignoring the semantics of candidate answers. In this paper, we propose a select-and-rerank (SAR) progressive framework based on Visual Entailment. Specifically, we first select the candidate answers relevant to the question or the image, then we rerank the candidate answers by a visual entailment task, which verifies whether the image semantically entails the synthetic statement of the question and each candidate answer. Experimental results show the effectiveness of our proposed framework, which establishes a new state-of-the-art accuracy on VQA-CP v2 with a 7.55% improvement.
Weakly supervised question answering usually has only the final answers as supervision signals while the correct solutions to derive the answers are not provided. This setting gives rise to the spurious solution problem: there may exist many spurious solutions that coincidentally derive the correct answer, but training on such solutions can hurt model performance (e.g., producing wrong solutions or answers). For example, for discrete reasoning tasks as on DROP, there may exist many equations to derive a numeric answer, and typically only one of them is correct. Previous learning methods mostly filter out spurious solutions with heuristics or using model confidence, but do not explicitly exploit the semantic correlations between a question and its solution. In this paper, to alleviate the spurious solution problem, we propose to explicitly exploit such semantic correlations by maximizing the mutual information between question-answer pairs and predicted solutions. Extensive experiments on four question answering datasets show that our method significantly outperforms previous learning methods in terms of task performance and is more effective in training models to produce correct solutions.
Privacy plays a crucial role in preserving democratic ideals and personal autonomy. The dominant legal approach to privacy in many jurisdictions is the “Notice and Choice” paradigm, where privacy policies are the primary instrument used to convey information to users. However, privacy policies are long and complex documents that are difficult for users to read and comprehend. We discuss how language technologies can play an important role in addressing this information gap, reporting on initial progress towards helping three specific categories of stakeholders take advantage of digital privacy policies: consumers, enterprises, and regulators. Our goal is to provide a roadmap for the development and use of language technologies to empower users to reclaim control over their privacy, limit privacy harms, and rally research efforts from the community towards addressing an issue with large social impact. We highlight many remaining opportunities to develop language technologies that are more precise or nuanced in the way in which they use the text of privacy policies.
Open pit mines left many regions worldwide inhospitable or uninhabitable. Many sites are left behind in a hazardous or contaminated state, show remnants of waste, or have other restrictions imposed upon them, e.g., for the protection of human or nature. Such information has to be permanently managed in order to reuse those areas in the future. In this work we present and evaluate an automated workflow for supporting the post-mining management of former lignite open pit mines in the eastern part of Germany, where prior to any planned land reuse, aforementioned information has to be acquired to ensure the safety and validity of such an endeavor. Usually, this information is found in expert reports, either in the form of paper documents, or in the best case as digitized unstructured text—all of them in German language. However, due to the size and complexity of these documents, any inquiry is tedious and time-consuming, thereby slowing down or even obstructing the reuse of related areas. Since no training data is available, we employ active learning in order to perform multi-label sentence classification for two categories of restrictions and seven categories of topics. The final system integrates optical character recognition (OCR), active-learning-based text classification, and geographic information system visualization in order to effectively extract, query, and visualize this information for any area of interest. Active learning and text classification results are twofold: Whereas the restriction categories were reasonably accurate (>0.85 F1), the seven topic-oriented categories seemed to be complex even for human annotators and achieved mediocre evaluation scores (<0.70 F1).
Questions of fairness, robustness, and transparency are paramount to address before deploying NLP systems. Central to these concerns is the question of reliability: Can NLP systems reliably treat different demographics fairly and function correctly in diverse and noisy environments? To address this, we argue for the need for reliability testing and contextualize it among existing work on improving accountability. We show how adversarial attacks can be reframed for this goal, via a framework for developing reliability tests. We argue that reliability testing — with an emphasis on interdisciplinary collaboration — will enable rigorous and targeted testing, and aid in the enactment and enforcement of industry standards.
Mental health conditions remain underdiagnosed even in countries with common access to advanced medical care. The ability to accurately and efficiently predict mood from easily collectible data has several important implications for the early detection, intervention, and treatment of mental health disorders. One promising data source to help monitor human behavior is daily smartphone usage. However, care must be taken to summarize behaviors without identifying the user through personal (e.g., personally identifiable information) or protected (e.g., race, gender) attributes. In this paper, we study behavioral markers of daily mood using a recent dataset of mobile behaviors from adolescent populations at high risk of suicidal behaviors. Using computational models, we find that language and multimodal representations of mobile typed text (spanning typed characters, words, keystroke timings, and app usage) are predictive of daily mood. However, we find that models trained to predict mood often also capture private user identities in their intermediate representations. To tackle this problem, we evaluate approaches that obfuscate user identity while remaining predictive. By combining multimodal representations with privacy-preserving learning, we are able to push forward the performance-privacy frontier.
This position paper investigates the problem of automated text anonymisation, which is a prerequisite for secure sharing of documents containing sensitive information about individuals. We summarise the key concepts behind text anonymisation and provide a review of current approaches. Anonymisation methods have so far been developed in two fields with little mutual interaction, namely natural language processing and privacy-preserving data publishing. Based on a case study, we outline the benefits and limitations of these approaches and discuss a number of open challenges, such as (1) how to account for multiple types of semantic inferences, (2) how to strike a balance between disclosure risk and data utility and (3) how to evaluate the quality of the resulting anonymisation. We lay out a case for moving beyond sequence labelling models and incorporate explicit measures of disclosure risk into the text anonymisation process.
Although parsing to Abstract Meaning Representation (AMR) has become very popular and AMR has been shown effective on the many sentence-level downstream tasks, little work has studied how to generate AMRs that can represent multi-sentence information. We introduce the first end-to-end AMR coreference resolution model in order to build multi-sentence AMRs. Compared with the previous pipeline and rule-based approaches, our model alleviates error propagation and it is more robust for both in-domain and out-domain situations. Besides, the document-level AMRs obtained by our model can significantly improve over the AMRs generated by a rule-based method (Liu et al., 2015) on text summarization.
Transformer language models have shown remarkable ability in detecting when a word is anomalous in context, but likelihood scores offer no information about the cause of the anomaly. In this work, we use Gaussian models for density estimation at intermediate layers of three language models (BERT, RoBERTa, and XLNet), and evaluate our method on BLiMP, a grammaticality judgement benchmark. In lower layers, surprisal is highly correlated to low token frequency, but this correlation diminishes in upper layers. Next, we gather datasets of morphosyntactic, semantic, and commonsense anomalies from psycholinguistic studies; we find that the best performing model RoBERTa exhibits surprisal in earlier layers when the anomaly is morphosyntactic than when it is semantic, while commonsense anomalies do not exhibit surprisal at any intermediate layer. These results suggest that language models employ separate mechanisms to detect different types of linguistic anomalies.
Most of the recent work on personality detection from online posts adopts multifarious deep neural networks to represent the posts and builds predictive models in a data-driven manner, without the exploitation of psycholinguistic knowledge that may unveil the connections between one’s language use and his psychological traits. In this paper, we propose a psycholinguistic knowledge-based tripartite graph network, TrigNet, which consists of a tripartite graph network and a BERT-based graph initializer. The graph network injects structural psycholinguistic knowledge in LIWC, a computerized instrument for psycholinguistic analysis, by constructing a heterogeneous tripartite graph. The initializer is employed to provide initial embeddings for the graph nodes. To reduce the computational cost in graph learning, we further propose a novel flow graph attention network (GAT) that only transmits messages between neighboring parties in the tripartite graph. Benefiting from the tripartite graph, TrigNet can aggregate post information from a psychological perspective, which is a novel way of exploiting domain knowledge. Extensive experiments on two datasets show that TrigNet outperforms the existing state-of-art model by 3.47 and 2.10 points in average F1. Moreover, the flow GAT reduces the FLOPS and Memory measures by 38% and 32%, respectively, in comparison to the original GAT in our setting.
Correct natural language understanding requires computers to distinguish the literal and metaphorical senses of a word. Recent neu- ral models achieve progress on verb metaphor detection by viewing it as sequence labeling. In this paper, we argue that it is appropriate to view this task as relation classification between a verb and its various contexts. We propose the Metaphor-relation BERT (Mr-BERT) model, which explicitly models the relation between a verb and its grammatical, sentential and semantic contexts. We evaluate our method on the VUA, MOH-X and TroFi datasets. Our method gets competitive results compared with state-of-the-art approaches.
Pretraining and multitask learning are widely used to improve the speech translation performance. In this study, we are interested in training a speech translation model along with an auxiliary text translation task. We conduct a detailed analysis to understand the impact of the auxiliary task on the primary task within the multitask learning framework. Our analysis confirms that multitask learning tends to generate similar decoder representations from different modalities and preserve more information from the pretrained text translation modules. We observe minimal negative transfer effect between the two tasks and sharing more parameters is helpful to transfer knowledge from the text task to the speech task. The analysis also reveals that the modality representation difference at the top decoder layers is still not negligible, and those layers are critical for the translation quality. Inspired by these findings, we propose three methods to improve translation quality. First, a parameter sharing and initialization strategy is proposed to enhance information sharing between the tasks. Second, a novel attention-based regularization is proposed for the encoders and pulls the representations from different modalities closer. Third, an online knowledge distillation is proposed to enhance the knowledge transfer from the text to the speech task. Our experiments show that the proposed approach improves translation performance by more than 2 BLEU over a strong baseline and achieves state-of-the-art results on the MuST-C English-German, English-French and English-Spanish language pairs.
Large pre-trained language models (PTLMs) have been shown to carry biases towards different social groups which leads to the reproduction of stereotypical and toxic content by major NLP systems. We propose a method based on logistic regression classifiers to probe English, French, and Arabic PTLMs and quantify the potentially harmful content that they convey with respect to a set of templates. The templates are prompted by a name of a social group followed by a cause-effect relation. We use PTLMs to predict masked tokens at the end of a sentence in order to examine how likely they enable toxicity towards specific communities. We shed the light on how such negative content can be triggered within unrelated and benign contexts based on evidence from a large-scale study, then we explain how to take advantage of our methodology to assess and mitigate the toxicity transmitted by PTLMs.
Technology for language generation has advanced rapidly, spurred by advancements in pre-training large models on massive amounts of data and the need for intelligent agents to communicate in a natural manner. While techniques can effectively generate fluent text, they can also produce undesirable societal biases that can have a disproportionately negative impact on marginalized populations. Language generation presents unique challenges for biases in terms of direct user interaction and the structure of decoding techniques. To better understand these challenges, we present a survey on societal biases in language generation, focusing on how data and techniques contribute to biases and progress towards reducing biases. Motivated by a lack of studies on biases from decoding techniques, we also conduct experiments to quantify the effects of these techniques. By further discussing general trends and open challenges, we call to attention promising directions for research and the importance of fairness and inclusivity considerations for language generation applications.
We demonstrate that transformers obtain impressive performance even when some of the layers are randomly initialized and never updated. Inspired by old and well-established ideas in machine learning, we explore a variety of non-linear “reservoir” layers interspersed with regular transformer layers, and show improvements in wall-clock compute time until convergence, as well as overall performance, on various machine translation and (masked) language modelling tasks.
Active Learning (AL) has been successfully applied to Deep Learning in order to drastically reduce the amount of data required to achieve high performance. Previous works have shown that lightweight architectures for Named Entity Recognition (NER) can achieve optimal performance with only 25% of the original training data. However, these methods do not exploit the sequential nature of language and the heterogeneity of uncertainty within each instance, requiring the labelling of whole sentences. Additionally, this standard method requires that the annotator has access to the full sentence when labelling. In this work, we overcome these limitations by allowing the AL algorithm to query subsequences within sentences, and propagate their labels to other sentences. We achieve highly efficient results on OntoNotes 5.0, only requiring 13% of the original training data, and CoNLL 2003, requiring only 27%. This is an improvement of 39% and 37% compared to querying full sentences.
In this paper, we detail the relationship between convolutions and self-attention in natural language tasks. We show that relative position embeddings in self-attention layers are equivalent to recently-proposed dynamic lightweight convolutions, and we consider multiple new ways of integrating convolutions into Transformer self-attention. Specifically, we propose composite attention, which unites previous relative position encoding methods under a convolutional framework. We conduct experiments by training BERT with composite attention, finding that convolutions consistently improve performance on multiple downstream tasks, replacing absolute position embeddings. To inform future work, we present results comparing lightweight convolutions, dynamic convolutions, and depthwise-separable convolutions in language model pre-training, considering multiple injection points for convolutions in self-attention layers.
The rapid development of large pre-trained language models has greatly increased the demand for model compression techniques, among which quantization is a popular solution. In this paper, we propose BinaryBERT, which pushes BERT quantization to the limit by weight binarization. We find that a binary BERT is hard to be trained directly than a ternary counterpart due to its complex and irregular loss landscape. Therefore, we propose ternary weight splitting, which initializes BinaryBERT by equivalently splitting from a half-sized ternary network. The binary model thus inherits the good performance of the ternary one, and can be further enhanced by fine-tuning the new architecture after splitting. Empirical results show that our BinaryBERT has only a slight performance drop compared with the full-precision model while being 24x smaller, achieving the state-of-the-art compression results on the GLUE and SQuAD benchmarks. Code will be released.
In the era of pre-trained language models, Transformers are the de facto choice of model architectures. While recent research has shown promise in entirely convolutional, or CNN, architectures, they have not been explored using the pre-train-fine-tune paradigm. In the context of language models, are convolutional models competitive to Transformers when pre-trained? This paper investigates this research question and presents several interesting findings. Across an extensive set of experiments on 8 datasets/tasks, we find that CNN-based pre-trained models are competitive and outperform their Transformer counterpart in certain scenarios, albeit with caveats. Overall, the findings outlined in this paper suggest that conflating pre-training and architectural advances is misguided and that both advances should be considered independently. We believe our research paves the way for a healthy amount of optimism in alternative architectures.
Distance based knowledge graph embedding methods show promising results on link prediction task, on which two topics have been widely studied: one is the ability to handle complex relations, such as N-to-1, 1-to-N and N-to-N, the other is to encode various relation patterns, such as symmetry/antisymmetry. However, the existing methods fail to solve these two problems at the same time, which leads to unsatisfactory results. To mitigate this problem, we propose PairRE, a model with paired vectors for each relation representation. The paired vectors enable an adaptive adjustment of the margin in loss function to fit for different complex relations. Besides, PairRE is capable of encoding three important relation patterns, symmetry/antisymmetry, inverse and composition. Given simple constraints on relation representations, PairRE can encode subrelation further. Experiments on link prediction benchmarks demonstrate the proposed key capabilities of PairRE. Moreover, We set a new state-of-the-art on two knowledge graph datasets of the challenging Open Graph Benchmark.
Hierarchical text classification is an important yet challenging task due to the complex structure of the label hierarchy. Existing methods ignore the semantic relationship between text and labels, so they cannot make full use of the hierarchical information. To this end, we formulate the text-label semantics relationship as a semantic matching problem and thus propose a hierarchy-aware label semantics matching network (HiMatch). First, we project text semantics and label semantics into a joint embedding space. We then introduce a joint embedding loss and a matching learning loss to model the matching relationship between the text semantics and the label semantics. Our model captures the text-label semantics matching relationship among coarse-grained labels and fine-grained labels in a hierarchy-aware manner. The experimental results on various benchmark datasets verify that our model achieves state-of-the-art results.
Fine-tuning large pre-trained models with task-specific data has achieved great success in NLP. However, it has been demonstrated that the majority of information within the self-attention networks is redundant and not utilized effectively during the fine-tuning stage. This leads to inferior results when generalizing the obtained models to out-of-domain distributions. To this end, we propose a simple yet effective data augmentation technique, HiddenCut, to better regularize the model and encourage it to learn more generalizable features. Specifically, contiguous spans within the hidden space are dynamically and strategically dropped during training. Experiments show that our HiddenCut method outperforms the state-of-the-art augmentation methods on the GLUE benchmark, and consistently exhibits superior generalization performances on out-of-distribution and challenging counterexamples. We have publicly released our code at https://github.com/GT-SALT/HiddenCut.
Generating open-domain conversational responses in the desired style usually suffers from the lack of parallel data in the style. Meanwhile, using monolingual stylistic data to increase style intensity often leads to the expense of decreasing content relevance. In this paper, we propose to disentangle the content and style in latent space by diluting sentence-level information in style representations. Combining the desired style representation and a response content representation will then obtain a stylistic response. Our approach achieves a higher BERT-based style intensity score and comparable BLEU scores, compared with baselines. Human evaluation results show that our approach significantly improves style intensity and maintains content relevance.
Understanding privacy policies is crucial for users as it empowers them to learn about the information that matters to them. Sentences written in a privacy policy document explain privacy practices, and the constituent text spans convey further specific information about that practice. We refer to predicting the privacy practice explained in a sentence as intent classification and identifying the text spans sharing specific information as slot filling. In this work, we propose PolicyIE, an English corpus consisting of 5,250 intent and 11,788 slot annotations spanning 31 privacy policies of websites and mobile applications. PolicyIE corpus is a challenging real-world benchmark with limited labeled examples reflecting the cost of collecting large-scale annotations from domain experts. We present two alternative neural approaches as baselines, (1) intent classification and slot filling as a joint sequence tagging and (2) modeling them as a sequence-to-sequence (Seq2Seq) learning task. The experiment results show that both approaches perform comparably in intent classification, while the Seq2Seq method outperforms the sequence tagging approach in slot filling by a large margin. We perform a detailed error analysis to reveal the challenges of the proposed corpus.
For task-oriented dialog systems to be maximally useful, it must be able to process conversations in a way that is (1) generalizable with a small number of training examples for new task domains, and (2) robust to user input in various styles, modalities, or domains. In pursuit of these goals, we introduce the RADDLE benchmark, a collection of corpora and tools for evaluating the performance of models across a diverse set of domains. By including tasks with limited training data, RADDLE is designed to favor and encourage models with a strong generalization ability. RADDLE also includes a diagnostic checklist that facilitates detailed robustness analysis in aspects such as language variations, speech errors, unseen entities, and out-of-domain utterances. We evaluate recent state-of-the-art systems based on pre-training and fine-tuning, and find that grounded pre-training on heterogeneous dialog corpora performs better than training a separate model per domain. Adversarial training is also proposed to improve model robustness against noisy inputs. Overall, existing models are less than satisfactory in robustness evaluation, which suggests opportunities for future improvement.
Although neural models have achieved competitive results in dialogue systems, they have shown limited ability in representing core semantics, such as ignoring important entities. To this end, we exploit Abstract Meaning Representation (AMR) to help dialogue modeling. Compared with the textual input, AMR explicitly provides core semantic knowledge and reduces data sparsity. We develop an algorithm to construct dialogue-level AMR graphs from sentence-level AMRs and explore two ways to incorporate AMRs into dialogue systems. Experimental results on both dialogue understanding and response generation tasks show the superiority of our model. To our knowledge, we are the first to leverage a formal semantic representation into neural dialogue modeling.
Recently, many studies are emerging towards building a retrieval-based dialogue system that is able to effectively leverage background knowledge (e.g., documents) when conversing with humans. However, it is non-trivial to collect large-scale dialogues that are naturally grounded on the background documents, which hinders the effective and adequate training of knowledge selection and response matching. To overcome the challenge, we consider decomposing the training of the knowledge-grounded response selection into three tasks including: 1) query-passage matching task; 2) query-dialogue history matching task; 3) multi-turn response matching task, and joint learning all these tasks in a unified pre-trained language model. The former two tasks could help the model in knowledge selection and comprehension, while the last task is designed for matching the proper response with the given query and background knowledge (dialogue history). By this means, the model can be learned to select relevant knowledge and distinguish proper response, with the help of ad-hoc retrieval corpora and a large number of ungrounded multi-turn dialogues. Experimental results on two benchmarks of knowledge-grounded response selection indicate that our model can achieve comparable performance with several existing methods that rely on crowd-sourced data for training.
Syntactic information, especially dependency trees, has been widely used by existing studies to improve relation extraction with better semantic guidance for analyzing the context information associated with the given entities. However, most existing studies suffer from the noise in the dependency trees, especially when they are automatically generated, so that intensively leveraging dependency information may introduce confusions to relation classification and necessary pruning is of great importance in this task. In this paper, we propose a dependency-driven approach for relation extraction with attentive graph convolutional networks (A-GCN). In this approach, an attention mechanism upon graph convolutional networks is applied to different contextual words in the dependency tree obtained from an off-the-shelf dependency parser, to distinguish the importance of different word dependencies. Consider that dependency types among words also contain important contextual guidance, which is potentially helpful for relation extraction, we also include the type information in A-GCN modeling. Experimental results on two English benchmark datasets demonstrate the effectiveness of our A-GCN, which outperforms previous studies and achieves state-of-the-art performance on both datasets.
Retrieval is a core component for open-domain NLP tasks. In open-domain tasks, multiple entities can share a name, making disambiguation an inherent yet under-explored problem. We propose an evaluation benchmark for assessing the entity disambiguation capabilities of these retrievers, which we call Ambiguous Entity Retrieval (AmbER) sets. We define an AmbER set as a collection of entities that share a name along with queries about those entities. By covering the set of entities for polysemous names, AmbER sets act as a challenging test of entity disambiguation. We create AmbER sets for three popular open-domain tasks: fact checking, slot filling, and question answering, and evaluate a diverse set of retrievers. We find that the retrievers exhibit popularity bias, significantly under-performing on rarer entities that share a name, e.g., they are twice as likely to retrieve erroneous documents on queries for the less popular entity under the same name. These experiments on AmbER sets show their utility as an evaluation tool and highlight the weaknesses of popular retrieval systems.
Leaderboards are widely used in NLP and push the field forward. While leaderboards are a straightforward ranking of NLP models, this simplicity can mask nuances in evaluation items (examples) and subjects (NLP models). Rather than replace leaderboards, we advocate a re-imagining so that they better highlight if and where progress is made. Building on educational testing, we create a Bayesian leaderboard model where latent subject skill and latent item difficulty predict correct responses. Using this model, we analyze the ranking reliability of leaderboards. Afterwards, we show the model can guide what to annotate, identify annotation errors, detect overfitting, and identify informative examples. We conclude with recommendations for future benchmark tasks.
Manual fact-checking does not scale well to serve the needs of the internet. This issue is further compounded in non-English contexts. In this paper, we discuss claim matching as a possible solution to scale fact-checking. We define claim matching as the task of identifying pairs of textual messages containing claims that can be served with one fact-check. We construct a novel dataset of WhatsApp tipline and public group messages alongside fact-checked claims that are first annotated for containing “claim-like statements” and then matched with potentially similar items and annotated for claim matching. Our dataset contains content in high-resource (English, Hindi) and lower-resource (Bengali, Malayalam, Tamil) languages. We train our own embedding model using knowledge distillation and a high-quality “teacher” model in order to address the imbalance in embedding quality between the low- and high-resource languages in our dataset. We provide evaluations on the performance of our solution and compare with baselines and existing state-of-the-art multilingual embedding models, namely LASER and LaBSE. We demonstrate that our performance exceeds LASER and LaBSE in all settings. We release our annotated datasets, codebooks, and trained embedding model to allow for further research.
While pre-training techniques are working very well in natural language processing, how to pre-train a decoder and effectively use it for neural machine translation (NMT) still remains a tricky issue. The main reason is that the cross-attention module between the encoder and decoder cannot be pre-trained, and the combined encoder-decoder model cannot work well in the fine-tuning stage because the inputs of the decoder cross-attention come from unknown encoder outputs. In this paper, we propose a better pre-training method for NMT by defining a semantic interface (SemFace) between the pre-trained encoder and the pre-trained decoder. Specifically, we propose two types of semantic interfaces, including CL-SemFace which regards cross-lingual embeddings as an interface, and VQ-SemFace which employs vector quantized embeddings to constrain the encoder outputs and decoder inputs in the same language-independent space. We conduct massive experiments on six supervised translation pairs and three unsupervised pairs. Experimental results demonstrate that our proposed SemFace can effectively connect the pre-trained encoder and decoder, and achieves significant improvement by 3.7 and 1.5 BLEU points on the two tasks respectively compared with previous pre-training-based NMT models.
The discrepancy between maximum likelihood estimation (MLE) and task measures such as BLEU score has been studied before for autoregressive neural machine translation (NMT) and resulted in alternative training algorithms (Ranzato et al., 2016; Norouzi et al., 2016; Shen et al., 2016; Wu et al., 2018). However, MLE training remains the de facto approach for autoregressive NMT because of its computational efficiency and stability. Despite this mismatch between the training objective and task measure, we notice that the samples drawn from an MLE-based trained NMT support the desired distribution – there are samples with much higher BLEU score comparing to the beam decoding output. To benefit from this observation, we train an energy-based model to mimic the behavior of the task measure (i.e., the energy-based model assigns lower energy to samples with higher BLEU score), which is resulted in a re-ranking algorithm based on the samples drawn from NMT: energy-based re-ranking (EBR). We use both marginal energy models (over target sentence) and joint energy models (over both source and target sentences). Our EBR with the joint energy model consistently improves the performance of the Transformer-based NMT: +3.7 BLEU points on IWSLT’14 German-English, +3.37 BELU points on Sinhala-English, +1.4 BLEU points on WMT’16 English-German tasks.
In recent years, we have seen a colossal effort in pre-training multilingual text encoders using large-scale corpora in many languages to facilitate cross-lingual transfer learning. However, due to typological differences across languages, the cross-lingual transfer is challenging. Nevertheless, language syntax, e.g., syntactic dependencies, can bridge the typological gap. Previous works have shown that pre-trained multilingual encoders, such as mBERT (CITATION), capture language syntax, helping cross-lingual transfer. This work shows that explicitly providing language syntax and training mBERT using an auxiliary objective to encode the universal dependency tree structure helps cross-lingual transfer. We perform rigorous experiments on four NLP tasks, including text classification, question answering, named entity recognition, and task-oriented semantic parsing. The experiment results show that syntax-augmented mBERT improves cross-lingual transfer on popular benchmarks, such as PAWS-X and MLQA, by 1.4 and 1.6 points on average across all languages. In the generalized transfer setting, the performance boosted significantly, with 3.9 and 3.1 points on average in PAWS-X and MLQA.
Pretrained multilingual models (PMMs) enable zero-shot learning via cross-lingual transfer, performing best for languages seen during pretraining. While methods exist to improve performance for unseen languages, they have almost exclusively been evaluated using amounts of raw text only available for a small fraction of the world’s languages. In this paper, we evaluate the performance of existing methods to adapt PMMs to new languages using a resource available for close to 1600 languages: the New Testament. This is challenging for two reasons: (1) the small corpus size, and (2) the narrow domain. While performance drops for all approaches, we surprisingly still see gains of up to 17.69% accuracy for part-of-speech tagging and 6.29 F1 for NER on average over all languages as compared to XLM-R. Another unexpected finding is that continued pretraining, the simplest approach, performs best. Finally, we perform a case study to disentangle the effects of domain and size and to shed light on the influence of the finetuning source language.
We study the problem of building entity tagging systems by using a few rules as weak supervision. Previous methods mostly focus on disambiguating entity types based on contexts and expert-provided rules, while assuming entity spans are given. In this work, we propose a novel method TALLOR that bootstraps high-quality logical rules to train a neural tagger in a fully automated manner. Specifically, we introduce compound rules that are composed from simple rules to increase the precision of boundary detection and generate more diverse pseudo labels. We further design a dynamic label selection strategy to ensure pseudo label quality and therefore avoid overfitting the neural tagger. Experiments on three datasets demonstrate that our method outperforms other weakly supervised methods and even rivals a state-of-the-art distantly supervised tagger with a lexicon of over 2,000 terms when starting from only 20 simple rules. Our method can serve as a tool for rapidly building taggers in emerging domains and tasks. Case studies show that learned rules can potentially explain the predicted entities.
Fine-tuning is the de facto way of leveraging large pretrained language models for downstream tasks. However, fine-tuning modifies all the language model parameters and therefore necessitates storing a full copy for each task. In this paper, we propose prefix-tuning, a lightweight alternative to fine-tuning for natural language generation tasks, which keeps language model parameters frozen and instead optimizes a sequence of continuous task-specific vectors, which we call the prefix. Prefix-tuning draws inspiration from prompting for language models, allowing subsequent tokens to attend to this prefix as if it were “virtual tokens”. We apply prefix-tuning to GPT-2 for table-to-text generation and to BART for summarization. We show that by learning only 0.1% of the parameters, prefix-tuning obtains comparable performance in the full data setting, outperforms fine-tuning in low-data settings, and extrapolates better to examples with topics that are unseen during training.
Recently, the sequence-to-sequence models have made remarkable progress on the task of keyphrase generation (KG) by concatenating multiple keyphrases in a predefined order as a target sequence during training. However, the keyphrases are inherently an unordered set rather than an ordered sequence. Imposing a predefined order will introduce wrong bias during training, which can highly penalize shifts in the order between keyphrases. In this work, we propose a new training paradigm One2Set without predefining an order to concatenate the keyphrases. To fit this paradigm, we propose a novel model that utilizes a fixed set of learned control codes as conditions to generate a set of keyphrases in parallel. To solve the problem that there is no correspondence between each prediction and target during training, we propose a K-step label assignment mechanism via bipartite matching, which greatly increases the diversity and reduces the repetition rate of generated keyphrases. The experimental results on multiple benchmarks demonstrate that our approach significantly outperforms the state-of-the-art methods.
Recent years have witnessed various types of generative models for natural language generation (NLG), especially RNNs or transformer based sequence-to-sequence models, as well as variational autoencoder (VAE) and generative adversarial network (GAN) based models. However, flow-based generative models, which achieve strong performance in image generation due to their invertibility and exact density estimation properties, have been less explored for NLG. In this paper, we propose a flow-based language generation model by adapting previous flow generative models to language generation via continuous input embeddings, adapted affine coupling structures, and a novel architecture for autoregressive text generation. We also apply our framework to Sequence-to-Sequence generation, including text- and video-based Question Generation (QG) and Neural Machine Translation (NMT), and data augmentation for Question Answering (QA). We use our language flow model to provide extra input features for QG and NMT, which achieves improvements over the strong QG baselines on SQuAD and TVQA and NMT baseline on WMT16. We also augment QA data with new context by injecting noise to the latent features of the language flow and show this augmentation leads to a large performance improvement from strong baselines on SQuAD and TVQA.
Wikipedia abstract generation aims to distill a Wikipedia abstract from web sources and has met significant success by adopting multi-document summarization techniques. However, previous works generally view the abstract as plain text, ignoring the fact that it is a description of a certain entity and can be decomposed into different topics. In this paper, we propose a two-stage model TWAG that guides the abstract generation with topical information. First, we detect the topic of each input paragraph with a classifier trained on existing Wikipedia articles to divide input documents into different topics. Then, we predict the topic distribution of each abstract sentence, and decode the sentence from topic-aware representations with a Pointer-Generator network. We evaluate our model on the WikiCatSum dataset, and the results show that TWAG outperforms various existing baselines and is capable of generating comprehensive abstracts.
Event forecasting is a challenging, yet important task, as humans seek to constantly plan for the future. Existing automated forecasting studies rely mostly on structured data, such as time-series or event-based knowledge graphs, to help predict future events. In this work, we aim to formulate a task, construct a dataset, and provide benchmarks for developing methods for event forecasting with large volumes of unstructured text data. To simulate the forecasting scenario on temporal news documents, we formulate the problem as a restricted-domain, multiple-choice, question-answering (QA) task. Unlike existing QA tasks, our task limits accessible information, and thus a model has to make a forecasting judgement. To showcase the usefulness of this task formulation, we introduce ForecastQA, a question-answering dataset consisting of 10,392 event forecasting questions, which have been collected and verified via crowdsourcing efforts. We present our experiments on ForecastQA using BERTbased models and find that our best model achieves 61.0% accuracy on the dataset, which still lags behind human performance by about 19%. We hope ForecastQA will support future research efforts in bridging this gap.
Syntactic structure is an important component of natural language text. Recent top-performing models in Answer Sentence Selection (AS2) use self-attention and transfer learning, but not syntactic structure. Tree structures have shown strong performance in tasks with sentence pair input like semantic relatedness. We investigate whether tree structures can boost performance in AS2. We introduce the Tree Aggregation Transformer: a novel recursive, tree-structured self-attention model for AS2. The recursive nature of our model is able to represent all levels of syntactic parse trees with only one additional self-attention layer. Without transfer learning, we establish a new state of the art on the popular TrecQA and WikiQA benchmark datasets. Additionally, we evaluate our method on four Community Question Answering datasets, and find that tree-structured representations have limitations with noisy user-generated text. We conduct probing experiments to evaluate how our models leverage tree structures across datasets. Our findings show that the ability of tree-structured models to successfully absorb syntactic information is strongly correlated with a higher performance in AS2.
Knowledge Graph (KG) and attention mechanism have been demonstrated effective in introducing and selecting useful information for weakly supervised methods. However, only qualitative analysis and ablation study are provided as evidence. In this paper, we contribute a dataset and propose a paradigm to quantitatively evaluate the effect of attention and KG on bag-level relation extraction (RE). We find that (1) higher attention accuracy may lead to worse performance as it may harm the model’s ability to extract entity mention features; (2) the performance of attention is largely influenced by various noise distribution patterns, which is closely related to real-world datasets; (3) KG-enhanced attention indeed improves RE performance, while not through enhanced attention but by incorporating entity prior; and (4) attention mechanism may exacerbate the issue of insufficient training data. Based on these findings, we show that a straightforward variant of RE model can achieve significant improvements (6% AUC on average) on two real-world datasets as compared with three state-of-the-art baselines. Our codes and datasets are available at https://github.com/zig-kwin-hu/how-KG-ATT-help.
Implicit Event Argument Extraction seeks to identify arguments that play direct or implicit roles in a given event. However, most prior works focus on capturing direct relations between arguments and the event trigger. The lack of reasoning ability brings many challenges to the extraction of implicit arguments. In this work, we present a Frame-aware Event Argument Extraction (FEAE) learning framework to tackle this issue through reasoning in event frame-level scope. The proposed method leverages related arguments of the expected one as clues to guide the reasoning process. To bridge the gap between oracle knowledge used in the training phase and the imperfect related arguments in the test stage, we further introduce a curriculum knowledge distillation strategy to drive a final model that could operate without extra inputs through mimicking the behavior of a well-informed teacher model. Experimental results demonstrate FEAE obtains new state-of-the-art performance on the RAMS dataset.
Open relation extraction aims to cluster relation instances referring to the same underlying relation, which is a critical step for general relation extraction. Current OpenRE models are commonly trained on the datasets generated from distant supervision, which often results in instability and makes the model easily collapsed. In this paper, we revisit the procedure of OpenRE from a causal view. By formulating OpenRE using a structural causal model, we identify that the above-mentioned problems stem from the spurious correlations from entities and context to the relation type. To address this issue, we conduct Element Intervention, which intervene on the context and entities respectively to obtain the underlying causal effects of them. We also provide two specific implementations of the interventions based on entity ranking and context contrasting. Experimental results on unsupervised relation extraction datasets show our method to outperform previous state-of-the-art methods and is robust across different datasets.
Automatic extraction of product attribute values is an important enabling technology in e-Commerce platforms. This task is usually modeled using sequence labeling architectures, with several extensions to handle multi-attribute extraction. One line of previous work constructs attribute-specific models, through separate decoders or entirely separate models. However, this approach constrains knowledge sharing across different attributes. Other contributions use a single multi-attribute model, with different techniques to embed attribute information. But sharing the entire network parameters across all attributes can limit the model’s capacity to capture attribute-specific characteristics. In this paper we present AdaTag, which uses adaptive decoding to handle extraction. We parameterize the decoder with pretrained attribute embeddings, through a hypernetwork and a Mixture-of-Experts (MoE) module. This allows for separate, but semantically correlated, decoders to be generated on the fly for different attributes. This approach facilitates knowledge sharing, while maintaining the specificity of each attribute. Our experiments on a real-world e-Commerce dataset show marked improvements over previous methods.
Integrating extracted knowledge from the Web to knowledge graphs (KGs) can facilitate tasks like question answering. We study relation integration that aims to align free-text relations in subject-relation-object extractions to relations in a target KG. To address the challenge that free-text relations are ambiguous, previous methods exploit neighbor entities and relations for additional context. However, the predictions are made independently, which can be mutually inconsistent. We propose a two-stage Collective Relation Integration (CoRI) model, where the first stage independently makes candidate predictions, and the second stage employs a collective model that accesses all candidate predictions to make globally coherent predictions. We further improve the collective model with augmented data from the portion of the target KG that is otherwise unused. Experiment results on two datasets show that CoRI can significantly outperform the baselines, improving AUC from .677 to .748 and from .716 to .780, respectively.
Streaming cross document entity coreference (CDC) systems disambiguate mentions of named entities in a scalable manner via incremental clustering. Unlike other approaches for named entity disambiguation (e.g., entity linking), streaming CDC allows for the disambiguation of entities that are unknown at inference time. Thus, it is well-suited for processing streams of data where new entities are frequently introduced. Despite these benefits, this task is currently difficult to study, as existing approaches are either evaluated on datasets that are no longer available, or omit other crucial details needed to ensure fair comparison. In this work, we address this issue by compiling a large benchmark adapted from existing free datasets, and performing a comprehensive evaluation of a number of novel and existing baseline models. We investigate: how to best encode mentions, which clustering algorithms are most effective for grouping mentions, how models transfer to different domains, and how bounding the number of mentions tracked during inference impacts performance. Our results show that the relative performance of neural and feature-based mention encoders varies across different domains, and in most cases the best performance is achieved using a combination of both approaches. We also find that performance is minimally impacted by limiting the number of tracked mentions.
Temporal Knowledge Graphs (TKGs) have been developed and used in many different areas. Reasoning on TKGs that predicts potential facts (events) in the future brings great challenges to existing models. When facing a prediction task, human beings usually search useful historical information (i.e., clues) in their memories and then reason for future meticulously. Inspired by this mechanism, we propose CluSTeR to predict future facts in a two-stage manner, Clue Searching and Temporal Reasoning, accordingly. Specifically, at the clue searching stage, CluSTeR learns a beam search policy via reinforcement learning (RL) to induce multiple clues from historical facts. At the temporal reasoning stage, it adopts a graph convolution network based sequence method to deduce answers from clues. Experiments on four datasets demonstrate the substantial advantages of CluSTeR compared with the state-of-the-art methods. Moreover, the clues found by CluSTeR further provide interpretability for the results.
Generating high-quality arguments, while being challenging, may benefit a wide range of downstream applications, such as writing assistants and argument search engines. Motivated by the effectiveness of utilizing knowledge graphs for supporting general text generation tasks, this paper investigates the usage of argumentation-related knowledge graphs to control the generation of arguments. In particular, we construct and populate three knowledge graphs, employing several compositions of them to encode various knowledge into texts of debate portals and relevant paragraphs from Wikipedia. Then, the texts with the encoded knowledge are used to fine-tune a pre-trained text generation model, GPT-2. We evaluate the newly created arguments manually and automatically, based on several dimensions important in argumentative contexts, including argumentativeness and plausibility. The results demonstrate the positive impact of encoding the graphs’ knowledge into debate portal texts for generating arguments with superior quality than those generated without knowledge.
Aspect Sentiment Triplet Extraction (ASTE) is the most recent subtask of ABSA which outputs triplets of an aspect target, its associated sentiment, and the corresponding opinion term. Recent models perform the triplet extraction in an end-to-end manner but heavily rely on the interactions between each target word and opinion word. Thereby, they cannot perform well on targets and opinions which contain multiple words. Our proposed span-level approach explicitly considers the interaction between the whole spans of targets and opinions when predicting their sentiment relation. Thus, it can make predictions with the semantics of whole spans, ensuring better sentiment consistency. To ease the high computational cost caused by span enumeration, we propose a dual-channel span pruning strategy by incorporating supervision from the Aspect Term Extraction (ATE) and Opinion Term Extraction (OTE) tasks. This strategy not only improves computational efficiency but also distinguishes the opinion and target spans more properly. Our framework simultaneously achieves strong performance for the ASTE as well as ATE and OTE tasks. In particular, our analysis shows that our span-level approach achieves more significant improvements over the baselines on triplets with multi-word targets or opinions.
Modern neural machine translation (NMT) models have achieved competitive performance in standard benchmarks such as WMT. However, there still exist significant issues such as robustness, domain generalization, etc. In this paper, we study NMT models from the perspective of compositional generalization by building a benchmark dataset, CoGnition, consisting of 216k clean and consistent sentence pairs. We quantitatively analyze effects of various factors using compound translation error rate, then demonstrate that the NMT model fails badly on compositional generalization, although it performs remarkably well under traditional metrics.
Word alignment, which aims to align translationally equivalent words between source and target sentences, plays an important role in many natural language processing tasks. Current unsupervised neural alignment methods focus on inducing alignments from neural machine translation models, which does not leverage the full context in the target sequence. In this paper, we propose Mask-Align, a self-supervised word alignment model that takes advantage of the full context on the target side. Our model masks out each target token and predicts it conditioned on both source and the remaining target tokens. This two-step process is based on the assumption that the source token contributing most to recovering the masked target token should be aligned. We also introduce an attention variant called leaky attention, which alleviates the problem of unexpected high cross-attention weights on special tokens such as periods. Experiments on four language pairs show that our model outperforms previous unsupervised neural aligners and obtains new state-of-the-art results.
Computer-aided translation (CAT), the use of software to assist a human translator in the translation process, has been proven to be useful in enhancing the productivity of human translators. Autocompletion, which suggests translation results according to the text pieces provided by human translators, is a core function of CAT. There are two limitations in previous research in this line. First, most research works on this topic focus on sentence-level autocompletion (i.e., generating the whole translation as a sentence based on human input), but word-level autocompletion is under-explored so far. Second, almost no public benchmarks are available for the autocompletion task of CAT. This might be among the reasons why research progress in CAT is much slower compared to automatic MT. In this paper, we propose the task of general word-level autocompletion (GWLAN) from a real-world CAT scenario, and construct the first public benchmark to facilitate research in this topic. In addition, we propose an effective method for GWLAN and compare it with several strong baselines. Experiments demonstrate that our proposed method can give significantly more accurate predictions than the baseline methods on our benchmark datasets.
Distant supervision tackles the data bottleneck in NER by automatically generating training instances via dictionary matching. Unfortunately, the learning of DS-NER is severely dictionary-biased, which suffers from spurious correlations and therefore undermines the effectiveness and the robustness of the learned models. In this paper, we fundamentally explain the dictionary bias via a Structural Causal Model (SCM), categorize the bias into intra-dictionary and inter-dictionary biases, and identify their causes. Based on the SCM, we learn de-biased DS-NER via causal interventions. For intra-dictionary bias, we conduct backdoor adjustment to remove the spurious correlations introduced by the dictionary confounder. For inter-dictionary bias, we propose a causal invariance regularizer which will make DS-NER models more robust to the perturbation of dictionaries. Experiments on four datasets and three DS-NER models show that our method can significantly improve the performance of DS-NER.
Research on overlapped and discontinuous named entity recognition (NER) has received increasing attention. The majority of previous work focuses on either overlapped or discontinuous entities. In this paper, we propose a novel span-based model that can recognize both overlapped and discontinuous entities jointly. The model includes two major steps. First, entity fragments are recognized by traversing over all possible text spans, thus, overlapped entities can be recognized. Second, we perform relation classification to judge whether a given pair of entity fragments to be overlapping or succession. In this way, we can recognize not only discontinuous entities, and meanwhile doubly check the overlapped entities. As a whole, our model can be regarded as a relation extraction paradigm essentially. Experimental results on multiple benchmark datasets (i.e., CLEF, GENIA and ACE05) show that our model is highly competitive for overlapped and discontinuous NER.
We consider the problem of collectively detecting multiple events, particularly in cross-sentence settings. The key to dealing with the problem is to encode semantic information and model event inter-dependency at a document-level. In this paper, we reformulate it as a Seq2Seq task and propose a Multi-Layer Bidirectional Network (MLBiNet) to capture the document-level association of events and semantic information simultaneously. Specifically, a bidirectional decoder is firstly devised to model event inter-dependency within a sentence when decoding the event tag vector sequence. Secondly, an information aggregation module is employed to aggregate sentence-level semantic and event tag information. Finally, we stack multiple bidirectional decoders and feed cross-sentence information, forming a multi-layer bidirectional tagging architecture to iteratively propagate information across sentences. We show that our approach provides significant improvement in performance compared to the current state-of-the-art results.
We study the problem of event coreference resolution (ECR) that seeks to group coreferent event mentions into the same clusters. Deep learning methods have recently been applied for this task to deliver state-of-the-art performance. However, existing deep learning models for ECR are limited in that they cannot exploit important interactions between relevant objects for ECR, e.g., context words and entity mentions, to support the encoding of document-level context. In addition, consistency constraints between golden and predicted clusters of event mentions have not been considered to improve representation learning in prior deep learning models for ECR. This work addresses such limitations by introducing a novel deep learning model for ECR. At the core of our model are document structures to explicitly capture relevant objects for ECR. Our document structures introduce diverse knowledge sources (discourse, syntax, semantics) to compute edges/interactions between structure nodes for document-level representation learning. We also present novel regularization techniques based on consistencies of golden and predicted clusters for event mentions in documents. Extensive experiments show that our model achieve state-of-the-art performance on two benchmark datasets.
Relational triple extraction is critical to understanding massive text corpora and constructing large-scale knowledge graph, which has attracted increasing research interest. However, existing studies still face some challenging issues, including information loss, error propagation and ignoring the interaction between entity and relation. To intuitively explore the above issues and address them, in this paper, we provide a revealing insight into relational triple extraction from a stereoscopic perspective, which rationalizes the occurrence of these issues and exposes the shortcomings of existing methods. Further, a novel model is proposed for relational triple extraction, which maps relational triples to a three-dimension (3-D) space and leverages three decoders to extract them, aimed at simultaneously handling the above issues. A series of experiments are conducted on five public datasets, demonstrating that the proposed model outperforms the recent advanced baselines.
Identifying causal relations of events is an important task in natural language processing area. However, the task is very challenging, because event causality is usually expressed in diverse forms that often lack explicit causal clues. Existing methods cannot handle well the problem, especially in the condition of lacking training data. Nonetheless, humans can make a correct judgement based on their background knowledge, including descriptive knowledge and relational knowledge. Inspired by it, we propose a novel Latent Structure Induction Network (LSIN) to incorporate the external structural knowledge into this task. Specifically, to make use of the descriptive knowledge, we devise a Descriptive Graph Induction module to obtain and encode the graph-structured descriptive knowledge. To leverage the relational knowledge, we propose a Relational Graph Induction module which is able to automatically learn a reasoning structure for event causality reasoning. Experimental results on two widely used datasets indicate that our approach significantly outperforms previous state-of-the-art methods.
Recent studies show that neural natural language processing (NLP) models are vulnerable to backdoor attacks. Injected with backdoors, models perform normally on benign examples but produce attacker-specified predictions when the backdoor is activated, presenting serious security threats to real-world applications. Since existing textual backdoor attacks pay little attention to the invisibility of backdoors, they can be easily detected and blocked. In this work, we present invisible backdoors that are activated by a learnable combination of word substitution. We show that NLP models can be injected with backdoors that lead to a nearly 100% attack success rate, whereas being highly invisible to existing defense strategies and even human inspections. The results raise a serious alarm to the security of NLP models, which requires further research to be resolved. All the data and code of this paper are released at https://github.com/thunlp/BkdAtk-LWS.
The large size of pretrained networks makes them difficult to deploy for multiple tasks in storage-constrained settings. Diff pruning enables parameter-efficient transfer learning that scales well with new tasks. The approach learns a task-specific “diff” vector that extends the original pretrained parameters. This diff vector is adaptively pruned during training with a differentiable approximation to the L0-norm penalty to encourage sparsity. As the number of tasks increases, diff pruning remains parameter-efficient, as it requires storing only a small diff vector for each task. Since it does not require access to all tasks during training, it is attractive in on-device deployment settings where tasks arrive in stream or even from different providers. Diff pruning can match the performance of finetuned baselines on the GLUE benchmark while only modifying 0.5% of the pretrained model’s parameters per task and scales favorably in comparison to popular pruning approaches.
Human language understanding operates at multiple levels of granularity (e.g., words, phrases, and sentences) with increasing levels of abstraction that can be hierarchically combined. However, existing deep models with stacked layers do not explicitly model any sort of hierarchical process. In this paper, we propose a recursive Transformer model based on differentiable CKY style binary trees to emulate this composition process, and we extend the bidirectional language model pre-training objective to this architecture, attempting to predict each word given its left and right abstraction nodes. To scale up our approach, we also introduce an efficient pruning and growing algorithm to reduce the time complexity and enable encoding in linear time. Experimental results on language modeling and unsupervised parsing show the effectiveness of our approach.
Zero-shot sequence labeling aims to build a sequence labeler without human-annotated datasets. One straightforward approach is utilizing existing systems (source models) to generate pseudo-labeled datasets and train a target sequence labeler accordingly. However, due to the gap between the source and the target languages/domains, this approach may fail to recover the true labels. In this paper, we propose a novel unified framework for zero-shot sequence labeling with minimum risk training and design a new decomposable risk function that models the relations between the predicted labels from the source models and the true labels. By making the risk function trainable, we draw a connection between minimum risk training and latent variable model learning. We propose a unified learning algorithm based on the expectation maximization (EM) algorithm. We extensively evaluate our proposed approaches on cross-lingual/domain sequence labeling tasks over twenty-one datasets. The results show that our approaches outperform state-of-the-art baseline systems.
Transfer learning from pretrained language models recently became the dominant approach for solving many NLP tasks. A common approach to transfer learning for multiple tasks that maximize parameter sharing trains one or more task-specific layers on top of the language model. In this paper, we present an alternative approach based on adversarial reprogramming, which extends earlier work on automatic prompt generation. Adversarial reprogramming attempts to learn task-specific word embeddings that, when concatenated to the input text, instruct the language model to solve the specified task. Using up to 25K trainable parameters per task, this approach outperforms all existing methods with up to 25M trainable parameters on the public leaderboard of the GLUE benchmark. Our method, initialized with task-specific human-readable prompts, also works in a few-shot setting, outperforming GPT-3 on two SuperGLUE tasks with just 32 training samples.
Sequence-to-sequence transduction is the core problem in language processing applications as diverse as semantic parsing, machine translation, and instruction following. The neural network models that provide the dominant solution to these problems are brittle, especially in low-resource settings: they fail to generalize correctly or systematically from small datasets. Past work has shown that many failures of systematic generalization arise from neural models’ inability to disentangle lexical phenomena from syntactic ones. To address this, we augment neural decoders with a lexical translation mechanism that generalizes existing copy mechanisms to incorporate learned, decontextualized, token-level translation rules. We describe how to initialize this mechanism using a variety of lexicon learning algorithms, and show that it improves systematic generalization on a diverse set of sequence modeling tasks drawn from cognitive science, formal semantics, and machine translation.
Personalization of natural language generation plays a vital role in a large spectrum of tasks, such as explainable recommendation, review summarization and dialog systems. In these tasks, user and item IDs are important identifiers for personalization. Transformer, which is demonstrated with strong language modeling capability, however, is not personalized and fails to make use of the user and item IDs since the ID tokens are not even in the same semantic space as the words. To address this problem, we present a PErsonalized Transformer for Explainable Recommendation (PETER), on which we design a simple and effective learning objective that utilizes the IDs to predict the words in the target explanation, so as to endow the IDs with linguistic meanings and to achieve personalized Transformer. Besides generating explanations, PETER can also make recommendations, which makes it a unified model for the whole recommendation-explanation pipeline. Extensive experiments show that our small unpretrained model outperforms fine-tuned BERT on the generation task, in terms of both effectiveness and efficiency, which highlights the importance and the nice utility of our design.
Following each patient visit, physicians draft long semi-structured clinical summaries called SOAP notes. While invaluable to clinicians and researchers, creating digital SOAP notes is burdensome, contributing to physician burnout. In this paper, we introduce the first complete pipelines to leverage deep summarization models to generate these notes based on transcripts of conversations between physicians and patients. After exploring a spectrum of methods across the extractive-abstractive spectrum, we propose Cluster2Sent, an algorithm that (i) extracts important utterances relevant to each summary section; (ii) clusters together related utterances; and then (iii) generates one summary sentence per cluster. Cluster2Sent outperforms its purely abstractive counterpart by 8 ROUGE-1 points, and produces significantly more factual and coherent sentences as assessed by expert human evaluators. For reproducibility, we demonstrate similar benefits on the publicly available AMI dataset. Our results speak to the benefits of structuring summaries into sections and annotating supporting evidence when constructing summarization corpora.
We investigate the problem of Chinese Grammatical Error Correction (CGEC) and present a new framework named Tail-to-Tail (TtT) non-autoregressive sequence prediction to address the deep issues hidden in CGEC. Considering that most tokens are correct and can be conveyed directly from source to target, and the error positions can be estimated and corrected based on the bidirectional context information, thus we employ a BERT-initialized Transformer Encoder as the backbone model to conduct information modeling and conveying. Considering that only relying on the same position substitution cannot handle the variable-length correction cases, various operations such substitution, deletion, insertion, and local paraphrasing are required jointly. Therefore, a Conditional Random Fields (CRF) layer is stacked on the up tail to conduct non-autoregressive sequence prediction by modeling the token dependencies. Since most tokens are correct and easily to be predicted/conveyed to the target, then the models may suffer from a severe class imbalance issue. To alleviate this problem, focal loss penalty strategies are integrated into the loss functions. Moreover, besides the typical fix-length error correction datasets, we also construct a variable-length corpus to conduct experiments. Experimental results on standard datasets, especially on the variable-length datasets, demonstrate the effectiveness of TtT in terms of sentence-level Accuracy, Precision, Recall, and F1-Measure on tasks of error Detection and Correction.
An important risk that children face today is online grooming, where a so-called sexual predator establishes an emotional connection with a minor online with the objective of sexual abuse. Prior work has sought to automatically identify grooming chats, but only after an incidence has already happened in the context of legal prosecution. In this work, we instead investigate this problem from the point of view of prevention. We define and study the task of early sexual predator detection (eSPD) in chats, where the goal is to analyze a running chat from its beginning and predict grooming attempts as early and as accurately as possible. We survey existing datasets and their limitations regarding eSPD, and create a new dataset called PANC for more realistic evaluations. We present strong baselines built on BERT that also reach state-of-the-art results for conventional SPD. Finally, we consider coping with limited computational resources, as real-life applications require eSPD on mobile devices.
Medical report generation is one of the most challenging tasks in medical image analysis. Although existing approaches have achieved promising results, they either require a predefined template database in order to retrieve sentences or ignore the hierarchical nature of medical report generation. To address these issues, we propose MedWriter that incorporates a novel hierarchical retrieval mechanism to automatically extract both report and sentence-level templates for clinically accurate report generation. MedWriter first employs the Visual-Language Retrieval (VLR) module to retrieve the most relevant reports for the given images. To guarantee the logical coherence between generated sentences, the Language-Language Retrieval (LLR) module is introduced to retrieve relevant sentences based on the previous generated description. At last, a language decoder fuses image features and features from retrieved reports and sentences to generate meaningful medical reports. We verified the effectiveness of our model by automatic evaluation and human evaluation on two datasets, i.e., Open-I and MIMIC-CXR.
Hierarchical Text Classification (HTC) is a challenging task that categorizes a textual description within a taxonomic hierarchy. Most of the existing methods focus on modeling the text. Recently, researchers attempt to model the class representations with some resources (e.g., external dictionaries). However, the concept shared among classes which is a kind of domain-specific and fine-grained information has been ignored in previous work. In this paper, we propose a novel concept-based label embedding method that can explicitly represent the concept and model the sharing mechanism among classes for the hierarchical text classification. Experimental results on two widely used datasets prove that the proposed model outperforms several state-of-the-art methods. We release our complementary resources (concepts and definitions of classes) for these two datasets to benefit the research on HTC.
Text-to-image retrieval is an essential task in cross-modal information retrieval, i.e., retrieving relevant images from a large and unlabelled dataset given textual queries. In this paper, we propose VisualSparta, a novel (Visual-text Sparse Transformer Matching) model that shows significant improvement in terms of both accuracy and efficiency. VisualSparta is capable of outperforming previous state-of-the-art scalable methods in MSCOCO and Flickr30K. We also show that it achieves substantial retrieving speed advantages, i.e., for a 1 million image index, VisualSparta using CPU gets ~391X speedup compared to CPU vector search and ~5.4X speedup compared to vector search with GPU acceleration. Experiments show that this speed advantage even gets bigger for larger datasets because VisualSparta can be efficiently implemented as an inverted index. To the best of our knowledge, VisualSparta is the first transformer-based text-to-image retrieval model that can achieve real-time searching for large-scale datasets, with significant accuracy improvement compared to previous state-of-the-art methods.
The effectiveness of Neural Information Retrieval (Neu-IR) often depends on a large scale of in-domain relevance training signals, which are not always available in real-world ranking scenarios. To democratize the benefits of Neu-IR, this paper presents MetaAdaptRank, a domain adaptive learning method that generalizes Neu-IR models from label-rich source domains to few-shot target domains. Drawing on source-domain massive relevance supervision, MetaAdaptRank contrastively synthesizes a large number of weak supervision signals for target domains and meta-learns to reweight these synthetic “weak” data based on their benefits to the target-domain ranking accuracy of Neu-IR models. Experiments on three TREC benchmarks in the web, news, and biomedical domains show that MetaAdaptRank significantly improves the few-shot ranking accuracy of Neu-IR models. Further analyses indicate that MetaAdaptRank thrives from both its contrastive weak data synthesis and meta-reweighted data selection. The code and data of this paper can be obtained from https://github.com/thunlp/MetaAdaptRank.
Semi-Supervised Text Classification (SSTC) mainly works under the spirit of self-training. They initialize the deep classifier by training over labeled texts; and then alternatively predict unlabeled texts as their pseudo-labels and train the deep classifier over the mixture of labeled and pseudo-labeled texts. Naturally, their performance is largely affected by the accuracy of pseudo-labels for unlabeled texts. Unfortunately, they often suffer from low accuracy because of the margin bias problem caused by the large difference between representation distributions of labels in SSTC. To alleviate this problem, we apply the angular margin loss, and perform Gaussian linear transformation to achieve balanced label angle variances, i.e., the variance of label angles of texts within the same label. More accuracy of predicted pseudo-labels can be achieved by constraining all label angle variances balanced, where they are estimated over both labeled and pseudo-labeled texts during self-training loops. With this insight, we propose a novel SSTC method, namely Semi-Supervised Text Classification with Balanced Deep representation Distributions (S2TC-BDD). To evaluate S2TC-BDD, we compare it against the state-of-the-art SSTC methods. Empirical results demonstrate the effectiveness of S2TC-BDD, especially when the labeled texts are scarce.
Recently, the retrieval models based on dense representations have been gradually applied in the first stage of the document retrieval tasks, showing better performance than traditional sparse vector space models. To obtain high efficiency, the basic structure of these models is Bi-encoder in most cases. However, this simple structure may cause serious information loss during the encoding of documents since the queries are agnostic. To address this problem, we design a method to mimic the queries to each of the documents by an iterative clustering process and represent the documents by multiple pseudo queries (i.e., the cluster centroids). To boost the retrieval process using approximate nearest neighbor search library, we also optimize the matching function with a two-step score calculation procedure. Experimental results on several popular ranking and QA datasets show that our model can achieve state-of-the-art results while still remaining high efficiency.
Learning high-quality sentence representations benefits a wide range of natural language processing tasks. Though BERT-based pre-trained language models achieve high performance on many downstream tasks, the native derived sentence representations are proved to be collapsed and thus produce a poor performance on the semantic textual similarity (STS) tasks. In this paper, we present ConSERT, a Contrastive Framework for Self-Supervised SEntence Representation Transfer, that adopts contrastive learning to fine-tune BERT in an unsupervised and effective way. By making use of unlabeled texts, ConSERT solves the collapse issue of BERT-derived sentence representations and make them more applicable for downstream tasks. Experiments on STS datasets demonstrate that ConSERT achieves an 8% relative improvement over the previous state-of-the-art, even comparable to the supervised SBERT-NLI. And when further incorporating NLI supervision, we achieve new state-of-the-art performance on STS tasks. Moreover, ConSERT obtains comparable results with only 1000 samples available, showing its robustness in data scarcity scenarios.
Due to the great potential in facilitating software development, code generation has attracted increasing attention recently. Generally, dominant models are Seq2Tree models, which convert the input natural language description into a sequence of tree-construction actions corresponding to the pre-order traversal of an Abstract Syntax Tree (AST). However, such a traversal order may not be suitable for handling all multi-branch nodes. In this paper, we propose to equip the Seq2Tree model with a context-based Branch Selector, which is able to dynamically determine optimal expansion orders of branches for multi-branch nodes. Particularly, since the selection of expansion orders is a non-differentiable multi-step operation, we optimize the selector through reinforcement learning, and formulate the reward function as the difference of model losses obtained through different expansion orders. Experimental results and in-depth analysis on several commonly-used datasets demonstrate the effectiveness and generality of our approach. We have released our code at https://github.com/DeepLearnXMU/CG-RL.
Despite recent successes of large pre-trained language models in solving reasoning tasks, their inference capabilities remain opaque. We posit that such models can be made more interpretable by explicitly generating interim inference rules, and using them to guide the generation of task-specific textual outputs. In this paper we present Coins, a recursive inference framework that i) iteratively reads context sentences, ii) dynamically generates contextualized inference rules, encodes them, and iii) uses them to guide task-specific output generation. We apply to a Narrative Story Completion task that asks a model to complete a story with missing sentences, to produce a coherent story with plausible logical connections, causal relationships, and temporal dependencies. By modularizing inference and sentence generation steps in a recurrent model, we aim to make reasoning steps and their effects on next sentence generation transparent. Our automatic and manual evaluations show that the model generates better story sentences than SOTA baselines, especially in terms of coherence. We further demonstrate improved performance over strong pre-trained LMs in generating commonsense inference rules. The recursive nature of holds the potential for controlled generation of longer sequences.
Procedural text understanding aims at tracking the states (e.g., create, move, destroy) and locations of the entities mentioned in a given paragraph. To effectively track the states and locations, it is essential to capture the rich semantic relations between entities, actions, and locations in the paragraph. Although recent works have achieved substantial progress, most of them focus on leveraging the inherent constraints or incorporating external knowledge for state prediction. The rich semantic relations in the given paragraph are largely overlooked. In this paper, we propose a novel approach (REAL) to procedural text understanding, where we build a general framework to systematically model the entity-entity, entity-action, and entity-location relations using a graph neural network. We further develop algorithms for graph construction, representation learning, and state and location tracking. We evaluate the proposed approach on two benchmark datasets, ProPara, and Recipes. The experimental results show that our method outperforms strong baselines by a large margin, i.e., 5.0% on ProPara and 3.2% on Recipes, illustrating the utility of semantic relations and the effectiveness of the graph-based reasoning model.
Semantic parsing is challenging due to the structure gap and the semantic gap between utterances and logical forms. In this paper, we propose an unsupervised semantic parsing method - Synchronous Semantic Decoding (SSD), which can simultaneously resolve the semantic gap and the structure gap by jointly leveraging paraphrasing and grammar-constrained decoding. Specifically, we reformulate semantic parsing as a constrained paraphrasing problem: given an utterance, our model synchronously generates its canonical utterancel and meaning representation. During synchronously decoding: the utterance paraphrasing is constrained by the structure of the logical form, therefore the canonical utterance can be paraphrased controlledly; the semantic decoding is guided by the semantics of the canonical utterance, therefore its logical form can be generated unsupervisedly. Experimental results show that SSD is a promising approach and can achieve state-of-the-art unsupervised semantic parsing performance on multiple datasets.
Despite the well-developed cut-edge representation learning for language, most language representation models usually focus on specific levels of linguistic units. This work introduces universal language representation learning, i.e., embeddings of different levels of linguistic units or text with quite diverse lengths in a uniform vector space. We propose the training objective MiSAD that utilizes meaningful n-grams extracted from large unlabeled corpus by a simple but effective algorithm for pre-trained language models. Then we empirically verify that well designed pre-training scheme may effectively yield universal language representation, which will bring great convenience when handling multiple layers of linguistic objects in a unified way. Especially, our model achieves the highest accuracy on analogy tasks in different language levels and significantly improves the performance on downstream tasks in the GLUE benchmark and a question answering dataset.
Pre-trained language models (PrLMs) have demonstrated superior performance due to their strong ability to learn universal language representations from self-supervised pre-training. However, even with the help of the powerful PrLMs, it is still challenging to effectively capture task-related knowledge from dialogue texts which are enriched by correlations among speaker-aware utterances. In this work, we present SPIDER, Structural Pre-traIned DialoguE Reader, to capture dialogue exclusive features. To simulate the dialogue-like features, we propose two training objectives in addition to the original LM objectives: 1) utterance order restoration, which predicts the order of the permuted utterances in dialogue context; 2) sentence backbone regularization, which regularizes the model to improve the factual correctness of summarized subject-verb-object triplets. Experimental results on widely used dialogue benchmarks verify the effectiveness of the newly introduced self-supervised tasks.
Pre-trained language models (PLMs) have achieved great success in natural language processing. Most of PLMs follow the default setting of architecture hyper-parameters (e.g., the hidden dimension is a quarter of the intermediate dimension in feed-forward sub-networks) in BERT. Few studies have been conducted to explore the design of architecture hyper-parameters in BERT, especially for the more efficient PLMs with tiny sizes, which are essential for practical deployment on resource-constrained devices. In this paper, we adopt the one-shot Neural Architecture Search (NAS) to automatically search architecture hyper-parameters. Specifically, we carefully design the techniques of one-shot learning and the search space to provide an adaptive and efficient development way of tiny PLMs for various latency constraints. We name our method AutoTinyBERT and evaluate its effectiveness on the GLUE and SQuAD benchmarks. The extensive experiments show that our method outperforms both the SOTA search-based baseline (NAS-BERT) and the SOTA distillation-based methods (such as DistilBERT, TinyBERT, MiniLM, and MobileBERT). In addition, based on the obtained architectures, we propose a more efficient development method that is even faster than the development of a single PLM. The source code and models will be publicly available upon publication.
Due to recent pretrained multilingual representation models, it has become feasible to exploit labeled data from one language to train a cross-lingual model that can then be applied to multiple new languages. In practice, however, we still face the problem of scarce labeled data, leading to subpar results. In this paper, we propose a novel data augmentation strategy for better cross-lingual natural language inference by enriching the data to reflect more diversity in a semantically faithful way. To this end, we propose two methods of training a generative model to induce synthesized examples, and then leverage the resulting data using an adversarial training regimen for more robustness. In a series of detailed experiments, we show that this fruitful combination leads to substantial gains in cross-lingual inference.
As high-quality labeled data is scarce, unsupervised sentence representation learning has attracted much attention. In this paper, we propose a new framework with a two-branch Siamese Network which maximizes the similarity between two augmented views of each sentence. Specifically, given one augmented view of the input sentence, the online network branch is trained by predicting the representation yielded by the target network of the same sentence under another augmented view. Meanwhile, the target network branch is bootstrapped with a moving average of the online network. The proposed method significantly outperforms other state-of-the-art unsupervised methods on semantic textual similarity (STS) and classification tasks. It can be adopted as a post-training procedure to boost the performance of the supervised methods. We further extend our method for learning multilingual sentence representations and demonstrate its effectiveness on cross-lingual STS tasks. Our code is available at https://github.com/yanzhangnlp/BSL.
Abductive reasoning aims at inferring the most plausible explanation for observed events, which would play critical roles in various NLP applications, such as reading comprehension and question answering. To facilitate this task, a narrative text based abductive reasoning task 𝛼NLI is proposed, together with explorations about building reasoning framework using pretrained language models. However, abundant event commonsense knowledge is not well exploited for this task. To fill this gap, we propose a variational autoencoder based model ege-RoBERTa, which employs a latent variable to capture the necessary commonsense knowledge from event graph for guiding the abductive reasoning task. Experimental results show that through learning the external event graph knowledge, our approach outperforms the baseline methods on the 𝛼NLI task.
The uniform information density (UID) hypothesis, which posits that speakers behaving optimally tend to distribute information uniformly across a linguistic signal, has gained traction in psycholinguistics as an explanation for certain syntactic, morphological, and prosodic choices. In this work, we explore whether the UID hypothesis can be operationalized as an inductive bias for statistical language modeling. Specifically, we augment the canonical MLE objective for training language models with a regularizer that encodes UID. In experiments on ten languages spanning five language families, we find that using UID regularization consistently improves perplexity in language models, having a larger effect when training data is limited. Moreover, via an analysis of generated sequences, we find that UID-regularized language models have other desirable properties, e.g., they generate text that is more lexically diverse. Our results not only suggest that UID is a reasonable inductive bias for language modeling, but also provide an alternative validation of the UID hypothesis using modern-day NLP tools.
In computational psycholinguistics, various language models have been evaluated against human reading behavior (e.g., eye movement) to build human-like computational models. However, most previous efforts have focused almost exclusively on English, despite the recent trend towards linguistic universal within the general community. In order to fill the gap, this paper investigates whether the established results in computational psycholinguistics can be generalized across languages. Specifically, we re-examine an established generalization —the lower perplexity a language model has, the more human-like the language model is— in Japanese with typologically different structures from English. Our experiments demonstrate that this established generalization exhibits a surprising lack of universality; namely, lower perplexity is not always human-like. Moreover, this discrepancy between English and Japanese is further explored from the perspective of (non-)uniform information density. Overall, our results suggest that a cross-lingual evaluation will be necessary to construct human-like computational models.
Lately proposed Word Sense Disambiguation (WSD) systems have approached the estimated upper bound of the task on standard evaluation benchmarks. However, these systems typically implement the disambiguation of words in a document almost independently, underutilizing sense and word dependency in context. In this paper, we convert the nearly isolated decisions into interrelated ones by exposing senses in context when learning sense embeddings in a similarity-based Sense Aware Context Exploitation (SACE) architecture. Meanwhile, we enhance the context embedding learning with selected sentences from the same document, rather than utilizing only the sentence where each ambiguous word appears. Experiments on both English and multilingual WSD datasets have shown the effectiveness of our approach, surpassing previous state-of-the-art by large margins (3.7% and 1.2% respectively), especially on few-shot (14.3%) and zero-shot (35.9%) scenarios.
Frame Identification (FI) is a fundamental and challenging task in frame semantic parsing. The task aims to find the exact frame evoked by a target word in a given sentence. It is generally regarded as a classification task in existing work, where frames are treated as discrete labels or represented using onehot embeddings. However, the valuable knowledge about frames is neglected. In this paper, we propose a Knowledge-Guided Frame Identification framework (KGFI) that integrates three types frame knowledge, including frame definitions, frame elements and frame-to-frame relations, to learn better frame representation, which guides the KGFI to jointly map target words and frames into the same embedding space and subsequently identify the best frame by calculating the dot-product similarity scores between the target word embedding and all of the frame embeddings. The extensive experimental results demonstrate KGFI significantly outperforms the state-of-the-art methods on two benchmark datasets.
The advent of contextual word embeddings — representations of words which incorporate semantic and syntactic information from their context—has led to tremendous improvements on a wide variety of NLP tasks. However, recent contextual models have prohibitively high computational cost in many use-cases and are often hard to interpret. In this work, we demonstrate that our proposed distillation method, which is a simple extension of CBOW-based training, allows to significantly improve computational efficiency of NLP applications, while outperforming the quality of existing static embeddings trained from scratch as well as those distilled from previously proposed methods. As a side-effect, our approach also allows a fair comparison of both contextual and static embeddings via standard lexical evaluation tasks.
A critical challenge faced by supervised word sense disambiguation (WSD) is the lack of large annotated datasets with sufficient coverage of words in their diversity of senses. This inspired recent research on few-shot WSD using meta-learning. While such work has successfully applied meta-learning to learn new word senses from very few examples, its performance still lags behind its fully-supervised counterpart. Aiming to further close this gap, we propose a model of semantic memory for WSD in a meta-learning setting. Semantic memory encapsulates prior experiences seen throughout the lifetime of the model, which aids better generalization in limited data settings. Our model is based on hierarchical variational inference and incorporates an adaptive memory update rule via a hypernetwork. We show our model advances the state of the art in few-shot WSD, supports effective learning in extremely data scarce (e.g. one-shot) scenarios and produces meaning prototypes that capture similar senses of distinct words.
Transformer-based language models (LMs) pretrained on large text collections implicitly store a wealth of lexical semantic knowledge, but it is non-trivial to extract that knowledge effectively from their parameters. Inspired by prior work on semantic specialization of static word embedding (WE) models, we show that it is possible to expose and enrich lexical knowledge from the LMs, that is, to specialize them to serve as effective and universal “decontextualized” word encoders even when fed input words “in isolation” (i.e., without any context). Their transformation into such word encoders is achieved through a simple and efficient lexical fine-tuning procedure (termed LexFit) based on dual-encoder network structures. Further, we show that LexFit can yield effective word encoders even with limited lexical supervision and, via cross-lingual transfer, in different languages without any readily available external knowledge. Our evaluation over four established, structurally different lexical-level tasks in 8 languages indicates the superiority of LexFit-based WEs over standard static WEs (e.g., fastText) and WEs from vanilla LMs. Other extensive experiments and ablation studies further profile the LexFit framework, and indicate best practices and performance variations across LexFit variants, languages, and lexical tasks, also directly questioning the usefulness of traditional WE models in the era of large neural models.
In this paper we present the first model for directly synthesizing fluent, natural-sounding spoken audio captions for images that does not require natural language text as an intermediate representation or source of supervision. Instead, we connect the image captioning module and the speech synthesis module with a set of discrete, sub-word speech units that are discovered with a self-supervised visual grounding task. We conduct experiments on the Flickr8k spoken caption dataset in addition to a novel corpus of spoken audio captions collected for the popular MSCOCO dataset, demonstrating that our generated captions also capture diverse visual semantics of the images they describe. We investigate several different intermediate speech representations, and empirically find that the representation must satisfy several important properties to serve as drop-in replacements for text.
Multimodal sentiment analysis is the challenging research area that attends to the fusion of multiple heterogeneous modalities. The main challenge is the occurrence of some missing modalities during the multimodal fusion procedure. However, the existing techniques require all modalities as input, thus are sensitive to missing modalities at predicting time. In this work, the coupled-translation fusion network (CTFN) is firstly proposed to model bi-direction interplay via couple learning, ensuring the robustness in respect to missing modalities. Specifically, the cyclic consistency constraint is presented to improve the translation performance, allowing us directly to discard decoder and only embraces encoder of Transformer. This could contribute to a much lighter model. Due to the couple learning, CTFN is able to conduct bi-direction cross-modality intercorrelation parallelly. Based on CTFN, a hierarchical architecture is further established to exploit multiple bi-direction translations, leading to double multimodal fusing embeddings compared with traditional translation methods. Moreover, the convolution block is utilized to further highlight explicit interactions among those translations. For evaluation, CTFN was verified on two multimodal benchmarks with extensive ablation studies. The experiments demonstrate that the proposed framework achieves state-of-the-art or often competitive performance. Additionally, CTFN still maintains robustness when considering missing modality.
In this work, we demonstrate that the contextualized word vectors derived from pretrained masked language model-based encoders share a common, perhaps undesirable pattern across layers. Namely, we find cases of persistent outlier neurons within BERT and RoBERTa’s hidden state vectors that consistently bear the smallest or largest values in said vectors. In an attempt to investigate the source of this information, we introduce a neuron-level analysis method, which reveals that the outliers are closely related to information captured by positional embeddings. We also pre-train the RoBERTa-base models from scratch and find that the outliers disappear without using positional embeddings. These outliers, we find, are the major cause of anisotropy of encoders’ raw vector spaces, and clipping them leads to increased similarity across vectors. We demonstrate this in practice by showing that clipped vectors can more accurately distinguish word senses, as well as lead to better sentence embeddings when mean pooling. In three supervised tasks, we find that clipping does not affect the performance.
We propose an alternate approach to quantifying how well language models learn natural language: we ask how well they match the statistical tendencies of natural language. To answer this question, we analyze whether text generated from language models exhibits the statistical tendencies present in the human-generated text on which they were trained. We provide a framework–paired with significance tests–for evaluating the fit of language models to these trends. We find that neural language models appear to learn only a subset of the tendencies considered, but align much more closely with empirical trends than proposed theoretical distributions (when present). Further, the fit to different distributions is highly-dependent on both model architecture and generation strategy. As concrete examples, text generated under the nucleus sampling scheme adheres more closely to the type–token relationship of natural language than text produced using standard ancestral sampling; text from LSTMs reflects the natural language distributions over length, stopwords, and symbols surprisingly well.
The importance of explaining the outcome of a machine learning model, especially a black-box model, is widely acknowledged. Recent approaches explain an outcome by identifying the contributions of input features to this outcome. In environments involving large black-box models or complex inputs, this leads to computationally demanding algorithms. Further, these algorithms often suffer from low stability, with explanations varying significantly across similar examples. In this paper, we propose a Learning to Explain (L2E) approach that learns the behaviour of an underlying explanation algorithm simultaneously from all training examples. Once the explanation algorithm is distilled into an explainer network, it can be used to explain new instances. Our experiments on three classification tasks, which compare our approach to six explanation algorithms, show that L2E is between 5 and 7.5×10ˆ4 times faster than these algorithms, while generating more stable explanations, and having comparable faithfulness to the black-box model.
A stereotype is an over-generalized belief about a particular group of people, e.g., Asians are good at math or African Americans are athletic. Such beliefs (biases) are known to hurt target groups. Since pretrained language models are trained on large real-world data, they are known to capture stereotypical biases. It is important to quantify to what extent these biases are present in them. Although this is a rapidly growing area of research, existing literature lacks in two important aspects: 1) they mainly evaluate bias of pretrained language models on a small set of artificial sentences, even though these models are trained on natural data 2) current evaluations focus on measuring bias without considering the language modeling ability of a model, which could lead to misleading trust on a model even if it is a poor language model. We address both these problems. We present StereoSet, a large-scale natural English dataset to measure stereotypical biases in four domains: gender, profession, race, and religion. We contrast both stereotypical bias and language modeling ability of popular models like BERT, GPT-2, RoBERTa, and XLnet. We show that these models exhibit strong stereotypical biases. Our data and code are available at https://stereoset.mit.edu.
Deep learning models have achieved great success on the task of Natural Language Inference (NLI), though only a few attempts try to explain their behaviors. Existing explanation methods usually pick prominent features such as words or phrases from the input text. However, for NLI, alignments among words or phrases are more enlightening clues to explain the model. To this end, this paper presents AREC, a post-hoc approach to generate alignment rationale explanations for co-attention based models in NLI. The explanation is based on feature selection, which keeps few but sufficient alignments while maintaining the same prediction of the target model. Experimental results show that our method is more faithful and human-readable compared with many existing approaches. We further study and re-evaluate three typical models through our explanation beyond accuracy, and propose a simple method that greatly improves the model robustness.
This paper presents a novel pre-trained language models (PLM) compression approach based on the matrix product operator (short as MPO) from quantum many-body physics. It can decompose an original matrix into central tensors (containing the core information) and auxiliary tensors (with only a small proportion of parameters). With the decomposed MPO structure, we propose a novel fine-tuning strategy by only updating the parameters from the auxiliary tensors, and design an optimization algorithm for MPO-based approximation over stacked network architectures. Our approach can be applied to the original or the compressed PLMs in a general way, which derives a lighter network and significantly reduces the parameters to be fine-tuned. Extensive experiments have demonstrated the effectiveness of the proposed approach in model compression, especially the reduction in fine-tuning parameters (91% reduction on average). The code to reproduce the results of this paper can be found at https://github.com/RUCAIBox/MPOP.
In the recent advances of natural language processing, the scale of the state-of-the-art models and datasets is usually extensive, which challenges the application of sample-based explanation methods in many aspects, such as explanation interpretability, efficiency, and faithfulness. In this work, for the first time, we can improve the interpretability of explanations by allowing arbitrary text sequences as the explanation unit. On top of this, we implement a hessian-free method with a model faithfulness guarantee. Finally, to compare our method with the others, we propose a semantic-based evaluation metric that can better align with humans’ judgment of explanations than the widely adopted diagnostic or re-training measures. The empirical results on multiple real data sets demonstrate the proposed method’s superior performance to popular explanation techniques such as Influence Function or TracIn on semantic evaluation.
We study the problem of leveraging the syntactic structure of text to enhance pre-trained models such as BERT and RoBERTa. Existing methods utilize syntax of text either in the pre-training stage or in the fine-tuning stage, so that they suffer from discrepancy between the two stages. Such a problem would lead to the necessity of having human-annotated syntactic information, which limits the application of existing methods to broader scenarios. To address this, we present a model that utilizes the syntax of text in both pre-training and fine-tuning stages. Our model is based on Transformer with a syntax-aware attention layer that considers the dependency tree of the text. We further introduce a new pre-training task of predicting the syntactic distance among tokens in the dependency tree. We evaluate the model on three downstream tasks, including relation classification, entity typing, and question answering. Results show that our model achieves state-of-the-art performance on six public benchmark datasets. We have two major findings. First, we demonstrate that infusing automatically produced syntax of text improves pre-trained models. Second, global syntactic distances among tokens bring larger performance gains compared to local head relations between contiguous tokens.
Unsupervised Domain Adaptation (UDA) aims to transfer the knowledge of source domain to the unlabeled target domain. Existing methods typically require to learn to adapt the target model by exploiting the source data and sharing the network architecture across domains. However, this pipeline makes the source data risky and is inflexible for deploying the target model. This paper tackles a novel setting where only a trained source model is available and different network architectures can be adapted for target domain in terms of deployment environments. We propose a generic framework named Cross-domain Knowledge Distillation (CdKD) without needing any source data. CdKD matches the joint distributions between a trained source model and a set of target data during distilling the knowledge from the source model to the target domain. As a type of important knowledge in the source domain, for the first time, the gradient information is exploited to boost the transfer performance. Experiments on cross-domain text classification demonstrate that CdKD achieves superior performance, which verifies the effectiveness in this novel setting.
Today’s text classifiers inevitably suffer from unintended dataset biases, especially the document-level label bias and word-level keyword bias, which may hurt models’ generalization. Many previous studies employed data-level manipulations or model-level balancing mechanisms to recover unbiased distributions and thus prevent models from capturing the two types of biases. Unfortunately, they either suffer from the extra cost of data collection/selection/annotation or need an elaborate design of balancing strategies. Different from traditional factual inference in which debiasing occurs before or during training, counterfactual inference mitigates the influence brought by unintended confounders after training, which can make unbiased decisions with biased observations. Inspired by this, we propose a model-agnostic text classification debiasing framework – Corsair, which can effectively avoid employing data manipulations or designing balancing mechanisms. Concretely, Corsair first trains a base model on a training set directly, allowing the dataset biases ‘poison’ the trained model. In inference, given a factual input document, Corsair imagines its two counterfactual counterparts to distill and mitigate the two biases captured by the poisonous model. Extensive experiments demonstrate Corsair’s effectiveness, generalizability and fairness.
User interest modeling is critical for personalized news recommendation. Existing news recommendation methods usually learn a single user embedding for each user from their previous behaviors to represent their overall interest. However, user interest is usually diverse and multi-grained, which is difficult to be accurately modeled by a single user embedding. In this paper, we propose a news recommendation method with hierarchical user interest modeling, named HieRec. Instead of a single user embedding, in our method each user is represented in a hierarchical interest tree to better capture their diverse and multi-grained interest in news. We use a three-level hierarchy to represent 1) overall user interest; 2) user interest in coarse-grained topics like sports; and 3) user interest in fine-grained topics like football. Moreover, we propose a hierarchical user interest matching framework to match candidate news with different levels of user interest for more accurate user interest targeting. Extensive experiments on two real-world datasets validate our method can effectively improve the performance of user modeling for personalized news recommendation.
Personalized news recommendation methods are widely used in online news services. These methods usually recommend news based on the matching between news content and user interest inferred from historical behaviors. However, these methods usually have difficulties in making accurate recommendations to cold-start users, and tend to recommend similar news with those users have read. In general, popular news usually contain important information and can attract users with different interests. Besides, they are usually diverse in content and topic. Thus, in this paper we propose to incorporate news popularity information to alleviate the cold-start and diversity problems for personalized news recommendation. In our method, the ranking score for recommending a candidate news to a target user is the combination of a personalized matching score and a news popularity score. The former is used to capture the personalized user interest in news. The latter is used to measure time-aware popularity of candidate news, which is predicted based on news content, recency, and real-time CTR using a unified framework. Besides, we propose a popularity-aware user encoder to eliminate the popularity bias in user behaviors for accurate interest modeling. Experiments on two real-world datasets show our method can effectively improve the accuracy and diversity for news recommendation.
False claims that have been previously fact-checked can still spread on social media. To mitigate their continual spread, detecting previously fact-checked claims is indispensable. Given a claim, existing works focus on providing evidence for detection by reranking candidate fact-checking articles (FC-articles) retrieved by BM25. However, these performances may be limited because they ignore the following characteristics of FC-articles: (1) claims are often quoted to describe the checked events, providing lexical information besides semantics; (2) sentence templates to introduce or debunk claims are common across articles, providing pattern information. Models that ignore the two aspects only leverage semantic relevance and may be misled by sentences that describe similar but irrelevant events. In this paper, we propose a novel reranker, MTM (Memory-enhanced Transformers for Matching) to rank FC-articles using key sentences selected with event (lexical and semantic) and pattern information. For event information, we propose a ROUGE-guided Transformer which is finetuned with regression of ROUGE. For pattern information, we generate pattern vectors for matching with sentences. By fusing event and pattern information, we select key sentences to represent an article and then predict if the article fact-checks the given claim using the claim, key sentences, and patterns. Experiments on two real-world datasets show that MTM outperforms existing methods. Human evaluation proves that MTM can capture key sentences for explanations.
Although deep neural networks have achieved prominent performance on many NLP tasks, they are vulnerable to adversarial examples. We propose Dirichlet Neighborhood Ensemble (DNE), a randomized method for training a robust model to defense synonym substitution-based attacks. During training, DNE forms virtual sentences by sampling embedding vectors for each word in an input sentence from a convex hull spanned by the word and its synonyms, and it augments them with the training data. In such a way, the model is robust to adversarial attacks while maintaining the performance on the original clean data. DNE is agnostic to the network architectures and scales to large models (e.g., BERT) for NLP applications. Through extensive experimentation, we demonstrate that our method consistently outperforms recently proposed defense methods by a significant margin across different network architectures and multiple data sets.
Increasing the input length has been a driver of progress in language modeling with transformers. We identify conditions where shorter inputs are not harmful, and achieve perplexity and efficiency improvements through two new methods that decrease input length. First, we show that initially training a model on short subsequences before moving on to longer ones both reduces overall training time and, surprisingly, substantially improves perplexity. Second, we show how to improve the efficiency of recurrence methods in transformers, which let models condition on previously processed tokens when generating sequences that exceed the maximal length the transformer can handle at once. Existing methods require computationally expensive relative position embeddings; we introduce a simple alternative of adding absolute position embeddings to queries and keys instead of to word embeddings, which efficiently produces superior results. We show that these recurrent models also benefit from short input lengths. Combining these techniques speeds up training by a factor of 1.65, reduces memory usage, and substantially improves perplexity on WikiText-103, without adding any parameters.
Task variance regularization, which can be used to improve the generalization of Multi-task Learning (MTL) models, remains unexplored in multi-task text classification. Accordingly, to fill this gap, this paper investigates how the task might be effectively regularized, and consequently proposes a multi-task learning method based on adversarial multi-armed bandit. The proposed method, named BanditMTL, regularizes the task variance by means of a mirror gradient ascent-descent algorithm. Adopting BanditMTL in the multi-task text classification context is found to achieve state-of-the-art performance. The results of extensive experiments back up our theoretical analysis and validate the superiority of our proposals.
In knowledge graph embedding, the theoretical relationship between the softmax cross-entropy and negative sampling loss functions has not been investigated. This makes it difficult to fairly compare the results of the two different loss functions. We attempted to solve this problem by using the Bregman divergence to provide a unified interpretation of the softmax cross-entropy and negative sampling loss functions. Under this interpretation, we can derive theoretical findings for fair comparison. Experimental results on the FB15k-237 and WN18RR datasets show that the theoretical findings are valid in practical settings.
Logical table-to-text generation aims to automatically generate fluent and logically faithful text from tables. The task remains challenging where deep learning models often generated linguistically fluent but logically inconsistent text. The underlying reason may be that deep learning models often capture surface-level spurious correlations rather than the causal relationships between the table x and the sentence y. Specifically, in the training stage, a model can get a low empirical loss without understanding x and use spurious statistical cues instead. In this paper, we propose a de-confounded variational encoder-decoder (DCVED) based on causal intervention, learning the objective p(y|do(x)). Firstly, we propose to use variational inference to estimate the confounders in the latent space and cooperate with the causal intervention based on Pearl’s do-calculus to alleviate the spurious correlations. Secondly, to make the latent confounder meaningful, we propose a back-prediction process to predict the not-used entities but linguistically similar to the exactly selected ones. Finally, since our variational model can generate multiple candidates, we train a table-text selector to find out the best candidate sentence for the given table. An extensive set of experiments show that our model outperforms the baselines and achieves new state-of-the-art performance on two logical table-to-text datasets in terms of logical fidelity.
Recent researches have shown that large natural language processing (NLP) models are vulnerable to a kind of security threat called the Backdoor Attack. Backdoor attacked models can achieve good performance on clean test sets but perform badly on those input sentences injected with designed trigger words. In this work, we point out a potential problem of current backdoor attacking research: its evaluation ignores the stealthiness of backdoor attacks, and most of existing backdoor attacking methods are not stealthy either to system deployers or to system users. To address this issue, we first propose two additional stealthiness-based metrics to make the backdoor attacking evaluation more credible. We further propose a novel word-based backdoor attacking method based on negative data augmentation and modifying word embeddings, making an important step towards achieving stealthy backdoor attacking. Experiments on sentiment analysis and toxic detection tasks show that our method is much stealthier while maintaining pretty good attacking performance. Our code is available at https://github.com/lancopku/SOS.
Crowdsourcing is regarded as one prospective solution for effective supervised learning, aiming to build large-scale annotated training data by crowd workers. Previous studies focus on reducing the influences from the noises of the crowdsourced annotations for supervised models. We take a different point in this work, regarding all crowdsourced annotations as gold-standard with respect to the individual annotators. In this way, we find that crowdsourcing could be highly similar to domain adaptation, and then the recent advances of cross-domain methods can be almost directly applied to crowdsourcing. Here we take named entity recognition (NER) as a study case, suggesting an annotator-aware representation learning model that inspired by the domain adaptation methods which attempt to capture effective domain-aware features. We investigate both unsupervised and supervised crowdsourcing learning, assuming that no or only small-scale expert annotations are available. Experimental results on a benchmark crowdsourced NER dataset show that our method is highly effective, leading to a new state-of-the-art performance. In addition, under the supervised setting, we can achieve impressive performance gains with only a very small scale of expert annotations.
Recent studies strive to incorporate various human rationales into neural networks to improve model performance, but few pay attention to the quality of the rationales. Most existing methods distribute their models’ focus to distantly-labeled rationale words entirely and equally, while ignoring the potential important non-rationale words and not distinguishing the importance of different rationale words. In this paper, we propose two novel auxiliary loss functions to make better use of distantly-labeled rationales, which encourage models to maintain their focus on important words beyond labeled rationales (PINs) and alleviate redundant training on non-helpful rationales (NoIRs). Experiments on two representative classification tasks show that our proposed methods can push a classification model to effectively learn crucial clues from non-perfect rationales while maintaining the ability to spread its focus to other unlabeled important words, thus significantly outperform existing methods.
QA models based on pretrained language models have achieved remarkable performance on various benchmark datasets. However, QA models do not generalize well to unseen data that falls outside the training distribution, due to distributional shifts. Data augmentation (DA) techniques which drop/replace words have shown to be effective in regularizing the model from overfitting to the training data. Yet, they may adversely affect the QA tasks since they incur semantic changes that may lead to wrong answers for the QA task. To tackle this problem, we propose a simple yet effective DA method based on a stochastic noise generator, which learns to perturb the word embedding of the input questions and context without changing their semantics. We validate the performance of the QA models trained with our word embedding perturbation on a single source dataset, on five different target domains. The results show that our method significantly outperforms the baseline DA methods. Notably, the model trained with ours outperforms the model trained with more than 240K artificially generated QA pairs.
Arguably, the visual perception of conversational agents to the physical world is a key way for them to exhibit the human-like intelligence. Image-grounded conversation is thus proposed to address this challenge. Existing works focus on exploring the multimodal dialog models that ground the conversation on a given image. In this paper, we take a step further to study image-grounded conversation under a fully open-ended setting where no paired dialog and image are assumed available. Specifically, we present Maria, a neural conversation agent powered by the visual world experiences which are retrieved from a large-scale image index. Maria consists of three flexible components, i.e., text-to-image retriever, visual concept detector and visual-knowledge-grounded response generator. The retriever aims to retrieve a correlated image to the dialog from an image index, while the visual concept detector extracts rich visual knowledge from the image. Then, the response generator is grounded on the extracted visual knowledge and dialog context to generate the target response. Extensive experiments demonstrate Maria outperforms previous state-of-the-art methods on automatic metrics and human evaluation, and can generate informative responses that have some visual commonsense of the physical world.
Conversational dialogue systems (CDSs) are hard to evaluate due to the complexity of natural language. Automatic evaluation of dialogues often shows insufficient correlation with human judgements. Human evaluation is reliable but labor-intensive. We introduce a human-machine collaborative framework, HMCEval, that can guarantee reliability of the evaluation outcomes with reduced human effort. HMCEval casts dialogue evaluation as a sample assignment problem, where we need to decide to assign a sample to a human or a machine for evaluation. HMCEval includes a model confidence estimation module to estimate the confidence of the predicted sample assignment, and a human effort estimation module to estimate the human effort should the sample be assigned to human evaluation, as well as a sample assignment execution module that finds the optimum assignment solution based on the estimated confidence and effort. We assess the performance of HMCEval on the task of evaluating malevolence in dialogues. The experimental results show that HMCEval achieves around 99% evaluation accuracy with half of the human effort spared, showing that HMCEval provides reliable evaluation outcomes while reducing human effort by a large amount.
Conditional Variational AutoEncoder (CVAE) effectively increases the diversity and informativeness of responses in open-ended dialogue generation tasks through enriching the context vector with sampled latent variables. However, due to the inherent one-to-many and many-to-one phenomena in human dialogues, the sampled latent variables may not correctly reflect the contexts’ semantics, leading to irrelevant and incoherent generated responses. To resolve this problem, we propose Self-separated Conditional Variational AutoEncoder (abbreviated as SepaCVAE) that introduces group information to regularize the latent variables, which enhances CVAE by improving the responses’ relevance and coherence while maintaining their diversity and informativeness. SepaCVAE actively divides the input data into groups, and then widens the absolute difference between data pairs from distinct groups, while narrowing the relative distance between data pairs in the same group. Empirical results from automatic evaluation and detailed analysis demonstrate that SepaCVAE can significantly boost responses in well-established open-domain dialogue datasets.
Conversational Question Simplification (CQS) aims to simplify self-contained questions into conversational ones by incorporating some conversational characteristics, e.g., anaphora and ellipsis. Existing maximum likelihood estimation based methods often get trapped in easily learned tokens as all tokens are treated equally during training. In this work, we introduce a Reinforcement Iterative Sequence Editing (RISE) framework that optimizes the minimum Levenshtein distance through explicit editing actions. RISE is able to pay attention to tokens that are related to conversational characteristics. To train RISE, we devise an Iterative Reinforce Training (IRT) algorithm with a Dynamic Programming based Sampling (DPS) process to improve exploration. Experimental results on two benchmark datasets show that RISE significantly outperforms state-of-the-art methods and generalizes well on unseen data.
A video-grounded dialogue system is required to understand both dialogue, which contains semantic dependencies from turn to turn, and video, which contains visual cues of spatial and temporal scene variations. Building such dialogue systems is a challenging problem, involving various reasoning types on both visual and language inputs. Existing benchmarks do not have enough annotations to thoroughly analyze dialogue systems and understand their capabilities and limitations in isolation. These benchmarks are also not explicitly designed to minimise biases that models can exploit without actual reasoning. To address these limitations, in this paper, we present DVD, a Diagnostic Dataset for Video-grounded Dialogue. The dataset is designed to contain minimal biases and has detailed annotations for the different types of reasoning over the spatio-temporal space of video. Dialogues are synthesized over multiple question turns, each of which is injected with a set of cross-turn semantic relationships. We use DVD to analyze existing approaches, providing interesting insights into their abilities and limitations. In total, DVD is built from 11k CATER synthetic videos and contains 10 instances of 10-round dialogues for each video, resulting in more than 100k dialogues and 1M question-answer pairs. Our code and dataset are publicly available.
Emotion recognition in conversation (ERC) is a crucial component in affective dialogue systems, which helps the system understand users’ emotions and generate empathetic responses. However, most works focus on modeling speaker and contextual information primarily on the textual modality or simply leveraging multimodal information through feature concatenation. In order to explore a more effective way of utilizing both multimodal and long-distance contextual information, we propose a new model based on multimodal fused graph convolutional network, MMGCN, in this work. MMGCN can not only make use of multimodal dependencies effectively, but also leverage speaker information to model inter-speaker and intra-speaker dependency. We evaluate our proposed model on two public benchmark datasets, IEMOCAP and MELD, and the results prove the effectiveness of MMGCN, which outperforms other SOTA methods by a significant margin under the multimodal conversation setting.
A dialogue is essentially a multi-turn interaction among interlocutors. Effective evaluation metrics should reflect the dynamics of such interaction. Existing automatic metrics are focused very much on the turn-level quality, while ignoring such dynamics. To this end, we propose DynaEval, a unified automatic evaluation framework which is not only capable of performing turn-level evaluation, but also holistically considers the quality of the entire dialogue. In DynaEval, the graph convolutional network (GCN) is adopted to model a dialogue in totality, where the graph nodes denote each individual utterance and the edges represent the dependency between pairs of utterances. A contrastive loss is then applied to distinguish well-formed dialogues from carefully constructed negative samples. Experiments show that DynaEval significantly outperforms the state-of-the-art dialogue coherence model, and correlates strongly with human judgements across multiple dialogue evaluation aspects at both turn and dialogue level.
Finding codes given natural language query is beneficial to the productivity of software developers. Future progress towards better semantic matching between query and code requires richer supervised training resources. To remedy this, we introduce CoSQA dataset. It includes 20,604 labels for pairs of natural language queries and codes, each annotated by at least 3 human annotators. We further introduce a contrastive learning method dubbed CoCLR to enhance text-code matching, which works as a data augmenter to bring more artificially generated training instances. We show that, evaluated on CodeXGLUE with the same CodeBERT model, training on CoSQA improves the accuracy of code question answering by 5.1% and incorporating CoCLR brings a further improvement of 10.5%.
A few approaches have been developed to improve neural machine translation (NMT) models with multiple passes of decoding. However, their performance gains are limited because of lacking proper policies to terminate the multi-pass process. To address this issue, we introduce a novel architecture of Rewriter-Evaluator. Translating a source sentence involves multiple rewriting passes. In every pass, a rewriter generates a new translation to improve the past translation. Termination of this multi-pass process is determined by a score of translation quality estimated by an evaluator. We also propose prioritized gradient descent (PGD) to jointly and efficiently train the rewriter and the evaluator. Extensive experiments on three machine translation tasks show that our architecture notably improves the performances of NMT models and significantly outperforms prior methods. An oracle experiment reveals that it can largely reduce performance gaps to the oracle policy. Experiments confirm that the evaluator trained with PGD is more accurate than prior methods in determining proper numbers of rewriting.
Neural chat translation aims to translate bilingual conversational text, which has a broad application in international exchanges and cooperation. Despite the impressive performance of sentence-level and context-aware Neural Machine Translation (NMT), there still remain challenges to translate bilingual conversational text due to its inherent characteristics such as role preference, dialogue coherence, and translation consistency. In this paper, we aim to promote the translation quality of conversational text by modeling the above properties. Specifically, we design three latent variational modules to learn the distributions of bilingual conversational characteristics. Through sampling from these learned distributions, the latent variables, tailored for role preference, dialogue coherence, and translation consistency, are incorporated into the NMT model for better translation. We evaluate our approach on the benchmark dataset BConTrasT (English<->German) and a self-collected bilingual dialogue corpus, named BMELD (English<->Chinese). Extensive experiments show that our approach notably boosts the performance over strong baselines by a large margin and significantly surpasses some state-of-the-art context-aware NMT models in terms of BLEU and TER. Additionally, we make the BMELD dataset publicly available for the research community.
Multilingual neural machine translation with a single model has drawn much attention due to its capability to deal with multiple languages. However, the current multilingual translation paradigm often makes the model tend to preserve the general knowledge, but ignore the language-specific knowledge. Some previous works try to solve this problem by adding various kinds of language-specific modules to the model, but they suffer from the parameter explosion problem and require specialized manual design. To solve these problems, we propose to divide the model neurons into general and language-specific parts based on their importance across languages. The general part is responsible for preserving the general knowledge and participating in the translation of all the languages, while the language-specific part is responsible for preserving the language-specific knowledge and participating in the translation of some specific languages. Experimental results on several language pairs, covering IWSLT and Europarl corpus datasets, demonstrate the effectiveness and universality of the proposed method.
Multi-source sequence generation (MSG) is an important kind of sequence generation tasks that takes multiple sources, including automatic post-editing, multi-source translation, multi-document summarization, etc. As MSG tasks suffer from the data scarcity problem and recent pretrained models have been proven to be effective for low-resource downstream tasks, transferring pretrained sequence-to-sequence models to MSG tasks is essential. Although directly finetuning pretrained models on MSG tasks and concatenating multiple sources into a single long sequence is regarded as a simple method to transfer pretrained models to MSG tasks, we conjecture that the direct finetuning method leads to catastrophic forgetting and solely relying on pretrained self-attention layers to capture cross-source information is not sufficient. Therefore, we propose a two-stage finetuning method to alleviate the pretrain-finetune discrepancy and introduce a novel MSG model with a fine encoder to learn better representations in MSG tasks. Experiments show that our approach achieves new state-of-the-art results on the WMT17 APE task and multi-source translation task using the WMT14 test set. When adapted to document-level translation, our framework outperforms strong baselines significantly.
Few-shot crosslingual transfer has been shown to outperform its zero-shot counterpart with pretrained encoders like multilingual BERT. Despite its growing popularity, little to no attention has been paid to standardizing and analyzing the design of few-shot experiments. In this work, we highlight a fundamental risk posed by this shortcoming, illustrating that the model exhibits a high degree of sensitivity to the selection of few shots. We conduct a large-scale experimental study on 40 sets of sampled few shots for six diverse NLP tasks across up to 40 languages. We provide an analysis of success and failure cases of few-shot transfer, which highlights the role of lexical features. Additionally, we show that a straightforward full model finetuning approach is quite effective for few-shot transfer, outperforming several state-of-the-art few-shot approaches. As a step towards standardizing few-shot crosslingual experimental designs, we make our sampled few shots publicly available.
Coreference resolution is essential for natural language understanding and has been long studied in NLP. In recent years, as the format of Question Answering (QA) became a standard for machine reading comprehension (MRC), there have been data collection efforts, e.g., Dasigi et al. (2019), that attempt to evaluate the ability of MRC models to reason about coreference. However, as we show, coreference reasoning in MRC is a greater challenge than earlier thought; MRC datasets do not reflect the natural distribution and, consequently, the challenges of coreference reasoning. Specifically, success on these datasets does not reflect a model’s proficiency in coreference reasoning. We propose a methodology for creating MRC datasets that better reflect the challenges of coreference reasoning and use it to create a sample evaluation set. The results on our dataset show that state-of-the-art models still struggle with these phenomena. Furthermore, we develop an effective way to use naturally occurring coreference phenomena from existing coreference resolution datasets when training MRC models. This allows us to show an improvement in the coreference reasoning abilities of state-of-the-art models.
One of the main bottlenecks in developing discourse dependency parsers is the lack of annotated training data. A potential solution is to utilize abundant unlabeled data by using unsupervised techniques, but there is so far little research in unsupervised discourse dependency parsing. Fortunately, unsupervised syntactic dependency parsing has been studied by decades, which could potentially be adapted for discourse parsing. In this paper, we propose a simple yet effective method to adapt unsupervised syntactic dependency parsing methodology for unsupervised discourse dependency parsing. We apply the method to adapt two state-of-the-art unsupervised syntactic dependency parsing methods. Experimental results demonstrate that our adaptation is effective. Moreover, we extend the adapted methods to the semi-supervised and supervised setting and surprisingly, we find that they outperform previous methods specially designed for supervised discourse parsing. Further analysis shows our adaptations result in superiority not only in parsing accuracy but also in time and space efficiency.
We introduce a generic seq2seq parsing framework that casts constituency parsing problems (syntactic and discourse parsing) into a series of conditional splitting decisions. Our parsing model estimates the conditional probability distribution of possible splitting points in a given text span and supports efficient top-down decoding, which is linear in number of nodes. The conditional splitting formulation together with efficient beam search inference facilitate structural consistency without relying on expensive structured inference. Crucially, for discourse analysis we show that in our formulation, discourse segmentation can be framed as a special case of parsing which allows us to perform discourse parsing without requiring segmentation as a pre-requisite. Experiments show that our model achieves good results on the standard syntactic parsing tasks under settings with/without pre-trained representations and rivals state-of-the-art (SoTA) methods that are more computationally expensive than ours. In discourse parsing, our method outperforms SoTA by a good margin.
Named Entity Recognition (NER) is the task of identifying spans that represent entities in sentences. Whether the entity spans are nested or discontinuous, the NER task can be categorized into the flat NER, nested NER, and discontinuous NER subtasks. These subtasks have been mainly solved by the token-level sequence labelling or span-level classification. However, these solutions can hardly tackle the three kinds of NER subtasks concurrently. To that end, we propose to formulate the NER subtasks as an entity span sequence generation task, which can be solved by a unified sequence-to-sequence (Seq2Seq) framework. Based on our unified framework, we can leverage the pre-trained Seq2Seq model to solve all three kinds of NER subtasks without the special design of the tagging schema or ways to enumerate spans. We exploit three types of entity representations to linearize entities into a sequence. Our proposed framework is easy-to-implement and achieves state-of-the-art (SoTA) or near SoTA performance on eight English NER datasets, including two flat NER datasets, three nested NER datasets, and three discontinuous NER datasets.
Unlike English letters, Chinese characters have rich and specific meanings. Usually, the meaning of a word can be derived from its constituent characters in some way. Several previous works on syntactic parsing propose to annotate shallow word-internal structures for better utilizing character-level information. This work proposes to model the deep internal structures of Chinese words as dependency trees with 11 labels for distinguishing syntactic relationships. First, based on newly compiled annotation guidelines, we manually annotate a word-internal structure treebank (WIST) consisting of over 30K multi-char words from Chinese Penn Treebank. To guarantee quality, each word is independently annotated by two annotators and inconsistencies are handled by a third senior annotator. Second, we present detailed and interesting analysis on WIST to reveal insights on Chinese word formation. Third, we propose word-internal structure parsing as a new task, and conduct benchmark experiments using a competitive dependency parser. Finally, we present two simple ways to encode word-internal structures, leading to promising gains on the sentence-level syntactic parsing task.
Named Entity Recognition (NER) for low-resource languages is a both practical and challenging research problem. This paper addresses zero-shot transfer for cross-lingual NER, especially when the amount of source-language training data is also limited. The paper first proposes a simple but effective labeled sequence translation method to translate source-language training data to target languages and avoids problems such as word order change and entity span determination. With the source-language data as well as the translated data, a generation-based multilingual data augmentation method is introduced to further increase diversity by generating synthetic labeled data in multiple languages. These augmented data enable the language model based NER models to generalize better with both the language-specific features from the target-language synthetic data and the language-independent features from multilingual synthetic data. An extensive set of experiments were conducted to demonstrate encouraging cross-lingual transfer performance of the new research on a wide variety of target languages.
Lexicon information and pre-trained models, such as BERT, have been combined to explore Chinese sequence labeling tasks due to their respective strengths. However, existing methods solely fuse lexicon features via a shallow and random initialized sequence layer and do not integrate them into the bottom layers of BERT. In this paper, we propose Lexicon Enhanced BERT (LEBERT) for Chinese sequence labeling, which integrates external lexicon knowledge into BERT layers directly by a Lexicon Adapter layer. Compared with existing methods, our model facilitates deep lexicon knowledge fusion at the lower layers of BERT. Experiments on ten Chinese datasets of three tasks including Named Entity Recognition, Word Segmentation, and Part-of-Speech Tagging, show that LEBERT achieves state-of-the-art results.
In recent years, math word problem solving has received considerable attention and achieved promising results, but previous methods rarely take numerical values into consideration. Most methods treat the numerical values in the problems as number symbols, and ignore the prominent role of the numerical values in solving the problem. In this paper, we propose a novel approach called NumS2T, which enhances math word problem solving performance by explicitly incorporating numerical values into a sequence-to-tree network. In addition, a numerical properties prediction mechanism is used to capture the category and comparison information of numerals and measure their importance in global expressions. Experimental results on the Math23K and APE datasets demonstrate that our model achieves better performance than existing state-of-the-art models.
Previous math word problem solvers following the encoder-decoder paradigm fail to explicitly incorporate essential math symbolic constraints, leading to unexplainable and unreasonable predictions. Herein, we propose Neural-Symbolic Solver (NS-Solver) to explicitly and seamlessly incorporate different levels of symbolic constraints by auxiliary tasks. Our NS-Solver consists of a problem reader to encode problems, a programmer to generate symbolic equations, and a symbolic executor to obtain answers. Along with target expression supervision, our solver is also optimized via 4 new auxiliary objectives to enforce different symbolic reasoning: a) self-supervised number prediction task predicting both number quantity and number locations; b) commonsense constant prediction task predicting what prior knowledge (e.g. how many legs a chicken has) is required; c) program consistency checker computing the semantic loss between predicted equation and target equation to ensure reasonable equation mapping; d) duality exploiting task exploiting the quasi-duality between symbolic equation generation and problem’s part-of-speech generation to enhance the understanding ability of a solver. Besides, to provide a more realistic and challenging benchmark for developing a universal and scalable solver, we also construct a new largescale MWP benchmark CM17K consisting of 4 kinds of MWPs (arithmetic, one-unknown linear, one-unknown non-linear, equation set) with more than 17K samples. Extensive experiments on Math23K and our CM17k demonstrate the superiority of our NS-Solver compared to state-of-the-art methods.
Recently, the performance of Pre-trained Language Models (PLMs) has been significantly improved by injecting knowledge facts to enhance their abilities of language understanding. For medical domains, the background knowledge sources are especially useful, due to the massive medical terms and their complicated relations are difficult to understand in text. In this work, we introduce SMedBERT, a medical PLM trained on large-scale medical corpora, incorporating deep structured semantic knowledge from neighbours of linked-entity. In SMedBERT, the mention-neighbour hybrid attention is proposed to learn heterogeneous-entity information, which infuses the semantic representations of entity types into the homogeneous neighbouring entity structure. Apart from knowledge integration as external features, we propose to employ the neighbors of linked-entities in the knowledge graph as additional global contexts of text mentions, allowing them to communicate via shared neighbors, thus enrich their semantic representations. Experiments demonstrate that SMedBERT significantly outperforms strong baselines in various knowledge-intensive Chinese medical tasks. It also improves the performance of other tasks such as question answering, question matching and natural language inference.
When evaluating an article and the claims it makes, a critical reader must be able to assess where the information presented comes from, and whether the various claims are mutually consistent and support the conclusion. This motivates the study of claim provenance, which seeks to trace and explain the origins of claims. In this paper, we introduce new techniques to model and reason about the provenance of multiple interacting claims, including how to capture fine-grained information about the context. Our solution hinges on first identifying the sentences that potentially contain important external information. We then develop a query generator with our novel rank-aware cross attention mechanism, which aims at generating metadata for the source article, based on the context and the signals collected from a search engine. This establishes relevant search queries, and it allows us to obtain source article candidates for each identified sentence and propose an ILP based algorithm to infer the best sources. We experiment with a newly created evaluation dataset, Politi-Prov, based on fact-checking articles from www.politifact.com; our experimental results show that our solution leads to a significant improvement over baselines.
Medical imaging plays a significant role in clinical practice of medical diagnosis, where the text reports of the images are essential in understanding them and facilitating later treatments. By generating the reports automatically, it is beneficial to help lighten the burden of radiologists and significantly promote clinical automation, which already attracts much attention in applying artificial intelligence to medical domain. Previous studies mainly follow the encoder-decoder paradigm and focus on the aspect of text generation, with few studies considering the importance of cross-modal mappings and explicitly exploit such mappings to facilitate radiology report generation. In this paper, we propose a cross-modal memory networks (CMN) to enhance the encoder-decoder framework for radiology report generation, where a shared memory is designed to record the alignment between images and texts so as to facilitate the interaction and generation across modalities. Experimental results illustrate the effectiveness of our proposed model, where state-of-the-art performance is achieved on two widely used benchmark datasets, i.e., IU X-Ray and MIMIC-CXR. Further analyses also prove that our model is able to better align information from radiology images and texts so as to help generating more accurate reports in terms of clinical indicators.
There is content such as hate speech, offensive, toxic or aggressive documents, which are perceived differently by their consumers. They are commonly identified using classifiers solely based on textual content that generalize pre-agreed meanings of difficult problems. Such models provide the same results for each user, which leads to high misclassification rate observable especially for contentious, aggressive documents. Both document controversy and user nonconformity require new solutions. Therefore, we propose novel personalized approaches that respect individual beliefs expressed by either user conformity-based measures or various embeddings of their previous text annotations. We found that only a few annotations of most controversial documents are enough for all our personalization methods to significantly outperform classic, generalized solutions. The more controversial the content, the greater the gain. The personalized solutions may be used to efficiently filter unwanted aggressive content in the way adjusted to a given person.
As more and more product reviews are posted in both text and images, Multimodal Review Analysis (MRA) becomes an attractive research topic. Among the existing review analysis tasks, helpfulness prediction on review text has become predominant due to its importance for e-commerce platforms and online shops, i.e. helping customers quickly acquire useful product information. This paper proposes a new task Multimodal Review Helpfulness Prediction (MRHP) aiming to analyze the review helpfulness from text and visual modalities. Meanwhile, a novel Multi-perspective Coherent Reasoning method (MCR) is proposed to solve the MRHP task, which conducts joint reasoning over texts and images from both the product and the review, and aggregates the signals to predict the review helpfulness. Concretely, we first propose a product-review coherent reasoning module to measure the intra- and inter-modal coherence between the target product and the review. In addition, we also devise an intra-review coherent reasoning module to identify the coherence between the text content and images of the review, which is a piece of strong evidence for review helpfulness prediction. To evaluate the effectiveness of MCR, we present two newly collected multimodal review datasets as benchmark evaluation resources for the MRHP task. Experimental results show that our MCR method can lead to a performance increase of up to 8.5% as compared to the best performing text-only model. The source code and datasets can be obtained from https://github.com/jhliu17/MCR.
In this paper, we propose Shallow Aggressive Decoding (SAD) to improve the online inference efficiency of the Transformer for instantaneous Grammatical Error Correction (GEC). SAD optimizes the online inference efficiency for GEC by two innovations: 1) it aggressively decodes as many tokens as possible in parallel instead of always decoding only one token in each step to improve computational parallelism; 2) it uses a shallow decoder instead of the conventional Transformer architecture with balanced encoder-decoder depth to reduce the computational cost during inference. Experiments in both English and Chinese GEC benchmarks show that aggressive decoding could yield identical predictions to greedy decoding but with significant speedup for online inference. Its combination with the shallow decoder could offer an even higher online inference speedup over the powerful Transformer baseline without quality loss. Not only does our approach allow a single model to achieve the state-of-the-art results in English GEC benchmarks: 66.4 F0.5 in the CoNLL-14 and 72.9 F0.5 in the BEA-19 test set with an almost 10x online inference speedup over the Transformer-big model, but also it is easily adapted to other languages. Our code is available at https://github.com/AutoTemp/Shallow-Aggressive-Decoding.
The ICD coding task aims at assigning codes of the International Classification of Diseases in clinical notes. Since manual coding is very laborious and prone to errors, many methods have been proposed for the automatic ICD coding task. However, existing works either ignore the long-tail of code frequency or the noisy clinical notes. To address the above issues, we propose an Interactive Shared Representation Network with Self-Distillation Mechanism. Specifically, an interactive shared representation network targets building connections among codes while modeling the co-occurrence, consequently alleviating the long-tail problem. Moreover, to cope with the noisy text issue, we encourage the model to focus on the clinical note’s noteworthy part and extract valuable information through a self-distillation learning mechanism. Experimental results on two MIMIC datasets demonstrate the effectiveness of our method.
Chinese Spelling Check (CSC) is a challenging task due to the complex characteristics of Chinese characters. Statistics reveal that most Chinese spelling errors belong to phonological or visual errors. However, previous methods rarely utilize phonological and morphological knowledge of Chinese characters or heavily rely on external resources to model their similarities. To address the above issues, we propose a novel end-to-end trainable model called PHMOSpell, which promotes the performance of CSC with multi-modal information. Specifically, we derive pinyin and glyph representations for Chinese characters from audio and visual modalities respectively, which are integrated into a pre-trained language model by a well-designed adaptive gating mechanism. To verify its effectiveness, we conduct comprehensive experiments and ablation tests. Experimental results on three shared benchmarks demonstrate that our model consistently outperforms previous state-of-the-art models.
This paper explores the task of Difficulty-Controllable Question Generation (DCQG), which aims at generating questions with required difficulty levels. Previous research on this task mainly defines the difficulty of a question as whether it can be correctly answered by a Question Answering (QA) system, lacking interpretability and controllability. In our work, we redefine question difficulty as the number of inference steps required to answer it and argue that Question Generation (QG) systems should have stronger control over the logic of generated questions. To this end, we propose a novel framework that progressively increases question difficulty through step-by-step rewriting under the guidance of an extracted reasoning chain. A dataset is automatically constructed to facilitate the research, on which extensive experiments are conducted to test the performance of our method.
Table-to-text generation aims at automatically generating natural text to help people conveniently obtain salient information in tables. Although neural models for table-to-text have achieved remarkable progress, some problems are still overlooked. Previous methods cannot deduce the factual results from the entity’s (player or team) performance and the relations between entities. To solve this issue, we first build an entity graph from the input tables and introduce a reasoning module to perform reasoning on the graph. Moreover, there are different relations (e.g., the numeric size relation and the importance relation) between records in different dimensions. And these relations may contribute to the data-to-text generation. However, it is hard for a vanilla encoder to capture these. Consequently, we propose to utilize two auxiliary tasks, Number Ranking (NR) and Importance Ranking (IR), to supervise the encoder to capture the different relations. Experimental results on ROTOWIRE and RW-FG show that our method not only has a good generalization but also outperforms previous methods on several metrics: BLEU, Content Selection, Content Ordering.
The multimodality problem has become a major challenge of existing non-autoregressive generation (NAG) systems. A common solution often resorts to sequence-level knowledge distillation by rebuilding the training dataset through autoregressive generation (hereinafter known as “teacher AG”). The success of such methods may largely depend on a latent assumption, i.e., the teacher AG is superior to the NAG model. However, in this work, we experimentally reveal that this assumption does not always hold for the text generation tasks like text summarization and story ending generation. To provide a feasible solution to the multimodality problem of NAG, we propose incorporating linguistic structure (Part-of-Speech sequence in particular) into NAG inference instead of relying on teacher AG. More specifically, the proposed POS-constrained Parallel Decoding (POSPD) method aims at providing a specific POS sequence to constrain the NAG model during decoding. Our experiments demonstrate that POSPD consistently improves NAG models on four text generation tasks to a greater extent compared to knowledge distillation. This observation validates the necessity of exploring the alternatives for sequence-level knowledge distillation.
A well-known limitation in pretrain-finetune paradigm lies in its inflexibility caused by the one-size-fits-all vocabulary.This potentially weakens the effect when applying pretrained models into natural language generation (NLG) tasks, especially for the subword distributions between upstream and downstream tasks with significant discrepancy. Towards approaching this problem, we extend the vanilla pretrain-finetune pipeline with an extra embedding transfer step. Specifically, a plug-and-play embedding generator is introduced to produce the representation of any input token, according to pre-trained embeddings of its morphologically similar ones.Thus, embeddings of mismatch tokens in downstream tasks can also be efficiently initialized.We conduct experiments on a variety of NLG tasks under the pretrain-finetune fashion. Experimental results and extensive analyses show that the proposed strategy offers us opportunities to feel free to transfer the vocabulary, leading to more efficient and better performed downstream NLG models.
In order to deeply understand the capability of pretrained language models in text generation and conduct a diagnostic evaluation, we propose TGEA, an error-annotated dataset with multiple benchmark tasks for text generation from pretrained language models (PLMs). We use carefully selected prompt words to guide GPT-2 to generate candidate sentences, from which we select 47K for error annotation. Crowdsourced workers manually check each of these sentences and detect 12k erroneous sentences. We create an error taxonomy to cover 24 types of errors occurring in these erroneous sentences according to the nature of errors with respect to linguistics and knowledge (e.g., common sense). For each erroneous span in PLM-generated sentences, we also detect another span that is closely associated with it. Each error is hence manually labeled with comprehensive annotations, including the span of the error, the associated span, minimal correction to the error, the type of the error, and rationale behind the error. Apart from the fully annotated dataset, we also present a detailed description of the data collection procedure, statistics and analysis of the dataset. This is the first dataset with comprehensive annotations for PLM-generated texts, which facilitates the diagnostic evaluation of PLM-based text generation. Furthermore, we use TGEA as a benchmark dataset and propose a series of automatic diagnosis tasks, including error detection, error type classification, associated span detection, error rationale generation, to further promote future study on the automatic error detection and correction on texts generated by pretrained language models.
Transformer-based models have achieved state-of-the-art results in a wide range of natural language processing (NLP) tasks including document summarization. Typically these systems are trained by fine-tuning a large pre-trained model to the target task. One issue with these transformer-based models is that they do not scale well in terms of memory and compute requirements as the input length grows. Thus, for long document summarization, it can be challenging to train or fine-tune these models. In this work, we exploit large pre-trained transformer-based models and address long-span dependencies in abstractive summarization using two methods: local self-attention; and explicit content selection. These approaches are compared on a range of network configurations. Experiments are carried out on standard long-span summarization tasks, including Spotify Podcast, arXiv, and PubMed datasets. We demonstrate that by combining these methods, we can achieve state-of-the-art results on all three tasks in the ROUGE scores. Moreover, without a large-scale GPU card, our approach can achieve comparable or better results than existing approaches.
In the field of dialogue summarization, due to the lack of training data, it is often difficult for supervised summary generation methods to learn vital information from dialogue context with limited data. Several attempts on unsupervised summarization for text by leveraging semantic information solely or auto-encoder strategy (i.e., sentence compression), it however cannot be adapted to the dialogue scene due to the limited words in utterances and huge gap between the dialogue and its summary. In this study, we propose a novel unsupervised strategy to address this challenge, which roots from the hypothetical foundation that a superior summary approximates a replacement of the original dialogue, and they are roughly equivalent for auxiliary (self-supervised) tasks, e.g., dialogue generation. The proposed strategy RepSum is applied to generate both extractive and abstractive summary with the guidance of the followed nˆth utterance generation and classification tasks. Extensive experiments on various datasets demonstrate the superiority of the proposed model compared with the state-of-the-art methods.
Abstractive summarization for long-document or multi-document remains challenging for the Seq2Seq architecture, as Seq2Seq is not good at analyzing long-distance relations in text. In this paper, we present BASS, a novel framework for Boosting Abstractive Summarization based on a unified Semantic graph, which aggregates co-referent phrases distributing across a long range of context and conveys rich relations between phrases. Further, a graph-based encoder-decoder model is proposed to improve both the document representation and summary generation process by leveraging the graph structure. Specifically, several graph augmentation methods are designed to encode both the explicit and implicit relations in the text while the graph-propagation attention mechanism is developed in the decoder to select salient content into the summary. Empirical results show that the proposed architecture brings substantial improvements for both long-document and multi-document summarization tasks.
Given a set of related publications, related work section generation aims to provide researchers with an overview of the specific research area by summarizing these works and introducing them in a logical order. Most of existing related work generation models follow the inflexible extractive style, which directly extract sentences from multiple original papers to form a related work discussion. Hence, in this paper, we propose a Relation-aware Related work Generator (RRG), which generates an abstractive related work from the given multiple scientific papers in the same research area. Concretely, we propose a relation-aware multi-document encoder that relates one document to another according to their content dependency in a relation graph. The relation graph and the document representation are interacted and polished iteratively, complementing each other in the training process. We also contribute two public datasets composed of related work sections and their corresponding papers. Extensive experiments on the two datasets show that the proposed model brings substantial improvements over several strong baselines. We hope that this work will promote advances in related work generation task.
Professional summaries are written with document-level information, such as the theme of the document, in mind. This is in contrast with most seq2seq decoders which simultaneously learn to focus on salient content, while deciding what to generate, at each decoding step. With the motivation to narrow this gap, we introduce Focus Attention Mechanism, a simple yet effective method to encourage decoders to proactively generate tokens that are similar or topical to the input document. Further, we propose a Focus Sampling method to enable generation of diverse summaries, an area currently understudied in summarization. When evaluated on the BBC extreme summarization task, two state-of-the-art models augmented with Focus Attention generate summaries that are closer to the target and more faithful to their input documents, outperforming their vanilla counterparts on ROUGE and multiple faithfulness measures. We also empirically demonstrate that Focus Sampling is more effective in generating diverse and faithful summaries than top-k or nucleus sampling-based decoding methods.
The availability of large-scale datasets has driven the development of neural models that create generic summaries from single or multiple documents. In this work we consider query focused summarization (QFS), a task for which training data in the form of queries, documents, and summaries is not readily available. We propose to decompose QFS into (1) query modeling (i.e., finding supportive evidence within a set of documents for a query) and (2) conditional language modeling (i.e., summary generation). We introduce MaRGE, a Masked ROUGE Regression framework for evidence estimation and ranking which relies on a unified representation for summaries and queries, so that summaries in generic data can be converted into proxy queries for learning a query model. Experiments across QFS benchmarks and query types show that our model achieves state-of-the-art performance despite learning from weak supervision.
This paper studies the bias problem of multi-hop question answering models, of answering correctly without correct reasoning. One way to robustify these models is by supervising to not only answer right, but also with right reasoning chains. An existing direction is to annotate reasoning chains to train models, requiring expensive additional annotations. In contrast, we propose a new approach to learn evidentiality, deciding whether the answer prediction is supported by correct evidences, without such annotations. Instead, we compare counterfactual changes in answer confidence with and without evidence sentences, to generate “pseudo-evidentiality” annotations. We validate our proposed model on an original set and challenge set in HotpotQA, showing that our method is accurate and robust in multi-hop reasoning.
Dense passage retrieval has been shown to be an effective approach for information retrieval tasks such as open domain question answering. Under this paradigm, a dual-encoder model is learned to encode questions and passages separately into vector representations, and all the passage vectors are then pre-computed and indexed, which can be efficiently retrieved by vector space search during inference time. In this paper, we propose a new contrastive learning method called Cross Momentum Contrastive learning (xMoCo), for learning a dual-encoder model for question-passage matching. Our method efficiently maintains a large pool of negative samples like the original MoCo, and by jointly optimizing question-to-passage and passage-to-question matching tasks, enables using separate encoders for questions and passages. We evaluate our method on various open-domain question answering dataset, and the experimental results show the effectiveness of the proposed method.
One of the main challenges in conversational question answering (CQA) is to resolve the conversational dependency, such as anaphora and ellipsis. However, existing approaches do not explicitly train QA models on how to resolve the dependency, and thus these models are limited in understanding human dialogues. In this paper, we propose a novel framework, ExCorD (Explicit guidance on how to resolve Conversational Dependency) to enhance the abilities of QA models in comprehending conversational context. ExCorD first generates self-contained questions that can be understood without the conversation history, then trains a QA model with the pairs of original and self-contained questions using a consistency-based regularizer. In our experiments, we demonstrate that ExCorD significantly improves the QA models’ performance by up to 1.2 F1 on QuAC, and 5.2 F1 on CANARD, while addressing the limitations of the existing approaches.
We present a new human-human dialogue dataset - PhotoChat, the first dataset that casts light on the photo sharing behavior in online messaging. PhotoChat contains 12k dialogues, each of which is paired with a user photo that is shared during the conversation. Based on this dataset, we propose two tasks to facilitate research on image-text modeling: a photo-sharing intent prediction task that predicts whether one intends to share a photo in the next conversation turn, and a photo retrieval task that retrieves the most relevant photo according to the dialogue context. In addition, for both tasks, we provide baseline models using the state-of-the-art models and report their benchmark performances. The best image retrieval model achieves 10.4% recall@1 (out of 1000 candidates) and the best photo intent prediction model achieves 58.1% F1 score, indicating that the dataset presents interesting yet challenging real-world problems. We are releasing PhotoChat to facilitate future research work among the community.
A neural multimodal machine translation (MMT) system is one that aims to perform better translation by extending conventional text-only translation models with multimodal information. Many recent studies report improvements when equipping their models with the multimodal module, despite the controversy of whether such improvements indeed come from the multimodal part. We revisit the contribution of multimodal information in MMT by devising two interpretable MMT models. To our surprise, although our models replicate similar gains as recently developed multimodal-integrated systems achieved, our models learn to ignore the multimodal information. Upon further investigation, we discover that the improvements achieved by the multimodal models over text-only counterparts are in fact results of the regularization effect. We report empirical findings that highlight the importance of MMT models’ interpretability, and discuss how our findings will benefit future research.
Video Question Answering is a task which requires an AI agent to answer questions grounded in video. This task entails three key challenges: (1) understand the intention of various questions, (2) capturing various elements of the input video (e.g., object, action, causality), and (3) cross-modal grounding between language and vision information. We propose Motion-Appearance Synergistic Networks (MASN), which embed two cross-modal features grounded on motion and appearance information and selectively utilize them depending on the question’s intentions. MASN consists of a motion module, an appearance module, and a motion-appearance fusion module. The motion module computes the action-oriented cross-modal joint representations, while the appearance module focuses on the appearance aspect of the input video. Finally, the motion-appearance fusion module takes each output of the motion module and the appearance module as input, and performs question-guided fusion. As a result, MASN achieves new state-of-the-art performance on the TGIF-QA and MSVD-QA datasets. We also conduct qualitative analysis by visualizing the inference results of MASN.
We study the problem of learning a named entity recognition (NER) tagger using noisy labels from multiple weak supervision sources. Though cheap to obtain, the labels from weak supervision sources are often incomplete, inaccurate, and contradictory, making it difficult to learn an accurate NER model. To address this challenge, we propose a conditional hidden Markov model (CHMM), which can effectively infer true labels from multi-source noisy labels in an unsupervised way. CHMM enhances the classic hidden Markov model with the contextual representation power of pre-trained language models. Specifically, CHMM learns token-wise transition and emission probabilities from the BERT embeddings of the input tokens to infer the latent true labels from noisy observations. We further refine CHMM with an alternate-training approach (CHMM-ALT). It fine-tunes a BERT-NER model with the labels inferred by CHMM, and this BERT-NER’s output is regarded as an additional weak source to train the CHMM in return. Experiments on four NER benchmarks from various domains show that our method outperforms state-of-the-art weakly supervised NER models by wide margins.
The journey of reducing noise from distant supervision (DS) generated training data has been started since the DS was first introduced into the relation extraction (RE) task. For the past decade, researchers apply the multi-instance learning (MIL) framework to find the most reliable feature from a bag of sentences. Although the pattern of MIL bags can greatly reduce DS noise, it fails to represent many other useful sentence features in the datasets. In many cases, these sentence features can only be acquired by extra sentence-level human annotation with heavy costs. Therefore, the performance of distantly supervised RE models is bounded. In this paper, we go beyond typical MIL framework and propose a novel contrastive instance learning (CIL) framework. Specifically, we regard the initial MIL as the relational triple encoder and constraint positive pairs against negative pairs for each instance. Experiments demonstrate the effectiveness of our proposed framework, with significant improvements over the previous methods on NYT10, GDS and KBP.
Distant supervision for relation extraction provides uniform bag labels for each sentence inside the bag, while accurate sentence labels are important for downstream applications that need the exact relation type. Directly using bag labels for sentence-level training will introduce much noise, thus severely degrading performance. In this work, we propose the use of negative training (NT), in which a model is trained using complementary labels regarding that “the instance does not belong to these complementary labels”. Since the probability of selecting a true label as a complementary label is low, NT provides less noisy information. Furthermore, the model trained with NT is able to separate the noisy data from the training data. Based on NT, we propose a sentence-level framework, SENT, for distant relation extraction. SENT not only filters the noisy data to construct a cleaner dataset, but also performs a re-labeling process to transform the noisy data into useful training data, thus further benefiting the model’s performance. Experimental results show the significant improvement of the proposed method over previous methods on sentence-level evaluation and de-noise effect.
Medical named entity recognition (NER) and normalization (NEN) are fundamental for constructing knowledge graphs and building QA systems. Existing implementations for medical NER and NEN are suffered from the error propagation between the two tasks. The mispredicted mentions from NER will directly influence the results of NEN. Therefore, the NER module is the bottleneck of the whole system. Besides, the learnable features for both tasks are beneficial to improving the model performance. To avoid the disadvantages of existing models and exploit the generalized representation across the two tasks, we design an end-to-end progressive multi-task learning model for jointly modeling medical NER and NEN in an effective way. There are three level tasks with progressive difficulty in the framework. The progressive tasks can reduce the error propagation with the incremental task settings which implies the lower level tasks gain the supervised signals other than errors from the higher level tasks to improve their performances. Besides, the context features are exploited to enrich the semantic information of entity mentions extracted by NER. The performance of NEN profits from the enhanced entity mention features. The standard entities from knowledge bases are introduced into the NER module for extracting corresponding entity mentions correctly. The empirical results on two publicly available medical literature datasets demonstrate the superiority of our method over nine typical methods.
Joint extraction of entities and relations from unstructured texts is a crucial task in information extraction. Recent methods achieve considerable performance but still suffer from some inherent limitations, such as redundancy of relation prediction, poor generalization of span-based extraction and inefficiency. In this paper, we decompose this task into three subtasks, Relation Judgement, Entity Extraction and Subject-object Alignment from a novel perspective and then propose a joint relational triple extraction framework based on Potential Relation and Global Correspondence (PRGC). Specifically, we design a component to predict potential relations, which constrains the following entity extraction to the predicted relation subset rather than all relations; then a relation-specific sequence tagging component is applied to handle the overlapping problem between subjects and objects; finally, a global correspondence component is designed to align the subject and object into a triple with low-complexity. Extensive experiments show that PRGC achieves state-of-the-art performance on public benchmarks with higher efficiency and delivers consistent performance gain on complex scenarios of overlapping triples. The source code has been submitted as the supplementary material and will be made publicly available after the blind review.
Few-shot Named Entity Recognition (NER) exploits only a handful of annotations to iden- tify and classify named entity mentions. Pro- totypical network shows superior performance on few-shot NER. However, existing prototyp- ical methods fail to differentiate rich seman- tics in other-class words, which will aggravate overfitting under few shot scenario. To address the issue, we propose a novel model, Mining Undefined Classes from Other-class (MUCO), that can automatically induce different unde- fined classes from the other class to improve few-shot NER. With these extra-labeled unde- fined classes, our method will improve the dis- criminative ability of NER classifier and en- hance the understanding of predefined classes with stand-by semantic knowledge. Experi- mental results demonstrate that our model out- performs five state-of-the-art models in both 1- shot and 5-shots settings on four NER bench- marks. We will release the code upon accep- tance. The source code is released on https: //github.com/shuaiwa16/OtherClassNER.git.
Compared to the general news domain, information extraction (IE) from biomedical text requires much broader domain knowledge. However, many previous IE methods do not utilize any external knowledge during inference. Due to the exponential growth of biomedical publications, models that do not go beyond their fixed set of parameters will likely fall behind. Inspired by how humans look up relevant information to comprehend a scientific text, we present a novel framework that utilizes external knowledge for joint entity and relation extraction named KECI (Knowledge-Enhanced Collective Inference). Given an input text, KECI first constructs an initial span graph representing its initial understanding of the text. It then uses an entity linker to form a knowledge graph containing relevant background knowledge for the the entity mentions in the text. To make the final predictions, KECI fuses the initial span graph and the knowledge graph into a more refined graph using an attention mechanism. KECI takes a collective approach to link mention spans to entities by integrating global relational information into local representations using graph convolutional networks. Our experimental results show that the framework is highly effective, achieving new state-of-the-art results in two different benchmark datasets: BioRelEx (binding interaction detection) and ADE (adverse drug event extraction). For example, KECI achieves absolute improvements of 4.59% and 4.91% in F1 scores over the state-of-the-art on the BioRelEx entity and relation extraction tasks
Biomedical Information Extraction from scientific literature presents two unique and non-trivial challenges. First, compared with general natural language texts, sentences from scientific papers usually possess wider contexts between knowledge elements. Moreover, comprehending the fine-grained scientific entities and events urgently requires domain-specific background knowledge. In this paper, we propose a novel biomedical Information Extraction (IE) model to tackle these two challenges and extract scientific entities and events from English research papers. We perform Abstract Meaning Representation (AMR) to compress the wide context to uncover a clear semantic structure for each complex sentence. Besides, we construct the sentence-level knowledge graph from an external knowledge base and use it to enrich the AMR graph to improve the model’s understanding of complex scientific concepts. We use an edge-conditioned graph attention network to encode the knowledge-enriched AMR graph for biomedical IE tasks. Experiments on the GENIA 2011 dataset show that the AMR and external knowledge have contributed 1.8% and 3.0% absolute F-score gains respectively. In order to evaluate the impact of our approach on real-world problems that involve topic-specific fine-grained knowledge elements, we have also created a new ontology and annotated corpus for entity and event extraction for the COVID-19 scientific literature, which can serve as a new benchmark for the biomedical IE community.
Event Detection (ED) aims to recognize mentions of events (i.e., event triggers) and their types in text. Recently, several ED datasets in various domains have been proposed. However, the major limitation of these resources is the lack of enough training data for individual event types which hinders the efficient training of data-hungry deep learning models. To overcome this issue, we propose to exploit the powerful pre-trained language model GPT-2 to generate training samples for ED. To prevent the noises inevitable in automatically generated data from hampering training process, we propose to exploit a teacher-student architecture in which the teacher is supposed to learn anchor knowledge from the original data. The student is then trained on combination of the original and GPT-generated data while being led by the anchor knowledge from the teacher. Optimal transport is introduced to facilitate the anchor knowledge-based guidance between the two networks. We evaluate the proposed model on multiple ED benchmark datasets, gaining consistent improvement and establishing state-of-the-art results for ED.
Event extraction (EE) has considerably benefited from pre-trained language models (PLMs) by fine-tuning. However, existing pre-training methods have not involved modeling event characteristics, resulting in the developed EE models cannot take full advantage of large-scale unsupervised data. To this end, we propose CLEVE, a contrastive pre-training framework for EE to better learn event knowledge from large unsupervised data and their semantic structures (e.g. AMR) obtained with automatic parsers. CLEVE contains a text encoder to learn event semantics and a graph encoder to learn event structures respectively. Specifically, the text encoder learns event semantic representations by self-supervised contrastive learning to represent the words of the same events closer than those unrelated words; the graph encoder learns event structure representations by graph contrastive pre-training on parsed event-related semantic structures. The two complementary representations then work together to improve both the conventional supervised EE and the unsupervised “liberal” EE, which requires jointly extracting events and discovering event schemata without any annotated data. Experiments on ACE 2005 and MAVEN datasets show that CLEVE achieves significant improvements, especially in the challenging unsupervised setting. The source code and pre-trained checkpoints can be obtained from https://github.com/THU-KEG/CLEVE.
Document-level event extraction (DEE) is indispensable when events are described throughout a document. We argue that sentence-level extractors are ill-suited to the DEE task where event arguments always scatter across sentences and multiple events may co-exist in a document. It is a challenging task because it requires a holistic understanding of the document and an aggregated ability to assemble arguments across multiple sentences. In this paper, we propose an end-to-end model, which can extract structured events from a document in a parallel manner. Specifically, we first introduce a document-level encoder to obtain the document-aware representations. Then, a multi-granularity non-autoregressive decoder is used to generate events in parallel. Finally, to train the entire model, a matching loss function is proposed, which can bootstrap a global optimization. The empirical results on the widely used DEE dataset show that our approach significantly outperforms current state-of-the-art methods in the challenging DEE task. Code will be available at https://github.com/HangYang-NLP/DE-PPN.
Large pre-trained language models achieve state-of-the-art results when fine-tuned on downstream NLP tasks. However, they almost exclusively focus on text-only representation, while neglecting cell-level layout information that is important for form image understanding. In this paper, we propose a new pre-training approach, StructuralLM, to jointly leverage cell and layout information from scanned documents. Specifically, we pre-train StructuralLM with two new designs to make the most of the interactions of cell and layout information: 1) each cell as a semantic unit; 2) classification of cell positions. The pre-trained StructuralLM achieves new state-of-the-art results in different types of downstream tasks, including form understanding (from 78.95 to 85.14), document visual question answering (from 72.59 to 83.94) and document image classification (from 94.43 to 96.08).
Aspect-based sentiment analysis is a fine-grained sentiment classification task. Recently, graph neural networks over dependency trees have been explored to explicitly model connections between aspects and opinion words. However, the improvement is limited due to the inaccuracy of the dependency parsing results and the informal expressions and complexity of online reviews. To overcome these challenges, in this paper, we propose a dual graph convolutional networks (DualGCN) model that considers the complementarity of syntax structures and semantic correlations simultaneously. Particularly, to alleviate dependency parsing errors, we design a SynGCN module with rich syntactic knowledge. To capture semantic correlations, we design a SemGCN module with self-attention mechanism. Furthermore, we propose orthogonal and differential regularizers to capture semantic correlations between words precisely by constraining attention scores in the SemGCN module. The orthogonal regularizer encourages the SemGCN to learn semantically correlated words with less overlap for each word. The differential regularizer encourages the SemGCN to learn semantic features that the SynGCN fails to capture. Experimental results on three public datasets show that our DualGCN model outperforms state-of-the-art methods and verify the effectiveness of our model.
Aspect category detection (ACD) in sentiment analysis aims to identify the aspect categories mentioned in a sentence. In this paper, we formulate ACD in the few-shot learning scenario. However, existing few-shot learning approaches mainly focus on single-label predictions. These methods can not work well for the ACD task since a sentence may contain multiple aspect categories. Therefore, we propose a multi-label few-shot learning method based on the prototypical network. To alleviate the noise, we design two effective attention mechanisms. The support-set attention aims to extract better prototypes by removing irrelevant aspects. The query-set attention computes multiple prototype-specific representations for each query instance, which are then used to compute accurate distances with the corresponding prototypes. To achieve multi-label inference, we further learn a dynamic threshold per instance by a policy network. Extensive experimental results on three datasets demonstrate that the proposed method significantly outperforms strong baselines.
Argument pair extraction (APE) is a research task for extracting arguments from two passages and identifying potential argument pairs. Prior research work treats this task as a sequence labeling problem and a binary classification problem on two passages that are directly concatenated together, which has a limitation of not fully utilizing the unique characteristics and inherent relations of two different passages. This paper proposes a novel attention-guided multi-layer multi-cross encoding scheme to address the challenges. The new model processes two passages with two individual sequence encoders and updates their representations using each other’s representations through attention. In addition, the pair prediction part is formulated as a table-filling problem by updating the representations of two sequences’ Cartesian product. Furthermore, an auxiliary attention loss is introduced to guide each argument to align to its paired argument. An extensive set of experiments show that the new model significantly improves the APE performance over several alternatives.
The goal of argumentation mining is to automatically extract argumentation structures from argumentative texts. Most existing methods determine argumentative relations by exhaustively enumerating all possible pairs of argument components, which suffer from low efficiency and class imbalance. Moreover, due to the complex nature of argumentation, there is, so far, no universal method that can address both tree and non-tree structured argumentation. Towards these issues, we propose a neural transition-based model for argumentation mining, which incrementally builds an argumentation graph by generating a sequence of actions, avoiding inefficient enumeration operations. Furthermore, our model can handle both tree and non-tree structured argumentation without introducing any structural constraints. Experimental results show that our model achieves the best performance on two public datasets of different structures.
This work presents Keep it Simple (KiS), a new approach to unsupervised text simplification which learns to balance a reward across three properties: fluency, salience and simplicity. We train the model with a novel algorithm to optimize the reward (k-SCST), in which the model proposes several candidate simplifications, computes each candidate’s reward, and encourages candidates that outperform the mean reward. Finally, we propose a realistic text comprehension task as an evaluation method for text simplification. When tested on the English news domain, the KiS model outperforms strong supervised baselines by more than 4 SARI points, and can help people complete a comprehension task an average of 18% faster while retaining accuracy, when compared to the original text.
Generating long and coherent text is an important but challenging task, particularly for open-ended language generation tasks such as story generation. Despite the success in modeling intra-sentence coherence, existing generation models (e.g., BART) still struggle to maintain a coherent event sequence throughout the generated text. We conjecture that this is because of the difficulty for the decoder to capture the high-level semantics and discourse structures in the context beyond token-level co-occurrence. In this paper, we propose a long text generation model, which can represent the prefix sentences at sentence level and discourse level in the decoding process. To this end, we propose two pretraining objectives to learn the representations by predicting inter-sentence semantic similarity and distinguishing between normal and shuffled sentence orders. Extensive experiments show that our model can generate more coherent texts than state-of-the-art baselines.
Automatic metrics are essential for developing natural language generation (NLG) models, particularly for open-ended language generation tasks such as story generation. However, existing automatic metrics are observed to correlate poorly with human evaluation. The lack of standardized benchmark datasets makes it difficult to fully evaluate the capabilities of a metric and fairly compare different metrics. Therefore, we propose OpenMEVA, a benchmark for evaluating open-ended story generation metrics. OpenMEVA provides a comprehensive test suite to assess the capabilities of metrics, including (a) the correlation with human judgments, (b) the generalization to different model outputs and datasets, (c) the ability to judge story coherence, and (d) the robustness to perturbations. To this end, OpenMEVA includes both manually annotated stories and auto-constructed test examples. We evaluate existing metrics on OpenMEVA and observe that they have poor correlation with human judgments, fail to recognize discourse-level incoherence, and lack inferential knowledge (e.g., causal order between events), the generalization ability and robustness. Our study presents insights for developing NLG models and metrics in further research.
We study the task of long-form opinion text generation, which faces at least two distinct challenges. First, existing neural generation models fall short of coherence, thus requiring efficient content planning. Second, diverse types of information are needed to guide the generator to cover both subjective and objective content. To this end, we propose DYPLOC, a generation framework that conducts dynamic planning of content while generating the output based on a novel design of mixed language models. To enrich the generation with diverse content, we further propose to use large pre-trained models to predict relevant concepts and to generate claims. We experiment with two challenging tasks on newly collected datasets: (1) argument generation with Reddit ChangeMyView, and (2) writing articles using New York Times’ Opinion section. Automatic evaluation shows that our model significantly outperforms competitive comparisons. Human judges further confirm that our generations are more coherent with richer content.
We investigate the less-explored task of generating open-ended questions that are typically answered by multiple sentences. We first define a new question type ontology which differentiates the nuanced nature of questions better than widely used question words. A new dataset with 4,959 questions is labeled based on the new ontology. We then propose a novel question type-aware question generation framework, augmented by a semantic graph representation, to jointly predict question focuses and produce the question. Based on this framework, we further use both exemplars and automatically generated templates to improve controllability and diversity. Experiments on two newly collected large-scale datasets show that our model improves question quality over competitive comparisons based on automatic metrics. Human judges also rate our model outputs highly in answerability, coverage of scope, and overall quality. Finally, our model variants with templates can produce questions with enhanced controllability and diversity.
We present BERTGen, a novel, generative, decoder-only model which extends BERT by fusing multimodal and multilingual pre-trained models VL-BERT and M-BERT, respectively. BERTGen is auto-regressively trained for language generation tasks, namely image captioning, machine translation and multimodal machine translation, under a multi-task setting. With a comprehensive set of evaluations, we show that BERTGen outperforms many strong baselines across the tasks explored. We also show BERTGen’s ability for zero-shot language generation, where it exhibits competitive performance to supervised counterparts. Finally, we conduct ablation studies which demonstrate that BERTGen substantially benefits from multi-tasking and effectively transfers relevant inductive biases from the pre-trained models.
Neural Machine Translation (NMT) models achieve state-of-the-art performance on many translation benchmarks. As an active research field in NMT, knowledge distillation is widely applied to enhance the model’s performance by transferring teacher model’s knowledge on each training sample. However, previous work rarely discusses the different impacts and connections among these samples, which serve as the medium for transferring teacher knowledge. In this paper, we design a novel protocol that can effectively analyze the different impacts of samples by comparing various samples’ partitions. Based on above protocol, we conduct extensive experiments and find that the teacher’s knowledge is not the more, the better. Knowledge over specific samples may even hurt the whole performance of knowledge distillation. Finally, to address these issues, we propose two simple yet effective strategies, i.e., batch-level and global-level selections, to pick suitable samples for distillation. We evaluate our approaches on two large-scale machine translation tasks, WMT’14 English-German and WMT’19 Chinese-English. Experimental results show that our approaches yield up to +1.28 and +0.89 BLEU points improvements over the Transformer baseline, respectively.
Recent work in neural machine translation has demonstrated both the necessity and feasibility of using inter-sentential context, context from sentences other than those currently being translated. However, while many current methods present model architectures that theoretically can use this extra context, it is often not clear how much they do actually utilize it at translation time. In this paper, we introduce a new metric, conditional cross-mutual information, to quantify usage of context by these models. Using this metric, we measure how much document-level machine translation systems use particular varieties of context. We find that target context is referenced more than source context, and that including more context has a diminishing affect on results. We then introduce a new, simple training method, context-aware word dropout, to increase the usage of context by context-aware models. Experiments show that our method not only increases context usage, but also improves the translation quality according to metrics such as BLEU and COMET, as well as performance on anaphoric pronoun resolution and lexical cohesion contrastive datasets.
Recent research on cross-lingual word embeddings has been dominated by unsupervised mapping approaches that align monolingual embeddings. Such methods critically rely on those embeddings having a similar structure, but it was recently shown that the separate training in different languages causes departures from this assumption. In this paper, we propose an alternative approach that does not have this limitation, while requiring a weak seed dictionary (e.g., a list of identical words) as the only form of supervision. Rather than aligning two fixed embedding spaces, our method works by fixing the target language embeddings, and learning a new set of embeddings for the source language that are aligned with them. To that end, we use an extension of skip-gram that leverages translated context words as anchor points, and incorporates self-learning and iterative restarts to reduce the dependency on the initial dictionary. Our approach outperforms conventional mapping methods on bilingual lexicon induction, and obtains competitive results in the downstream XNLI task.
We show that margin-based bitext mining in a multilingual sentence space can be successfully scaled to operate on monolingual corpora of billions of sentences. We use 32 snapshots of a curated common crawl corpus (Wenzel et al, 2019) totaling 71 billion unique sentences. Using one unified approach for 90 languages, we were able to mine 10.8 billion parallel sentences, out of which only 2.9 billions are aligned with English. We illustrate the capability of our scalable mining system to create high quality training sets from one language to any other by training hundreds of different machine translation models and evaluating them on the many-to-many TED benchmark. Further, we evaluate on competitive translation benchmarks such as WMT and WAT. Using only mined bitext, we set a new state of the art for a single system on the WMT’19 test set for English-German/Russian/Chinese. In particular, our English/German and English/Russian systems outperform the best single ones by over 4 BLEU points and are on par with best WMT’19 systems, which train on the WMT training data and augment it with backtranslation. We also achieve excellent results for distant languages pairs like Russian/Japanese, outperforming the best submission at the 2020 WAT workshop. All of the mined bitext will be freely available.
Despite transformers’ impressive accuracy, their computational cost is often prohibitive to use with limited computational resources. Most previous approaches to improve inference efficiency require a separate model for each possible computational budget. In this paper, we extend PoWER-BERT (Goyal et al., 2020) and propose Length-Adaptive Transformer that can be used for various inference scenarios after one-shot training. We train a transformer with LengthDrop, a structural variant of dropout, which stochastically determines a sequence length at each layer. We then conduct a multi-objective evolutionary search to find a length configuration that maximizes the accuracy and minimizes the efficiency metric under any given computational budget. Additionally, we significantly extend the applicability of PoWER-BERT beyond sequence-level classification into token-level classification with Drop-and-Restore process that drops word-vectors temporarily in intermediate layers and restores at the last layer if necessary. We empirically verify the utility of the proposed approach by demonstrating the superior accuracy-efficiency trade-off under various setups, including span-based question answering and text classification. Code is available at https://github.com/clovaai/lengthadaptive-transformer.
Transformer-based pre-trained language models like BERT, though powerful in many tasks, are expensive in both memory and computation, due to their large number of parameters. Previous works show that some parameters in these models can be pruned away without severe accuracy drop. However, these redundant features contribute to a comprehensive understanding of the training data and removing them weakens the model’s representation ability. In this paper, we propose GhostBERT, which generates more features with very cheap operations from the remaining features. In this way, GhostBERT has similar memory and computational cost as the pruned model, but enjoys much larger representation power. The proposed ghost module can also be applied to unpruned BERT models to enhance their performance with negligible additional parameters and computation. Empirical results on the GLUE benchmark on three backbone models (i.e., BERT, RoBERTa and ELECTRA) verify the efficacy of our proposed method.
The Lottery Ticket Hypothesis suggests that an over-parametrized network consists of ”lottery tickets”, and training a certain collection of them (i.e., a subnetwork) can match the performance of the full model. In this paper, we study such a collection of tickets, which is referred to as ”winning tickets”, in extremely over-parametrized models, e.g., pre-trained language models. We observe that at certain compression ratios, the generalization performance of the winning tickets can not only match but also exceed that of the full model. In particular, we observe a phase transition phenomenon: As the compression ratio increases, generalization performance of the winning tickets first improves then deteriorates after a certain threshold. We refer to the tickets on the threshold as ”super tickets”. We further show that the phase transition is task and model dependent — as the model size becomes larger and the training data set becomes smaller, the transition becomes more pronounced. Our experiments on the GLUE benchmark show that the super tickets improve single task fine-tuning by 0.9 points on BERT-base and 1.0 points on BERT-large, in terms of task-average score. We also demonstrate that adaptively sharing the super tickets across tasks benefits multi-task learning.
Learning disentangled representations of textual data is essential for many natural language tasks such as fair classification, style transfer and sentence generation, among others. The existent dominant approaches in the context of text data either rely on training an adversary (discriminator) that aims at making attribute values difficult to be inferred from the latent code or rely on minimising variational bounds of the mutual information between latent code and the value attribute. However, the available methods suffer of the impossibility to provide a fine-grained control of the degree (or force) of disentanglement. In contrast to adversarial methods, which are remarkably simple, although the adversary seems to be performing perfectly well during the training phase, after it is completed a fair amount of information about the undesired attribute still remains. This paper introduces a novel variational upper bound to the mutual information between an attribute and the latent code of an encoder. Our bound aims at controlling the approximation error via the Renyi’s divergence, leading to both better disentangled representations and in particular, a precise control of the desirable degree of disentanglement than state-of-the-art methods proposed for textual data. Furthermore, it does not suffer from the degeneracy of other losses in multi-class scenarios. We show the superiority of this method on fair classification and on textual style transfer tasks. Additionally, we provide new insights illustrating various trade-offs in style transfer when attempting to learn disentangled representations and quality of the generated sentence.
Beam search is a go-to strategy for decoding neural sequence models. The algorithm can naturally be viewed as a subset optimization problem, albeit one where the corresponding set function does not reflect interactions between candidates. Empirically, this leads to sets often exhibiting high overlap, e.g., strings may differ by only a single word. Yet in use-cases that call for multiple solutions, a diverse or representative set is often desired. To address this issue, we propose a reformulation of beam search, which we call determinantal beam search. Determinantal beam search has a natural relationship to determinantal point processes (DPPs), models over sets that inherently encode intra-set interactions. By posing iterations in beam search as a series of subdeterminant maximization problems, we can turn the algorithm into a diverse subset selection process. In a case study, we use the string subsequence kernel to explicitly encourage n-gram coverage in text generated from a sequence model. We observe that our algorithm offers competitive performance against other diverse set generation strategies in the context of language generation, while providing a more general approach to optimizing for diversity.
Graph convolutional network (GCN) has become popular in various natural language processing (NLP) tasks with its superiority in long-term and non-consecutive word interactions. However, existing single-hop graph reasoning in GCN may miss some important non-consecutive dependencies. In this study, we define the spectral graph convolutional network with the high-order dynamic Chebyshev approximation (HDGCN), which augments the multi-hop graph reasoning by fusing messages aggregated from direct and long-term dependencies into one convolutional layer. To alleviate the over-smoothing in high-order Chebyshev approximation, a multi-vote-based cross-attention (MVCAttn) with linear computation complexity is also proposed. The empirical results on four transductive and inductive NLP tasks and the ablation study verify the efficacy of the proposed model.
Typing every character in a text message may require more time or effort than strictly necessary. Skipping spaces or other characters may be able to speed input and reduce a user’s physical input effort. This can be particularly important for people with motor impairments. In a large crowdsourced study, we found workers frequently abbreviated text by omitting mid-word vowels. We designed a recognizer optimized for expanding noisy abbreviated input where users often omit spaces and mid-word vowels. We show using neural language models for selecting conversational-style training text and for rescoring the recognizer’s n-best sentences improved accuracy. On noisy touchscreen data collected from hundreds of users, we found accurate abbreviated input was possible even if a third of characters was omitted. Finally, in a study where users had to dwell for a second on each key, sentence abbreviated input was competitive with a conventional keyboard with word predictions. After practice, users wrote abbreviated sentences at 9.6 words-per-minute versus word input at 9.9 words-per-minute.
Behavior of deep neural networks can be inconsistent between different versions. Regressions during model update are a common cause of concern that often over-weigh the benefits in accuracy or efficiency gain. This work focuses on quantifying, reducing and analyzing regression errors in the NLP model updates. Using negative flip rate as regression measure, we show that regression has a prevalent presence across tasks in the GLUE benchmark. We formulate the regression-free model updates into a constrained optimization problem, and further reduce it into a relaxed form which can be approximately optimized through knowledge distillation training method. We empirically analyze how model ensemble reduces regression. Finally, we conduct CheckList behavioral testing to understand the distribution of regressions across linguistic phenomena, and the efficacy of ensemble and distillation methods.
Propaganda can be defined as a form of communication that aims to influence the opinions or the actions of people towards a specific goal; this is achieved by means of well-defined rhetorical and psychological devices. Propaganda, in the form we know it today, can be dated back to the beginning of the 17th century. However, it is with the advent of the Internet and the social media that propaganda has started to spread on a much larger scale than before, thus becoming major societal and political issue. Nowadays, a large fraction of propaganda in social media is multimodal, mixing textual with visual content. With this in mind, here we propose a new multi-label multimodal task: detecting the type of propaganda techniques used in memes. We further create and release a new corpus of 950 memes, carefully annotated with 22 propaganda techniques, which can appear in the text, in the image, or in both. Our analysis of the corpus shows that understanding both modalities together is essential for detecting these techniques. This is further confirmed in our experiments with several state-of-the-art multimodal models.
In adversarial data collection (ADC), a human workforce interacts with a model in real time, attempting to produce examples that elicit incorrect predictions. Researchers hope that models trained on these more challenging datasets will rely less on superficial patterns, and thus be less brittle. However, despite ADC’s intuitive appeal, it remains unclear when training on adversarial datasets produces more robust models. In this paper, we conduct a large-scale controlled study focused on question answering, assigning workers at random to compose questions either (i) adversarially (with a model in the loop); or (ii) in the standard fashion (without a model). Across a variety of models and datasets, we find that models trained on adversarial data usually perform better on other adversarial datasets but worse on a diverse collection of out-of-domain evaluation sets. Finally, we provide a qualitative analysis of adversarial (vs standard) data, identifying key differences and offering guidance for future research.
Open-domain question answering can be reformulated as a phrase retrieval problem, without the need for processing documents on-demand during inference (Seo et al., 2019). However, current phrase retrieval models heavily depend on sparse representations and still underperform retriever-reader approaches. In this work, we show for the first time that we can learn dense representations of phrases alone that achieve much stronger performance in open-domain QA. We present an effective method to learn phrase representations from the supervision of reading comprehension tasks, coupled with novel negative sampling methods. We also propose a query-side fine-tuning strategy, which can support transfer learning and reduce the discrepancy between training and inference. On five popular open-domain QA datasets, our model DensePhrases improves over previous phrase retrieval models by 15%-25% absolute accuracy and matches the performance of state-of-the-art retriever-reader models. Our model is easy to parallelize due to pure dense representations and processes more than 10 questions per second on CPUs. Finally, we directly use our pre-indexed dense phrase representations for two slot filling tasks, showing the promise of utilizing DensePhrases as a dense knowledge base for downstream tasks.
Recent work on training neural retrievers for open-domain question answering (OpenQA) has employed both supervised and unsupervised approaches. However, it remains unclear how unsupervised and supervised methods can be used most effectively for neural retrievers. In this work, we systematically study retriever pre-training. We first propose an approach of unsupervised pre-training with the Inverse Cloze Task and masked salient spans, followed by supervised finetuning using question-context pairs. This approach leads to absolute gains of 2+ points over the previous best result in the top-20 retrieval accuracy on Natural Questions and TriviaQA datasets. We next explore two approaches for end-to-end training of the reader and retriever components in OpenQA models, which differ in the manner the reader ingests the retrieved documents. Our experiments demonstrate the effectiveness of these approaches as we obtain state-of-the-art results. On the Natural Questions dataset, we obtain a top-20 retrieval accuracy of 84%, an improvement of 5 points over the recent DPR model. We also achieve good results on answer extraction, outperforming recent models like REALM and RAG by 3+ points.
Temporal Knowledge Graphs (Temporal KGs) extend regular Knowledge Graphs by providing temporal scopes (start and end times) on each edge in the KG. While Question Answering over KG (KGQA) has received some attention from the research community, QA over Temporal KGs (Temporal KGQA) is a relatively unexplored area. Lack of broad coverage datasets has been another factor limiting progress in this area. We address this challenge by presenting CRONQUESTIONS, the largest known Temporal KGQA dataset, clearly stratified into buckets of structural complexity. CRONQUESTIONS expands the only known previous dataset by a factor of 340x. We find that various state-of-the-art KGQA methods fall far short of the desired performance on this new dataset. In response, we also propose CRONKGQA, a transformer-based solution that exploits recent advances in Temporal KG embeddings, and achieves performance superior to all baselines, with an increase of 120% in accuracy over the next best performing method. Through extensive experiments, we give detailed insights into the workings of CRONKGQA, as well as situations where significant further improvements appear possible. In addition to the dataset, we have released our code as well.
Although automated metrics are commonly used to evaluate NLG systems, they often correlate poorly with human judgements. Newer metrics such as BERTScore have addressed many weaknesses in prior metrics such as BLEU and ROUGE, which rely on n-gram matching. These newer methods, however, are still limited in that they do not consider the generation context, so they cannot properly reward generated text that is correct but deviates from the given reference. In this paper, we propose Language Model Augmented Relevance Score (MARS), a new context-aware metric for NLG evaluation. MARS leverages off-the-shelf language models, guided by reinforcement learning, to create augmented references that consider both the generation context and available human references, which are then used as additional references to score generated text. Compared with seven existing metrics in three common NLG tasks, MARS not only achieves higher correlation with human reference judgements, but also differentiates well-formed candidates from adversarial samples to a larger degree.
Despite recent advances in natural language generation, it remains challenging to control attributes of generated text. We propose DExperts: Decoding-time Experts, a decoding-time method for controlled text generation that combines a pretrained language model with “expert” LMs and/or “anti-expert” LMs in a product of experts. Intuitively, under the ensemble, tokens only get high probability if they are considered likely by the experts, and unlikely by the anti-experts. We apply DExperts to language detoxification and sentiment-controlled generation, where we outperform existing controllable generation methods on both automatic and human evaluations. Moreover, because DExperts operates only on the output of the pretrained LM, it is effective with (anti-)experts of smaller size, including when operating on GPT-3. Our work highlights the promise of tuning small LMs on text with (un)desirable attributes for efficient decoding-time steering.
While counterfactual examples are useful for analysis and training of NLP models, current generation methods either rely on manual labor to create very few counterfactuals, or only instantiate limited types of perturbations such as paraphrases or word substitutions. We present Polyjuice, a general-purpose counterfactual generator that allows for control over perturbation types and locations, trained by finetuning GPT-2 on multiple datasets of paired sentences. We show that Polyjuice produces diverse sets of realistic counterfactuals, which in turn are useful in various distinct applications: improving training and evaluation on three different tasks (with around 70% less annotation effort than manual generation), augmenting state-of-the-art explanation techniques, and supporting systematic counterfactual error analysis by revealing behaviors easily missed by human experts.
Generating metaphors is a difficult task as it requires understanding nuanced relationships between abstract concepts. In this paper, we aim to generate a metaphoric sentence given a literal expression by replacing relevant verbs. Guided by conceptual metaphor theory, we propose to control the generation process by encoding conceptual mappings between cognitive domains to generate meaningful metaphoric expressions. To achieve this, we develop two methods: 1) using FrameNet-based embeddings to learn mappings between domains and applying them at the lexical level (CM-Lex), and 2) deriving source/target pairs to train a controlled seq-to-seq generation model (CM-BART). We assess our methods through automatic and human evaluation for basic metaphoricity and conceptual metaphor presence. We show that the unsupervised CM-Lex model is competitive with recent deep learning metaphor generation systems, and CM-BART outperforms all other models both in automatic and human evaluations.
Wet laboratory protocols (WLPs) are critical for conveying reproducible procedures in biological research. They are composed of instructions written in natural language describing the step-wise processing of materials by specific actions. This process flow description for reagents and materials synthesis in WLPs can be captured by material state transfer graphs (MSTGs), which encode global temporal and causal relationships between actions. Here, we propose methods to automatically generate a MSTG for a given protocol by extracting all action relationships across multiple sentences. We also note that previous corpora and methods focused primarily on local intra-sentence relationships between actions and entities and did not address two critical issues: (i) resolution of implicit arguments and (ii) establishing long-range dependencies across sentences. We propose a new model that incrementally learns latent structures and is better suited to resolving inter-sentence relations and implicit arguments. This model draws upon a new corpus WLP-MSTG which was created by extending annotations in the WLP corpora for inter-sentence relations and implicit arguments. Our model achieves an F1 score of 54.53% for temporal and causal relations in protocols from our corpus, which is a significant improvement over previous models - DyGIE++:28.17%; spERT:27.81%. We make our annotated WLP-MSTG corpus available to the research community.
Risk prediction is an essential task in financial markets. Merger and Acquisition (M&A) calls provide key insights into the claims made by company executives about the restructuring of the financial firms. Extracting vocal and textual cues from M&A calls can help model the risk associated with such financial activities. To aid the analysis of M&A calls, we curate a dataset of conference call transcripts and their corresponding audio recordings for the time period ranging from 2016 to 2020. We introduce M3ANet, a baseline architecture that takes advantage of the multimodal multi-speaker input to forecast the financial risk associated with the M&A calls. Empirical results prove that the task is challenging, with the pro-posed architecture performing marginally better than strong BERT-based baselines. We release the M3A dataset and benchmark models to motivate future research on this challenging problem domain.
To translate large volumes of text in a globally connected world, more and more translators are integrating machine translation (MT) and post-editing (PE) into their translation workflows to generate publishable quality translations. While this process has been shown to save time and reduce errors, the task of translation is changing from mostly text production from scratch to fixing errors within useful but partly incorrect MT output. This is affecting the interface design of translation tools, where better support for text editing tasks is required. Here, we present the first study that investigates the usefulness of mid-air hand gestures in combination with the keyboard (GK) for text editing in PE of MT. Guided by a gesture elicitation study with 14 freelance translators, we develop a prototype supporting mid-air hand gestures for cursor placement, text selection, deletion, and reordering. These gestures combined with the keyboard facilitate all editing types required for PE. An evaluation of the prototype shows that the average editing duration of GK is only slightly slower than the standard mouse and keyboard (MK), even though participants are very familiar with the latter, and relative novices to the former. Furthermore, the qualitative analysis shows positive attitudes towards hand gestures for PE, especially when manipulating single words.
Geometry problem solving has attracted much attention in the NLP community recently. The task is challenging as it requires abstract problem understanding and symbolic reasoning with axiomatic knowledge. However, current datasets are either small in scale or not publicly available. Thus, we construct a new large-scale benchmark, Geometry3K, consisting of 3,002 geometry problems with dense annotation in formal language. We further propose a novel geometry solving approach with formal language and symbolic reasoning, called Interpretable Geometry Problem Solver (Inter-GPS). Inter-GPS first parses the problem text and diagram into formal language automatically via rule-based text parsing and neural object detecting, respectively. Unlike implicit learning in existing methods, Inter-GPS incorporates theorem knowledge as conditional rules and performs symbolic reasoning step by step. Also, a theorem predictor is designed to infer the theorem application sequence fed to the symbolic solver for the more efficient and reasonable searching path. Extensive experiments on the Geometry3K and GEOS datasets demonstrate that Inter-GPS achieves significant improvements over existing methods. The project with code and data is available at https://lupantech.github.io/inter-gps.
Structured information is an important knowledge source for automatic verification of factual claims. Nevertheless, the majority of existing research into this task has focused on textual data, and the few recent inquiries into structured data have been for the closed-domain setting where appropriate evidence for each claim is assumed to have already been retrieved. In this paper, we investigate verification over structured data in the open-domain setting, introducing a joint reranking-and-verification model which fuses evidence documents in the verification component. Our open-domain model achieves performance comparable to the closed-domain state-of-the-art on the TabFact dataset, and demonstrates performance gains from the inclusion of multiple tables as well as a significant improvement over a heuristic retrieval baseline.
Collecting together microblogs representing opinions about the same topics within the same timeframe is useful to a number of different tasks and practitioners. A major question is how to evaluate the quality of such thematic clusters. Here we create a corpus of microblog clusters from three different domains and time windows and define the task of evaluating thematic coherence. We provide annotation guidelines and human annotations of thematic coherence by journalist experts. We subsequently investigate the efficacy of different automated evaluation metrics for the task. We consider a range of metrics including surface level metrics, ones for topic model coherence and text generation metrics (TGMs). While surface level metrics perform well, outperforming topic coherence metrics, they are not as consistent as TGMs. TGMs are more reliable than all other metrics considered for capturing thematic coherence in microblog clusters due to being less sensitive to the effect of time windows.
Monolingual word alignment is important for studying fine-grained editing operations (i.e., deletion, addition, and substitution) in text-to-text generation tasks, such as paraphrase generation, text simplification, neutralizing biased language, etc. In this paper, we present a novel neural semi-Markov CRF alignment model, which unifies word and phrase alignments through variable-length spans. We also create a new benchmark with human annotations that cover four different text genres to evaluate monolingual word alignment models in more realistic settings. Experimental results show that our proposed model outperforms all previous approaches for monolingual word alignment as well as a competitive QA-based baseline, which was previously only applied to bilingual data. Our model demonstrates good generalizability to three out-of-domain datasets and shows great utility in two downstream applications: automatic text simplification and sentence pair classification tasks.
Organisations disclose their privacy practices by posting privacy policies on their websites. Even though internet users often care about their digital privacy, they usually do not read privacy policies, since understanding them requires a significant investment of time and effort. Natural language processing has been used to create experimental tools to interpret privacy policies, but there has been a lack of large privacy policy corpora to facilitate the creation of large-scale semi-supervised and unsupervised models to interpret and simplify privacy policies. Thus, we present the PrivaSeer Corpus of 1,005,380 English language website privacy policies collected from the web. The number of unique websites represented in PrivaSeer is about ten times larger than the next largest public collection of web privacy policies, and it surpasses the aggregate of unique websites represented in all other publicly available privacy policy corpora combined. We describe a corpus creation pipeline with stages that include a web crawler, language detection, document classification, duplicate and near-duplicate removal, and content extraction. We employ an unsupervised topic modelling approach to investigate the contents of policy documents in the corpus and discuss the distribution of topics in privacy policies at web scale. We further investigate the relationship between privacy policy domain PageRanks and text features of the privacy policies. Finally, we use the corpus to pretrain PrivBERT, a transformer-based privacy policy language model, and obtain state of the art results on the data practice classification and question answering tasks.
Estimating the expected output quality of generation systems is central to NLG. This paper qualifies the notion that automatic metrics are not as good as humans in estimating system-level quality. Statistically, humans are unbiased, high variance estimators, while metrics are biased, low variance estimators. We compare these estimators by their error in pairwise prediction (which generation system is better?) using the bootstrap. Measuring this error is complicated: predictions are evaluated against noisy, human predicted labels instead of the ground truth, and metric predictions fluctuate based on the test sets they were calculated on. By applying a bias-variance-noise decomposition, we adjust this error to a noise-free, infinite test set setting. Our analysis compares the adjusted error of metrics to humans and a derived, perfect segment-level annotator, both of which are unbiased estimators dependent on the number of judgments collected. In MT, we identify two settings where metrics outperform humans due to a statistical advantage in variance: when the number of human judgments used is small, and when the quality difference between compared systems is small.
We present InferWiki, a Knowledge Graph Completion (KGC) dataset that improves upon existing benchmarks in inferential ability, assumptions, and patterns. First, each testing sample is predictable with supportive data in the training set. To ensure it, we propose to utilize rule-guided train/test generation, instead of conventional random split. Second, InferWiki initiates the evaluation following the open-world assumption and improves the inferential difficulty of the closed-world assumption, by providing manually annotated negative and unknown triples. Third, we include various inference patterns (e.g., reasoning path length and types) for comprehensive evaluation. In experiments, we curate two settings of InferWiki varying in sizes and structures, and apply the construction process on CoDEx as comparative datasets. The results and empirical analyses demonstrate the necessity and high-quality of InferWiki. Nevertheless, the performance gap among various inferential assumptions and patterns presents the difficulty and inspires future research direction. Our datasets can be found in https://github.com/TaoMiner/inferwiki.
While online conversations can cover a vast amount of information in many different formats, abstractive text summarization has primarily focused on modeling solely news articles. This research gap is due, in part, to the lack of standardized datasets for summarizing online discussions. To address this gap, we design annotation protocols motivated by an issues–viewpoints–assertions framework to crowdsource four new datasets on diverse online conversation forms of news comments, discussion forums, community question answering forums, and email threads. We benchmark state-of-the-art models on our datasets and analyze characteristics associated with the data. To create a comprehensive benchmark, we also evaluate these models on widely-used conversation summarization datasets to establish strong baselines in this domain. Furthermore, we incorporate argument mining through graph construction to directly model the issues, viewpoints, and assertions present in a conversation and filter noisy input, showing comparable or improved results according to automatic and human evaluations.
A commonly observed problem with the state-of-the art abstractive summarization models is that the generated summaries can be factually inconsistent with the input documents. The fact that automatic summarization may produce plausible-sounding yet inaccurate summaries is a major concern that limits its wide application. In this paper we present an approach to address factual consistency in summarization. We first propose an efficient automatic evaluation metric to measure factual consistency; next, we propose a novel learning algorithm that maximizes the proposed metric during model training. Through extensive experiments, we confirm that our method is effective in improving factual consistency and even overall quality of the summaries, as judged by both automatic metrics and human evaluation.
Recent years have brought about an interest in the challenging task of summarizing conversation threads (meetings, online discussions, etc.). Such summaries help analysis of the long text to quickly catch up with the decisions made and thus improve our work or communication efficiency. To spur research in thread summarization, we have developed an abstractive Email Thread Summarization (EmailSum) dataset, which contains human-annotated short (<30 words) and long (<100 words) summaries of 2,549 email threads (each containing 3 to 10 emails) over a wide variety of topics. We perform a comprehensive empirical study to explore different summarization techniques (including extractive and abstractive methods, single-document and hierarchical models, as well as transfer and semisupervised learning) and conduct human evaluations on both short and long summary generation tasks. Our results reveal the key challenges of current abstractive summarization models in this task, such as understanding the sender’s intent and identifying the roles of sender and receiver. Furthermore, we find that widely used automatic evaluation metrics (ROUGE, BERTScore) are weakly correlated with human judgments on this email thread summarization task. Hence, we emphasize the importance of human evaluation and the development of better metrics by the community.
Parallel cross-lingual summarization data is scarce, requiring models to better use the limited available cross-lingual resources. Existing methods to do so often adopt sequence-to-sequence networks with multi-task frameworks. Such approaches apply multiple decoders, each of which is utilized for a specific task. However, these independent decoders share no parameters, hence fail to capture the relationships between the discrete phrases of summaries in different languages, breaking the connections in order to transfer the knowledge of the high-resource languages to low-resource languages. To bridge these connections, we propose a novel Multi-Task framework for Cross-Lingual Abstractive Summarization (MCLAS) in a low-resource setting. Employing one unified decoder to generate the sequential concatenation of monolingual and cross-lingual summaries, MCLAS makes the monolingual summarization task a prerequisite of the CLS task. In this way, the shared decoder learns interactions involving alignments and summary patterns across languages, which encourages attaining knowledge transfer. Experiments on two CLS datasets demonstrate that our model significantly outperforms three baseline models in both low-resource and full-dataset scenarios. Moreover, in-depth analysis on the generated summaries and attention heads verifies that interactions are learned well using MCLAS, which benefits the CLS task under limited parallel resources.
Despite the prominence of neural abstractive summarization models, we know little about how they actually form summaries and how to understand where their decisions come from. We propose a two-step method to interpret summarization model decisions. We first analyze the model’s behavior by ablating the full model to categorize each decoder decision into one of several generation modes: roughly, is the model behaving like a language model, is it relying heavily on the input, or is it somewhere in between? After isolating decisions that do depend on the input, we explore interpreting these decisions using several different attribution methods. We compare these techniques based on their ability to select content and reconstruct the model’s predicted token from perturbations of the input, thus revealing whether highlighted attributions are truly important for the generation of the next token. While this machinery can be broadly useful even beyond summarization, we specifically demonstrate its capability to identify phrases the summarization model has memorized and determine where in the training pipeline this memorization happened, as well as study complex generation phenomena like sentence fusion on a per-instance basis.
Humans create things for a reason. Ancient people created spears for hunting, knives for cutting meat, pots for preparing food, etc. The prototypical function of a physical artifact is a kind of commonsense knowledge that we rely on to understand natural language. For example, if someone says “She borrowed the book” then you would assume that she intends to read the book, or if someone asks “Can I use your knife?” then you would assume that they need to cut something. In this paper, we introduce a new NLP task of learning the prototypical uses for human-made physical objects. We use frames from FrameNet to represent a set of common functions for objects, and describe a manually annotated data set of physical objects labeled with their prototypical function. We also present experimental results for this task, including BERT-based models that use predictions from masked patterns as well as artifact sense definitions from WordNet and frame definitions from FrameNet.
Linguistic probing of pretrained Transformer-based language models (LMs) revealed that they encode a range of syntactic and semantic properties of a language. However, they are still prone to fall back on superficial cues and simple heuristics to solve downstream tasks, rather than leverage deeper linguistic information. In this paper, we target a specific facet of linguistic knowledge, the interplay between verb meaning and argument structure. We investigate whether injecting explicit information on verbs’ semantic-syntactic behaviour improves the performance of pretrained LMs in event extraction tasks, where accurate verb processing is paramount. Concretely, we impart the verb knowledge from curated lexical resources into dedicated adapter modules (verb adapters), allowing it to complement, in downstream tasks, the language knowledge obtained during LM-pretraining. We first demonstrate that injecting verb knowledge leads to performance gains in English event extraction. We then explore the utility of verb adapters for event extraction in other languages: we investigate 1) zero-shot language transfer with multilingual Transformers and 2) transfer via (noisy automatic) translation of English verb-based lexical knowledge. Our results show that the benefits of verb knowledge injection indeed extend to other languages, even when relying on noisily translated lexical knowledge.
Static word embeddings that represent words by a single vector cannot capture the variability of word meaning in different linguistic and extralinguistic contexts. Building on prior work on contextualized and dynamic word embeddings, we introduce dynamic contextualized word embeddings that represent words as a function of both linguistic and extralinguistic context. Based on a pretrained language model (PLM), dynamic contextualized word embeddings model time and social space jointly, which makes them attractive for a range of NLP tasks involving semantic variability. We highlight potential application scenarios by means of qualitative and quantitative analyses on four English datasets.
While there is a large amount of research in the field of Lexical Semantic Change Detection, only few approaches go beyond a standard benchmark evaluation of existing models. In this paper, we propose a shift of focus from change detection to change discovery, i.e., discovering novel word senses over time from the full corpus vocabulary. By heavily fine-tuning a type-based and a token-based approach on recently published German data, we demonstrate that both models can successfully be applied to discover new words undergoing meaning change. Furthermore, we provide an almost fully automated framework for both evaluation and discovery.
Humans are increasingly interacting with machines through language, sometimes in contexts where the user may not know they are talking to a machine (like over the phone or a text chatbot). We aim to understand how system designers and researchers might allow their systems to confirm its non-human identity. We collect over 2,500 phrasings related to the intent of “Are you a robot?”. This is paired with over 2,500 adversarially selected utterances where only confirming the system is non-human would be insufficient or disfluent. We compare classifiers to recognize the intent and discuss the precision/recall and model complexity tradeoffs. Such classifiers could be integrated into dialog systems to avoid undesired deception. We then explore how both a generative research model (Blender) as well as two deployed systems (Amazon Alexa, Google Assistant) handle this intent, finding that systems often fail to confirm their non-human identity. Finally, we try to understand what a good response to the intent would be, and conduct a user study to compare the important aspects when responding to this intent.
In this paper we explore the improvement of intent recognition in conversational systems by the use of meta-knowledge embedded in intent identifiers. Developers often include such knowledge, structure as taxonomies, in the documentation of chatbots. By using neuro-symbolic algorithms to incorporate those taxonomies into embeddings of the output space, we were able to improve accuracy in intent recognition. In datasets with intents and example utterances from 200 professional chatbots, we saw decreases in the equal error rate (EER) in more than 40% of the chatbots in comparison to the baseline of the same algorithm without the meta-knowledge. The meta-knowledge proved also to be effective in detecting out-of-scope utterances, improving the false acceptance rate (FAR) in two thirds of the chatbots, with decreases of 0.05 or more in FAR in almost 40% of the chatbots. When considering only the well-developed workspaces with a high level use of taxonomies, FAR decreased more than 0.05 in 77% of them, and more than 0.1 in 39% of the chatbots.
To improve the coherence and knowledge retrieval capabilities of non-task-oriented dialogue systems, recent Transformer-based models aim to integrate fixed background context. This often comes in the form of knowledge graphs, and the integration is done by creating pseudo utterances through paraphrasing knowledge triples, added into the accumulated dialogue context. However, the context length is fixed in these architectures, which restricts how much background or dialogue context can be kept. In this work, we propose a more concise encoding for background context structured in the form of knowledge graphs, by expressing the graph connections through restrictions on the attention weights. The results of our human evaluation show that this encoding reduces space requirements without negative effects on the precision of reproduction of knowledge and perceived consistency. Further, models trained with our proposed context encoding generate dialogues that are judged to be more comprehensive and interesting.
Emotion Recognition in Conversations (ERC) has gained increasing attention for developing empathetic machines. Recently, many approaches have been devoted to perceiving conversational context by deep learning models. However, these approaches are insufficient in understanding the context due to lacking the ability to extract and integrate emotional clues. In this work, we propose novel Contextual Reasoning Networks (DialogueCRN) to fully understand the conversational context from a cognitive perspective. Inspired by the Cognitive Theory of Emotion, we design multi-turn reasoning modules to extract and integrate emotional clues. The reasoning module iteratively performs an intuitive retrieving process and a conscious reasoning process, which imitates human unique cognitive thinking. Extensive experiments on three public benchmark datasets demonstrate the effectiveness and superiority of the proposed model.
When collecting annotations and labeled data from humans, a standard practice is to use inter-rater reliability (IRR) as a measure of data goodness (Hallgren, 2012). Metrics such as Krippendorff’s alpha or Cohen’s kappa are typically required to be above a threshold of 0.6 (Landis and Koch, 1977). These absolute thresholds are unreasonable for crowdsourced data from annotators with high cultural and training variances, especially on subjective topics. We present a new alternative to interpreting IRR that is more empirical and contextualized. It is based upon benchmarking IRR against baseline measures in a replication, one of which is a novel cross-replication reliability (xRR) measure based on Cohen’s (1960) kappa. We call this approach the xRR framework. We opensource a replication dataset of 4 million human judgements of facial expressions and analyze it with the proposed framework. We argue this framework can be used to measure the quality of crowdsourced datasets.
Everyday conversations require understanding everyday events, which in turn, requires understanding temporal commonsense concepts interwoven with those events. Despite recent progress with massive pre-trained language models (LMs) such as T5 and GPT-3, their capability of temporal reasoning in dialogs remains largely under-explored. In this paper, we present the first study to investigate pre-trained LMs for their temporal reasoning capabilities in dialogs by introducing a new task and a crowd-sourced English challenge set, TimeDial. We formulate TimeDial as a multiple choice cloze task with over 1.1K carefully curated dialogs. Empirical results demonstrate that even the best performing models struggle on this task compared to humans, with 23 absolute points of gap in accuracy. Furthermore, our analysis reveals that the models fail to reason about dialog context correctly; instead, they rely on shallow cues based on existing temporal patterns in context, motivating future research for modeling temporal concepts in text and robust contextual reasoning about them. The dataset is publicly available at https://github.com/google-research-datasets/timedial.
Most words are ambiguous—-i.e., they convey distinct meanings in different contexts—-and even the meanings of unambiguous words are context-dependent. Both phenomena present a challenge for NLP. Recently, the advent of contextualized word embeddings has led to success on tasks involving lexical ambiguity, such as Word Sense Disambiguation. However, there are few tasks that directly evaluate how well these contextualized embeddings accommodate the more continuous, dynamic nature of word meaning—-particularly in a way that matches human intuitions. We introduce RAW-C, a dataset of graded, human relatedness judgments for 112 ambiguous words in context (with 672 sentence pairs total), as well as human estimates of sense dominance. The average inter-annotator agreement (assessed using a leave-one-annotator-out method) was 0.79. We then show that a measure of cosine distance, computed using contextualized embeddings from BERT and ELMo, correlates with human judgments, but that cosine distance also systematically underestimates how similar humans find uses of the same sense of a word to be, and systematically overestimates how similar humans find uses of different-sense homonyms. Finally, we propose a synthesis between psycholinguistic theories of the mental lexicon and computational models of lexical semantics.
Pre-trained language models (LMs) are currently integral to many natural language processing systems. Although multilingual LMs were also introduced to serve many languages, these have limitations such as being costly at inference time and the size and diversity of non-English data involved in their pre-training. We remedy these issues for a collection of diverse Arabic varieties by introducing two powerful deep bidirectional transformer-based models, ARBERT and MARBERT. To evaluate our models, we also introduce ARLUE, a new benchmark for multi-dialectal Arabic language understanding evaluation. ARLUE is built using 42 datasets targeting six different task clusters, allowing us to offer a series of standardized experiments under rich conditions. When fine-tuned on ARLUE, our models collectively achieve new state-of-the-art results across the majority of tasks (37 out of 48 classification tasks, on the 42 datasets). Our best model acquires the highest ARLUE score (77.40) across all six task clusters, outperforming all other models including XLM-R Large ( 3.4x larger size). Our models are publicly available at https://github.com/UBC-NLP/marbert and ARLUE will be released through the same repository.
If two sentences have the same meaning, it should follow that they are equivalent in their inferential properties, i.e., each sentence should textually entail the other. However, many paraphrase datasets currently in widespread use rely on a sense of paraphrase based on word overlap and syntax. Can we teach them instead to identify paraphrases in a way that draws on the inferential properties of the sentences, and is not over-reliant on lexical and syntactic similarities of a sentence pair? We apply the adversarial paradigm to this question, and introduce a new adversarial method of dataset creation for paraphrase identification: the Adversarial Paraphrasing Task (APT), which asks participants to generate semantically equivalent (in the sense of mutually implicative) but lexically and syntactically disparate paraphrases. These sentence pairs can then be used both to test paraphrase identification models (which get barely random accuracy) and then improve their performance. To accelerate dataset generation, we explore automation of APT using T5, and show that the resulting dataset also improves accuracy. We discuss implications for paraphrase detection and release our dataset in the hope of making paraphrase detection models better able to detect sentence-level meaning equivalence.
A false contract is more likely to be rejected than a contract is, yet a false key is less likely than a key to open doors. While correctly interpreting and assessing the effects of such adjective-noun pairs (e.g., false key) on the plausibility of given events (e.g., opening doors) underpins many natural language understanding tasks, doing so often requires a significant degree of world knowledge and common-sense reasoning. We introduce ADEPT – a large-scale semantic plausibility task consisting of over 16 thousand sentences that are paired with slightly modified versions obtained by adding an adjective to a noun. Overall, we find that while the task appears easier for human judges (85% accuracy), it proves more difficult for transformer-based models like RoBERTa (71% accuracy). Our experiments also show that neither the adjective itself nor its taxonomic class suffice in determining the correct plausibility judgement, emphasizing the importance of endowing automatic natural language understanding systems with more context sensitivity and common-sense reasoning.
We present ReadOnce Transformers, an approach to convert a transformer-based model into one that can build an information-capturing, task-independent, and compressed representation of text. The resulting representation is reusable across different examples and tasks, thereby requiring a document shared across many examples or tasks to only be read once. This leads to faster training and evaluation of models. Additionally, we extend standard text-to-text transformer models to Representation+Text-to-text models, and evaluate on multiple downstream tasks: multi-hop QA, abstractive QA, and long-document summarization. Our one-time computed representation results in a 2x-5x speedup compared to standard text-to-text models, while the compression also allows existing language models to handle longer documents without the need for designing new pre-trained models.
Models of narrative schema knowledge have proven useful for a range of event-related tasks, but they typically do not capture the temporal relationships between events. We propose a single model that addresses both temporal ordering, sorting given events into the order they occurred, and event infilling, predicting new events which fit into an existing temporally-ordered sequence. We use a BART-based conditional generation model that can capture both temporality and common event co-occurrence, meaning it can be flexibly applied to different tasks in this space. Our model is trained as a denoising autoencoder: we take temporally-ordered event sequences, shuffle them, delete some events, and then attempt to recover the original event sequence. This task teaches the model to make inferences given incomplete knowledge about the events in an underlying scenario. On the temporal ordering task, we show that our model is able to unscramble event sequences from existing datasets without access to explicitly labeled temporal training data, outperforming both a BERT-based pairwise model and a BERT-based pointer network. On event infilling, human evaluation shows that our model is able to generate events that fit better temporally into the input events when compared to GPT-2 story completion models.
The wanton spread of hate speech on the internet brings great harm to society and families. It is urgent to establish and improve automatic detection and active avoidance mechanisms for hate speech. While there exist methods for hate speech detection, they stereotype words and hence suffer from inherently biased training. In other words, getting more affective features from other affective resources will significantly affect the performance of hate speech detection. In this paper, we propose a hate speech detection framework based on sentiment knowledge sharing. While extracting the affective features of the target sentence itself, we make better use of the sentiment features from external resources, and finally fuse features from different feature extraction units to detect hate speech. Experimental results on two public datasets demonstrate the effectiveness of our model.
We propose a transition-based bubble parser to perform coordination structure identification and dependency-based syntactic analysis simultaneously. Bubble representations were proposed in the formal linguistics literature decades ago; they enhance dependency trees by encoding coordination boundaries and internal relationships within coordination structures explicitly. In this paper, we introduce a transition system and neural models for parsing these bubble-enhanced structures. Experimental results on the English Penn Treebank and the English GENIA corpus show that our parsers beat previous state-of-the-art approaches on the task of coordination structure prediction, especially for the subset of sentences with complex coordination structures.
Recent years have seen the paradigm shift of Named Entity Recognition (NER) systems from sequence labeling to span prediction. Despite its preliminary effectiveness, the span prediction model’s architectural bias has not been fully understood. In this paper, we first investigate the strengths and weaknesses when the span prediction model is used for named entity recognition compared with the sequence labeling framework and how to further improve it, which motivates us to make complementary advantages of systems based on different paradigms. We then reveal that span prediction, simultaneously, can serve as a system combiner to re-recognize named entities from different systems’ outputs. We experimentally implement 154 systems on 11 datasets, covering three languages, comprehensive results show the effectiveness of span prediction models that both serve as base NER systems and system combiners. We make all codes and datasets available: https://github.com/neulab/spanner, as well as an online system demo: http://spanner.sh. Our model also has been deployed into the ExplainaBoard platform, which allows users to flexibly perform a system combination of top-scoring systems in an interactive way: http://explainaboard.nlpedia.ai/leaderboard/task-ner/.
There are two major classes of natural language grammars — the dependency grammar that models one-to-one correspondences between words and the constituency grammar that models the assembly of one or several corresponded words. While previous unsupervised parsing methods mostly focus on only inducing one class of grammars, we introduce a novel model, StructFormer, that can induce dependency and constituency structure at the same time. To achieve this, we propose a new parsing framework that can jointly generate a constituency tree and dependency graph. Then we integrate the induced dependency relations into the transformer, in a differentiable manner, through a novel dependency-constrained self-attention mechanism. Experimental results show that our model can achieve strong results on unsupervised constituency parsing, unsupervised dependency parsing, and masked language modeling at the same time.
Cross-lingual language tasks typically require a substantial amount of annotated data or parallel translation data. We explore whether language representations that capture relationships among languages can be learned and subsequently leveraged in cross-lingual tasks without the use of parallel data. We generate dense embeddings for 29 languages using a denoising autoencoder, and evaluate the embeddings using the World Atlas of Language Structures (WALS) and two extrinsic tasks in a zero-shot setting: cross-lingual dependency parsing and cross-lingual natural language inference.
Decipherment of historical ciphers is a challenging problem. The language of the target plaintext might be unknown, and ciphertext can have a lot of noise. State-of-the-art decipherment methods use beam search and a neural language model to score candidate plaintext hypotheses for a given cipher, assuming the plaintext language is known. We propose an end-to-end multilingual model for solving simple substitution ciphers. We test our model on synthetic and real historical ciphers and show that our proposed method can decipher text without explicit language identification while still being robust to noise.
While it has been shown that Neural Machine Translation (NMT) is highly sensitive to noisy parallel training samples, prior work treats all types of mismatches between source and target as noise. As a result, it remains unclear how samples that are mostly equivalent but contain a small number of semantically divergent tokens impact NMT training. To close this gap, we analyze the impact of different types of fine-grained semantic divergences on Transformer models. We show that models trained on synthetic divergences output degenerated text more frequently and are less confident in their predictions. Based on these findings, we introduce a divergent-aware NMT framework that uses factors to help NMT recover from the degradation caused by naturally occurring divergences, improving both translation quality and model calibration on EN-FR tasks.
Reranking models enable the integration of rich features to select a better output hypothesis within an n-best list or lattice. These models have a long history in NLP, and we revisit discriminative reranking for modern neural machine translation models by training a large transformer architecture. This takes as input both the source sentence as well as a list of hypotheses to output a ranked list. The reranker is trained to predict the observed distribution of a desired metric, e.g. BLEU, over the n-best list. Since such a discriminator contains hundreds of millions of parameters, we improve its generalization using pre-training and data augmentation techniques. Experiments on four WMT directions show that our discriminative reranking approach is effective and complementary to existing generative reranking approaches, yielding improvements of up to 4 BLEU over the beam search output.
Active learning promises to alleviate the massive data needs of supervised machine learning: it has successfully improved sample efficiency by an order of magnitude on traditional tasks like topic classification and object recognition. However, we uncover a striking contrast to this promise: across 5 models and 4 datasets on the task of visual question answering, a wide variety of active learning approaches fail to outperform random selection. To understand this discrepancy, we profile 8 active learning methods on a per-example basis, and identify the problem as collective outliers – groups of examples that active learning methods prefer to acquire but models fail to learn (e.g., questions that ask about text in images or require external knowledge). Through systematic ablation experiments and qualitative visualizations, we verify that collective outliers are a general phenomenon responsible for degrading pool-based active learning. Notably, we show that active learning sample efficiency increases significantly as the number of collective outliers in the active learning pool decreases. We conclude with a discussion and prescriptive recommendations for mitigating the effects of these outliers in future work.
Human evaluations are typically considered the gold standard in natural language generation, but as models’ fluency improves, how well can evaluators detect and judge machine-generated text? We run a study assessing non-experts’ ability to distinguish between human- and machine-authored text (GPT2 and GPT3) in three domains (stories, news articles, and recipes). We find that, without training, evaluators distinguished between GPT3- and human-authored text at random chance level. We explore three approaches for quickly training evaluators to better identify GPT3-authored text (detailed instructions, annotated examples, and paired examples) and find that while evaluators’ accuracy improved up to 55%, it did not significantly improve across the three domains. Given the inconsistent results across text domains and the often contradictory reasons evaluators gave for their judgments, we examine the role untrained human evaluations play in NLG evaluation and provide recommendations to NLG researchers for improving human evaluations of text generated from state-of-the-art models.
This paper presents the first large-scale meta-evaluation of machine translation (MT). We annotated MT evaluations conducted in 769 research papers published from 2010 to 2020. Our study shows that practices for automatic MT evaluation have dramatically changed during the past decade and follow concerning trends. An increasing number of MT evaluations exclusively rely on differences between BLEU scores to draw conclusions, without performing any kind of statistical significance testing nor human evaluation, while at least 108 metrics claiming to be better than BLEU have been proposed. MT evaluations in recent papers tend to copy and compare automatic metric scores from previous work to claim the superiority of a method or an algorithm without confirming neither exactly the same training, validating, and testing data have been used nor the metric scores are comparable. Furthermore, tools for reporting standardized metric scores are still far from being widely adopted by the MT community. After showing how the accumulation of these pitfalls leads to dubious evaluation, we propose a guideline to encourage better automatic MT evaluation along with a simple meta-evaluation scoring method to assess its credibility.
Prior work has proved that Translation Memory (TM) can boost the performance of Neural Machine Translation (NMT). In contrast to existing work that uses bilingual corpus as TM and employs source-side similarity search for memory retrieval, we propose a new framework that uses monolingual memory and performs learnable memory retrieval in a cross-lingual manner. Our framework has unique advantages. First, the cross-lingual memory retriever allows abundant monolingual data to be TM. Second, the memory retriever and NMT model can be jointly optimized for the ultimate translation goal. Experiments show that the proposed method obtains substantial improvements. Remarkably, it even outperforms strong TM-augmented NMT baselines using bilingual TM. Owning to the ability to leverage monolingual data, our model also demonstrates effectiveness in low-resource and domain adaptation scenarios.
Although pretrained language models can be fine-tuned to produce state-of-the-art results for a very wide range of language understanding tasks, the dynamics of this process are not well understood, especially in the low data regime. Why can we use relatively vanilla gradient descent algorithms (e.g., without strong regularization) to tune a model with hundreds of millions of parameters on datasets with only hundreds or thousands of labeled examples? In this paper, we argue that analyzing fine-tuning through the lens of intrinsic dimension provides us with empirical and theoretical intuitions to explain this remarkable phenomenon. We empirically show that common pre-trained models have a very low intrinsic dimension; in other words, there exists a low dimension reparameterization that is as effective for fine-tuning as the full parameter space. For example, by optimizing only 200 trainable parameters randomly projected back into the full space, we can tune a RoBERTa model to achieve 90% of the full parameter performance levels on MRPC. Furthermore, we empirically show that pre-training implicitly minimizes intrinsic dimension and, perhaps surprisingly, larger models tend to have lower intrinsic dimension after a fixed number of pre-training updates, at least in part explaining their extreme effectiveness. Lastly, we connect intrinsic dimensionality with low dimensional task representations and compression based generalization bounds to provide intrinsic-dimension-based generalization bounds that are independent of the full parameter count.
Recent investigations into the inner-workings of state-of-the-art large-scale pre-trained Transformer-based Natural Language Understanding (NLU) models indicate that they appear to understand human-like syntax, at least to some extent. We provide novel evidence that complicates this claim: we find that state-of-the-art Natural Language Inference (NLI) models assign the same labels to permuted examples as they do to the original, i.e. they are invariant to random word-order permutations. This behavior notably differs from that of humans; we struggle to understand the meaning of ungrammatical sentences. To measure the severity of this issue, we propose a suite of metrics and investigate which properties of particular permutations lead models to be word order invariant. For example, in MNLI dataset we find almost all (98.7%) examples contain at least one permutation which elicits the gold label. Models are even able to assign gold labels to permutations that they originally failed to predict correctly. We provide a comprehensive empirical evaluation of this phenomenon, and further show that this issue exists in pre-Transformer RNN / ConvNet based encoders, as well as across multiple languages (English and Chinese). Our code and data are available at https://github.com/facebookresearch/unlu.
Signed languages are the primary means of communication for many deaf and hard of hearing individuals. Since signed languages exhibit all the fundamental linguistic properties of natural language, we believe that tools and theories of Natural Language Processing (NLP) are crucial towards its modeling. However, existing research in Sign Language Processing (SLP) seldom attempt to explore and leverage the linguistic organization of signed languages. This position paper calls on the NLP community to include signed languages as a research area with high social and scientific impact. We first discuss the linguistic properties of signed languages to consider during their modeling. Then, we review the limitations of current SLP models and identify the open challenges to extend NLP to signed languages. Finally, we urge (1) the adoption of an efficient tokenization method; (2) the development of linguistically-informed models; (3) the collection of real-world signed language data; (4) the inclusion of local signed language communities as an active and leading voice in the direction of research.
The choice of token vocabulary affects the performance of machine translation. This paper aims to figure out what is a good vocabulary and whether we can find the optimal vocabulary without trial training. To answer these questions, we first provide an alternative understanding of vocabulary from the perspective of information theory. It motivates us to formulate the quest of vocabularization – finding the best token dictionary with a proper size – as an optimal transport (OT) problem. We propose VOLT, a simple and efficient solution without trial training. Empirical results show that VOLT beats widely-used vocabularies in diverse scenarios, including WMT-14 English-German translation, TED bilingual translation, and TED multilingual translation. For example, VOLT achieves 70% vocabulary size reduction and 0.5 BLEU gain on English-German translation. Also, compared to BPE-search, VOLT reduces the search time from 384 GPU hours to 30 GPU hours on English-German translation. Codes are available at https://github.com/Jingjing-NLP/VOLT.
A snowclone is a customizable phrasal template that can be realized in multiple, instantly recognized variants. For example, “* is the new *" (Orange is the new black, 40 is the new 30). Snowclones are extensively used in social media. In this paper, we study snowclones originating from pop-culture quotes; our goal is to automatically detect cultural references in text. We introduce a new, publicly available data set of pop-culture quotes and their corresponding snowclone usages and train models on them. We publish code for Catchphrase, an internet browser plugin to automatically detect and mark references in real-time, and examine its performance via a user study. Aside from assisting people to better comprehend cultural references, we hope that detecting snowclones can complement work on paraphrasing and help tackling long-standing questions in social science about the dynamics of information propagation.
Large-scale pretrained language models have led to dramatic improvements in text generation. Impressive performance can be achieved by finetuning only on a small number of instances (few-shot setting). Nonetheless, almost all previous work simply applies random sampling to select the few-shot training instances. Little to no attention has been paid to the selection strategies and how they would affect model performance. In this work, we present a study on training instance selection in few-shot neural text generation. The selection decision is made based only on the unlabeled data so as to identify the most worthwhile data points that should be annotated under some budget of labeling cost. Based on the intuition that the few-shot training instances should be diverse and representative of the entire data distribution, we propose a simple selection strategy with K-means clustering. We show that even with the naive clustering-based approach, the generation models consistently outperform random sampling on three text generation tasks: data-to-text generation, document summarization and question generation. The code and training data are made available. We hope that this work will call for more attention on this largely unexplored area.
The introduction of pretrained language models has reduced many complex task-specific NLP models to simple lightweight layers. An exception to this trend is coreference resolution, where a sophisticated task-specific model is appended to a pretrained transformer encoder. While highly effective, the model has a very large memory footprint – primarily due to dynamically-constructed span and span-pair representations – which hinders the processing of complete documents and the ability to train on multiple instances in a single batch. We introduce a lightweight end-to-end coreference model that removes the dependency on span representations, handcrafted features, and heuristics. Our model performs competitively with the current standard model, while being simpler and more efficient.
In comparison with English, due to the lack of explicit word boundary and tenses information, Chinese Named Entity Recognition (NER) is much more challenging. In this paper, we propose a boundary enhanced approach for better Chinese NER. In particular, our approach enhances the boundary information from two perspectives. On one hand, we enhance the representation of the internal dependency of phrases by an additional Graph Attention Network(GAT) layer. On the other hand, taking the entity head-tail prediction (i.e., boundaries) as an auxiliary task, we propose an unified framework to learn the boundary information and recognize the NE jointly. Experiments on both the OntoNotes and the Weibo corpora show the effectiveness of our approach.
The high-quality translation results produced by machine translation (MT) systems still pose a huge challenge for automatic evaluation. Current MT evaluation pays the same attention to each sentence component, while the questions of real-world examinations (e.g., university examinations) have different difficulties and weightings. In this paper, we propose a novel difficulty-aware MT evaluation metric, expanding the evaluation dimension by taking translation difficulty into consideration. A translation that fails to be predicted by most MT systems will be treated as a difficult one and assigned a large weight in the final score function, and conversely. Experimental results on the WMT19 English-German Metrics shared tasks show that our proposed method outperforms commonly used MT metrics in terms of human correlation. In particular, our proposed method performs well even when all the MT systems are very competitive, which is when most existing metrics fail to distinguish between them. The source code is freely available at https://github.com/NLP2CT/Difficulty-Aware-MT-Evaluation.
Humor recognition has been widely studied as a text classification problem using data-driven approaches. However, most existing work does not examine the actual joke mechanism to understand humor. We break down any joke into two distinct components: the set-up and the punchline, and further explore the special relationship between them. Inspired by the incongruity theory of humor, we model the set-up as the part developing semantic uncertainty, and the punchline disrupting audience expectations. With increasingly powerful language models, we were able to feed the set-up along with the punchline into the GPT-2 language model, and calculate the uncertainty and surprisal values of the jokes. By conducting experiments on the SemEval 2021 Task 7 dataset, we found that these two features have better capabilities of telling jokes from non-jokes, compared with existing baselines.
Disentanglement of latent representations into content and style spaces has been a commonly employed method for unsupervised text style transfer. These techniques aim to learn the disentangled representations and tweak them to modify the style of a sentence. In this paper, we propose a counterfactual-based method to modify the latent representation, by posing a ‘what-if’ scenario. This simple and disciplined approach also enables a fine-grained control on the transfer strength. We conduct experiments with the proposed methodology on multiple attribute transfer tasks like Sentiment, Formality and Excitement to support our hypothesis.
Shapley Values, a solution to the credit assignment problem in cooperative game theory, are a popular type of explanation in machine learning, having been used to explain the importance of features, embeddings, and even neurons. In NLP, however, leave-one-out and attention-based explanations still predominate. Can we draw a connection between these different methods? We formally prove that — save for the degenerate case — attention weights and leave-one-out values cannot be Shapley Values. Attention flow is a post-processed variant of attention weights obtained by running the max-flow algorithm on the attention graph. Perhaps surprisingly, we prove that attention flows are indeed Shapley Values, at least at the layerwise level. Given the many desirable theoretical qualities of Shapley Values — which has driven their adoption among the ML community — we argue that NLP practitioners should, when possible, adopt attention flow explanations alongside more traditional ones.
Video paragraph captioning aims to generate a set of coherent sentences to describe a video that contains several events. Most previous methods simplify this task by using ground-truth event segments. In this work, we propose a novel framework by taking this task as a text summarization task. We first generate lots of sentence-level captions focusing on different video clips and then summarize these captions to obtain the final paragraph caption. Our method does not depend on ground-truth event segments. Experiments on two popular datasets ActivityNet Captions and YouCookII demonstrate the advantages of our new framework. On the ActivityNet dataset, our method even outperforms some previous methods using ground-truth event segment labels.
Deep learning algorithms have shown promising results in visual question answering (VQA) tasks, but a more careful look reveals that they often do not understand the rich signal they are being fed with. To understand and better measure the generalization capabilities of VQA systems, we look at their robustness to counterfactually augmented data. Our proposed augmentations are designed to make a focused intervention on a specific property of the question such that the answer changes. Using these augmentations, we propose a new robustness measure, Robustness to Augmented Data (RAD), which measures the consistency of model predictions between original and augmented examples. Through extensive experimentation, we show that RAD, unlike classical accuracy measures, can quantify when state-of-the-art systems are not robust to counterfactuals. We find substantial failure cases which reveal that current VQA systems are still brittle. Finally, we connect between robustness and generalization, demonstrating the predictive power of RAD for performance on unseen augmentations.
Existing approaches for the Table-to-Text task suffer from issues such as missing information, hallucination and repetition. Many approaches to this problem use Reinforcement Learning (RL), which maximizes a single manually defined reward, such as BLEU. In this work, we instead pose the Table-to-Text task as Inverse Reinforcement Learning (IRL) problem. We explore using multiple interpretable unsupervised reward components that are combined linearly to form a composite reward function. The composite reward function and the description generator are learned jointly. We find that IRL outperforms strong RL baselines marginally. We further study the generalization of learned IRL rewards in scenarios involving domain adaptation. Our experiments reveal significant challenges in using IRL for this task.
Most fact checking models for automatic fake news detection are based on reasoning: given a claim with associated evidence, the models aim to estimate the claim veracity based on the supporting or refuting content within the evidence. When these models perform well, it is generally assumed to be due to the models having learned to reason over the evidence with regards to the claim. In this paper, we investigate this assumption of reasoning, by exploring the relationship and importance of both claim and evidence. Surprisingly, we find on political fact checking datasets that most often the highest effectiveness is obtained by utilizing only the evidence, as the impact of including the claim is either negligible or harmful to the effectiveness. This highlights an important problem in what constitutes evidence in existing approaches for automatic fake news detection.
Despite end-to-end neural systems making significant progress in the last decade for task-oriented as well as chit-chat based dialogue systems, most dialogue systems rely on hybrid approaches which use a combination of rule-based, retrieval and generative approaches for generating a set of ranked responses. Such dialogue systems need to rely on a fallback mechanism to respond to out-of-domain or novel user queries which are not answerable within the scope of the dialogue system. While, dialogue systems today rely on static and unnatural responses like “I don’t know the answer to that question” or “I’m not sure about that”, we design a neural approach which generates responses which are contextually aware with the user query as well as say no to the user. Such customized responses provide paraphrasing ability and contextualization as well as improve the interaction with the user and reduce dialogue monotonicity. Our simple approach makes use of rules over dependency parses and a text-to-text transformer fine-tuned on synthetic data of question-response pairs generating highly relevant, grammatical as well as diverse questions. We perform automatic and manual evaluations to demonstrate the efficacy of the system.
Spoken Language Understanding (SLU) systems parse speech into semantic structures like dialog acts and slots. This involves the use of an Automatic Speech Recognizer (ASR) to transcribe speech into multiple text alternatives (hypotheses). Transcription errors, ordinary in ASRs, impact downstream SLU performance negatively. Common approaches to mitigate such errors involve using richer information from the ASR, either in form of N-best hypotheses or word-lattices. We hypothesize that transformer models will learn better with a simpler utterance representation using the concatenation of the N-best ASR alternatives, where each alternative is separated by a special delimiter [SEP]. In our work, we test our hypothesis by using the concatenated N-best ASR alternatives as the input to the transformer encoder models, namely BERT and XLM-RoBERTa, and achieve equivalent performance to the prior state-of-the-art model on DSTC2 dataset. We also show that our approach significantly outperforms the prior state-of-the-art when subjected to the low data regime. Additionally, this methodology is accessible to users of third-party ASR APIs which do not provide word-lattice information.
Is bias amplified when neural machine translation (NMT) models are optimized for speed and evaluated on generic test sets using BLEU? We investigate architectures and techniques commonly used to speed up decoding in Transformer-based models, such as greedy search, quantization, average attention networks (AANs) and shallow decoder models and show their effect on gendered noun translation. We construct a new gender bias test set, SimpleGEN, based on gendered noun phrases in which there is a single, unambiguous, correct answer. While we find minimal overall BLEU degradation as we apply speed optimizations, we observe that gendered noun translation performance degrades at a much faster rate.
State-of-the-art machine translation (MT) systems are typically trained to generate “standard” target language; however, many languages have multiple varieties (regional varieties, dialects, sociolects, non-native varieties) that are different from the standard language. Such varieties are often low-resource, and hence do not benefit from contemporary NLP solutions, MT included. We propose a general framework to rapidly adapt MT systems to generate language varieties that are close to, but different from, the standard target language, using no parallel (source–variety) data. This also includes adaptation of MT systems to low-resource typologically-related target languages. We experiment with adapting an English–Russian MT system to generate Ukrainian and Belarusian, an English–Norwegian Bokmål system to generate Nynorsk, and an English–Arabic system to generate four Arabic dialects, obtaining significant improvements over competitive baselines.
Sparse attention has been claimed to increase model interpretability under the assumption that it highlights influential inputs. Yet the attention distribution is typically over representations internal to the model rather than the inputs themselves, suggesting this assumption may not have merit. We build on the recent work exploring the interpretability of attention; we design a set of experiments to help us understand how sparsity affects our ability to use attention as an explainability tool. On three text classification tasks, we verify that only a weak relationship between inputs and co-indexed intermediate representations exists—under sparse attention and otherwise. Further, we do not find any plausible mappings from sparse attention distributions to a sparse set of influential inputs through other avenues. Rather, we observe in this setting that inducing sparsity may make it less plausible that attention can be used as a tool for understanding model behavior.
Mechanisms for encoding positional information are central for transformer-based language models. In this paper, we analyze the position embeddings of existing language models, finding strong evidence of translation invariance, both for the embeddings themselves and for their effect on self-attention. The degree of translation invariance increases during training and correlates positively with model performance. Our findings lead us to propose translation-invariant self-attention (TISA), which accounts for the relative position between tokens in an interpretable fashion without needing conventional position embeddings. Our proposal has several theoretical advantages over existing position-representation approaches. Proof-of-concept experiments show that it improves on regular ALBERT on GLUE tasks, while only adding orders of magnitude less positional parameters.
Determining the relative importance of the elements in a sentence is a key factor for effortless natural language understanding. For human language processing, we can approximate patterns of relative importance by measuring reading fixations using eye-tracking technology. In neural language models, gradient-based saliency methods indicate the relative importance of a token for the target objective. In this work, we compare patterns of relative importance in English language processing by humans and models and analyze the underlying linguistic patterns. We find that human processing patterns in English correlate strongly with saliency-based importance in language models and not with attention-based importance. Our results indicate that saliency could be a cognitively more plausible metric for interpreting neural language models. The code is available on github: https://github.com/beinborn/relative_importance.
Pretrained language models (PLM) achieve surprising performance on the Choice of Plausible Alternatives (COPA) task. However, whether PLMs have truly acquired the ability of causal reasoning remains a question. In this paper, we investigate the problem of semantic similarity bias and reveal the vulnerability of current COPA models by certain attacks. Previous solutions that tackle the superficial cues of unbalanced token distribution still encounter the same problem of semantic bias, even more seriously due to the utilization of more training data. We mitigate this problem by simply adding a regularization loss and experimental results show that this solution not only improves the model’s generalization ability, but also assists the models to perform more robustly on a challenging dataset, BCOPA-CE, which has unbiased token distribution and is more difficult for models to distinguish cause and effect.
A current open question in natural language processing is to what extent language models, which are trained with access only to the form of language, are able to capture the meaning of language. This question is challenging to answer in general, as there is no clear line between meaning and form, but rather meaning constrains form in consistent ways. The goal of this study is to offer insights into a narrower but critical subquestion: Under what conditions should we expect that meaning and form covary sufficiently, such that a language model with access only to form might nonetheless succeed in emulating meaning? Focusing on several formal languages (propositional logic and a set of programming languages), we generate training corpora using a variety of motivated constraints, and measure a distributional language model’s ability to differentiate logical symbols (AND, OR, and NOT). Our findings are largely negative: none of our simulated training corpora result in models which definitively differentiate meaningfully different symbols (e.g., AND vs. OR), suggesting a limitation to the types of semantic signals that current models are able to exploit.
The predominant challenge in weakly supervised semantic parsing is that of spurious programs that evaluate to correct answers for the wrong reasons. Prior work uses elaborate search strategies to mitigate the prevalence of spurious programs; however, they typically consider only one input at a time. In this work we explore the use of consistency between the output programs for related inputs to reduce the impact of spurious programs. We bias the program search (and thus the model’s training signal) towards programs that map the same phrase in related inputs to the same sub-parts in their respective programs. Additionally, we study the importance of designing logical formalisms that facilitate this kind of consistency-based training. We find that a more consistent formalism leads to improved model performance even without consistency-based training. When combined together, these two insights lead to a 10% absolute improvement over the best prior result on the Natural Language Visual Reasoning dataset.
In this paper, we present an improved model for voicing silent speech, where audio is synthesized from facial electromyography (EMG) signals. To give our model greater flexibility to learn its own input features, we directly use EMG signals as input in the place of hand-designed features used by prior work. Our model uses convolutional layers to extract features from the signals and Transformer layers to propagate information across longer distances. To provide better signal for learning, we also introduce an auxiliary task of predicting phoneme labels in addition to predicting speech audio features. On an open vocabulary intelligibility evaluation, our model improves the state of the art for this task by an absolute 25.8%.
Whereas much of the success of the current generation of neural language models has been driven by increasingly large training corpora, relatively little research has been dedicated to analyzing these massive sources of textual data. In this exploratory analysis, we delve deeper into the Common Crawl, a colossal web corpus that is extensively used for training language models. We find that it contains a significant amount of undesirable content, including hate speech and sexually explicit content, even after filtering procedures. We discuss the potential impacts of this content on language models and conclude with future research directions and a more mindful approach to corpus collection and analysis.
Most current quality estimation (QE) models for machine translation are trained and evaluated in a static setting where training and test data are assumed to be from a fixed distribution. However, in real-life settings, the test data that a deployed QE model would be exposed to may differ from its training data. In particular, training samples are often labelled by one or a small set of annotators, whose perceptions of translation quality and needs may differ substantially from those of end-users, who will employ predictions in practice. To address this challenge, we propose an online Bayesian meta-learning framework for the continuous training of QE models that is able to adapt them to the needs of different users, while being robust to distributional shifts in training and test data. Experiments on data with varying number of users and language characteristics validate the effectiveness of the proposed approach.
Sequential sentence classification aims to classify each sentence in the document based on the context in which sentences appear. Most existing work addresses this problem using a hierarchical sequence labeling network. However, they ignore considering the latent segment structure of the document, in which contiguous sentences often have coherent semantics. In this paper, we proposed a span-based dynamic local attention model that could explicitly capture the structural information by the proposed supervised dynamic local attention. We further introduce an auxiliary task called span-based classification to explore the span-level representations. Extensive experiments show that our model achieves better or competitive performance against state-of-the-art baselines on two benchmark datasets.
Ordered word sequences contain the rich structures that define language. However, it’s often not clear if or how modern pretrained language models utilize these structures. We show that the token representations and self-attention activations within BERT are surprisingly resilient to shuffling the order of input tokens, and that for several GLUE language understanding tasks, shuffling only minimally degrades performance, e.g., by 4% for QNLI. While bleak from the perspective of language understanding, our results have positive implications for cases where copyright or ethics necessitates the consideration of bag-of-words data (vs. full documents). We simulate such a scenario for three sensitive classification tasks, demonstrating minimal performance degradation vs. releasing full language sequences.
Recent works made significant advances on summarization tasks, facilitated by summarization datasets. Several existing datasets have the form of coherent-paragraph summaries. However, these datasets were curated from academic documents that were written for experts, thus making the essential step of assessing the summarization output through human-evaluation very demanding. To overcome these limitations, we present a dataset based on article summaries appearing on the WikiHow website, composed of how-to articles and coherent-paragraph summaries written in plain language. We compare our dataset attributes to existing ones, including readability and world-knowledge, showing our dataset makes human evaluation significantly easier and thus, more effective. A human evaluation conducted on PubMed and the proposed dataset reinforces our findings.
Despite the success of various text generation metrics such as BERTScore, it is still difficult to evaluate the image captions without enough reference captions due to the diversity of the descriptions. In this paper, we introduce a new metric UMIC, an Unreferenced Metric for Image Captioning which does not require reference captions to evaluate image captions. Based on Vision-and-Language BERT, we train UMIC to discriminate negative captions via contrastive learning. Also, we observe critical problems of the previous benchmark dataset (i.e., human annotations) on image captioning metric, and introduce a new collection of human annotations on the generated captions. We validate UMIC on four datasets, including our new dataset, and show that UMIC has a higher correlation than all previous metrics that require multiple references.
Good quality monolingual word embeddings (MWEs) can be built for languages which have large amounts of unlabeled text. MWEs can be aligned to bilingual spaces using only a few thousand word translation pairs. For low resource languages training MWEs monolingually results in MWEs of poor quality, and thus poor bilingual word embeddings (BWEs) as well. This paper proposes a new approach for building BWEs in which the vector space of the high resource source language is used as a starting point for training an embedding space for the low resource target language. By using the source vectors as anchors the vector spaces are automatically aligned during training. We experiment on English-German, English-Hiligaynon and English-Macedonian. We show that our approach results not only in improved BWEs and bilingual lexicon induction performance, but also in improved target language MWE quality as measured using monolingual word similarity.
Although multilingual neural machine translation (MNMT) enables multiple language translations, the training process is based on independent multilingual objectives. Most multilingual models can not explicitly exploit different language pairs to assist each other, ignoring the relationships among them. In this work, we propose a novel agreement-based method to encourage multilingual agreement among different translation directions, which minimizes the differences among them. We combine the multilingual training objectives with the agreement term by randomly substituting some fragments of the source language with their counterpart translations of auxiliary languages. To examine the effectiveness of our method, we conduct experiments on the multilingual translation task of 10 language pairs. Experimental results show that our method achieves significant improvements over the previous multilingual baselines.
Weighted finite-state machines are a fundamental building block of NLP systems. They have withstood the test of time—from their early use in noisy channel models in the 1990s up to modern-day neurally parameterized conditional random fields. This work examines the computation of higher-order derivatives with respect to the normalization constant for weighted finite-state machines. We provide a general algorithm for evaluating derivatives of all orders, which has not been previously described in the literature. In the case of second-order derivatives, our scheme runs in the optimal O(Aˆ2 Nˆ4) time where A is the alphabet size and N is the number of states. Our algorithm is significantly faster than prior algorithms. Additionally, our approach leads to a significantly faster algorithm for computing second-order expectations, such as covariance matrices and gradients of first-order expectations.
The growth of online consumer health questions has led to the necessity for reliable and accurate question answering systems. A recent study showed that manual summarization of consumer health questions brings significant improvement in retrieving relevant answers. However, the automatic summarization of long questions is a challenging task due to the lack of training data and the complexity of the related subtasks, such as the question focus and type recognition. In this paper, we introduce a reinforcement learning-based framework for abstractive question summarization. We propose two novel rewards obtained from the downstream tasks of (i) question-type identification and (ii) question-focus recognition to regularize the question generation model. These rewards ensure the generation of semantically valid questions and encourage the inclusion of key medical entities/foci in the question summary. We evaluated our proposed method on two benchmark datasets and achieved higher performance over state-of-the-art models. The manual evaluation of the summaries reveals that the generated questions are more diverse and have fewer factual inconsistencies than the baseline summaries. The source code is available here: https://github.com/shwetanlp/CHQ-Summ.
Relation linking is a crucial component of Knowledge Base Question Answering systems. Existing systems use a wide variety of heuristics, or ensembles of multiple systems, heavily relying on the surface question text. However, the explicit semantic parse of the question is a rich source of relation information that is not taken advantage of. We propose a simple transformer-based neural model for relation linking that leverages the AMR semantic parse of a sentence. Our system significantly outperforms the state-of-the-art on 4 popular benchmark datasets. These are based on either DBpedia or Wikidata, demonstrating that our approach is effective across KGs.
Early fusion models with cross-attention have shown better-than-human performance on some question answer benchmarks, while it is a poor fit for retrieval since it prevents pre-computation of the answer representations. We present a supervised data mining method using an accurate early fusion model to improve the training of an efficient late fusion retrieval model. We first train an accurate classification model with cross-attention between questions and answers. The cross-attention model is then used to annotate additional passages in order to generate weighted training examples for a neural retrieval model. The resulting retrieval model with additional data significantly outperforms retrieval models directly trained with gold annotations on Precision at N (P@N) and Mean Reciprocal Rank (MRR).
Generating descriptive sentences that convey non-trivial, detailed, and salient information about images is an important goal of image captioning. In this paper we propose a novel approach to encourage captioning models to produce more detailed captions using natural language inference, based on the motivation that, among different captions of an image, descriptive captions are more likely to entail less descriptive captions. Specifically, we construct directed inference graphs for reference captions based on natural language inference. A PageRank algorithm is then employed to estimate the descriptiveness score of each node. Built on that, we use reference sampling and weighted designated rewards to guide captioning to generate descriptive captions. The results on MSCOCO show that the proposed method outperforms the baselines significantly on a wide range of conventional and descriptiveness-related evaluation metrics.
We present an instance-based nearest neighbor approach to entity linking. In contrast to most prior entity retrieval systems which represent each entity with a single vector, we build a contextualized mention-encoder that learns to place similar mentions of the same entity closer in vector space than mentions of different entities. This approach allows all mentions of an entity to serve as “class prototypes” as inference involves retrieving from the full set of labeled entity mentions in the training set and applying the nearest mention neighbor’s entity label. Our model is trained on a large multilingual corpus of mention pairs derived from Wikipedia hyperlinks, and performs nearest neighbor inference on an index of 700 million mentions. It is simpler to train, gives more interpretable predictions, and outperforms all other systems on two multilingual entity linking benchmarks.
BERT has been shown to be extremely effective on a wide variety of natural language processing tasks, including sentiment analysis and emotion detection. However, the proposed pretraining objectives of BERT do not induce any sentiment or emotion-specific biases into the model. In this paper, we present Emotion Masked Language Modelling, a variation of Masked Language Modelling aimed at improving the BERT language representation model for emotion detection and sentiment analysis tasks. Using the same pre-training corpora as the original model, Wikipedia and BookCorpus, our BERT variation manages to improve the downstream performance on 4 tasks from emotion detection and sentiment analysis by an average of 1.2% F-1. Moreover, our approach shows an increased performance in our task-specific robustness tests.
Prior work has revealed that positive words occur more frequently than negative words in human expressions, which is typically attributed to positivity bias, a tendency for people to report positive views of reality. But what about the language used in negative reviews? Consistent with prior work, we show that English negative reviews tend to contain more positive words than negative words, using a variety of datasets. We reconcile this observation with prior findings on the pragmatics of negation, and show that negations are commonly associated with positive words in negative reviews. Furthermore, in negative reviews, the majority of sentences with positive words express negative opinions based on sentiment classifiers, indicating some form of negation.
Large pre-trained language generation models such as GPT-2 have demonstrated their effectiveness as language priors by reaching state-of-the-art results in various language generation tasks. However, the performance of pre-trained models on task-oriented dialog tasks is still under-explored. We propose a Pre-trainedRole Alternating Language model (PRAL), explicitly designed for task-oriented conversational systems. We design several techniques: start position randomization, knowledge distillation, and history discount to improve pre-training performance. In addition, we introduce a high-quality large-scale task-oriented dialog pre-training dataset by post-prossessing13 dialog datasets. We effectively adapt PRALon three downstream tasks. The results show that PRAL outperforms or is on par with state-of-the-art models.
Natural reading orders of words are crucial for information extraction from form-like documents. Despite recent advances in Graph Convolutional Networks (GCNs) on modeling spatial layout patterns of documents, they have limited ability to capture reading orders of given word-level node representations in a graph. We propose Reading Order Equivariant Positional Encoding (ROPE), a new positional encoding technique designed to apprehend the sequential presentation of words in documents. ROPE generates unique reading order codes for neighboring words relative to the target word given a word-level graph connectivity. We study two fundamental document entity extraction tasks including word labeling and word grouping on the public FUNSD dataset and a large-scale payment dataset. We show that ROPE consistently improves existing GCNs with a margin up to 8.4% F1-score.
Event extraction has long been a challenging task, addressed mostly with supervised methods that require expensive annotation and are not extensible to new event ontologies. In this work, we explore the possibility of zero-shot event extraction by formulating it as a set of Textual Entailment (TE) and/or Question Answering (QA) queries (e.g. “A city was attacked” entails “There is an attack”), exploiting pretrained TE/QA models for direct transfer. On ACE-2005 and ERE, our system achieves acceptable results, yet there is still a large gap from supervised approaches, showing that current QA and TE technologies fail in transferring to a different domain. To investigate the reasons behind the gap, we analyze the remaining key challenges, their respective impact, and possible improvement directions.
Pre-trained language models have achieved human-level performance on many Machine Reading Comprehension (MRC) tasks, but it remains unclear whether these models truly understand language or answer questions by exploiting statistical biases in datasets. Here, we demonstrate a simple yet effective method to attack MRC models and reveal the statistical biases in these models. We apply the method to the RACE dataset, for which the answer to each MRC question is selected from 4 options. It is found that several pre-trained language models, including BERT, ALBERT, and RoBERTa, show consistent preference to some options, even when these options are irrelevant to the question. When interfered by these irrelevant options, the performance of MRC models can be reduced from human-level performance to the chance-level performance. Human readers, however, are not clearly affected by these irrelevant options. Finally, we propose an augmented training method that can greatly reduce models’ statistical biases.
Extensive work has argued in favour of paying crowd workers a wage that is at least equivalent to the U.S. federal minimum wage. Meanwhile, research on collecting high quality annotations suggests using a qualification that requires workers to have previously completed a certain number of tasks. If most requesters who pay fairly require workers to have completed a large number of tasks already then workers need to complete a substantial amount of poorly paid work before they can earn a fair wage. Through analysis of worker discussions and guidance for researchers, we estimate that workers spend approximately 2.25 months of full time effort on poorly paid tasks in order to get the qualifications needed for better paid tasks. We discuss alternatives to this qualification and conduct a study of the correlation between qualifications and work quality on two NLP tasks. We find that it is possible to reduce the burden on workers while still collecting high quality data.
Human activities can be seen as sequences of events, which are crucial to understanding societies. Disproportional event distribution for different demographic groups can manifest and amplify social stereotypes, and potentially jeopardize the ability of members in some groups to pursue certain goals. In this paper, we present the first event-centric study of gender biases in a Wikipedia corpus. To facilitate the study, we curate a corpus of career and personal life descriptions with demographic information consisting of 7,854 fragments from 10,412 celebrities. Then we detect events with a state-of-the-art event detection model, calibrate the results using strategically generated templates, and extract events that have asymmetric associations with genders. Our study discovers that the Wikipedia pages tend to intermingle personal life events with professional events for females but not for males, which calls for the awareness of the Wikipedia community to formalize guidelines and train the editors to mind the implicit biases that contributors carry. Our work also lays the foundation for future works on quantifying and discovering event biases at the corpus level.
Neural machine translation has achieved great success in bilingual settings, as well as in multilingual settings. With the increase of the number of languages, multilingual systems tend to underperform their bilingual counterparts. Model capacity has been found crucial for massively multilingual NMT to support language pairs with varying typological characteristics. Previous work increases the modeling capacity by deepening or widening the Transformer. However, modeling cardinality based on aggregating a set of transformations with the same topology has been proven more effective than going deeper or wider when increasing capacity. In this paper, we propose to efficiently increase the capacity for multilingual NMT by increasing the cardinality. Unlike previous work which feeds the same input to several transformations and merges their outputs into one, we present a Multi-Input-Multi-Output (MIMO) architecture that allows each transformation of the block to have its own input. We also present a task-aware attention mechanism to learn to selectively utilize individual transformations from a set of transformations for different translation directions. Our model surpasses previous work and establishes a new state-of-the-art on the large scale OPUS-100 corpus while being 1.31 times as fast.
kNN-MT, recently proposed by Khandelwal et al. (2020a), successfully combines pre-trained neural machine translation (NMT) model with token-level k-nearest-neighbor (kNN) retrieval to improve the translation accuracy. However, the traditional kNN algorithm used in kNN-MT simply retrieves a same number of nearest neighbors for each target token, which may cause prediction errors when the retrieved neighbors include noises. In this paper, we propose Adaptive kNN-MT to dynamically determine the number of k for each target token. We achieve this by introducing a light-weight Meta-k Network, which can be efficiently trained with only a few training samples. On four benchmark machine translation datasets, we demonstrate that the proposed method is able to effectively filter out the noises in retrieval results and significantly outperforms the vanilla kNN-MT model. Even more noteworthy is that the Meta-k Network learned on one domain could be directly applied to other domains and obtain consistent improvements, illustrating the generality of our method. Our implementation is open-sourced at https://github.com/zhengxxn/adaptive-knn-mt.
Orthogonality constraints encourage matrices to be orthogonal for numerical stability. These plug-and-play constraints, which can be conveniently incorporated into model training, have been studied for popular architectures in natural language processing, such as convolutional neural networks and recurrent neural networks. However, a dedicated study on such constraints for transformers has been absent. To fill this gap, this paper studies orthogonality constraints for transformers, showing the effectiveness with empirical evidence from ten machine translation tasks and two dialogue generation tasks. For example, on the large-scale WMT’16 En→De benchmark, simply plugging-and-playing orthogonality constraints on the original transformer model (Vaswani et al., 2017) increases the BLEU from 28.4 to 29.6, coming close to the 29.7 BLEU achieved by the very competitive dynamic convolution (Wu et al., 2019).
Imagine you are in a supermarket. You have two bananas in your basket and want to buy four apples. How many fruits do you have in total? This seemingly straightforward question can be challenging for data-driven language models, even if trained at scale. However, we would expect such generic language models to possess some mathematical abilities in addition to typical linguistic competence. Towards this goal, we investigate if a commonly used language model, BERT, possesses such mathematical abilities and, if so, to what degree. For that, we fine-tune BERT on a popular dataset for word math problems, AQuA-RAT, and conduct several tests to understand learned representations better. Since we teach models trained on natural language to do formal mathematics, we hypothesize that such models would benefit from training on semi-formal steps that explain how math results are derived. To better accommodate such training, we also propose new pretext tasks for learning mathematical rules. We call them (Neighbor) Reasoning Order Prediction (ROP or NROP). With this new model, we achieve significantly better outcomes than data-driven baselines and even on-par with more tailored models.
Datasets with induced emotion labels are scarce but of utmost importance for many NLP tasks. We present a new, automated method for collecting texts along with their induced reaction labels. The method exploits the online use of reaction GIFs, which capture complex affective states. We show how to augment the data with induced emotion and induced sentiment labels. We use our method to create and publish ReactionGIF, a first-of-its-kind affective dataset of 30K tweets. We provide baselines for three new tasks, including induced sentiment prediction and multilabel classification of induced emotions. Our method and dataset open new research opportunities in emotion detection and affective computing.
This work explores a framework for fact verification that leverages pretrained sequence-to-sequence transformer models for sentence selection and label prediction, two key sub-tasks in fact verification. Most notably, improving on previous pointwise aggregation approaches for label prediction, we take advantage of T5 using a listwise approach coupled with data augmentation. With this enhancement, we observe that our label prediction stage is more robust to noise and capable of verifying complex claims by jointly reasoning over multiple pieces of evidence. Experimental results on the FEVER task show that our system attains a FEVER score of 75.87% on the blind test set. This puts our approach atop the competitive FEVER leaderboard at the time of our work, scoring higher than the second place submission by almost two points in label accuracy and over one point in FEVER score.
Sentence embedding methods using natural language inference (NLI) datasets have been successfully applied to various tasks. However, these methods are only available for limited languages due to relying heavily on the large NLI datasets. In this paper, we propose DefSent, a sentence embedding method that uses definition sentences from a word dictionary, which performs comparably on unsupervised semantics textual similarity (STS) tasks and slightly better on SentEval tasks than conventional methods. Since dictionaries are available for many languages, DefSent is more broadly applicable than methods using NLI datasets without constructing additional datasets. We demonstrate that DefSent performs comparably on unsupervised semantics textual similarity (STS) tasks and slightly better on SentEval tasks to the methods using large NLI datasets. Our code is publicly available at https://github.com/hpprc/defsent.
Modern sentence encoders are used to generate dense vector representations that capture the underlying linguistic characteristics for a sequence of words, including phrases, sentences, or paragraphs. These kinds of representations are ideal for training a classifier for an end task such as sentiment analysis, question answering and text classification. Different models have been proposed to efficiently generate general purpose sentence representations to be used in pretraining protocols. While averaging is the most commonly used efficient sentence encoder, Discrete Cosine Transform (DCT) was recently proposed as an alternative that captures the underlying syntactic characteristics of a given text without compromising practical efficiency compared to averaging. However, as with most other sentence encoders, the DCT sentence encoder was only evaluated in English. To this end, we utilize DCT encoder to generate universal sentence representation for different languages such as German, French, Spanish and Russian. The experimental results clearly show the superior effectiveness of DCT encoding in which consistent performance improvements are achieved over strong baselines on multiple standardized datasets
High-quality alignment between movie scripts and plot summaries is an asset for learning to summarize stories and to generate dialogues. The alignment task is challenging as scripts and summaries substantially differ in details and abstraction levels as well as in linguistic register. This paper addresses the alignment problem by devising a fully unsupervised approach based on a global optimization model. Experimental results on ten movies show the viability of our method with 76% F1-score and its superiority over a previous baseline. We publish alignments for 914 movies to foster research in this new topic.
Most studies on word-level Quality Estimation (QE) of machine translation focus on language-specific models. The obvious disadvantages of these approaches are the need for labelled data for each language pair and the high cost required to maintain several language-specific models. To overcome these problems, we explore different approaches to multilingual, word-level QE. We show that multilingual QE models perform on par with the current language-specific models. In the cases of zero-shot and few-shot QE, we demonstrate that it is possible to accurately predict word-level quality for any given new language pair from models trained on other language pairs. Our findings suggest that the word-level QE models based on powerful pre-trained transformers that we propose in this paper generalise well across languages, making them more useful in real-world scenarios.
A sequence-to-sequence learning with neural networks has empirically proven to be an effective framework for Chinese Spelling Correction (CSC), which takes a sentence with some spelling errors as input and outputs the corrected one. However, CSC models may fail to correct spelling errors covered by the confusion sets, and also will encounter unseen ones. We propose a method, which continually identifies the weak spots of a model to generate more valuable training instances, and apply a task-specific pre-training strategy to enhance the model. The generated adversarial examples are gradually added to the training set. Experimental results show that such an adversarial training method combined with the pre-training strategy can improve both the generalization and robustness of multiple CSC models across three different datasets, achieving state-of-the-art performance for CSC task.
Adaptive Computation (AC) has been shown to be effective in improving the efficiency of Open-Domain Question Answering (ODQA) systems. However, the current AC approaches require tuning of all model parameters, and training state-of-the-art ODQA models requires significant computational resources that may not be available for most researchers. We propose Adaptive Passage Encoder, an AC method that can be applied to an existing ODQA model and can be trained efficiently on a single GPU. It keeps the parameters of the base ODQA model fixed, but it overrides the default layer-by-layer computation of the encoder with an AC policy that is trained to optimise the computational efficiency of the model. Our experimental results show that our method improves upon a state-of-the-art model on two datasets, and is also more accurate than previous AC methods due to the stronger base ODQA model. All source code and datasets are available at https://github.com/uclnlp/APE.
In this paper, we empirically investigate adversarial attack on NMT from two aspects: languages (the source vs. the target language) and positions (front vs. rear). For autoregressive NMT models that generate target words from left to right, we observe that adversarial attack on the source language is more effective than on the target language, and that attacking front positions of target sentences or positions of source sentences aligned to the front positions of corresponding target sentences is more effective than attacking other positions. We further exploit the attention distribution of the victim model to attack source sentences at positions that have a strong association with front target words. Experiment results demonstrate that our attention-based adversarial attack is more effective than adversarial attacks by sampling positions randomly or according to gradients.
SOTA coreference resolution produces increasingly impressive scores on the OntoNotes benchmark. However lack of comparable data following the same scheme for more genres makes it difficult to evaluate generalizability to open domain data. This paper provides a dataset and comprehensive evaluation showing that the latest neural LM based end-to-end systems degrade very substantially out of domain. We make an OntoNotes-like coreference dataset called OntoGUM publicly available, converted from GUM, an English corpus covering 12 genres, using deterministic rules, which we evaluate. Thanks to the rich syntactic and discourse annotations in GUM, we are able to create the largest human-annotated coreference corpus following the OntoNotes guidelines, and the first to be evaluated for consistency with the OntoNotes scheme. Out-of-domain evaluation across 12 genres shows nearly 15-20% degradation for both deterministic and deep learning systems, indicating a lack of generalizability or covert overfitting in existing coreference resolution models.
Visual Question Answering (VQA) methods aim at leveraging visual input to answer questions that may require complex reasoning over entities. Current models are trained on labelled data that may be insufficient to learn complex knowledge representations. In this paper, we propose a new method to enhance the reasoning capabilities of a multi-modal pretrained model (Vision+Language BERT) by integrating facts extracted from an external knowledge base. Evaluation on the KVQA dataset benchmark demonstrates that our method outperforms competitive baselines by 19%, achieving new state-of-the-art results. We also perform an extensive analysis highlighting the limitations of our best performing model through an ablation study.
Neural models for automated fact verification have achieved promising results thanks to the availability of large, human-annotated datasets. However, for each new domain that requires fact verification, creating a dataset by manually writing claims and linking them to their supporting evidence is expensive. We develop QACG, a framework for training a robust fact verification model by using automatically generated claims that can be supported, refuted, or unverifiable from evidence from Wikipedia. QACG generates question-answer pairs from the evidence and then converts them into different types of claims. Experiments on the FEVER dataset show that our QACG framework significantly reduces the demand for human-annotated training data. In a zero-shot scenario, QACG improves a RoBERTa model’s F1 from 50% to 77%, equivalent in performance to 2K+ manually-curated examples. Our QACG code is publicly available.
Scarcity of parallel data causes formality style transfer models to have scarce success in preserving content. We show that fine-tuning pre-trained language (GPT-2) and sequence-to-sequence (BART) models boosts content preservation, and that this is possible even with limited amounts of parallel data. Augmenting these models with rewards that target style and content –the two core aspects of the task– we achieve a new state-of-the-art.
Existing works for aspect-based sentiment analysis (ABSA) have adopted a unified approach, which allows the interactive relations among subtasks. However, we observe that these methods tend to predict polarities based on the literal meaning of aspect and opinion terms and mainly consider relations implicitly among subtasks at the word level. In addition, identifying multiple aspect–opinion pairs with their polarities is much more challenging. Therefore, a comprehensive understanding of contextual information w.r.t. the aspect and opinion are further required in ABSA. In this paper, we propose Deep Contextualized Relation-Aware Network (DCRAN), which allows interactive relations among subtasks with deep contextual information based on two modules (i.e., Aspect and Opinion Propagation and Explicit Self-Supervised Strategies). Especially, we design novel self-supervised strategies for ABSA, which have strengths in dealing with multiple aspects. Experimental results show that DCRAN significantly outperforms previous state-of-the-art methods by large margins on three widely used benchmarks.
Aspect-based sentiment analysis (ABSA) has received increasing attention recently. Most existing work tackles ABSA in a discriminative manner, designing various task-specific classification networks for the prediction. Despite their effectiveness, these methods ignore the rich label semantics in ABSA problems and require extensive task-specific designs. In this paper, we propose to tackle various ABSA tasks in a unified generative framework. Two types of paradigms, namely annotation-style and extraction-style modeling, are designed to enable the training process by formulating each ABSA task as a text generation problem. We conduct experiments on four ABSA tasks across multiple benchmark datasets where our proposed generative approach achieves new state-of-the-art results in almost all cases. This also validates the strong generality of the proposed framework which can be easily adapted to arbitrary ABSA task without additional task-specific model design.
Recently, token-level adaptive training has achieved promising improvement in machine translation, where the cross-entropy loss function is adjusted by assigning different training weights to different tokens, in order to alleviate the token imbalance problem. However, previous approaches only use static word frequency information in the target language without considering the source language, which is insufficient for bilingual tasks like machine translation. In this paper, we propose a novel bilingual mutual information (BMI) based adaptive objective, which measures the learning difficulty for each target token from the perspective of bilingualism, and assigns an adaptive weight accordingly to improve token-level adaptive training. This method assigns larger training weights to tokens with higher BMI, so that easy tokens are updated with coarse granularity while difficult tokens are updated with fine granularity. Experimental results on WMT14 English-to-German and WMT19 Chinese-to-English demonstrate the superiority of our approach compared with the Transformer baseline and previous token-level adaptive training approaches. Further analyses confirm that our method can improve the lexical diversity.
This ability to learn consecutive tasks without forgetting how to perform previously trained problems is essential for developing an online dialogue system. This paper proposes an effective continual learning method for the task-oriented dialogue system with iterative network pruning, expanding, and masking (TPEM), which preserves performance on previously encountered tasks while accelerating learning progress on subsequent tasks. Specifically, TPEM (i) leverages network pruning to keep the knowledge for old tasks, (ii) adopts network expanding to create free weights for new tasks, and (iii) introduces task-specific network masking to alleviate the negative impact of fixed weights of old tasks on new tasks. We conduct extensive experiments on seven different tasks from three benchmark datasets and show empirically that TPEM leads to significantly improved results over the strong competitors.
We present TIMERS - a TIME, Rhetorical and Syntactic-aware model for document-level temporal relation classification in the English language. Our proposed method leverages rhetorical discourse features and temporal arguments from semantic role labels, in addition to traditional local syntactic features, trained through a Gated Relational-GCN. Extensive experiments show that the proposed model outperforms previous methods by 5-18% on the TDDiscourse, TimeBank-Dense, and MATRES datasets due to our discourse-level modeling.
Arabic diacritization is a fundamental task for Arabic language processing. Previous studies have demonstrated that automatically generated knowledge can be helpful to this task. However, these studies regard the auto-generated knowledge instances as gold references, which limits their effectiveness since such knowledge is not always accurate and inferior instances can lead to incorrect predictions. In this paper, we propose to use regularized decoding and adversarial training to appropriately learn from such noisy knowledge for diacritization. Experimental results on two benchmark datasets show that, even with quite flawed auto-generated knowledge, our model can still learn adequate diacritics and outperform all previous studies, on both datasets.
Subword segmentation algorithms have been a de facto choice when building neural machine translation systems. However, most of them need to learn a segmentation model based on some heuristics, which may produce sub-optimal segmentation. This can be problematic in some scenarios when the target language has rich morphological changes or there is not enough data for learning compact composition rules. Translating at fully character level has the potential to alleviate the issue, but empirical performances of character-based models has not been fully explored. In this paper, we present an in-depth comparison between character-based and subword-based NMT systems under three settings: translating to typologically diverse languages, training with low resource, and adapting to unseen domains. Experiment results show strong competitiveness of character-based models. Further analyses show that compared to subword-based models, character-based models are better at handling morphological phenomena, generating rare and unknown words, and more suitable for transferring to unseen domains.
Chinese word segmentation (CWS) is undoubtedly an important basic task in natural language processing. Previous works only focus on the textual modality, but there are often audio and video utterances (such as news broadcast and face-to-face dialogues), where textual, acoustic and visual modalities normally exist. To this end, we attempt to combine the multi-modality (mainly the converted text and actual voice information) to perform CWS. In this paper, we annotate a new dataset for CWS containing text and audio. Moreover, we propose a time-dependent multi-modal interactive model based on Transformer framework to integrate multi-modal information for word sequence labeling. The experimental results on three different training sets show the effectiveness of our approach with fusing text and audio.
Discrimination between antonyms and synonyms is an important and challenging NLP task. Antonyms and synonyms often share the same or similar contexts and thus are hard to make a distinction. This paper proposes two underlying hypotheses and employs the mixture-of-experts framework as a solution. It works on the basis of a divide-and-conquer strategy, where a number of localized experts focus on their own domains (or subspaces) to learn their specialties, and a gating mechanism determines the space partitioning and the expert mixture. Experimental results have shown that our method achieves the state-of-the-art performance on the task.
Injecting external domain-specific knowledge (e.g., UMLS) into pretrained language models (LMs) advances their capability to handle specialised in-domain tasks such as biomedical entity linking (BEL). However, such abundant expert knowledge is available only for a handful of languages (e.g., English). In this work, by proposing a novel cross-lingual biomedical entity linking task (XL-BEL) and establishing a new XL-BEL benchmark spanning 10 typologically diverse languages, we first investigate the ability of standard knowledge-agnostic as well as knowledge-enhanced monolingual and multilingual LMs beyond the standard monolingual English BEL task. The scores indicate large gaps to English performance. We then address the challenge of transferring domain-specific knowledge in resource-rich languages to resource-poor ones. To this end, we propose and evaluate a series of cross-lingual transfer methods for the XL-BEL task, and demonstrate that general-domain bitext helps propagate the available English knowledge to languages with little to no in-domain data. Remarkably, we show that our proposed domain-specific transfer methods yield consistent gains across all target languages, sometimes up to 20 Precision@1 points, without any in-domain knowledge in the target language, and without any in-domain parallel data.
The representation degeneration problem in Contextual Word Representations (CWRs) hurts the expressiveness of the embedding space by forming an anisotropic cone where even unrelated words have excessively positive correlations. Existing techniques for tackling this issue require a learning process to re-train models with additional objectives and mostly employ a global assessment to study isotropy. Our quantitative analysis over isotropy shows that a local assessment could be more accurate due to the clustered structure of CWRs. Based on this observation, we propose a local cluster-based method to address the degeneration issue in contextual embedding spaces. We show that in clusters including punctuations and stop words, local dominant directions encode structural information, removing which can improve CWRs performance on semantic tasks. Moreover, we find that tense information in verb representations dominates sense semantics. We show that removing dominant directions of verb representations can transform the space to better suit semantic applications. Our experiments demonstrate that the proposed cluster-based method can mitigate the degeneration problem on multiple tasks.
Humans often refer to personal narratives, life experiences, and events to make a conversation more engaging and rich. While persona-grounded dialog models are able to generate responses that follow a given persona, they often miss out on stating detailed experiences or events related to a persona, often leaving conversations shallow and dull. In this work, we equip dialog models with ‘background stories’ related to a persona by leveraging fictional narratives from existing story datasets (e.g. ROCStories). Since current dialog datasets do not contain such narratives as responses, we perform an unsupervised adaptation of a retrieved story for generating a dialog response using a gradient-based rewriting technique. Our proposed method encourages the generated response to be fluent (i.e., highly likely) with the dialog history, minimally different from the retrieved story to preserve event ordering and consistent with the original persona. We demonstrate that our method can generate responses that are more diverse, and are rated more engaging and human-like by human evaluators, compared to outputs from existing dialog models.
The famous “laurel/yanny” phenomenon references an audio clip that elicits dramatically different responses from different listeners. For the original clip, roughly half the population hears the word “laurel,” while the other half hears “yanny.” How common are such “polyperceivable” audio clips? In this paper we apply ML techniques to study the prevalence of polyperceivability in spoken language. We devise a metric that correlates with polyperceivability of audio clips, use it to efficiently find new “laurel/yanny”-type examples, and validate these results with human experiments. Our results suggest that polyperceivable examples are surprisingly prevalent in natural language, existing for >2% of English words.
Event language models represent plausible sequences of events. Most existing approaches train autoregressive models on text, which successfully capture event co-occurrence but unfortunately constrain the model to follow the discourse order in which events are presented. Other domains may employ different discourse orders, and for many applications, we may care about different notions of ordering (e.g., temporal) or not care about ordering at all (e.g., when predicting related events in a schema). We propose a simple yet surprisingly effective strategy for improving event language models by perturbing event sequences so we can relax model dependence on text order. Despite generating completely synthetic event orderings, we show that this technique improves the performance of the event language models on both applications and out-of-domain events data.
Information Retrieval using dense low-dimensional representations recently became popular and showed out-performance to traditional sparse-representations like BM25. However, no previous work investigated how dense representations perform with large index sizes. We show theoretically and empirically that the performance for dense representations decreases quicker than sparse representations for increasing index sizes. In extreme cases, this can even lead to a tipping point where at a certain index size sparse representations outperform dense representations. We show that this behavior is tightly connected to the number of dimensions of the representations: The lower the dimension, the higher the chance for false positives, i.e. returning irrelevant documents
Cross-lingual text classification aims at training a classifier on the source language and transferring the knowledge to target languages, which is very useful for low-resource languages. Recent multilingual pretrained language models (mPLM) achieve impressive results in cross-lingual classification tasks, but rarely consider factors beyond semantic similarity, causing performance degradation between some language pairs. In this paper we propose a simple yet effective method to incorporate heterogeneous information within and across languages for cross-lingual text classification using graph convolutional networks (GCN). In particular, we construct a heterogeneous graph by treating documents and words as nodes, and linking nodes with different relations, which include part-of-speech roles, semantic similarity, and document translations. Extensive experiments show that our graph-based method significantly outperforms state-of-the-art models on all tasks, and also achieves consistent performance gain over baselines in low-resource settings where external tools like translators are unavailable.
Question answering (QA) in English has been widely explored, but multilingual datasets are relatively new, with several methods attempting to bridge the gap between high- and low-resourced languages using data augmentation through translation and cross-lingual transfer. In this project we take a step back and study which approaches allow us to take the most advantage of existing resources in order to produce QA systems in many languages. Specifically, we perform extensive analysis to measure the efficacy of few-shot approaches augmented with automatic translations and permutations of context-question-answer pairs. In addition, we make suggestions for future dataset development efforts that make better use of a fixed annotation budget, with a goal of increasing the language coverage of QA datasets and systems.
We propose an effective context-sensitive neural model for time to event (TTE) prediction task, which aims to predict the amount of time to/from the occurrence of given events in streaming content. We investigate this problem in the context of a multi-task learning framework, which we enrich with time difference embeddings. In addition, we develop a multi-genre dataset of English events about soccer competitions and academy awards ceremonies, and their relevant tweets obtained from Twitter. Our model is 1.4 and 3.3 hours more accurate than the current state-of-the-art model in estimating TTE on English and Dutch tweets respectively. We examine different aspects of our model to illustrate its source of improvement.
Compositional generalization is the ability to generalize systematically to a new data distribution by combining known components. Although humans seem to have a great ability to generalize compositionally, state-of-the-art neural models struggle to do so. In this work, we study compositional generalization in classification tasks and present two main contributions. First, we study ways to convert a natural language sequence-to-sequence dataset to a classification dataset that also requires compositional generalization. Second, we show that providing structural hints (specifically, providing parse trees and entity links as attention masks for a Transformer model) helps compositional generalization.
Pre-trained text-to-text transformers such as BART have achieved impressive performance across a range of NLP tasks. Recent study further shows that they can learn to generalize to novel tasks, by including task descriptions as part of the source sequence and training the model with (source, target) examples. At test time, these fine-tuned models can make inferences on new tasks using the new task descriptions as part of the input. However, this approach has potential limitations, as the model learns to solve individual (source, target) examples (i.e., at the instance level), instead of learning to solve tasks by taking all examples within a task as a whole (i.e., at the task level). To this end, we introduce Hypter, a framework that improves text-to-text transformer’s generalization ability to unseen tasks by training a hypernetwork to generate task-specific, light-weight adapters from task descriptions. Experiments on ZEST dataset and a synthetic SQuAD dataset demonstrate that Hypter improves upon fine-tuning baselines. Notably, when using BART-Large as the main network, Hypter brings 11.3% comparative improvement on ZEST dataset.
Slot-filling is an essential component for building task-oriented dialog systems. In this work, we focus on the zero-shot slot-filling problem, where the model needs to predict slots and their values, given utterances from new domains without training on the target domain. Prior methods directly encode slot descriptions to generalize to unseen slot types. However, raw slot descriptions are often ambiguous and do not encode enough semantic information, limiting the models’ zero-shot capability. To address this problem, we introduce QA-driven slot filling (QASF), which extracts slot-filler spans from utterances with a span-based QA model. We use a linguistically motivated questioning strategy to turn descriptions into questions, allowing the model to generalize to unseen slot types. Moreover, our QASF model can benefit from weak supervision signals from QA pairs synthetically generated from unlabeled conversations. Our full system substantially outperforms baselines by over 5% on the SNIPS benchmark.
Language models like BERT and SpanBERT pretrained on open-domain data have obtained impressive gains on various NLP tasks. In this paper, we probe the effectiveness of domain-adaptive pretraining objectives on downstream tasks. In particular, three objectives, including a novel objective focusing on modeling predicate-argument relations, are evaluated on two challenging dialogue understanding tasks. Experimental results demonstrate that domain-adaptive pretraining with proper objectives can significantly improve the performance of a strong baseline on these tasks, achieving the new state-of-the-art performances.
It has become a common pattern in our field: One group introduces a language task, exemplified by a dataset, which they argue is challenging enough to serve as a benchmark. They also provide a baseline model for it, which then soon is improved upon by other groups. Often, research efforts then move on, and the pattern repeats itself. What is typically left implicit is the argumentation for why this constitutes progress, and progress towards what. In this paper, we try to step back for a moment from this pattern and work out possible argumentations and their parts.
In this work, we introduce : the largest publicly available multilingual dataset for factual verification of naturally existing real-world claims. The dataset contains short statements in 25 languages and is labeled for veracity by expert fact-checkers. The dataset includes a multilingual evaluation benchmark that measures both out-of-domain generalization, and zero-shot capabilities of the multilingual models. Using state-of-the-art multilingual transformer-based models, we develop several automated fact-checking models that, along with textual claims, make use of additional metadata and evidence from news stories retrieved using a search engine. Empirically, our best model attains an F-score of around 40%, suggesting that our dataset is a challenging benchmark for the evaluation of multilingual fact-checking models.
Recently, mT5 - a massively multilingual version of T5 - leveraged a unified text-to-text format to attain state-of-the-art results on a wide variety of multilingual NLP tasks. In this paper, we investigate the impact of incorporating parallel data into mT5 pre-training. We find that multi-tasking language modeling with objectives such as machine translation during pre-training is a straightforward way to improve performance on downstream multilingual and cross-lingual tasks. However, the gains start to diminish as the model capacity increases, suggesting that parallel data might not be as essential for larger models. At the same time, even at larger model sizes, we find that pre-training with parallel data still provides benefits in the limited labelled data regime
Intelligent and adaptive online education systems aim to make high-quality education available for a diverse range of students. However, existing systems usually depend on a pool of hand-made questions, limiting how fine-grained and open-ended they can be in adapting to individual students. We explore targeted question generation as a controllable sequence generation task. We first show how to fine-tune pre-trained language models for deep knowledge tracing (LM-KT). This model accurately predicts the probability of a student answering a question correctly, and generalizes to questions not seen in training. We then use LM-KT to specify the objective and data for training a model to generate questions conditioned on the student and target difficulty. Our results show we succeed at generating novel, well-calibrated language translation questions for second language learners from a real online education platform.
This paper presents a simple recipe to trainstate-of-the-art multilingual Grammatical Error Correction (GEC) models. We achieve this by first proposing a language-agnostic method to generate a large number of synthetic examples. The second ingredient is to use large-scale multilingual language models (up to 11B parameters). Once fine-tuned on language-specific supervised sets we surpass the previous state-of-the-art results on GEC benchmarks in four languages: English, Czech, German and Russian. Having established a new set of baselines for GEC, we make our results easily reproducible and accessible by releasing a CLANG-8 dataset. It is produced by using our best model, which we call gT5, to clean the targets of a widely used yet noisy Lang-8 dataset. cLang-8 greatly simplifies typical GEC training pipelines composed of multiple fine-tuning stages – we demonstrate that performing a single fine-tuning stepon cLang-8 with the off-the-shelf language models yields further accuracy improvements over an already top-performing gT5 model for English.
Pathology imaging is broadly used for identifying the causes and effects of diseases or injuries. Given a pathology image, being able to answer questions about the clinical findings contained in the image is very important for medical decision making. In this paper, we aim to develop a pathological visual question answering framework to analyze pathology images and answer medical questions related to these images. To build such a framework, we create PathVQA, a VQA dataset with 32,795 questions asked from 4,998 pathology images. We also propose a three-level optimization framework which performs self-supervised pretraining and VQA finetuning end-to-end to learn powerful visual and textual representations jointly and automatically identifies and excludes noisy self-supervised examples from pretraining. We perform experiments on our created PathVQA dataset and the results demonstrate the effectiveness of our proposed methods. The datasets and code are available at https://github.com/UCSD-AI4H/PathVQA
Text-based games (TBGs) have emerged as useful benchmarks for evaluating progress at the intersection of grounded language understanding and reinforcement learning (RL). Recent work has proposed the use of external knowledge to improve the efficiency of RL agents for TBGs. In this paper, we posit that to act efficiently in TBGs, an agent must be able to track the state of the game while retrieving and using relevant commonsense knowledge. Thus, we propose an agent for TBGs that induces a graph representation of the game state and jointly grounds it with a graph of commonsense knowledge from ConceptNet. This combination is achieved through bidirectional knowledge graph attention between the two symbolic representations. We show that agents that incorporate commonsense into the game state graph outperform baseline agents.
We introduce mTVR, a large-scale multilingual video moment retrieval dataset, containing 218K English and Chinese queries from 21.8K TV show video clips. The dataset is collected by extending the popular TVR dataset (in English) with paired Chinese queries and subtitles. Compared to existing moment retrieval datasets, mTVR is multilingual, larger, and comes with diverse annotations. We further propose mXML, a multilingual moment retrieval model that learns and operates on data from both languages, via encoder parameter sharing and language neighborhood constraints. We demonstrate the effectiveness of mXML on the newly collected mTVR dataset, where mXML outperforms strong monolingual baselines while using fewer parameters. In addition, we also provide detailed dataset analyses and model ablations. Data and code are publicly available at https://github.com/jayleicn/mTVRetrieval
Named entity recognition (NER) is well studied for the general domain, and recent systems have achieved human-level performance for identifying common entity types. However, the NER performance is still moderate for specialized domains that tend to feature complicated contexts and jargonistic entity types. To address these challenges, we propose explicitly connecting entity mentions based on both global coreference relations and local dependency relations for building better entity mention representations. In our experiments, we incorporate entity mention relations by Graph Neural Networks and show that our system noticeably improves the NER performance on two datasets from different domains. We further show that the proposed lightweight system can effectively elevate the NER performance to a higher level even when only a tiny amount of labeled data is available, which is desirable for domain-specific NER.
Accurate terminology translation is crucial for ensuring the practicality and reliability of neural machine translation (NMT) systems. To address this, lexically constrained NMT explores various methods to ensure pre-specified words and phrases appear in the translation output. However, in many cases, those methods are studied on general domain corpora, where the terms are mostly uni- and bi-grams (>98%). In this paper, we instead tackle a more challenging setup consisting of domain-specific corpora with much longer n-gram and highly specialized terms. Inspired by the recent success of masked span prediction models, we propose a simple and effective training strategy that achieves consistent improvements on both terminology and sentence-level translation for three domain-specific corpora in two language pairs.
To help individuals express themselves better, quotation recommendation is receiving growing attention. Nevertheless, most prior efforts focus on modeling quotations and queries separately and ignore the relationship between the quotations and the queries. In this work, we introduce a transformation matrix that directly maps the query representations to quotation representations. To better learn the mapping relationship, we employ a mapping loss that minimizes the distance of two semantic spaces (one for quotation and another for mapped-query). Furthermore, we explore using the words in history queries to interpret the figurative language of quotations, where quotation-aware attention is applied on top of history queries to highlight the indicator words. Experiments on two datasets in English and Chinese show that our model outperforms previous state-of-the-art models.
Topic models extract groups of words from documents, whose interpretation as a topic hopefully allows for a better understanding of the data. However, the resulting word groups are often not coherent, making them harder to interpret. Recently, neural topic models have shown improvements in overall coherence. Concurrently, contextual embeddings have advanced the state of the art of neural models in general. In this paper, we combine contextualized representations with neural topic models. We find that our approach produces more meaningful and coherent topics than traditional bag-of-words topic models and recent neural models. Our results indicate that future improvements in language models will translate into better topic models.
Neural semantic parsers have obtained acceptable results in the context of parsing DRSs (Discourse Representation Structures). In particular models with character sequences as input showed remarkable performance for English. But how does this approach perform on languages with a different writing system, like Chinese, a language with a large vocabulary of characters? Does rule-based tokenisation of the input help, and which granularity is preferred: characters, or words? The results are promising. Even with DRSs based on English, good results for Chinese are obtained. Tokenisation offers a small advantage for English, but not for Chinese. Overall, characters are preferred as input, both for English and Chinese.
Training datasets for semantic parsing are typically small due to the higher expertise required for annotation than most other NLP tasks. As a result, models for this application usually need additional prior knowledge to be built into the architecture or algorithm. The increased dependency on human experts hinders automation and raises the development and maintenance costs in practice. This work investigates whether a generic transformer-based seq2seq model can achieve competitive performance with minimal code-generation-specific inductive bias design. By exploiting a relatively sizeable monolingual corpus of the target programming language, which is cheap to mine from the web, we achieved 81.03% exact match accuracy on Django and 32.57 BLEU score on CoNaLa. Both are SOTA to the best of our knowledge. This positive evidence highlights a potentially easier path toward building accurate semantic parsers in practice.
The general format of natural language inference (NLI) makes it tempting to be used for zero-shot text classification by casting any target label into a sentence of hypothesis and verifying whether or not it could be entailed by the input, aiming at generic classification applicable on any specified label space. In this opinion piece, we point out a few overlooked issues that are yet to be discussed in this line of work. We observe huge variance across different classification datasets amongst standard BERT-based NLI models and surprisingly find that pre-trained BERT without any fine-tuning can yield competitive performance against BERT fine-tuned for NLI. With the concern that these models heavily rely on spurious lexical patterns for prediction, we also experiment with preliminary approaches for more robust NLI, but the results are in general negative. Our observations reveal implicit but challenging difficulties in entailment-based zero-shot text classification.
Commonsense reasoning aims to incorporate sets of commonsense facts, retrieved from Commonsense Knowledge Graphs (CKG), to draw conclusion about ordinary situations. The dynamic nature of commonsense knowledge postulates models capable of performing multi-hop reasoning over new situations. This feature also results in having large-scale sparse Knowledge Graphs, where such reasoning process is needed to predict relations between new events. However, existing approaches in this area are limited by considering CKGs as a limited set of facts, thus rendering them unfit for reasoning over new unseen situations and events. In this paper, we present a neural-symbolic reasoner, which is capable of reasoning over large-scale dynamic CKGs. The logic rules for reasoning over CKGs are learned during training by our model. In addition to providing interpretable explanation, the learned logic rules help to generalise prediction to newly introduced events. Experimental results on the task of link prediction on CKGs prove the effectiveness of our model by outperforming the state-of-the-art models.
According to the self-determination theory, the levels of satisfaction of three basic needs (competence, autonomy and relatedness) have implications on people’s everyday life and career. We benchmark the novel task of automatically detecting those needs on short posts in English, by modelling it as a ternary classification task, and as three binary classification tasks. A detailed manual analysis shows that the latter has advantages in the real-world scenario, and that our best models achieve similar performances as a trained human annotator.
Recent studies on semantic frame induction show that relatively high performance has been achieved by using clustering-based methods with contextualized word embeddings. However, there are two potential drawbacks to these methods: one is that they focus too much on the superficial information of the frame-evoking verb and the other is that they tend to divide the instances of the same verb into too many different frame clusters. To overcome these drawbacks, we propose a semantic frame induction method using masked word embeddings and two-step clustering. Through experiments on the English FrameNet data, we demonstrate that using the masked word embeddings is effective for avoiding too much reliance on the surface information of frame-evoking verbs and that two-step clustering can improve the number of resulting frame clusters for the instances of the same verb.
Adapter modules were recently introduced as an efficient alternative to fine-tuning in NLP. Adapter tuning consists in freezing pre-trained parameters of a model and injecting lightweight modules between layers, resulting in the addition of only a small number of task-specific trainable parameters. While adapter tuning was investigated for multilingual neural machine translation, this paper proposes a comprehensive analysis of adapters for multilingual speech translation (ST). Starting from different pre-trained models (a multilingual ST trained on parallel data or a multilingual BART (mBART) trained on non parallel multilingual data), we show that adapters can be used to: (a) efficiently specialize ST to specific language pairs with a low extra cost in terms of parameters, and (b) transfer from an automatic speech recognition (ASR) task and an mBART pre-trained model to a multilingual ST task. Experiments show that adapter tuning offer competitive results to full fine-tuning, while being much more parameter-efficient.
The importance of parameter selection in supervised learning is well known. However, due to the many parameter combinations, an incomplete or an insufficient procedure is often applied. This situation may cause misleading or confusing conclusions. In this opinion paper, through an intriguing example we point out that the seriousness goes beyond what is generally recognized. In the topic of multilabel classification for medical code prediction, one influential paper conducted a proper parameter selection on a set, but when moving to a subset of frequently occurring labels, the authors used the same parameters without a separate tuning. The set of frequent labels became a popular benchmark in subsequent studies, which kept pushing the state of the art. However, we discovered that most of the results in these studies cannot surpass the approach in the original paper if a parameter tuning had been conducted at the time. Thus it is unclear how much progress the subsequent developments have actually brought. The lesson clearly indicates that without enough attention on parameter selection, the research progress in our field can be uncertain or even illusive.
Few-shot text classification aims to classify inputs whose label has only a few examples. Previous studies overlooked the semantic relevance between label representations. Therefore, they are easily confused by labels that are relevant. To address this problem, we propose a method that generates distinct label representations that embed information specific to each label. Our method is applicable to conventional few-shot classification models. Experimental results show that our method significantly improved the performance of few-shot text classification across models and datasets.
In real scenarios, a multilingual model trained to solve NLP tasks on a set of languages can be required to support new languages over time. Unfortunately, the straightforward retraining on a dataset containing annotated examples for all the languages is both expensive and time-consuming, especially when the number of target languages grows. Moreover, the original annotated material may no longer be available due to storage or business constraints. Re-training only with the new language data will inevitably result in Catastrophic Forgetting of previously acquired knowledge. We propose a Continual Learning strategy that updates a model to support new languages over time, while maintaining consistent results on previously learned languages. We define a Teacher-Student framework where the existing model “teaches” to a student model its knowledge about the languages it supports, while the student is also trained on a new language. We report an experimental evaluation in several tasks including Sentence Classification, Relational Learning and Sequence Labeling.
Transformer is important for text modeling. However, it has difficulty in handling long documents due to the quadratic complexity with input text length. In order to handle this problem, we propose a hierarchical interactive Transformer (Hi-Transformer) for efficient and effective long document modeling. Hi-Transformer models documents in a hierarchical way, i.e., first learns sentence representations and then learns document representations. It can effectively reduce the complexity and meanwhile capture global document context in the modeling of each sentence. More specifically, we first use a sentence Transformer to learn the representations of each sentence. Then we use a document Transformer to model the global document context from these sentence representations. Next, we use another sentence Transformer to enhance sentence modeling using the global document context. Finally, we use hierarchical pooling method to obtain document embedding. Extensive experiments on three benchmark datasets validate the efficiency and effectiveness of Hi-Transformer in long document modeling.
Transfer learning with large pretrained transformer-based language models like BERT has become a dominating approach for most NLP tasks. Simply fine-tuning those large language models on downstream tasks or combining it with task-specific pretraining is often not robust. In particular, the performance considerably varies as the random seed changes or the number of pretraining and/or fine-tuning iterations varies, and the fine-tuned model is vulnerable to adversarial attack. We propose a simple yet effective adapter-based approach to mitigate these issues. Specifically, we insert small bottleneck layers (i.e., adapter) within each layer of a pretrained model, then fix the pretrained layers and train the adapter layers on the downstream task data, with (1) task-specific unsupervised pretraining and then (2) task-specific supervised training (e.g., classification, sequence labeling). Our experiments demonstrate that such a training scheme leads to improved stability and adversarial robustness in transfer learning to various downstream tasks.
Natural Language Inference (NLI) datasets contain examples with highly ambiguous labels. While many research works do not pay much attention to this fact, several recent efforts have been made to acknowledge and embrace the existence of ambiguity, such as UNLI and ChaosNLI. In this paper, we explore the option of training directly on the estimated label distribution of the annotators in the NLI task, using a learning loss based on this ambiguity distribution instead of the gold-labels. We prepare AmbiNLI, a trial dataset obtained from readily available sources, and show it is possible to reduce ChaosNLI divergence scores when finetuning on this data, a promising first step towards learning how to capture linguistic ambiguity. Additionally, we show that training on the same amount of data but targeting the ambiguity distribution instead of gold-labels can result in models that achieve higher performance and learn better representations for downstream tasks.
Detecting Out-of-Domain (OOD) or unknown intents from user queries is essential in a task-oriented dialog system. A key challenge of OOD detection is to learn discriminative semantic features. Traditional cross-entropy loss only focuses on whether a sample is correctly classified, and does not explicitly distinguish the margins between categories. In this paper, we propose a supervised contrastive learning objective to minimize intra-class variance by pulling together in-domain intents belonging to the same class and maximize inter-class variance by pushing apart samples from different classes. Besides, we employ an adversarial augmentation mechanism to obtain pseudo diverse views of a sample in the latent space. Experiments on two public datasets prove the effectiveness of our method capturing discriminative representations for OOD detection.
Existing dialog state tracking (DST) models are trained with dialog data in a random order, neglecting rich structural information in a dataset. In this paper, we propose to use curriculum learning (CL) to better leverage both the curriculum structure and schema structure for task-oriented dialogs. Specifically, we propose a model-agnostic framework called Schema-aware Curriculum Learning for Dialog State Tracking (SaCLog), which consists of a preview module that pre-trains a DST model with schema information, a curriculum module that optimizes the model with CL, and a review module that augments mispredicted data to reinforce the CL training. We show that our proposed approach improves DST performance over both a transformer-based and RNN-based DST model (TripPy and TRADE) and achieves new state-of-the-art results on WOZ2.0 and MultiWOZ2.1.
Under the pandemic of COVID-19, people experiencing COVID19-related symptoms have a pressing need to consult doctors. Because of the shortage of medical professionals, many people cannot receive online consultations timely. To address this problem, we aim to develop a medical dialog system that can provide COVID19-related consultations. We collected two dialog datasets – CovidDialog – (in English and Chinese respectively) containing conversations between doctors and patients about COVID-19. While the largest of their kind, these two datasets are still relatively small compared with general-domain dialog datasets. Training complex dialog generation models on small datasets bears high risk of overfitting. To alleviate overfitting, we develop a multi-task learning approach, which regularizes the data-deficient dialog generation task with a masked token prediction task. Experiments on the CovidDialog datasets demonstrate the effectiveness of our approach. We perform both human evaluation and automatic evaluation of dialogs generated by our method. Results show that the generated responses are promising in being doctor-like, relevant to conversation history, clinically informative and correct. The code and the data are available at https://github.com/UCSD-AI4H/COVID-Dialogue.
In multi-modal dialogue systems, it is important to allow the use of images as part of a multi-turn conversation. Training such dialogue systems generally requires a large-scale dataset consisting of multi-turn dialogues that involve images, but such datasets rarely exist. In response, this paper proposes a 45k multi-modal dialogue dataset created with minimal human intervention. Our method to create such a dataset consists of (1) preparing and pre-processing text dialogue datasets, (2) creating image-mixed dialogues by using a text-to-image replacement technique, and (3) employing a contextual-similarity-based filtering step to ensure the contextual coherence of the dataset. To evaluate the validity of our dataset, we devise a simple retrieval model for dialogue sentence prediction tasks. Automatic metrics and human evaluation results on such tasks show that our dataset can be effectively used as training data for multi-modal dialogue systems which require an understanding of images and text in a context-aware manner. Our dataset and generation code is available at https://github.com/shh1574/multi-modal-dialogue-dataset.
Reducing and counter-acting hate speech on Social Media is a significant concern. Most of the proposed automatic methods are conducted exclusively on English and very few consistently labeled, non-English resources have been proposed. Learning to detect hate speech on English and transferring to unseen languages seems an immediate solution. This work is the first to shed light on the limits of this zero-shot, cross-lingual transfer learning framework for hate speech detection. We use benchmark data sets in English, Italian, and Spanish to detect hate speech towards immigrants and women. Investigating post-hoc explanations of the model, we discover that non-hateful, language-specific taboo interjections are misinterpreted as signals of hate speech. Our findings demonstrate that zero-shot, cross-lingual models cannot be used as they are, but need to be carefully designed.
Neural machine translation models are often biased toward the limited translation references seen during training. To amend this form of overfitting, in this paper we propose fine-tuning the models with a novel training objective based on the recently-proposed BERTScore evaluation metric. BERTScore is a scoring function based on contextual embeddings that overcomes the typical limitations of n-gram-based metrics (e.g. synonyms, paraphrases), allowing translations that are different from the references, yet close in the contextual embedding space, to be treated as substantially correct. To be able to use BERTScore as a training objective, we propose three approaches for generating soft predictions, allowing the network to remain completely differentiable end-to-end. Experiments carried out over four, diverse language pairs show improvements of up to 0.58 pp (3.28%) in BLEU score and up to 0.76 pp (0.98%) in BERTScore (F_BERT) when fine-tuning a strong baseline.
Implicit discourse relation classification is a challenging task, in particular when the text domain is different from the standard Penn Discourse Treebank (PDTB; Prasad et al., 2008) training corpus domain (Wall Street Journal in 1990s). We here tackle the task of implicit discourse relation classification on the biomedical domain, for which the Biomedical Discourse Relation Bank (BioDRB; Prasad et al., 2011) is available. We show that entity information can be used to improve discourse relational argument representation. In a first step, we show that explicitly marked instances that are content-wise similar to the target relations can be used to achieve good performance in the cross-domain setting using a simple unsupervised voting pipeline. As a further step, we show that with the linked entity information from the first step, a transformer which is augmented with entity-related information (KBERT; Liu et al., 2020) sets the new state of the art performance on the dataset, outperforming the large pre-trained BioBERT (Lee et al., 2020) model by 2% points.
In this work, we propose Masked Noun-Phrase Prediction (MNPP), a pre-training strategy to tackle pronoun resolution in a fully unsupervised setting. Firstly, We evaluate our pre-trained model on various pronoun resolution datasets without any finetuning. Our method outperforms all previous unsupervised methods on all datasets by large margins. Secondly, we proceed to a few-shot setting where we finetune our pre-trained model on WinoGrande-S and XS separately. Our method outperforms RoBERTa-large baseline with large margins, meanwhile, achieving a higher AUC score after further finetuning on the remaining three official splits of WinoGrande.
Recently, question answering (QA) based on machine reading comprehension has become popular. This work focuses on generative QA which aims to generate an abstractive answer to a given question instead of extracting an answer span from a provided passage. Generative QA often suffers from two critical problems: (1) summarizing content irrelevant to a given question, (2) drifting away from a correct answer during generation. In this paper, we address these problems by a novel Rationale-Enriched Answer Generator (REAG), which incorporates an extractive mechanism into a generative model. Specifically, we add an extraction task on the encoder to obtain the rationale for an answer, which is the most relevant piece of text in an input document to a given question. Based on the extracted rationale and original input, the decoder is expected to generate an answer with high confidence. We jointly train REAG on the MS MARCO QA+NLG task and the experimental results show that REAG improves the quality and semantic accuracy of answers over baseline models.
In news articles the lead bias is a common phenomenon that usually dominates the learning signals for neural extractive summarizers, severely limiting their performance on data with different or even no bias. In this paper, we introduce a novel technique to demote lead bias and make the summarizer focus more on the content semantics. Experiments on two news corpora with different degrees of lead bias show that our method can effectively demote the model’s learned lead bias and improve its generality on out-of-distribution data, with little to no performance loss on in-distribution data.
Machine reading comprehension (MRC) is a crucial task in natural language processing and has achieved remarkable advancements. However, most of the neural MRC models are still far from robust and fail to generalize well in real-world applications. In order to comprehensively verify the robustness and generalization of MRC models, we introduce a real-world Chinese dataset – DuReader_robust . It is designed to evaluate the MRC models from three aspects: over-sensitivity, over-stability and generalization. Comparing to previous work, the instances in DuReader_robust are natural texts, rather than the altered unnatural texts. It presents the challenges when applying MRC models to real-world applications. The experimental results show that MRC models do not perform well on the challenge test set. Moreover, we analyze the behavior of existing models on the challenge test set, which may provide suggestions for future model development. The dataset and codes are publicly available at https://github.com/baidu/DuReader.
With the recent advancements in deep learning, neural solvers have gained promising results in solving math word problems. However, these SOTA solvers only generate binary expression trees that contain basic arithmetic operators and do not explicitly use the math formulas. As a result, the expression trees they produce are lengthy and uninterpretable because they need to use multiple operators and constants to represent one single formula. In this paper, we propose sequence-to-general tree (S2G) that learns to generate interpretable and executable operation trees where the nodes can be formulas with an arbitrary number of arguments. With nodes now allowed to be formulas, S2G can learn to incorporate mathematical domain knowledge into problem-solving, making the results more interpretable. Experiments show that S2G can achieve a better performance against strong baselines on problems that require domain knowledge.
Understanding the multi-scale visual information in a video is essential for Video Question Answering (VideoQA). Therefore, we propose a novel Multi-Scale Progressive Attention Network (MSPAN) to achieve relational reasoning between cross-scale video information. We construct clips of different lengths to represent different scales of the video. Then, the clip-level features are aggregated into node features by using max-pool, and a graph is generated for each scale of clips. For cross-scale feature interaction, we design a message passing strategy between adjacent scale graphs, i.e., top-down scale interaction and bottom-up scale interaction. Under the question’s guidance of progressive attention, we realize the fusion of all-scale video features. Experimental evaluations on three benchmarks: TGIF-QA, MSVD-QA and MSRVTT-QA show our method has achieved state-of-the-art performance.
Most state-of-the-art open-domain question answering systems use a neural retrieval model to encode passages into continuous vectors and extract them from a knowledge source. However, such retrieval models often require large memory to run because of the massive size of their passage index. In this paper, we introduce Binary Passage Retriever (BPR), a memory-efficient neural retrieval model that integrates a learning-to-hash technique into the state-of-the-art Dense Passage Retriever (DPR) to represent the passage index using compact binary codes rather than continuous vectors. BPR is trained with a multi-task objective over two tasks: efficient candidate generation based on binary codes and accurate reranking based on continuous vectors. Compared with DPR, BPR substantially reduces the memory cost from 65GB to 2GB without a loss of accuracy on two standard open-domain question answering benchmarks: Natural Questions and TriviaQA. Our code and trained models are available at https://github.com/studio-ousia/bpr.
Few-shot relation extraction (FSRE) is of great importance in long-tail distribution problem, especially in special domain with low-resource data. Most existing FSRE algorithms fail to accurately classify the relations merely based on the information of the sentences together with the recognized entity pairs, due to limited samples and lack of knowledge. To address this problem, in this paper, we proposed a novel entity CONCEPT-enhanced FEw-shot Relation Extraction scheme (ConceptFERE), which introduces the inherent concepts of entities to provide clues for relation prediction and boost the relations classification performance. Firstly, a concept-sentence attention module is developed to select the most appropriate concept from multiple concepts of each entity by calculating the semantic similarity between sentences and concepts. Secondly, a self-attention based fusion module is presented to bridge the gap of concept embedding and sentence embedding from different semantic spaces. Extensive experiments on the FSRE benchmark dataset FewRel have demonstrated the effectiveness and the superiority of the proposed ConceptFERE scheme as compared to the state-of-the-art baselines. Code is available at https://github.com/LittleGuoKe/ConceptFERE.
Generalization is an important ability that helps to ensure that a machine learning model can perform well on unseen data. In this paper, we study the effect of data bias on model generalization, using Chinese Named Entity Recognition (NER) as a case study. Specifically, we analyzed five benchmarking datasets for Chinese NER, and observed the following two types of data bias that can compromise model generalization ability. Firstly, the test sets of all the five datasets contain a significant proportion of entities that have been seen in the training sets. Such test data would therefore not be able to reflect the true generalization ability of a model. Secondly, all datasets are dominated by a few fat-head entities, i.e., entities appearing with particularly high frequency. As a result, a model might be able to produce high prediction accuracy simply by keyword memorization without leveraging context knowledge. To address these data biases, we first refine each test set by excluding seen entities from it, so as to better evaluate a model’s generalization ability. Then, we propose a simple yet effective entity resampling method to make entities within the same category distributed equally, encouraging a model to leverage both name and context knowledge in the training process. Experimental results demonstrate that the proposed entity resampling method significantly improves a model’s ability in detecting unseen entities, especially for company, organization and position categories.
Document-level Relation Extraction (RE) is a more challenging task than sentence RE as it often requires reasoning over multiple sentences. Yet, human annotators usually use a small number of sentences to identify the relationship between a given entity pair. In this paper, we present an embarrassingly simple but effective method to heuristically select evidence sentences for document-level RE, which can be easily combined with BiLSTM to achieve good performance on benchmark datasets, even better than fancy graph neural network based methods. We have released our code at https://github.com/AndrewZhe/Three-Sentences-Are-All-You-Need.
Learning prerequisite chains is an important task for one to pick up knowledge efficiently in both known and unknown domains. For example, one may be an expert in the natural language processing (NLP) domain, but want to determine the best order in which to learn new concepts in an unfamiliar Computer Vision domain (CV). Both domains share some common concepts, such as machine learning basics and deep learning models. In this paper, we solve the task of unsupervised cross-domain concept prerequisite chain learning, using an optimized variational graph autoencoder. Our model learns to transfer concept prerequisite relations from an information-rich domain (source domain) to an information-poor domain (target domain), substantially surpassing other baseline models. In addition, we expand an existing dataset by introducing two new domains—-CV and Bioinformatics (BIO). The annotated data and resources as well as the code will be made publicly available.
We present a text representation approach that can combine different views (representations) of the same input through effective data fusion and attention strategies for ranking purposes. We apply our model to the problem of differential diagnosis, which aims to find the most probable diseases that match with clinical descriptions of patients, using data from the Undiagnosed Diseases Network. Our model outperforms several ranking approaches (including a commercially-supported system) by effectively prioritizing and combining representations obtained from traditional and recent text representation techniques. We elaborate on several aspects of our model and shed light on its improved performance.
Crowdworker-constructed natural language inference (NLI) datasets have been found to contain statistical artifacts associated with the annotation process that allow hypothesis-only classifiers to achieve better-than-random performance (CITATION). We investigate whether MedNLI, a physician-annotated dataset with premises extracted from clinical notes, contains such artifacts (CITATION). We find that entailed hypotheses contain generic versions of specific concepts in the premise, as well as modifiers related to responsiveness, duration, and probability. Neutral hypotheses feature conditions and behaviors that co-occur with, or cause, the condition(s) in the premise. Contradiction hypotheses feature explicit negation of the premise and implicit negation via assertion of good health. Adversarial filtering demonstrates that performance degrades when evaluated on the difficult subset. We provide partition information and recommendations for alternative dataset construction strategies for knowledge-intensive domains.
With the explosion of chatbot applications, Conversational Question Answering (CQA) has generated a lot of interest in recent years. Among proposals, reading comprehension models which take advantage of the conversation history (previous QA) seem to answer better than those which only consider the current question. Nevertheless, we note that the CQA evaluation protocol has a major limitation. In particular, models are allowed, at each turn of the conversation, to access the ground truth answers of the previous turns. Not only does this severely prevent their applications in fully autonomous chatbots, it also leads to unsuspected biases in their behavior. In this paper, we highlight this effect and propose new tools for evaluation and training in order to guard against the noted issues. The new results that we bring come to reinforce methods of the current state of the art.
Existing models on Machine Reading Comprehension (MRC) require complex model architecture for effectively modeling long texts with paragraph representation and classification, thereby making inference computationally inefficient for production use. In this work, we propose VAULT: a light-weight and parallel-efficient paragraph representation for MRC based on contextualized representation from long document input, trained using a new Gaussian distribution-based objective that pays close attention to the partially correct instances that are close to the ground-truth. We validate our VAULT architecture showing experimental results on two benchmark MRC datasets that require long context modeling; one Wikipedia-based (Natural Questions (NQ)) and the other on TechNotes (TechQA). VAULT can achieve comparable performance on NQ with a state-of-the-art (SOTA) complex document modeling approach while being 16 times faster, demonstrating the efficiency of our proposed model. We also demonstrate that our model can also be effectively adapted to a completely different domain – TechQA – with large improvement over a model fine-tuned on a previously published large PLM.
Leveraging additional unlabeled data to boost model performance is common practice in machine learning and natural language processing. For generation tasks, if there is overlap between the additional data and the target text evaluation data, then training on the additional data is training on answers of the test set. This leads to overly-inflated scores with the additional data compared to real-world testing scenarios and problems when comparing models. We study the AMR dataset and Gigaword, which is popularly used for improving AMR-to-text generators, and find significant overlap between Gigaword and a subset of the AMR dataset. We propose methods for excluding parts of Gigaword to remove this overlap, and show that our approach leads to a more realistic evaluation of the task of AMR-to-text generation. Going forward, we give simple best-practice recommendations for leveraging additional data in AMR-to-text generation.
Social media has become a valuable resource for the study of suicidal ideation and the assessment of suicide risk. Among social media platforms, Reddit has emerged as the most promising one due to its anonymity and its focus on topic-based communities (subreddits) that can be indicative of someone’s state of mind or interest regarding mental health disorders such as r/SuicideWatch, r/Anxiety, r/depression. A challenge for previous work on suicide risk assessment has been the small amount of labeled data. We propose an empirical investigation into several classes of weakly-supervised approaches, and show that using pseudo-labeling based on related issues around mental health (e.g., anxiety, depression) helps improve model performance for suicide risk assessment.
The Shuffle Test is the most common task to evaluate whether NLP models can measure coherence in text. Most recent work uses direct supervision on the task; we show that by simply finetuning a RoBERTa model, we can achieve a near perfect accuracy of 97.8%, a state-of-the-art. We argue that this outstanding performance is unlikely to lead to a good model of text coherence, and suggest that the Shuffle Test should be approached in a Zero-Shot setting: models should be evaluated without being trained on the task itself. We evaluate common models in this setting, such as Generative and Bi-directional Transformers, and find that larger architectures achieve high-performance out-of-the-box. Finally, we suggest the k-Block Shuffle Test, a modification of the original by increasing the size of blocks shuffled. Even though human reader performance remains high (around 95% accuracy), model performance drops from 94% to 78% as block size increases, creating a conceptually simple challenge to benchmark NLP models.
In this paper, we present a conceptually simple while empirically powerful framework for abstractive summarization, SimCLS, which can bridge the gap between the learning objective and evaluation metrics resulting from the currently dominated sequence-to-sequence learning framework by formulating text generation as a reference-free evaluation problem (i.e., quality estimation) assisted by contrastive learning. Experimental results show that, with minor modification over existing top-scoring systems, SimCLS can improve the performance of existing top-performing models by a large margin. Particularly, 2.51 absolute improvement against BART and 2.50 over PEGASUS w.r.t ROUGE-1 on the CNN/DailyMail dataset, driving the state-of-the-art performance to a new level. We have open-sourced our codes and results: https://github.com/yixinL7/SimCLS. Results of our proposed models have been deployed into ExplainaBoard platform, which allows researchers to understand our systems in a more fine-grained way.
In this work, we introduce a corpus for satire detection in Romanian news. We gathered 55,608 public news articles from multiple real and satirical news sources, composing one of the largest corpora for satire detection regardless of language and the only one for the Romanian language. We provide an official split of the text samples, such that training news articles belong to different sources than test news articles, thus ensuring that models do not achieve high performance simply due to overfitting. We conduct experiments with two state-of-the-art deep neural models, resulting in a set of strong baselines for our novel corpus. Our results show that the machine-level accuracy for satire detection in Romanian is quite low (under 73% on the test set) compared to the human-level accuracy (87%), leaving enough room for improvement in future research.
Faceted summarization provides briefings of a document from different perspectives. Readers can quickly comprehend the main points of a long document with the help of a structured outline. However, little research has been conducted on this subject, partially due to the lack of large-scale faceted summarization datasets. In this study, we present FacetSum, a faceted summarization benchmark built on Emerald journal articles, covering a diverse range of domains. Different from traditional document-summary pairs, FacetSum provides multiple summaries, each targeted at specific sections of a long document, including the purpose, method, findings, and value. Analyses and empirical results on our dataset reveal the importance of bringing structure into summaries. We believe FacetSum will spur further advances in summarization research and foster the development of NLP systems that can leverage the structured information in both long texts and summaries.
Søgaard (2020) obtained results suggesting the fraction of trees occurring in the test data isomorphic to trees in the training set accounts for a non-trivial variation in parser performance. Similar to other statistical analyses in NLP, the results were based on evaluating linear regressions. However, the study had methodological issues and was undertaken using a small sample size leading to unreliable results. We present a replication study in which we also bin sentences by length and find that only a small subset of sentences vary in performance with respect to graph isomorphism. Further, the correlation observed between parser performance and graph isomorphism in the wild disappears when controlling for covariants. However, in a controlled experiment, where covariants are kept fixed, we do observe a correlation. We suggest that conclusions drawn from statistical analyses like this need to be tempered and that controlled experiments can complement them by more readily teasing factors apart.
High-performing machine translation (MT) systems can help overcome language barriers while making it possible for everyone to communicate and use language technologies in the language of their choice. However, such systems require large amounts of parallel sentences for training, and translators can be difficult to find and expensive. Here, we present a data collection strategy for MT which, in contrast, is cheap and simple, as it does not require bilingual speakers. Based on the insight that humans pay specific attention to movements, we use graphics interchange formats (GIFs) as a pivot to collect parallel sentences from monolingual annotators. We use our strategy to collect data in Hindi, Tamil and English. As a baseline, we also collect data using images as a pivot. We perform an intrinsic evaluation by manually evaluating a subset of the sentence pairs and an extrinsic evaluation by finetuning mBART (Liu et al., 2020) on the collected data. We find that sentences collected via GIFs are indeed of higher quality.
Data processing is an important step in various natural language processing tasks. As the commonly used datasets in named entity recognition contain only a limited number of samples, it is important to obtain additional labeled data in an efficient and reliable manner. A common practice is to utilize large monolingual unlabeled corpora. Another popular technique is to create synthetic data from the original labeled data (data augmentation). In this work, we investigate the impact of these two methods on the performance of three different named entity recognition tasks.
Graph-to-text generation has benefited from pre-trained language models (PLMs) in achieving better performance than structured graph encoders. However, they fail to fully utilize the structure information of the input graph. In this paper, we aim to further improve the performance of the pre-trained language model by proposing a structured graph-to-text model with a two-step fine-tuning mechanism which first fine-tunes model on Wikipedia before adapting to the graph-to-text generation. In addition to using the traditional token and position embeddings to encode the knowledge graph (KG), we propose a novel tree-level embedding method to capture the inter-dependency structures of the input graph. This new approach has significantly improved the performance of all text generation metrics for the English WebNLG 2017 dataset.
The neural hidden Markov model has been proposed as an alternative to attention mechanism in machine translation with recurrent neural networks. However, since the introduction of the transformer models, its performance has been surpassed. This work proposes to introduce the concept of the hidden Markov model to the transformer architecture, which outperforms the transformer baseline. Interestingly, we find that the zero-order model already provides promising performance, giving it an edge compared to a model with first-order dependency, which performs similarly but is significantly slower in training and decoding.
Although BERT based relation classification (RC) models have achieved significant improvements over the traditional deep learning models, it seems that no consensus can be reached on what is the optimal architecture, since there are many design choices available. In this work, we design a comprehensive search space for BERT based RC models and employ a modified version of efficient neural architecture search (ENAS) method to automatically discover the design choices mentioned above. Experiments on eight benchmark RC tasks show that our method is efficient and effective in finding better architectures than the baseline BERT based RC models. Ablation study demonstrates the necessity of our search space design and the effectiveness of our search method. We also show that our framework can also apply to other entity related tasks like coreference resolution and span based named entity recognition (NER).
Despite the recent advancements of attention-based deep learning architectures across a majority of Natural Language Processing tasks, their application remains limited in a low-resource setting because of a lack of pre-trained models for such languages. In this study, we make the first attempt to investigate the challenges of adapting these techniques to an extremely low-resource language – Sumerian cuneiform – one of the world’s oldest written languages attested from at least the beginning of the 3rd millennium BC. Specifically, we introduce the first cross-lingual information extraction pipeline for Sumerian, which includes part-of-speech tagging, named entity recognition, and machine translation. We introduce InterpretLR, an interpretability toolkit for low-resource NLP and use it alongside human evaluations to gauge the trained models. Notably, all our techniques and most components of our pipeline can be generalised to any low-resource language. We publicly release all our implementations including a novel data set with domain-specific pre-processing to promote further research in this domain.
This paper studies whether emergent languages in a signaling game follow Zipf’s law of abbreviation (ZLA), especially when the communication ability of agents is limited because of interfering noises. ZLA is a well-known tendency in human languages where the more frequently a word is used, the shorter it will be. Surprisingly, previous work demonstrated that emergent languages do not obey ZLA at all when neural agents play a signaling game. It also reported that a ZLA-like tendency appeared by adding an explicit penalty on word lengths, which can be considered some external factors in reality such as articulatory effort. We hypothesize, on the other hand, that there might be not only such external factors but also some internal factors related to cognitive abilities. We assume that it could be simulated by modeling the effect of noises on the agents’ environment. In our experimental setup, the hidden states of the LSTM-based speaker and listener were added with Gaussian noise, while the channel was subject to discrete random replacement. Our results suggest that noise on a speaker is one of the factors for ZLA or at least causes emergent languages to approach ZLA, while noise on a listener and a channel is not.
Abstractive summarization is the task of compressing a long document into a coherent short document while retaining salient information. Modern abstractive summarization methods are based on deep neural networks which often require large training datasets. Since collecting summarization datasets is an expensive and time-consuming task, practical industrial settings are usually low-resource. In this paper, we study a challenging low-resource setting of summarizing long legal briefs with an average source document length of 4268 words and only 120 available (document, summary) pairs. To account for data scarcity, we used a modern pre-trained abstractive summarizer BART, which only achieves 17.9 ROUGE-L as it struggles with long documents. We thus attempt to compress these long documents by identifying salient sentences in the source which best ground the summary, using a novel algorithm based on GPT-2 language model perplexity scores, that operates within the low resource regime. On feeding the compressed documents to BART, we observe a 6.0 ROUGE-L improvement. Our method also beats several competitive salience detection baselines. Furthermore, the identified salient sentences tend to agree with independent human labeling by domain experts.
The impressive performances of pre-trained visually grounded language models have motivated a growing body of research investigating what has been learned during the pre-training. As a lot of these models are based on Transformers, several studies on the attention mechanisms used by the models to learn to associate phrases with their visual grounding in the image have been conducted. In this work, we investigate how supervising attention directly to learn visual grounding can affect the behavior of such models. We compare three different methods on attention supervision and their impact on the performances of a state-of-the-art visually grounded language model on two popular vision-and-language tasks.
Video-guided machine translation, as one type of multimodal machine translations, aims to engage video contents as auxiliary information to address the word sense ambiguity problem in machine translation. Previous studies only use features from pretrained action detection models as motion representations of the video to solve the verb sense ambiguity, leaving the noun sense ambiguity a problem. To address this problem, we propose a video-guided machine translation system by using both spatial and motion representations in videos. For spatial features, we propose a hierarchical attention network to model the spatial information from object-level to video-level. Experiments on the VATEX dataset show that our system achieves 35.86 BLEU-4 score, which is 0.51 score higher than the single model of the SOTA method.
Past work investigating what makes a Reddit post popular has indicated that style is a far better predictor than content, where posts conforming to a subreddit’s community style are better received. However, what about a diglossia, when there are two community styles? In Singapore, the basilect (‘Singlish’) co-exists with an acrolect (standard English), each with contrasting advantages of community identity and prestige respectively. In this paper, I apply stylistic approaches to predicting Reddit post scores in a diglossia. Using data from the Singaporean and British subreddits, I show that while the acrolect’s prestige attracts more upvotes, the most popular posts also draw on Singlish vocabulary to appeal to the community identity.
Natural language generation systems have witnessed important progress in the last years, but they are shown to generate tokens that are unrelated to the source input. This problem affects computational models in many NLP tasks, and it is particularly unpleasant in multimodal systems. In this work, we assess the rate of object hallucination in multimodal conversational agents playing the GuessWhat?! referential game. Better visual processing has been shown to mitigate this issue in image captioning; hence, we adapt to the GuessWhat?! task the best visual processing models at disposal, and propose two new models to play the Questioner agent. We show that the new models generate few hallucinations compared to other renowned models available in the literature. Moreover, their hallucinations are less severe (affect task-accuracy less) and are more human-like. We also analyse where hallucinations tend to occur more often through the dialogue: hallucinations are less frequent in earlier turns, cause a cascade hallucination effect, and are often preceded by negative answers, which have been shown to be harder to ground.
India is one of the most linguistically diverse nations of the world and is culturally very rich. Most of these languages are somewhat similar to each other on account of sharing a common ancestry or being in contact for a long period of time. Nowadays, researchers are constantly putting efforts in utilizing the language relatedness to improve the performance of various NLP systems such as cross lingual semantic search, machine translation, sentiment analysis systems, etc. So in this paper, we performed an extensive case study on similarity involving languages of the Indian subcontinent. Language similarity prediction is defined as the task of measuring how similar the two languages are on the basis of their lexical, morphological and syntactic features. In this study, we concentrate only on the approach to calculate lexical similarity between Indian languages by looking at various factors such as size and type of corpus, similarity algorithms, subword segmentation, etc. The main takeaways from our work are: (i) Relative order of the language similarities largely remain the same, regardless of the factors mentioned above, (ii) Similarity within the same language family is higher, (iii) Languages share more lexical features at the subword level.
Social media is often used by individuals and organisations as a platform to spread misinformation. With the recent coronavirus pandemic we have seen a surge of misinformation on Twitter, posing a danger to public health. In this paper, we compile a large COVID-19 Twitter misinformation corpus and perform an analysis to discover patterns with respect to vocabulary usage. Among others, our analysis reveals that the variety of topics and vocabulary usage are considerably more limited and negative in tweets related to misinformation than in randomly extracted tweets. In addition to our qualitative analysis, our experimental results show that a simple linear model based only on lexical features is effective in identifying misinformation-related tweets (with accuracy over 80%), providing evidence to the fact that the vocabulary used in misinformation largely differs from generic tweets.
Currently, text chatting is one of the primary means of communication. However, modern text chat still in general does not offer any navigation or even full-featured search, although the high volumes of messages demand it. In order to mitigate these inconveniences, we formulate the problem of situation-based summarization and propose a special data annotation tool intended for developing training and gold-standard data. A situation is a subset of messages revolving around a single event in both temporal and contextual senses: e.g, a group of friends arranging a meeting in chat, agreeing on date, time, and place. Situations can be extracted via information retrieval, natural language processing, and machine learning techniques. Since the task is novel, neither training nor gold-standard datasets for it have been created yet. In this paper, we present the formulation of the situation-based summarization problem. Next, we describe Chat Corpora Annotator (CCA): the first annotation system designed specifically for exploring and annotating chat log data. We also introduce a custom query language for semi-automatic situation extraction. Finally, we present the first gold-standard dataset for situation-based summarization. The software source code and the dataset are publicly available.
In this study, we propose a model that extends the continuous space topic model (CSTM), which flexibly controls word probability in a document, using pre-trained word embeddings. To develop the proposed model, we pre-train word embeddings, which capture the semantics of words and plug them into the CSTM. Intrinsic experimental results show that the proposed model exhibits a superior performance over the CSTM in terms of perplexity and convergence speed. Furthermore, extrinsic experimental results show that the proposed model is useful for a document classification task when compared with the baseline model. We qualitatively show that the latent coordinates obtained by training the proposed model are better than those of the baseline model.
The semantics of a text is manifested not only by what is read but also by what is not read. In this article, we will study how those implicit “not read” information such as end-of-paragraph () and end-of-sequence () affect the quality of text generation. Specifically, we find that the pre-trained language model GPT2 can generate better continuations by learning to generate the in the fine-tuning stage. Experimental results on English story generation show that can lead to higher BLEU scores and lower perplexity. We also conduct experiments on a self-collected Chinese essay dataset with Chinese-GPT2, a character level LM without and during pre-training. Experimental results show that the Chinese GPT2 can generate better essay endings with .
Unsupervised cross-lingual word embedding(CLWE) methods learn a linear transformation matrix that maps two monolingual embedding spaces that are separately trained with monolingual corpora. This method relies on the assumption that the two embedding spaces are structurally similar, which does not necessarily hold true in general. In this paper, we argue that using a pseudo-parallel corpus generated by an unsupervised machine translation model facilitates the structural similarity of the two embedding spaces and improves the quality of CLWEs in the unsupervised mapping method. We show that our approach outperforms other alternative approaches given the same amount of data, and, through detailed analysis, we show that data augmentation with the pseudo data from unsupervised machine translation is especially effective for mapping-based CLWEs because (1) the pseudo data makes the source and target corpora (partially) parallel; (2) the pseudo data contains information on the original language that helps to learn similar embedding spaces between the source and target languages.
Constructing knowledge graphs from unstructured text is an important task that is relevant to many domains. Most previous work focuses on extracting information from sentences or paragraphs, due to the difficulty of analyzing longer contexts. In this paper we propose a new jointly trained model that can be used for various information extraction tasks at the document level. The tasks performed by this system are entity and event identification, typing, and coreference resolution. In order to improve entity and event typing, we utilize context-aware representations aggregated from the detected mentions of the corresponding entities and events across the entire document. By extending our system to document-level, we can improve our results by incorporating cross-sentence dependencies and additional contextual information that might not be available at the sentence level, which allows for more globally optimized predictions. We evaluate our system on documents from the ACE05-E+ dataset and find significant improvement over the sentence-level SOTA on entity and event trigger identification and classification.
Television shows play an important role inpropagating societal norms. Owing to the popularity of the situational comedy (sitcom) genre, it contributes significantly to the over-all development of society. In an effort to analyze the content of television shows belong-ing to this genre, we present a dataset of dialogue turns from popular sitcoms annotated for the presence of sexist remarks. We train a text classification model to detect sexism using domain adaptive learning. We apply the model to our dataset to analyze the evolution of sexist content over the years. We propose a domain-specific semi-supervised architecture for the aforementioned detection of sexism.Through extensive experiments, we show that our model often yields better classification performance over generic deep learn-ing based sentence classification that does not employ domain-specific training. We find that while sexism decreases over time on average,the proportion of sexist dialogue for the most sexist sitcom actually increases. A quantitative analysis along with a detailed error analysis presents the case for our proposed methodology
In this paper we present our observations and evaluations by observing the linguistic performance of the system on several steps on the training process of various English-to-German Neural Machine Translation models. The linguistic performance is measured through a semi-automatic process using a test suite. Among several linguistic observations, we find that the translation quality of some linguistic categories decreased within the recorded iterations. Additionally, we notice some drops of the translation quality of certain categories when using a larger corpus.
Question answering (QA) models for reading comprehension have achieved human-level accuracy on in-distribution test sets. However, they have been demonstrated to lack robustness to challenge sets, whose distribution is different from that of training sets. Existing data augmentation methods mitigate this problem by simply augmenting training sets with synthetic examples sampled from the same distribution as the challenge sets. However, these methods assume that the distribution of a challenge set is known a priori, making them less applicable to unseen challenge sets. In this study, we focus on question-answer pair generation (QAG) to mitigate this problem. While most existing QAG methods aim to improve the quality of synthetic examples, we conjecture that diversity-promoting QAG can mitigate the sparsity of training sets and lead to better robustness. We present a variational QAG model that generates multiple diverse QA pairs from a paragraph. Our experiments show that our method can improve the accuracy of 12 challenge sets, as well as the in-distribution accuracy.
The quality of the annotated data directly influences in the success of supervised NLP models. However, creating annotated datasets is often time-consuming and expensive. Although the annotation tool takes an important role, we know little about how it influences annotation quality. We compare the quality of annotations for the task of chat-untangling made by non-experts annotators using two different tools. The first is SLATE, an existing command-line based tool, and the second is Parlay, a new tool we developed that integrates mouse interaction and visual links. Our experimental results indicate that, while both tools perform similarly in terms of annotation quality, Parlay offers a significantly better user experience.
In this study, we investigate the role of the multiple layers in deep transformer models. We design a variant of Albert that dynamically adapts the number of layers for each token of the input. The key specificity of Albert is that weights are tied across layers. Therefore, the stack of encoder layers iteratively repeats the application of the same transformation function on the input. We interpret the repetition of this application as an iterative process where the token contextualized representations are progressively refined. We analyze this process at the token level during pre-training, fine-tuning, and inference. We show that tokens do not require the same amount of iterations and that difficult or crucial tokens for the task are subject to more iterations.
Curriculum learning has improved the quality of neural machine translation, where only source-side features are considered in the metrics to determine the difficulty of translation. In this study, we apply curriculum learning to paraphrase generation for the first time. Different from machine translation, paraphrase generation allows a certain level of discrepancy in semantics between source and target, which results in diverse transformations from lexical substitution to reordering of clauses. Hence, the difficulty of transformations requires considering both source and target contexts. Experiments on formality transfer using GYAFC showed that our curriculum learning with edit distance improves the quality of paraphrase generation. Additionally, the proposed method improves the quality of difficult samples, which was not possible for previous methods.
The application of transformer-based contextual representations has became a de facto solution for solving complex NLP tasks. Despite their successes, such representations are arguably opaque as their latent dimensions are not directly interpretable. To alleviate this limitation of contextual representations, we devise such an algorithm where the output representation expresses human-interpretable information of each dimension. We achieve this by constructing a transformation matrix based on the semantic content of the embedding space and predefined semantic categories using Hellinger distance. We evaluate our inferred representations on supersense prediction task. Our experiments reveal that the interpretable nature of transformed contextual representations makes it possible to accurately predict the supersense category of a word by simply looking for its transformed coordinate with the largest coefficient. We quantify the effects of our proposed transformation when applied over traditional dense contextual embeddings. We additionally investigate and report consistent improvements for the integration of sparse contextual word representations into our proposed algorithm.
Analysis of emotions elicited by opinions, comments, or articles commonly exploits annotated corpora, in which the labels assigned to documents average the views of all annotators, or represent a majority decision. The models trained on such data are effective at identifying the general views of the population. However, their usefulness for predicting the emotions evoked by the textual content in a particular individual is limited. In this paper, we present a study performed on a dataset containing 7,000 opinions, each annotated by about 50 people with two dimensions: valence, arousal, and with intensity of eight emotions from Plutchik’s model. Our study showed that individual responses often significantly differed from the mean. Therefore, we proposed a novel measure to estimate this effect – Personal Emotional Bias (PEB). We also developed a new BERT-based transformer architecture to predict emotions from an individual human perspective. We found PEB a major factor for improving the quality of personalized reasoning. Both the method and measure may boost the quality of content recommendation systems and personalized solutions that protect users from hate speech or unwanted content, which are highly subjective in nature.
Despite the development of pre-trained language models (PLMs) significantly raise the performances of various Chinese natural language processing (NLP) tasks, the vocabulary (vocab) for these Chinese PLMs remains to be the one provided by Google Chinese BERT (CITATION), which is based on Chinese characters (chars). Second, the masked language model pre-training is based on a single vocab, limiting its downstream task performances. In this work, we first experimentally demonstrate that building a vocab via Chinese word segmentation (CWS) guided sub-word tokenization (SGT) can improve the performances of Chinese PLMs. Then we propose two versions of multi-vocab pre-training (MVP), Hi-MVP and AL-MVP, to improve the models’ expressiveness. Experiments show that: (a) MVP training strategies improve PLMs’ downstream performances, especially it can improve the PLM’s performances on span-level tasks; (b) our AL-MVP outperforms the recent AMBERT (CITATION) after large-scale pre-training, and it is more robust against adversarial attacks.
The internet has actually come to be an essential resource of health knowledge for individuals around the world in the present situation of the coronavirus condition pandemic(COVID-19). During pandemic situations, myths, sensationalism, rumours and misinformation, generated intentionally or unintentionally, spread rapidly through social networks. Twitter is one of these popular social networks people use to share COVID-19 related news, information, and thoughts that reflect their perception and opinion about the pandemic. Evaluation of tweets for recognizing misinformation can create beneficial understanding to review the top quality and also the readability of online information concerning the COVID-19. This paper presents a multilingual COVID-19 related tweet analysis method, CMTA, that uses BERT, a deep learning model for multilingual tweet misinformation detection and classification. CMTA extracts features from multilingual textual data, which is then categorized into specific information classes. Classification is done by a Dense-CNN model trained on tweets manually annotated into information classes (i.e., ‘false’, ‘partly false’, ‘misleading’). The paper presents an analysis of multilingual tweets from February to June, showing the distribution type of information spread across different languages. To access the performance of the CMTA multilingual model, we performed a comparative analysis of 8 monolingual model and CMTA for the misinformation detection task. The results show that our proposed CMTA model has surpassed various monolingual models which consolidated the fact that through transfer learning a multilingual framework could be developed.
Individuals with autism spectrum disorder (ASD) experience difficulties in social aspects of communication, but the linguistic characteristics associated with deficits in discourse and pragmatic expression are often difficult to precisely identify and quantify. We are currently collecting a corpus of transcribed natural conversations produced in an experimental setting in which participants with and without ASD complete a number of collaborative tasks with their neurotypical peers. Using this dyadic conversational data, we investigate three pragmatic features – politeness, uncertainty, and informativeness – and present a dataset of utterances annotated for each of these features on a three-point scale. We then introduce ongoing work in developing and training neural models to automatically predict these features, with the goal of identifying the same between-groups differences that are observed using manual annotations. We find the best performing model for all three features is a feed-forward neural network trained with BERT embeddings. Our models yield higher accuracy than ones used in previous approaches for deriving these features, with F1 exceeding 0.82 for all three pragmatic features.
Most earlier work on text summarization is carried out on news article datasets. The summary in these datasets is naturally located at the beginning of the text. Hence, a model can spuriously utilize this correlation for summary generation instead of truly learning to summarize. To address this issue, we constructed a new dataset, SumPubMed , using scientific articles from the PubMed archive. We conducted a human analysis of summary coverage, redundancy, readability, coherence, and informativeness on SumPubMed . SumPubMed is challenging because (a) the summary is distributed throughout the text (not-localized on top), and (b) it contains rare domain-specific scientific terms. We observe that seq2seq models that adequately summarize news articles struggle to summarize SumPubMed . Thus, SumPubMed opens new avenues for the future improvement of models as well as the development of new evaluation metrics.
The events that took place at the Unite the Right rally held in Charlottesville, Virginia on August 11-12, 2017 caused intense reaction on social media from users across the political spectrum. We present a novel application of psycholinguistics - specifically, construal level theory - to analyze the language on social media around this event of social import through topic models. We find that including psycholinguistic measures of concreteness as covariates in topic models can lead to informed analysis of the language surrounding an event of political import.
Misleading information spreads on the Internet at an incredible speed, which can lead to irreparable consequences in some cases. Therefore, it is becoming essential to develop fake news detection technologies. While substantial work has been done in this direction, one of the limitations of the current approaches is that these models are focused only on one language and do not use multilingual information. In this work, we propose a new technique based on cross-lingual evidence (CE) that can be used for fake news detection and improve existing approaches. The hypothesis of the usage of cross-lingual evidence as a feature for fake news detection is confirmed, firstly, by manual experiment based on a set of known true and fake news. Besides, we compared our fake news classification system based on the proposed feature with several strong baselines on two multi-domain datasets of general-topic news and one newly fake COVID-19 news dataset showing that combining cross-lingual evidence with strong baselines such as RoBERTa yields significant improvements in fake news detection.
It is reported that grammatical information is useful for machine translation (MT) task. However, the annotation of grammatical information requires the highly human resources. Furthermore, it is not trivial to adapt grammatical information to MT since grammatical annotation usually adapts tokenization standards which might not be suitable to capture the relation of two languages, and the use of sub-word tokenization, e.g., Byte-Pair-Encoding, to alleviate out-of-vocabulary problem might not be compatible with those annotations. In this work, we propose two methods to explicitly incorporate grammatical information without supervising annotation; first, latent phrase structure is induced in an unsupervised fashion from a multi-head attention mechanism; second, the induced phrase structures in encoder and decoder are synchronized so that they are compatible with each other using constraints during training. We demonstrate that our approach produces better performance and explainability in two tasks, translation and alignment tasks without extra resources. Although we could not obtain the high quality phrase structure in constituency parsing when evaluated monolingually, we find that the induced phrase structures enhance the explainability of translation through the synchronization constraint.
The presence of zero-pronoun (ZP) greatly affects the downstream tasks of NLP in pro-drop languages such as Japanese and Chinese. To tackle the problem, the previous works identified ZPs as sequence labeling on the word sequence or the linearlized tree nodes of the input. We propose a novel approach to ZP identification by casting it as a query-based argument span prediction task. Given a predicate as a query, our model predicts the omission with ZP. In the experiments, our model surpassed the sequence labeling baseline.
Various studies show that pretrained language models such as BERT cannot straightforwardly replace encoders in neural machine translation despite their enormous success in other tasks. This is even more astonishing considering the similarities between the architectures. This paper sheds some light on the embedding spaces they create, using average cosine similarity, contextuality metrics and measures for representational similarity for comparison, revealing that BERT and NMT encoder representations look significantly different from one another. In order to address this issue, we propose a supervised transformation from one into the other using explicit alignment and fine-tuning. Our results demonstrate the need for such a transformation to improve the applicability of BERT in MT.
This paper proposes a novel attention mechanism for Transformer Neural Machine Translation, “Synchronous Syntactic Attention,” inspired by synchronous dependency grammars. The mechanism synchronizes source-side and target-side syntactic self-attentions by minimizing the difference between target-side self-attentions and the source-side self-attentions mapped by the encoder-decoder attention matrix. The experiments show that the proposed method improves the translation performance on WMT14 En-De, WMT16 En-Ro, and ASPEC Ja-En (up to +0.38 points in BLEU).
This paper introduces TexSmart, a text understanding system that supports fine-grained named entity recognition (NER) and enhanced semantic analysis functionalities. Compared to most previous publicly available text understanding systems and tools, TexSmart holds some unique features. First, the NER function of TexSmart supports over 1,000 entity types, while most other public tools typically support several to (at most) dozens of entity types. Second, TexSmart introduces new semantic analysis functions like semantic expansion and deep semantic representation, that are absent in most previous systems. Third, a spectrum of algorithms (from very fast algorithms to those that are relatively slow but more accurate) are implemented for one function in TexSmart, to fulfill the requirements of different academic and industrial applications. The adoption of unsupervised or weakly-supervised algorithms is especially emphasized, with the goal of easily updating our models to include fresh data with less human annotation efforts.
We present IntelliCAT, an interactive translation interface with neural models that streamline the post-editing process on machine translation output. We leverage two quality estimation (QE) models at different granularities: sentence-level QE, to predict the quality of each machine-translated sentence, and word-level QE, to locate the parts of the machine-translated sentence that need correction. Additionally, we introduce a novel translation suggestion model conditioned on both the left and right contexts, providing alternatives for specific words or phrases for correction. Finally, with word alignments, IntelliCAT automatically preserves the original document’s styles in the translated document. The experimental results show that post-editing based on the proposed QE and translation suggestions can significantly improve translation quality. Furthermore, a user study reveals that three features provided in IntelliCAT significantly accelerate the post-editing task, achieving a 52.9% speedup in translation time compared to translating from scratch. The interface is publicly available at https://intellicat.beringlab.com/.
This paper announces version 1.0 of the Classical Language Toolkit (CLTK), an NLP framework for pre-modern languages. The vast majority of NLP, its algorithms and software, is created with assumptions particular to living languages, thus neglecting certain important characteristics of largely non-spoken historical languages. Further, scholars of pre-modern languages often have different goals than those of living-language researchers. To fill this void, the CLTK adapts ideas from several leading NLP frameworks to create a novel software architecture that satisfies the unique needs of pre-modern languages and their researchers. Its centerpiece is a modular processing pipeline that balances the competing demands of algorithmic diversity with pre-configured defaults. The CLTK currently provides pipelines, including models, for almost 20 languages.
In this paper, we release an open-source library, called TextBox, to provide a unified, modularized, and extensible text generation framework. TextBox aims to support a broad set of text generation tasks and models. In our library, we implement 21 text generation models on 9 benchmark datasets, covering the categories of VAE, GAN, and pretrained language models. Meanwhile, our library maintains sufficient modularity and extensibility by properly decomposing the model architecture, inference, and learning process into highly reusable modules, which allows users to easily incorporate new models into our framework. The above features make TextBox especially suitable for researchers and practitioners to quickly reproduce baseline models and develop new models. TextBox is implemented based on PyTorch, and released under Apache License 2.0 at the link https://github.com/RUCAIBox/TextBox.
ASCENT is a fully automated methodology for extracting and consolidating commonsense assertions from web contents (Nguyen et al., 2021). It advances traditional triple-based commonsense knowledge representation by capturing semantic facets like locations and purposes, and composite concepts, i.e., subgroups and related aspects of subjects. In this demo, we present a web portal that allows users to understand its construction process, explore its content, and observe its impact in the use case of question answering. The demo website (https://ascent.mpi-inf.mpg.de) and an introductory video (https://youtu.be/qMkJXqu_Yd4) are both available online.
Scientific knowledge is evolving at an unprecedented rate of speed, with new concepts constantly being introduced from millions of academic articles published every month. In this paper, we introduce a self-supervised end-to-end system, SciConceptMiner, for the automatic capture of emerging scientific concepts from both independent knowledge sources (semi-structured data) and academic publications (unstructured documents). First, we adopt a BERT-based sequence labeling model to predict candidate concept phrases with self-supervision data. Then, we incorporate rich Web content for synonym detection and concept selection via a web search API. This two-stage approach achieves highly accurate (94.7%) concept identification with more than 740K scientific concepts. These concepts are deployed in the Microsoft Academic production system and are the backbone for its semantic search capability.
NeurST is an open-source toolkit for neural speech translation. The toolkit mainly focuses on end-to-end speech translation, which is easy to use, modify, and extend to advanced speech translation research and products. NeurST aims at facilitating the speech translation research for NLP researchers and building reliable benchmarks for this field. It provides step-by-step recipes for feature extraction, data preprocessing, distributed training, and evaluation. In this paper, we will introduce the framework design of NeurST and show experimental results for different benchmark datasets, which can be regarded as reliable baselines for future research. The toolkit is publicly available at https://github.com/bytedance/neurst and we will continuously update the performance of with other counterparts and studies at https://st-benchmark.github.io/.
With more than 7000 languages worldwide, multilingual natural language processing (NLP) is essential both from an academic and commercial perspective. Researching typological properties of languages is fundamental for progress in multilingual NLP. Examples include assessing language similarity for effective transfer learning, injecting inductive biases into machine learning models or creating resources such as dictionaries and inflection tables. We provide ParCourE, an online tool that allows to browse a word-aligned parallel corpus, covering 1334 languages. We give evidence that this is useful for typological research. ParCourE can be set up for any parallel corpus and can thus be used for typological research on other corpora as well as for exploring their quality and properties.
We present MT-Telescope, a visualization platform designed to facilitate comparative analysis of the output quality of two Machine Translation (MT) systems. While automated MT evaluation metrics are commonly used to evaluate MT systems at a corpus-level, our platform supports fine-grained segment-level analysis and interactive visualisations that expose the fundamental differences in the performance of the compared systems. MT-Telescope also supports dynamic corpus filtering to enable focused analysis on specific phenomena such as; translation of named entities, handling of terminology, and the impact of input segment length on translation quality. Furthermore, the platform provides a bootstrapped t-test for statistical significance as a means of evaluating the rigor of the resulting system ranking. MT-Telescope is open source, written in Python, and is built around a user friendly and dynamic web interface. Complementing other existing tools, our platform is designed to facilitate and promote the broader adoption of more rigorous analysis practices in the evaluation of MT quality.
Health professional regulators aim to protect the health and well-being of patients and the public by setting standards for scrutinising and overseeing the training and conduct of health and care professionals. A major task of such regulators is the investigation of complaints against practitioners. However, processing a complaint often lasts several months and is particularly costly. Hence, we worked with international regulators from different countries (the UK, US and Australia), to develop the first decision support tool that aims to help such regulators process complaints more efficiently. Our system uses state-of-the-art machine learning and natural language processing techniques to process complaints and predict their risk level. Our tool also provides additional useful information including explanations, to help the regulatory staff interpret the prediction results, and similar past cases as well as non-compliance to regulations, to support the decision making.
CogNet is a knowledge base that integrates three types of knowledge: linguistic knowledge, world knowledge and commonsense knowledge. In this paper, we propose an information extraction toolkit, called CogIE, which is a bridge connecting raw texts and CogNet. CogIE has three features: versatile, knowledge-grounded and extensible. First, CogIE is a versatile toolkit with a rich set of functional modules, including named entity recognition, entity typing, entity linking, relation extraction, event extraction and frame-semantic parsing. Second, as a knowledge-grounded toolkit, CogIE can ground the extracted facts to CogNet and leverage different types of knowledge to enrich extracted results. Third, for extensibility, owing to the design of three-tier architecture, CogIE is not only a plug-and-play toolkit for developers but also an extensible programming framework for researchers. We release an open-access online system to visually extract information from texts. Source code, datasets and pre-trained models are publicly available at GitHub, with a short instruction video.
We present fastHan, an open-source toolkit for four basic tasks in Chinese natural language processing: Chinese word segmentation (CWS), Part-of-Speech (POS) tagging, named entity recognition (NER), and dependency parsing. The backbone of fastHan is a multi-task model based on a pruned BERT, which uses the first 8 layers in BERT. We also provide a 4-layer base model compressed from the 8-layer model. The joint-model is trained and evaluated on 13 corpora of four tasks, yielding near state-of-the-art (SOTA) performance in dependency parsing and NER, achieving SOTA performance in CWS and POS. Besides, fastHan’s transferability is also strong, performing much better than popular segmentation tools on a non-training corpus. To better meet the need of practical application, we allow users to use their own labeled data to further fine-tune fastHan. In addition to its small size and excellent performance, fastHan is user-friendly. Implemented as a python package, fastHan isolates users from the internal technical details and is convenient to use. The project is released on Github.
In this paper, we present Tintful, an NLP annotation software that can be used both to manually annotate texts and to fix mistakes in NLP pipelines, such as Stanford CoreNLP. Using a paradigm similar to wiki-like systems, a user who notices some wrong annotation can easily fix it and submit the resulting (and right) entry back to the tool developers. Moreover, Tintful can be used to easily annotate data from scratch. The input documents do not need to be in a particular format: starting from the plain text, the sentences are first annotated with CoreNLP, then the user can edit the annotations and submit everything back through a user-friendly interface.
We introduce Explainable Scientific Research Assistant (ESRA), a literature discovery platform that augments search results with relevant details and explanations, aiding users in understanding more about their queries and the returned papers beyond existing literature search systems. Enabled by a knowledge graph we extracted from abstracts of 23k papers on the arXiv’s cs.CL category, ESRA provides three main features: explanation (for why a paper is returned to the user), list of facts (that are relevant to the query), and graph visualization (drawing connections between the query and each paper with surrounding related entities). The experimental results with humans involved show that ESRA can accelerate the users’ search process with paper explanations and helps them better explore the landscape of the topics of interest by exploiting the underlying knowledge graph. We provide the ESRA web application at http://esra.cp.eng.chula.ac.th/.
An essential operation in web corpus construction consists in retaining the desired content while discarding the rest. Another challenge finding one’s way through websites. This article introduces a text discovery and extraction tool published under open-source license. Its installation and use is straightforward, notably from Python and on the command-line. The software allows for main text, comments and metadata extraction, while also providing building blocks for web crawling tasks. A comparative evaluation on real-world data also shows its interest as well as the performance of other available solutions. The contributions of this paper are threefold: it references the software, features a benchmark, and provides a meaningful baseline for similar tasks. The tool performs significantly better than other open-source solutions in this evaluation and in external benchmarks.
Why do large pre-trained transformer-based models perform so well across a wide variety of NLP tasks? Recent research suggests the key may lie in multi-headed attention mechanism’s ability to learn and represent linguistic information. Understanding how these models represent both syntactic and semantic knowledge is vital to investigate why they succeed and fail, what they have learned, and how they can improve. We present Dodrio, an open-source interactive visualization tool to help NLP researchers and practitioners analyze attention mechanisms in transformer-based models with linguistic knowledge. Dodrio tightly integrates an overview that summarizes the roles of different attention heads, and detailed views that help users compare attention weights with the syntactic structure and semantic information in the input text. To facilitate the visual comparison of attention weights and linguistic knowledge, Dodrio applies different graph visualization techniques to represent attention weights scalable to longer input text. Case studies highlight how Dodrio provides insights into understanding the attention mechanism in transformer-based models. Dodrio is available at https://poloclub.github.io/dodrio/.
This paper presents REM, a novel tool for the semi-automated real-time moderation of large scale online forums. The growing demand for online participation and the increasing number of user comments raise challenges in filtering out harmful and undesirable content from public debates in online forums. Since a manual moderation does not scale well and pure automated approaches often lack the required level of accuracy, we suggest a semi-automated moderation approach. Our approach maximizes the efficiency of manual efforts by targeting only those comments for which human intervention is needed, e.g. due to high classification uncertainty. Our tool offers a rich visual interactive environment enabling the exploration of online debates. We conduct a preliminary evaluation experiment to demonstrate the suitability of our approach and publicly release the source code of REM.
Novel neural architectures, training strategies, and the availability of large-scale corpora haven been the driving force behind recent progress in abstractive text summarization. However, due to the black-box nature of neural models, uninformative evaluation metrics, and scarce tooling for model and data analysis the true performance and failure modes of summarization models remain largely unknown. To address this limitation, we introduce SummVis, an open-source tool for visualizing abstractive summaries that enables fine-grained analysis of the models, data, and evaluation metrics associated with text summarization. Through its lexical and semantic visualizations, the tools offers an easy entry point for in-depth model prediction exploration across important dimensions such as factual consistency or abstractiveness. The tool together with several pre-computed model outputs is available at https://summvis.com.
Much past work has focused on extracting information like events, entities, and relations from documents. Very little work has focused on analyzing these results for better model understanding. In this paper, we introduce a curation interface that takes an Information Extraction (IE) system’s output in a pre-defined format and generates a graphical representation of its elements. The interface supports editing while curating schemas for complex events like Improvised Explosive Device (IED) based scenarios. We identify various schemas that either have linear event chains or contain parallel events with complicated temporal ordering. We iteratively update an induced schema to uniquely identify events specific to it, add optional events around them, and prune unnecessary events. The resulting schemas are improved and enriched versions of the machine-induced versions.
TEXTOIR is the first integrated and visualized platform for text open intent recognition. It is composed of two main modules: open intent detection and open intent discovery. Each module integrates most of the state-of-the-art algorithms and benchmark intent datasets. It also contains an overall framework connecting the two modules in a pipeline scheme. In addition, this platform has visualized tools for data and model management, training, evaluation and analysis of the performance from different aspects. TEXTOIR provides useful toolkits and convenient visualized interfaces for each sub-module, and designs a framework to implement a complete process to both identify known intents and discover open intents.
There is a long history of research related to automated story generation, dating back as far as the 1970s. Recently, the rapid development of pre-trained language models has spurred great progresses in this field. Equipped with GPT-2 and the latest GPT-3, AI Dungeon has been seen as a famous example of the powerful text generation capabilities of large-scale pre-trained language models, and a possibility for future games. However, as a game, AI Dungeon lacks incentives to players and relies entirely on players to explore on their own. This makes players’ enthusiasm decline rapidly. In this paper, we present an open-ended text adventure game in Chinese, named as KuiLeiXi. In KuiLeiXi, players need to interact with the AI until the pre-determined plot goals are reached. By introducing the plot goals, players have a stronger incentive to explore ways to reach plot goals, while the AI’s abilities are not abused to generate harmful contents. This limited freedom allows this game to be integrated as a part of a romance simulation mobile game, Yu Jian Love. Since KuiLeiXi was launched, it has received a lot of positive feedbacks from more than 100,000 players. A demo video is available at https://youtu.be/DyYZhxMRrkk.
In recent years, conversational recommender systems (CRSs) have drawn a wide attention in the research community, which focus on providing high-quality recommendations to users via natural language conversations. However, due to diverse scenarios and data formats, existing studies on CRSs lack unified and standardized implementation or comparison. To tackle this challenge, we release an open-source toolkit CRSLab, which provides a unified and extensible framework with highly-decoupled modules to develop CRSs. Based on this framework, we collect 6 commonly used human-annotated CRS datasets and implement 19 models that include advanced techniques such as graph neural networks and pre-training models. Besides, our toolkit provides a series of automatic evaluation protocols and a human-machine interaction interface to evaluate and compare different CRS methods. The project and documents are released at https://github.com/RUCAIBox/CRSLab.
Probing (or diagnostic classification) has become a popular strategy for investigating whether a given set of intermediate features is present in the representations of neural models. Naive probing studies may have misleading results, but various recent works have suggested more reliable methodologies that compensate for the possible pitfalls of probing. However, these best practices are numerous and fast-evolving. To simplify the process of running a set of probing experiments in line with suggested methodologies, we introduce Probe-Ably: an extendable probing framework which supports and automates the application of probing methods to the user’s inputs.
We present the first end-to-end, transformer-based table question answering (QA) system that takes natural language questions and massive table corpora as inputs to retrieve the most relevant tables and locate the correct table cells to answer the question. Our system, CLTR, extends the current state-of-the-art QA over tables model to build an end-to-end table QA architecture. This system has successfully tackled many real-world table QA problems with a simple, unified pipeline. Our proposed system can also generate a heatmap of candidate columns and rows over complex tables and allow users to quickly identify the correct cells to answer questions. In addition, we introduce two new open domain benchmarks, E2E_WTQ and E2E_GNQ, consisting of 2,005 natural language questions over 76,242 tables. The benchmarks are designed to validate CLTR as well as accommodate future table retrieval and end-to-end table QA research and experiments. Our experiments demonstrate that our system is the current state-of-the-art model on the table retrieval task and produces promising results for end-to-end table QA.
Domain experts often need to extract structured information from large corpora. We advocate for a search paradigm called “extractive search”, in which a search query is enriched with capture-slots, to allow for such rapid extraction. Such an extractive search system can be built around syntactic structures, resulting in high-precision, low-recall results. We show how the recall can be improved using neural retrieval and alignment. The goals of this paper are to concisely introduce the extractive-search paradigm; and to demonstrate a prototype neural retrieval system for extractive search and its benefits and potential. Our prototype is available at https://spike.neural-sim.apps.allenai.org/ and a video demonstration is available at https://vimeo.com/559586687.
Transformer-based models have made tremendous impacts in natural language generation. However the inference speed is a bottleneck due to large model size and intensive computing involved in auto-regressive decoding process. We develop FastSeq framework to accelerate sequence generation without accuracy loss. The proposed optimization techniques include an attention cache optimization, an efficient algorithm for detecting repeated n-grams, and an asynchronous generation pipeline with parallel I/O. These optimizations are general enough to be applicable to Transformer-based models (e.g., T5, GPT2, and UniLM). Our benchmark results on a set of widely used and diverse models demonstrate 4-9x inference speed gain. Additionally, FastSeq is easy to use with a simple one-line code change. The source code is available at https://github.com/microsoft/fastseq.
We present Logical Optimal Actions (LOA), an action decision architecture of reinforcement learning applications with a neuro-symbolic framework which is a combination of neural network and symbolic knowledge acquisition approach for natural language interaction games. The demonstration for LOA experiments consists of a web-based interactive platform for text-based games and visualization for acquired knowledge for improving interpretability for trained rules. This demonstration also provides a comparison module with other neuro-symbolic approaches as well as non-symbolic state-of-the-art agent models on the same text-based games. Our LOA also provides open-sourced implementation in Python for the reinforcement learning environment to facilitate an experiment for studying neuro-symbolic agents. Demo site: https://ibm.biz/acl21-loa, Code: https://github.com/ibm/loa
Now, the pre-training technique is ubiquitous in natural language processing field. ProphetNet is a pre-training based natural language generation method which shows powerful performance on English text summarization and question generation tasks. In this paper, we extend ProphetNet into other domains and languages, and present the ProphetNet family pre-training models, named ProphetNet-X, where X can be English, Chinese, Multi-lingual, and so on. We pre-train a cross-lingual generation model ProphetNet-Multi, a Chinese generation model ProphetNet-Zh, two open-domain dialog generation models ProphetNet-Dialog-En and ProphetNet-Dialog-Zh. And also, we provide a PLG (Programming Language Generation) model ProphetNet-Code to show the generation performance besides NLG (Natural Language Generation) tasks. In our experiments, ProphetNet-X models achieve new state-of-the-art performance on 10 benchmarks. All the models of ProphetNet-X share the same model structure, which allows users to easily switch between different models. We make the code and models publicly available, and we will keep updating more pre-training models and finetuning scripts.
Automated Essay Assessment (AEA) aims to judge students’ writing proficiency in an automatic way. This paper presents a Chinese AEA system IFlyEssayAssess (IFlyEA), targeting on evaluating essays written by native Chinese students from primary and junior schools. IFlyEA provides multi-level and multi-dimension analytical modules for essay assessment. It has state-of-the-art grammar level analysis techniques, and also integrates components for rhetoric and discourse level analysis, which are important for evaluating native speakers’ writing ability, but still challenging and less studied in previous work. Based on the comprehensive analysis, IFlyEA provides application services for essay scoring, review generation, recommendation, and explainable analytical visualization. These services can benefit both teachers and students during the process of writing teaching and learning.
Our understanding of why Transformer-based NLP models have been achieving their recent success lags behind our ability to continue scaling these models. To increase the transparency of Transformer-based language models, we present Ecco – an open-source library for the explainability of Transformer-based NLP models. Ecco provides a set of tools to capture, analyze, visualize, and interactively explore the inner mechanics of these models. This includes (1) gradient-based feature attribution for natural language generation (2) hidden states and their evolution between model layers (3) convenient access and examination tools for neuron activations in the under-explored Feed-Forward Neural Network sublayer of Transformer layers. (4) convenient examination of activation vectors via canonical correlation analysis (CCA), non-negative matrix factorization (NMF), and probing classifiers. We find that syntactic information can be retrieved from BERT’s FFNN representations in levels comparable to those in hidden state representations. More curiously, we find that the model builds up syntactic information in its hidden states even when intermediate FFNNs indicate diminished levels of syntactic information. Ecco is available at https://www.eccox.io/
Adobe’s Portable Document Format (PDF) is a popular way of distributing view-only documents with a rich visual markup. This presents a challenge to NLP practitioners who wish to use the information contained within PDF documents for training models or data analysis, because annotating these documents is difficult. In this paper, we present PDF Annotation with Labels and Structure (PAWLS), a new annotation tool designed specifically for the PDF document format. PAWLS is particularly suited for mixed-mode annotation and scenarios in which annotators require extended context to annotate accurately. PAWLS supports span-based textual annotation, N-ary relations and freeform, non-textual bounding boxes, all of which can be exported in convenient formats for training multi-modal machine learning models. A read-only PAWLS server is available at https://pawls.apps.allenai.org/, and the source code is available at https://github.com/allenai/pawls.
We present TweeNLP, a one-stop portal that organizes Twitter’s natural language processing (NLP) data and builds a visualization and exploration platform. It curates 19,395 tweets (as of April 2021) from various NLP conferences and general NLP discussions. It supports multiple features such as TweetExplorer to explore tweets by topics, visualize insights from Twitter activity throughout the organization cycle of conferences, discover popular research papers and researchers. It also builds a timeline of conference and workshop submission deadlines. We envision TweeNLP to function as a collective memory unit for the NLP community by integrating the tweets pertaining to research papers with the NLPExplorer scientific literature search engine. The current system is hosted at http://nlpexplorer.org/twitter/CFP.
We introduce ChrEnTranslate, an online machine translation demonstration system for translation between English and an endangered language Cherokee. It supports both statistical and neural translation models as well as provides quality estimation to inform users of reliability, two user feedback interfaces for experts and common users respectively, example inputs to collect human translations for monolingual data, word alignment visualization, and relevant terms from the Cherokee English dictionary. The quantitative evaluation demonstrates that our backbone translation models achieve state-of-the-art translation performance and our quality estimation well correlates with both BLEU and human judgment. By analyzing 216 pieces of expert feedback, we find that NMT is preferable because it copies less than SMT, and, in general, current models can translate fragments of the source sentence but make major mistakes. When we add these 216 expert-corrected parallel texts into the training set and retrain models, equal or slightly better performance is observed, which demonstrates indicates the potential of human-in-the-loop learning.
With the rapid development of NLP research, leaderboards have emerged as one tool to track the performance of various systems on various NLP tasks. They are effective in this goal to some extent, but generally present a rather simplistic one-dimensional view of the submitted systems, communicated only through holistic accuracy numbers. In this paper, we present a new conceptualization and implementation of NLP evaluation: the ExplainaBoard, which in addition to inheriting the functionality of the standard leaderboard, also allows researchers to (i) diagnose strengths and weaknesses of a single system (e.g. what is the best-performing system bad at?) (ii) interpret relationships between multiple systems. (e.g. where does system A outperform system B? What if we combine systems A, B and C?) and (iii) examine prediction results closely (e.g. what are common errors made by multiple systems or in what contexts do particular errors occur?). So far, ExplainaBoard covers more than 400 systems, 50 datasets, 40 languages, and 12 tasks. We not only released an online platform at the website but also make our evaluation tool an API with MIT Licence at Github and PyPi that allows users to conveniently assess their models offline. We additionally release all output files from systems that we have run or collected to motivate “output-driven” research in the future.
The usage of individual words can change over time, for example, when words experience a semantic shift. As text datasets generally comprise documents that were collected over a longer period of time, examining word usage changes in a corpus can often reveal interesting patterns. In this paper, we introduce a simple and intuitive way to track word usage changes via continuously evolving embeddings, computed as a weighted running average of transformer-based contextualized embeddings. We demonstrate our approach on a corpus of recent New York Times article snippets and provide code for an easy to use web app to conveniently explore semantic shifts with interactive plots.
A natural language database interface (NLDB) can democratize data-driven insights for non-technical users. However, existing Text-to-SQL semantic parsers cannot achieve high enough accuracy in the cross-database setting to allow good usability in practice. This work presents TURING, a NLDB system toward bridging this gap. The cross-domain semantic parser of TURING with our novel value prediction method achieves 75.1% execution accuracy, and 78.3% top-5 beam execution accuracy on the Spider validation set (Yu et al., 2018b). To benefit from the higher beam accuracy, we design an interactive system where the SQL hypotheses in the beam are explained step-by-step in natural language, with their differences highlighted. The user can then compare and judge the hypotheses to select which one reflects their intention if any. The English explanations of SQL queries in TURING are produced by our high-precision natural language generation system based on synchronous grammars.
While there are more than 7000 languages in the world, most translation research efforts have targeted a few high resource languages. Commercial translation systems support only one hundred languages or fewer, and do not make these models available for transfer to low resource languages. In this work, we present useful tools for machine translation research: MTData, NLCodec and RTG. We demonstrate their usefulness by creating a multilingual neural machine translation model capable of translating from 500 source languages to English. We make this multilingual model readily downloadable and usable as a service, or as a parent model for transfer-learning to even lower-resource languages.
We present LEGOEval, an open-source toolkit that enables researchers to easily evaluate dialogue systems in a few lines of code using the online crowdsource platform, Amazon Mechanical Turk. Compared to existing toolkits, LEGOEval features a flexible task design by providing a Python API that maps to commonly used React.js interface components. Researchers can personalize their evaluation procedures easily with our built-in pages as if playing with LEGO blocks. Thus, LEGOEval provides a fast, consistent method for reproducing human evaluation results. Besides the flexible task design, LEGOEval also offers an easy API to review collected data.
We present Retriever-Transducer-Checker (ReTraCk), a neural semantic parsing framework for large scale knowledge base question answering (KBQA). ReTraCk is designed as a modular framework to maintain high flexibility. It includes a retriever to retrieve relevant KB items efficiently, a transducer to generate logical form with syntax correctness guarantees and a checker to improve transduction procedure. ReTraCk is ranked at top1 overall performance on the GrailQA leaderboard and obtains highly competitive performance on the typical WebQuestionsSP benchmark. Our system can interact with users timely, demonstrating the efficiency of the proposed framework.
We present skweak, a versatile, Python-based software toolkit enabling NLP developers to apply weak supervision to a wide range of NLP tasks. Weak supervision is an emerging machine learning paradigm based on a simple idea: instead of labelling data points by hand, we use labelling functions derived from domain knowledge to automatically obtain annotations for a given dataset. The resulting labels are then aggregated with a generative model that estimates the accuracy (and possible confusions) of each labelling function. The skweak toolkit makes it easy to implement a large spectrum of labelling functions (such as heuristics, gazetteers, neural models or linguistic constraints) on text data, apply them on a corpus, and aggregate their results in a fully unsupervised fashion. skweak is especially designed to facilitate the use of weak supervision for NLP tasks such as text classification and sequence labelling. We illustrate the use of skweak for NER and sentiment analysis. skweak is released under an open-source license and is available at https://github.com/NorskRegnesentral/skweak
TextFlint is a multilingual robustness evaluation toolkit for NLP tasks that incorporates universal text transformation, task-specific transformation, adversarial attack, subpopulation, and their combinations to provide comprehensive robustness analyses. This enables practitioners to automatically evaluate their models from various aspects or to customize their evaluations as desired with just a few lines of code. TextFlint also generates complete analytical reports as well as targeted augmented data to address the shortcomings of the model in terms of its robustness. To guarantee acceptability, all the text transformations are linguistically based and all the transformed data selected (up to 100,000 texts) scored highly under human evaluation. To validate the utility, we performed large-scale empirical evaluations (over 67,000) on state-of-the-art deep learning models, classic supervised methods, and real-world systems. The toolkit is already available at https://github.com/textflint with all the evaluation results demonstrated at textflint.io.
In visual storytelling, a short story is generated based on a given image sequence. Despite years of work, most visual storytelling models remain limited in terms of the generated stories’ fixed length: most models produce stories with exactly five sentences because five-sentence stories dominate the training data. The fix-length stories carry limited details and provide ambiguous textual information to the readers. Therefore, we propose to “stretch” the stories, which create the potential to present in-depth visual details. This paper presents Stretch-VST, a visual storytelling framework that enables the generation of prolonged stories by adding appropriate knowledge, which is selected by the proposed scoring function. We propose a length-controlled Transformer to generate long stories. This model introduces novel positional encoding methods to maintain story quality with lengthy inputs. Experiments confirm that long stories are generated without deteriorating the quality. The human evaluation further shows that Stretch-VST can provide better focus and detail when stories are prolonged compared to state of the art. We create a webpage to demonstrate our prolonged capability.
Textual adversarial attacking has received wide and increasing attention in recent years. Various attack models have been proposed, which are enormously distinct and implemented with different programming frameworks and settings. These facts hinder quick utilization and fair comparison of attack models. In this paper, we present an open-source textual adversarial attack toolkit named OpenAttack to solve these issues. Compared with existing other textual adversarial attack toolkits, OpenAttack has its unique strengths in support for all attack types, multilinguality, and parallel processing. Currently, OpenAttack includes 15 typical attack models that cover all attack types. Its highly inclusive modular design not only supports quick utilization of existing attack models, but also enables great flexibility and extensibility. OpenAttack has broad uses including comparing and evaluating attack models, measuring robustness of a model, assisting in developing new attack models, and adversarial training. Source code and documentation can be obtained at https://github.com/thunlp/OpenAttack.
The tutorial focuses on Debating Technologies, a sub-field of computational argumentation defined as “computational technologies developed directly to enhance, support, and engage with human debating” (Gurevych et al., 2016). A recent milestone in this field is Project Debater, which was revealed in 2019 as the first AI system that can debate human experts on complex topics. Project Debater is the third in the series of IBM Research AI’s grand challenges, following Deep Blue and Watson. It has been developed for over six years by a large team of researchers and engineers, and its live demonstration in February 2019 received massive media attention. This research effort has resulted in more than 50 scientific papers to date, and many datasets freely available for research purposes. We discuss the scientific challenges that arise when building such a system, including argument mining, argument quality assessment, stance classification, principled argument detection, narrative generation, and rebutting a human opponent. Many of the underlying capabilities of Project Debater have been made freely available for academic research, and the tutorial will include a detailed explanation of how to use and leverage these tools. In addition to discussing individual components, the tutorial also provides a holistic view of a debating system. Such a view is largely missing in the academic literature, where each paper typically addresses a specific problem in isolation. We present a complete pipeline of a debating system, and discuss the information flow and the interaction between the various components. Finally, we discuss practical applications and future challenges of debating technologies.
This tutorial targets researchers and practitioners who are interested in AI technologies that help machines understand natural language text, particularly real-world events described in the text. These include methods to extract the internal structures of an event regarding its protagonist(s), participant(s) and properties, as well as external structures concerning memberships, temporal and causal relations of multiple events. This tutorial will provide audience with a systematic introduction of (i) knowledge representations of events, (ii) various methods for automated extraction, conceptualization and prediction of events and their relations, (iii) induction of event processes and properties, and (iv) a wide range of NLU and commonsense understanding tasks that benefit from aforementioned techniques. We will conclude the tutorial by outlining emerging research problems in this area.
Deep learning based natural language processing (NLP) has become the mainstream of research in recent years and significantly outperforms conventional methods. However, deep learning models are notorious for being data and computation hungry. These downsides limit the application of such models from deployment to different domains, languages, countries, or styles, since collecting in-genre data and model training from scratch are costly. The long-tail nature of human language makes challenges even more significant. Meta-learning, or ‘Learning to Learn’, aims to learn better learning algorithms, including better parameter initialization, optimization strategy, network architecture, distance metrics, and beyond. Meta-learning has been shown to allow faster fine-tuning, converge to better performance, and achieve amazing results for few-shot learning in many applications. Meta-learning is one of the most important new techniques in machine learning in recent years. There is a related tutorial in ICML 2019 and a related course at Stanford, but most of the example applications given in these materials are about image processing. It is believed that meta-learning has great potential to be applied in NLP, and some works have been proposed with notable achievements in several relevant problems, e.g., relation extraction, machine translation, and dialogue generation and state tracking. However, it does not catch the same level of attention as in the image processing community. In the tutorial, we will first introduce Meta-learning approaches and the theory behind them, and then review the works of applying this technology to NLP problems. This tutorial intends to facilitate researchers in the NLP community to understand this new technology better and promote more research studies using this new technology.
This tutorial provides a comprehensive guide to make the most of pre-training for neural machine translation. Firstly, we will briefly introduce the background of NMT, pre-training methodology, and point out the main challenges when applying pre-training for NMT. Then we will focus on analysing the role of pre-training in enhancing the performance of NMT, how to design a better pre-training model for executing specific NMT tasks and how to better integrate the pre-trained model into NMT system. In each part, we will provide examples, discuss training techniques and analyse what is transferred when applying pre-training.
Prosody is essential in human interaction, enabling people to show interest, establish rapport, efficiently convey nuances of attitude or intent, and so on. Some applications that exploit prosodic knowledge have recently shown superhuman performance, and in many respects our ability to effectively model prosody is rapidly advancing. This tutorial will overview the computational modeling of prosody, including recent advances and diverse actual and potential applications.
How information is created, shared and consumed has changed rapidly in recent decades, in part thanks to new social platforms and technologies on the web. With ever-larger amounts of unstructured and limited labels, organizing and reconciling information from different sources and modalities is a central challenge in machine learning. This cutting-edge tutorial aims to introduce the multimodal entailment task, which can be useful for detecting semantic alignments when a single modality alone does not suffice for a whole content understanding. Starting with a brief overview of natural language processing, computer vision, structured data and neural graph learning, we lay the foundations for the multimodal sections to follow. We then discuss recent multimodal learning literature covering visual, audio and language streams, and explore case studies focusing on tasks which require fine-grained understanding of visual and linguistic semantics question answering, veracity and hatred classification. Finally, we introduce a new dataset for recognizing multimodal entailment, exploring it in a hands-on collaborative section. Overall, this tutorial gives an overview of multimodal learning, introduces a multimodal entailment dataset, and encourages future research in the topic.
Where have we been, and where are we going? It is easier to talk about the past than the future. These days, benchmarks evolve more bottom up (such as papers with code). There used to be more top-down leadership from government (and industry, in the case of systems, with benchmarks such as SPEC). Going forward, there may be more top-down leadership from organizations like MLPerf and/or influencers like David Ferrucci, who was responsible for IBM’s success with Jeopardy, and has recently written a paper suggesting how the community should think about benchmarking for machine comprehension. Tasks such as reading comprehension become even more interesting as we move beyond English. Multilinguality introduces many challenges, and even more opportunities.
NLP models struggle with generalization due to sampling and annotator bias. This paper focuses on a different kind of bias that has received very little attention: guideline bias, i.e., the bias introduced by how our annotator guidelines are formulated. We examine two recently introduced dialogue datasets, CCPE-M and Taskmaster-1, both collected by trained assistants in a Wizard-of-Oz set-up. For CCPE-M, we show how a simple lexical bias for the word like in the guidelines biases the data collection. This bias, in effect, leads to poor performance on data without this bias: a preference elicitation architecture based on BERT suffers a 5.3% absolute drop in performance, when like is replaced with a synonymous phrase, and a 13.2% drop in performance when evaluated on out-of-sample data. For Taskmaster-1, we show how the order in which instructions are resented, biases the data collection.
Evaluation is of paramount importance in data-driven research fields such as Natural Language Processing (NLP) and Computer Vision (CV). Current evaluation practice largely hinges on the existence of a single “ground truth” against which we can meaningfully compare the prediction of a model. However, this comparison is flawed for two reasons. 1) In many cases, more than one answer is correct. 2) Even where there is a single answer, disagreement among annotators is ubiquitous, making it difficult to decide on a gold standard. We argue that the current methods of adjudication, agreement, and evaluation need serious reconsideration. Some researchers now propose to minimize disagreement and to fix datasets. We argue that this is a gross oversimplification, and likely to conceal the underlying complexity. Instead, we suggest that we need to better capture the sources of disagreement to improve today’s evaluation practice. We discuss three sources of disagreement: from the annotator, the data, and the context, and show how this affects even seemingly objective tasks. Datasets with multiple annotations are becoming more common, as are methods to integrate disagreement into modeling. The logical next step is to extend this to evaluation.
The applications of automatic speech recognition (ASR) systems are proliferating, in part due to recent significant quality improvements. However, as recent work indicates, even state-of-the-art speech recognition systems – some which deliver impressive benchmark results, struggle to generalize across use cases. We review relevant work, and, hoping to inform future benchmark development, outline a taxonomy of speech recognition use cases, proposed for the next generation of ASR benchmarks. We also survey work on metrics, in addition to the de facto standard Word Error Rate (WER) metric, and we introduce a versatile framework designed to describe interactions between linguistic variation and ASR performance metrics.
This workshop is the fourth issue of a series of workshops on automatic extraction of socio-political events from news, organized by the Emerging Market Welfare Project, with the support of the Joint Research Centre of the European Commission and with contributions from many other prominent scholars in this field. The purpose of this series of workshops is to foster research and development of reliable, valid, robust, and practical solutions for automatically detecting descriptions of socio-political events, such as protests, riots, wars and armed conflicts, in text streams. This year workshop contributors make use of the state-of-the-art NLP technologies, such as Deep Learning, Word Embeddings and Transformers and cover a wide range of topics from text classification to news bias detection. Around 40 teams have registered and 15 teams contributed to three tasks that are i) multilingual protest news detection detection, ii) fine-grained classification of socio-political events, and iii) discovering Black Lives Matter protest events. The workshop also highlights two keynote and four invited talks about various aspects of creating event data sets and multi- and cross-lingual machine learning in few- and zero-shot settings.
Event extraction is a challenging and exciting task in the world of machine learning & natural language processing. The breadth of events of possible interest, the speed at which surrounding socio-political event contexts evolve, and the complexities involved in generating representative annotated data all contribute to this challenge. One particular dimension of difficulty is the intrinsically global nature of events: many downstream use cases for event extraction involve reporting not just in a few major languages but in a much broader context. The languages of interest for even a fixed task may still shift from day to day, e.g. when a disease emerges in an unexpected location. Early approaches to multi-lingual event extraction (e.g. ACE) relied wholly on supervised data provided in each language of interest. Later approaches leveraged the success of machine translation to side-step the issue, simply translating foreign-language content to English and deploying English models on the result (often leaving some significant portion of the original content behind). Most recently, however, the community has begun to shown significant progress applying zero-shot transfer techniques to the problem, developing models using supervised English data but decoding in a foreign language without translation, typically using embedding spaces specifically designed to capture multi-lingual semantic content. In this talk I will discuss multiple dimensions of these promising new approaches and the linguistic representations that underlie them. I will compare them with approaches based on machine translation (as well as with models trained using in-language training data, where available), and discuss their strengths and weaknesses in different contexts, including the amount of English/foreign bitext available and the nature of the target event ontology. I will also discuss possible future directions with an eye to improving the quality of event extraction no matter its source around the globe.
Advances in machine learning are nothing short of revolutionary in their potential to analyze massive amounts of data and in doing so, create new knowledge bases. But there is a responsibility in wielding the power to analyze these data since the public attributes a high degree of confidence to results which are based on big datasets. In this keynote, I will first address our ethical imperative as scholars to “get it right.” This imperative relates not only to model precision but also to the quality of the underlying data, and to whether the models inadvertently reproduce or obscure political biases in the source material. In considering the ethical imperative to get it right, it is also important to define what is “right”: what is considered an acceptable threshold for classification success needs to be understood in light of the project’s objectives. I then reflect on the different topics and data which are sourced in this field. Much of the existing research has focused on identifying conflict events (e.g. battles), but scholars are also increasingly turning to ML approaches to address other facets of the conflict environment. Conflict event extraction has long been a challenge for the natural language processing (NLP) community because it requires sophisticated methods for defining event ontologies, creating language resources, and developing algorithmic approaches. NLP machine-learning tools are ill-adapted to the complex, often messy, and diverse data generated during conflicts. Relative to other types of NLP text corpora, conflicts tend to generate less textual data, and texts are generated non-systematically. Conflict-related texts are often lexically idiosyncratic and tend to be written differently across actors, periods, and conflicts. Event definition and adjudication present tough challenges in the context of conflict corpora. Topics which rely on other types of data may be better-suited to NLP and machine learning methods. For example, Twitter and other social media data lend themselves well to studying hate speech, public opinion, social polarization, or discursive aspects of conflictual environments. Likewise, government-produced policy documents have typically been analyzed with historical, qualitative methods but their standardized formats and quantity suggest that ML methods can provide new traction. ML approaches may also allow scholars to exploit local sources and multi-language sources to a greater degree than has been possible. Many challenges remain, and these are best addressed in collaborative projects which build on interdisciplinary expertise. Classification projects need to be anchored in the theoretical interests of scholars of political violence if the data they produce are to be put to analytical use. There are few ontologies for classification that adequately reflect conflict researchers’ interests, which highlights the need for conceptual as well as technical development.
We analyze the effect of further retraining BERT with different domain specific data as an unsupervised domain adaptation strategy for event extraction. Portability of event extraction models is particularly challenging, with large performance drops affecting data on the same text genres (e.g., news). We present PROTEST-ER, a retrained BERT model for protest event extraction. PROTEST-ER outperforms a corresponding generic BERT on out-of-domain data of 8.1 points. Our best performing models reach 51.91-46.39 F1 across both domains.
Most of the existing information extraction frameworks (Wadden et al., 2019; Veysehet al., 2020) focus on sentence-level tasks and are hardly able to capture the consolidated information from a given document. In our endeavour to generate precise document-level information frames from lengthy textual records, we introduce the task of Information Aggregation or Argument Aggregation. More specifically, our aim is to filter irrelevant and redundant argument mentions that were extracted at a sentence level and render a document level information frame. Majority of the existing works have been observed to resolve related tasks of document-level event argument extraction (Yang et al., 2018; Zheng et al., 2019) and salient entity identification (Jain et al., 2020) using supervised techniques. To remove dependency from large amounts of labelled data, we explore the task of information aggregation using weakly supervised techniques. In particular, we present an extractive algorithm with multiple sieves which adopts active learning strategies to work efficiently in low-resource settings. For this task, we have annotated our own test dataset comprising of 131 document information frames and have released the code and dataset to further research prospects in this new domain. To the best of our knowledge, we are the first to establish baseline results for this task in English. Our data and code are publicly available at https://github.com/DebanjanaKar/ArgFuse.
Language provides speakers with a rich system of modality for expressing thoughts about events, without being committed to their actual occurrence. Modality is commonly used in the political news domain, where both actual and possible courses of events are discussed. NLP systems struggle with these semantic phenomena, often incorrectly extracting events which did not happen, which can lead to issues in downstream applications. We present an open-domain, lexicon-based event extraction system that captures various types of modality. This information is valuable for Question Answering, Knowledge Graph construction and Fact-checking tasks, and our evaluation shows that the system is sufficiently strong to be used in downstream applications.
We apply statistical techniques from natural language processing to a collection of Western and Hong Kong–based English-language newspaper articles spanning the years 1998–2020, studying the difference and evolution of its portrayal. We observe that both content and attitudes differ between Western and Hong Kong–based sources. ANOVA on keyword frequencies reveals that Hong Kong–based papers discuss protests and democracy less often. Topic modeling detects salient aspects of protests and shows that Hong Kong–based papers made fewer references to police violence during the Anti–Extradition Law Amendment Bill Movement. Diachronic shifts in word embedding neighborhoods reveal a shift in the characterization of salient keywords once the Movement emerged. Together, these raise questions about the existence of anodyne reporting from Hong Kong–based media. Likewise, they illustrate the importance of sample selection for protest event analysis.
Text data are an important source of detailed information about social and political events. Automated systems parse large volumes of text data to infer or extract structured information that describes actors, actions, dates, times, and locations. One of these sub-tasks is geocoding: predicting the geographic coordinates associated with events or locations described by a given text. I present an end-to-end probabilistic model for geocoding text data. Additionally, I collect a novel data set for evaluating the performance of geocoding systems. I compare the model-based solution, called ELECTRo-map, to the current state-of-the-art open source system for geocoding texts for event data. Finally, I discuss the benefits of end-to-end model-based geocoding, including principled uncertainty estimation and the ability of these models to leverage contextual information.
Incidents in industries have huge social and political impact and minimizing the consequent damage has been a high priority. However, automated analysis of repositories of incident reports has remained a challenge. In this paper, we focus on automatically extracting events from incident reports. Due to absence of event annotated datasets for industrial incidents we employ a transfer learning based approach which is shown to outperform several baselines. We further provide detailed analysis regarding effect of increase in pre-training data and provide explainability of why pre-training improves the performance.
The dynamics and influence of fake news on Twitter during the 2020 US presidential election remains to be clarified. Here, we use a dataset related to 2020 U.S Election that consists of news articles and tweets on those articles. Therefore, it is extremely important to stop the spread of fake news before it reaches a mass level, which is a big challenge. We propose a novel fake news detection framework that can address this challenge. Our proposed framework exploits the information from news articles and social contexts to detect fake news. The proposed model is based on a Transformer architecture, which can learn useful representations from fake news data and predicts the probability of a news as being fake or real. Experimental results on real-world data show that our model can detect fake news with higher accuracy and much earlier, compared to the baselines.
Benchmarking state-of-the-art text classification and information extraction systems in multilingual, cross-lingual, few-shot, and zero-shot settings for socio-political event information collection is achieved in the scope of the shared task Socio-political and Crisis Events Detection at the workshop CASE @ ACL-IJCNLP 2021. Socio-political event data is utilized for national and international policy- and decision-making. Therefore, the reliability and validity of these datasets are of the utmost importance. We split the shared task into three parts to address the three aspects of data collection (Task 1), fine-grained semantic classification (Task 2), and evaluation (Task 3). Task 1, which is the focus of this report, is on multilingual protest news detection and comprises four subtasks that are document classification (subtask 1), sentence classification (subtask 2), event sentence coreference identification (subtask 3), and event extraction (subtask 4). All subtasks had English, Portuguese, and Spanish for both training and evaluation data. Data in Hindi language was available only for the evaluation of subtask 1. The majority of the submissions, which are 238 in total, are created using multi- and cross-lingual approaches. Best scores are above 77.27 F1-macro for subtask 1, above 85.32 F1-macro for subtask 2, above 84.23 CoNLL 2012 average score for subtask 3, and above 66.20 F1-macro for subtask 4 in all evaluation settings. The performance of the best system for subtask 4 is above 66.20 F1 for all available languages. Although there is still a significant room for improvement in cross-lingual and zero-shot settings, the best submissions for each evaluation scenario yield remarkable results. Monolingual models outperformed the multilingual models in a few evaluation scenarios.
The aim of the CASE 2021 Shared Task 1 was to detect and classify socio-political and crisis event information at document, sentence, cross-sentence, and token levels in a multilingual setting, with each of these subtasks being evaluated separately in each test language. Our submission contained entries in all of the subtasks, and the scores obtained validated our research finding : That the multilingual element of the tasks should be embraced, so that modeling and training regimes use the multilingual nature of the tasks to their mutual benefit, rather than trying to tackle the different languages separately.
In a world abounding in constant protests resulting from events like a global pandemic, climate change, religious or political conflicts, there has always been a need to detect events/protests before getting amplified by news media or social media. This paper demonstrates our work on the sentence classification subtask of multilingual protest detection in CASE@ACL-IJCNLP 2021. We approached this task by employing various multilingual pre-trained transformer models to classify if any sentence contains information about an event that has transpired or not. We performed soft voting over the models, achieving the best results among the models, accomplishing a macro F1-Score of 0.8291, 0.7578, and 0.7951 in English, Spanish, and Portuguese, respectively.
Event Sentence Coreference Identification (ESCI) aims to cluster event sentences that refer to the same event together for information extraction. We describe our ESCI solution developed for the ACL-CASE 2021 shared tasks on the detection and classification of socio-political and crisis event information in a multilingual setting. For a given article, our proposed pipeline comprises of an accurate sentence pair classifier that identifies coreferent sentence pairs and subsequently uses these predicted probabilities to cluster sentences into groups. Sentence pair representations are constructed from fine-tuned BERT embeddings plus POS embeddings fed through a BiLSTM model, and combined with linguistic-based lexical and semantic similarities between sentences. Our best models ranked 2nd, 1st and 2nd and obtained CoNLL F1 scores of 81.20%, 93.03%, 83.15% for the English, Portuguese and Spanish test sets respectively in the ACL-CASE 2021 competition.
In this paper we present multiple approaches for event detection on document and sentence level, as well as a technique for event sentence co-reference resolution. The advantage of our co-reference resolution approach, which handles the task as a clustering problem, is that we use a single neural net to solve the task, which stands in contrast to other clustering algorithms that often are build on more complex models. This means that we can set our focus on the optimization of a single neural network instead of having to optimize numerous different parameters. We use small densely connected neural networks and pre-trained multilingual transformer embeddings in all subtasks. We use either document or sentence embeddings, depending on the task, and refrain from using word embeddings, so that the implementation of complicated network structures and unfolding of RNNs, which can deal with input of different sizes, is not necessary. We achieved an average macro F1 of 0.65 in subtask 1 (i.e., document level classification), and a macro F1 of 0.70 in subtask 2 (i.e., sentence level classification). For the co-reference resolution subtask, we achieved an average CoNLL-2012 score across all languages of 0.83.
Automatic socio-political and crisis event detection has been a challenge for natural language processing as well as social and political science communities, due to the diversity and nuance in such events and high accuracy requirements. In this paper, we propose an approach which can handle both document and cross-sentence level event detection in a multilingual setting using pretrained transformer models. Our approach became the winning solution in document level predictions and secured the 3rd place in cross-sentence level predictions for the English language. We could also achieve competitive results for other languages to prove the effectiveness and universality of our approach.
This paper summarizes our group’s efforts in the multilingual protest news detection shared task, which is organized as a part of the Challenges and Applications of Automated Extraction of Socio-political Events from Text (CASE) Workshop. We participated in all four subtasks in English. Especially in the identification of event containing sentences task, our proposed ensemble approach using RoBERTa and multichannel CNN-LexStem model yields higher performance. Similarly in the event extraction task, our transformer-LSTM-CRF architecture outperforms regular transformers significantly.
In this paper, we present the event detection models and systems we have developed for Multilingual Protest News Detection - Shared Task 1 at CASE 2021. The shared task has 4 subtasks which cover event detection at different granularity levels (from document level to token level) and across multiple languages (English, Hindi, Portuguese and Spanish). To handle data from multiple languages, we use a multilingual transformer-based language model (XLM-R) as the input text encoder. We apply a variety of techniques and build several transformer-based models that perform consistently well across all the subtasks and languages. Our systems achieve an average F_1 score of 81.2. Out of thirteen subtask-language tracks, our submissions rank 1st in nine and 2nd in four tracks.
We participated CASE shared task in ACL-IJCNLP 2021. This paper is a summary of our experiments and ideas about this shared task. For each subtask we shared our approach, successful and failed methods and our thoughts about them. We submit our results once for every subtask, except for subtask3, in task submission system and present scores based on our validation set formed from given training samples in this paper. Techniques and models we mentioned includes BERT, Multilingual BERT, oversampling, undersampling, data augmentation and their implications with each other. Most of the experiments we came up with were not completed, as time did not permit, but we share them here as we plan to do them as suggested in the future work part of document.
An ever-increasing amount of text, in the form of social media posts and news articles, gives rise to new challenges and opportunities for the automatic extraction of socio-political events. In this paper, we present our submission to the Shared Tasks on Socio-Political and Crisis Events Detection, Task 1, Multilingual Protest News Detection, Subtask 2, Event Sentence Classification, of CASE @ ACL-IJCNLP 2021. In our submission, we utilize the RoBERTa model with additional pretraining, and achieve the best F1 score of 0.8532 in event sentence classification in English and the second-best F1 score of 0.8700 in Portuguese via simple translation. We analyze the failure cases of our model. We also conduct an ablation study to show the effect of choosing the right pretrained language model, adding additional training data and data augmentation.
This paper explains our participation in task 1 of the CASE 2021 shared task. This task is about multilingual event extraction from news. We focused on sub-task 4, event information extraction. This sub-task has a small training dataset and we fine-tuned a multilingual BERT to solve this sub-task. We studied the instability problem on the dataset and tried to mitigate it.
This paper accompanies our top-performing submission to the CASE 2021 shared task, which is hosted at the workshop on Challenges and Applications of Automated Extraction of Socio-political Events from Text. Subtasks 1 and 2 of Task 1 concern the classification of newspaper articles and sentences into “conflict” versus “not conflict”-related in four different languages. Our model performs competitively in both subtasks (up to 0.8662 macro F1), obtaining the highest score of all contributions for subtask 1 on Hindi articles (0.7877 macro F1). We describe all experiments conducted with the XLM-RoBERTa (XLM-R) model and report results obtained in each binary classification task. We propose supplementing the original training data with additional data on political conflict events. In addition, we provide an analysis of unigram probability estimates and geospatial references contained within the original training corpus.
This paper describes the Shared Task on Fine-grained Event Classification in News-like Text Snippets. The Shared Task is divided into three sub-tasks: (a) classification of text snippets reporting socio-political events (25 classes) for which vast amount of training data exists, although exhibiting different structure and style vis-a-vis test data, (b) enhancement to a generalized zero-shot learning problem, where 3 additional event types were introduced in advance, but without any training data (‘unseen’ classes), and (c) further extension, which introduced 2 additional event types, announced shortly prior to the evaluation phase. The reported Shared Task focuses on classification of events in English texts and is organized as part of the Workshop on Challenges and Applications of Automated Extraction of Socio-political Events from Text (CASE 2021), co-located with the ACL-IJCNLP 2021 Conference. Four teams participated in the task. Best performing systems for the three aforementioned sub-tasks achieved 83.9%, 79.7% and 77.1% weighted F1 scores respectively.
Supervised models can achieve very high accuracy for fine-grained text classification. In practice, however, training data may be abundant for some types but scarce or even non-existent for others. We propose a hybrid architecture that uses as much labeled data as available for fine-tuning classification models, while also allowing for types with little (few-shot) or no (zero-shot) labeled data. In particular, we pair a supervised text classification model with a Natural Language Inference (NLI) reranking model. The NLI reranker uses a textual representation of target types that allows it to score the strength with which a type is implied by a text, without requiring training data for the types. Experiments show that the NLI model is very sensitive to the choice of textual representation, but can be effective for classifying unseen types. It can also improve classification accuracy for the known types of an already highly accurate supervised model.
We introduce a method for the classification of texts into fine-grained categories of sociopolitical events. This particular method is responsive to all three Subtasks of Task 2, Fine-Grained Classification of Socio-Political Events, introduced at the CASE workshop of ACL-IJCNLP 2021. We frame Task 2 as textual entailment: given an input text and a candidate event class (“query”), the model predicts whether the text describes an event of the given type. The model is able to correctly classify in-sample event types with an average F1-score of 0.74 but struggles with some out-of-sample event types. Despite this, the model shows promise for the zero-shot identification of certain sociopolitical events by achieving an F1-score of 0.52 on one wholly out-of-sample event class.
We present our submission to Task 2 of the Socio-political and Crisis Events Detection Shared Task at the CASE @ ACL-IJCNLP 2021 workshop. The task at hand aims at the fine-grained classification of socio-political events. Our best model was a fine-tuned RoBERTa transformer model using document embeddings. The corpus consisted of a balanced selection of sub-events extracted from the ACLED event dataset. We achieved a macro F-score of 0.923 and a micro F-score of 0.932 during our preliminary experiments on a held-out test set. The same model also performed best on the shared task test data (weighted F-score = 0.83). To analyze the results we calculated the topic compactness of the commonly misclassified events and conducted an error analysis.
Evaluating the state-of-the-art event detection systems on determining spatio-temporal distribution of the events on the ground is performed unfrequently. But, the ability to both (1) extract events “in the wild” from text and (2) properly evaluate event detection systems has potential to support a wide variety of tasks such as monitoring the activity of socio-political movements, examining media coverage and public support of these movements, and informing policy decisions. Therefore, we study performance of the best event detection systems on detecting Black Lives Matter (BLM) events from tweets and news articles. The murder of George Floyd, an unarmed Black man, at the hands of police officers received global attention throughout the second half of 2020. Protests against police violence emerged worldwide and the BLM movement, which was once mostly regulated to the United States, was now seeing activity globally. This shared task asks participants to identify BLM related events from large unstructured data sources, using systems pretrained to extract socio-political events from text. We evaluate several metrics, accessing each system’s ability to identify protest events both temporally and spatially. Results show that identifying daily protest counts is an easier task than classifying spatial and temporal protest trends simultaneously, with maximum performance of 0.745 and 0.210 (Pearson r), respectively. Additionally, all baselines and participant systems suffered from low recall, with a maximum recall of 5.08.
We present the results of Shared Task at Workshop DialDoc 2021 that is focused on document-grounded dialogue and conversational question answering. The primary goal of this Shared Task is to build goal-oriented information-seeking conversation systems that can identify the most relevant knowledge in the associated document for generating agent responses in natural language. It includes two subtasks on predicting agent responses: the first subtask is to predict the grounding text span in the given document for next agent response; the second subtask is to generate agent response in natural language given the context. Many submissions outperform baseline significantly. For the first task, the best-performing system achieved 67.1 Exact Match and 76.3 F1. For the second subtask, the best system achieved 41.1 SacreBLEU and highest rank by human evaluation.
The key challenge of the visual dialog task is how to fuse features from multimodal sources and extract relevant information from dialog history to answer the current query. In this work, we formulate a visual dialog as an information flow in which each piece of information is encoded with the joint visual-linguistic representation of a single dialog round. Based on this formulation, we consider the visual dialog task as a sequence problem consisting of ordered visual-linguistic vectors.For featurization, we use a Dense SymmetricCo-Attention network (Nguyen and Okatani,2018) as a lightweight vison-language joint representation generator to fuse multimodal features (i.e., image and text), yielding better computation and data efficiencies. For inference, we propose two Sequential Dialog Networks (SeqDialN): the first uses LSTM(Hochreiter and Schmidhuber,1997) for information propagation (IP) and the second uses a modified Transformer (Vaswani et al.,2017) for multi-step reasoning (MR). Our architecture separates the complexity of multimodal feature fusion from that of inference, which allows simpler design of the inference engine. On VisDial v1.0 test-std dataset, our best single generative SeqDialN achieves 62.54% NDCG and 48.63% MRR; our ensemble generative SeqDialN achieves 63.78% NDCG and 49.98% MRR, which set a new state-of-the-art generative visual dialog model. We fine-tune discriminative SeqDialN with dense annotations and boost the performance up to 72.41% NDCG and 55.11% MRR. In this work, we discuss the extensive experiments we have conducted to demonstrate the effectiveness of our model components. We also provide visualization for the reasoning process from the relevant conversation rounds and discuss our fine-tuning methods. The code is available at https://github.com/xiaoxiaoheimei/SeqDialN.
Most existing neural network based task-oriented dialog systems follow encoder-decoder paradigm, where the decoder purely depends on the source texts to generate a sequence of words, usually suffering from instability and poor readability. Inspired by the traditional template-based generation approaches, we propose a template-guided hybrid pointer network for knowledge-based task-oriented dialog systems, which retrieves several potentially relevant answers from a pre-constructed domain-specific conversational repository as guidance answers, and incorporates the guidance answers into both the encoding and decoding processes. Specifically, we design a memory pointer network model with a gating mechanism to fully exploit the semantic correlation between the retrieved answers and the ground-truth response. We evaluate our model on four widely used task-oriented datasets, including one simulated and three manually created datasets. The experimental results demonstrate that the proposed model achieves significantly better performance than the state-of-the-art methods over different automatic evaluation metrics.
This paper presents a learning assistant that tests one’s knowledge and gives feedback that helps a person learn at a faster pace. A learning assistant (based on automated question generation) has extensive uses in education, information websites, self-assessment, FAQs, testing ML agents, research, etc. Multiple researchers, and companies have worked on Virtual Assistance, but majorly in English. We built our learning assistant for Telugu language to help with teaching in the mother tongue, which is the most efficient way of learning. Our system is built primarily based on Question Generation in Telugu. Many experiments were conducted on Question Generation in English in multiple ways. We have built the first hybrid machine learning and rule-based solution in Telugu, which proves efficient for short stories or short passages in children’s books. Our work covers the fundamental question forms with question types: adjective, yes/no, adverb, verb, when, where, whose, quotative, and quantitative (how many/how much). We constructed rules for question generation using Part of Speech (POS) tags and Universal Dependency (UD) tags along with linguistic information of the surrounding relevant context of the word. We used keyword matching, multilingual sentence embedding to evaluate the answer. Our system is primarily built on question generation in Telugu, and is also capable of evaluating the user’s answers to the generated questions.
We apply the modular dialog system framework to combine open-domain question answering with a task-oriented dialog system. This meta dialog system can answer questions from Wikipedia and at the same time act as a personal assistant. The aim of this system is to combine the strength of an open-domain question answering system with the conversational power of task-oriented dialog systems. After explaining the technical details of the system, we combined a new dataset out of standard datasets to evaluate the system. We further introduce an evaluation method for this system. Using this method, we compare the performance of the non-modular system with the performance of the modular system and show that the modular dialog system framework is very suitable for this combination of conversational agents and that the performance of each agent decreases only marginally through the modular setting.
Information-seeking dialogue systems, including knowledge identification and response generation, aim to respond to users with fluent, coherent, and informative responses based on users’ needs, which. To tackle this challenge, we utilize data augmentation methods and several training techniques with the pre-trained language models to learn a general pattern of the task and thus achieve promising performance. In DialDoc21 competition, our system achieved 74.95 F1 score and 60.74 Exact Match score in subtask 1, and 37.72 SacreBLEU score in subtask 2. Empirical analysis is provided to explain the effectiveness of our approaches.
We participate in the DialDoc Shared Task sub-task 1 (Knowledge Identification). The task requires identifying the grounding knowledge in form of a document span for the next dialogue turn. We employ two well-known pre-trained language models (RoBERTa and ELECTRA) to identify candidate document spans and propose a metric-based ensemble method for span selection. Our methods include data augmentation, model pre-training/fine-tuning, post-processing, and ensemble. On the submission page, we rank 2nd based on the average of normalized F1 and EM scores used for the final evaluation. Specifically, we rank 2nd on EM and 3rd on F1.
This paper summarizes our entries to both subtasks of the first DialDoc shared task which focuses on the agent response prediction task in goal-oriented document-grounded dialogs. The task is split into two subtasks: predicting a span in a document that grounds an agent turn and generating an agent response based on a dialog and grounding document. In the first subtask, we restrict the set of valid spans to the ones defined in the dataset, use a biaffine classifier to model spans, and finally use an ensemble of different models. For the second sub-task, we use a cascaded model which grounds the response prediction on the predicted span instead of the full document. With these approaches, we obtain significant improvements in both subtasks compared to the baseline.
Retrieving relevant answers from heterogeneous data formats, for given for questions, is a challenging problem. The process of pinpointing relevant information suitable to answer a question is further compounded in large document collections containing documents of substantial length. This paper presents the models designed as part of our submission to the DialDoc21 Shared Task (Document-grounded Dialogue and Conversational Question Answering) for span prediction in question answering. The proposed models leverage the superior predictive power of pretrained transformer models like RoBERTa, ALBERT and ELECTRA, to identify the most relevant information in an associated passage for the next agent turn. To further enhance the performance, the models were fine-tuned on different span selection based question answering datasets like SQuAD2.0 and Natural Questions (NQ) corpus. We also explored ensemble techniques for combining multiple models to achieve enhanced performance for the task. Our team SB_NITK ranked 6th on the leaderboard for the Knowledge Identification task, and our best ensemble model achieved an Exact score of 58.58 and an F1 score of 73.39.
An intelligent dialogue system in a multi-turn setting should not only generate the responses which are of good quality, but it should also generate the responses which can lead to long-term success of the dialogue. Although, the current approaches improved the response quality, but they over-look the training signals present in the dialogue data. We can leverage these signals to generate the weakly supervised training data for learning dialog policy and reward estimator, and make the policy take actions (generates responses) which can foresee the future direction for a successful (rewarding) conversation. We simulate the dialogue between an agent and a user (modelled similar to an agent with supervised learning objective) to interact with each other. The agent uses dynamic blocking to generate ranked diverse responses and exploration-exploitation to select among the Top-K responses. Each simulated state-action pair is evaluated (works as a weak annotation) with three quality modules: Semantic Relevant, Semantic Coherence and Consistent Flow. Empirical studies with two benchmarks indicate that our model can significantly out-perform the response quality and lead to a successful conversation on both automatic evaluation and human judgment.
Users frequently ask simple factoid questions for question answering (QA) systems, attenuating the impact of myriad recent works that support more complex questions. Prompting users with automatically generated suggested questions (SQs) can improve user understanding of QA system capabilities and thus facilitate more effective use. We aim to produce self-explanatory questions that focus on main document topics and are answerable with variable length passages as appropriate. We satisfy these requirements by using a BERT-based Pointer-Generator Network trained on the Natural Questions (NQ) dataset. Our model shows SOTA performance of SQ generation on the NQ dataset (20.1 BLEU-4). We further apply our model on out-of-domain news articles, evaluating with a QA system due to the lack of gold questions and demonstrate that our model produces better SQs for news articles – with further confirmation via a human evaluation.
Document-grounded goal-oriented dialog system understands users’ utterances, and generates proper responses by using information obtained from documents. The Dialdoc21 shared task consists of two subtasks; subtask1, finding text spans associated with users’ utterances from documents, and subtask2, generating responses based on information obtained from subtask1. In this paper, we propose two models (i.e., a knowledge span prediction model and a response generation model) for the subtask1 and the subtask2. In the subtask1, dialogue act losses are used with RoBERTa, and title embeddings are added to input representation of RoBERTa. In the subtask2, various special tokens and embeddings are added to input representation of BART’s encoder. Then, we propose a method to assign different difficulty scores to leverage curriculum learning. In the subtask1, our span prediction model achieved F1-scores of 74.81 (ranked at top 7) and 73.41 (ranked at top 5) in test-dev phase and test phase, respectively. In the subtask2, our response generation model achieved sacreBLEUs of 37.50 (ranked at top 3) and 41.06 (ranked at top 1) in in test-dev phase and test phase, respectively.
In this paper, we discuss our submission for DialDoc subtask 1. The subtask requires systems to extract knowledge from FAQ-type documents vital to reply to a user’s query in a conversational setting. We experiment with pretraining a BERT-based question-answering model on different QA datasets from MRQA, as well as conversational QA datasets like CoQA and QuAC. Our results show that models pretrained on CoQA and QuAC perform better than their counterparts that are pretrained on MRQA datasets. Our results also indicate that adding more pretraining data does not necessarily result in improved performance. Our final model, which is an ensemble of AlBERT-XL pretrained on CoQA and QuAC independently, with the chosen answer having the highest average probability score, achieves an F1-Score of 70.9% on the official test-set.
In this paper, we describe our systems for solving the two Doc2Dial shared task: knowledge identification and response generation. We proposed several pre-processing and post-processing methods, and we experimented with data augmentation by pre-training the models on other relevant datasets. Our best model for knowledge identification outperformed the baseline by 10.5+ f1-score on the test-dev split, and our best model for response generation outperformed the baseline by 11+ Sacrebleu score on the test-dev split.
In this work, we draw parallels between automatically responding to emails for combating social-engineering attacks and document-grounded response generation and lay out the blueprint of our approach. Phishing emails are longer than dialogue utterances and often contain multiple intents. Hence, we need to make decisions similar to those for document-grounded responses in deciding what parts of long text to use and how to address each intent to generate a knowledgeable multi-component response that pushes scammers towards agendas that aid in attribution and linking attacks. We propose , a hybrid system that uses customizable probabilistic finite state transducers to orchestrate pushing agendas coupled with neural dialogue systems that generate responses to unexpected prompts, as a promising solution to this end. We emphasize the need for this system by highlighting each component’s strengths and weaknesses and show how they complement each other.
Most prior work on task-oriented dialogue systems are restricted to limited coverage of domain APIs. However, users oftentimes have requests that are out of the scope of these APIs. This work focuses on responding to these beyond-API-coverage user turns by incorporating external, unstructured knowledge sources. Our approach works in a pipelined manner with knowledge-seeking turn detection, knowledge selection, and response generation in sequence. We introduce novel data augmentation methods for the first two steps and demonstrate that the use of information extracted from dialogue context improves the knowledge selection and end-to-end performances. Through experiments, we achieve state-of-the-art performance for both automatic and human evaluation metrics on the DSTC9 Track 1 benchmark dataset, validating the effectiveness of our contributions.
Word embeddings (e.g., word2vec) have been applied successfully to eCommerce products through prod2vec. Inspired by the recent performance improvements on several NLP tasks brought by contextualized embeddings, we propose to transfer BERT-like architectures to eCommerce: our model - Prod2BERT - is trained to generate representations of products through masked session modeling. Through extensive experiments over multiple shops, different tasks, and a range of design choices, we systematically compare the accuracy of Prod2BERT and prod2vec embeddings: while Prod2BERT is found to be superior in several scenarios, we highlight the importance of resources and hyperparameters in the best performing models. Finally, we provide guidelines to practitioners for training embeddings under a variety of computational and data constraints.
Identifying the value of product attribute is essential for many e-commerce functions such as product search and product recommendations. Therefore, identifying attribute values from unstructured product descriptions is a critical undertaking for any e-commerce retailer. What makes this problem challenging is the diversity of product types and their attributes and values. Existing methods have typically employed multiple types of machine learning models, each of which handles specific product types or attribute classes. This has limited their scalability and generalization for large scale real world e-commerce applications. Previous approaches for this task have formulated the attribute value extraction as a Named Entity Recognition (NER) task or a Question Answering (QA) task. In this paper we have presented a generative approach to the attribute value extraction problem using language models. We leverage the large-scale pretraining of the GPT-2 and the T5 text-to-text transformer to create fine-tuned models that can effectively perform this task. We show that a single general model is very effective for this task over a broad set of product attribute values with the open world assumption. Our approach achieves state-of-the-art performance for different attribute classes, which has previously required a diverse set of models.
Automatic Speech Recognition (ASR) robustness toward slot entities are critical in e-commerce voice assistants that involve monetary transactions and purchases. Along with effective domain adaptation, it is intuitive that cross utterance contextual cues play an important role in disambiguating domain specific content words from speech. In this paper, we investigate various techniques to improve contextualization, content word robustness and domain adaptation of a Transformer-XL neural language model (NLM) to rescore ASR N-best hypotheses. To improve contextualization, we utilize turn level dialogue acts along with cross utterance context carry over. Additionally, to adapt our domain-general NLM towards e-commerce on-the-fly, we use embeddings derived from a finetuned masked LM on in-domain data. Finally, to improve robustness towards in-domain content words, we propose a multi-task model that can jointly perform content word detection and language modeling tasks. Compared to a non-contextual LSTM LM baseline, our best performing NLM rescorer results in a content WER reduction of 19.2% on e-commerce audio test set and a slot labeling F1 improvement of 6.4%.
User satisfaction estimation in the dialogue-based customer service is critical not only for helping developers find the system defects, but also making it possible to get timely human intervention for dissatisfied customers. In this paper, we investigate the problem of user satisfaction estimation in E-commerce customer service. In order to apply the estimator to online services for timely human intervention, we need to estimate the satisfaction score at each turn. However, in actual scenario we can only collect the satisfaction labels for the whole dialogue sessions via user feedback. To this end, we formalize the turn-level satisfaction estimation as a reinforcement learning problem, in which the model can be optimized with only session-level satisfaction labels. We conduct experiments on the dataset collected from a commercial customer service system, and compare our model with the supervised learning models. Extensive experiments show that the proposed method outperforms all the baseline models.
Keyword augmentation is a fundamental problem for sponsored search modeling and business. Machine generated keywords can be recommended to advertisers for better campaign discoverability as well as used as features for sourcing and ranking models. Generating high-quality keywords is difficult, especially for cold campaigns with limited or even no historical logs; and the industry trend of including multiple products in a single ad campaign is making the problem more challenging. In this paper, we propose a keyword augmentation method based on generative seq2seq model and trie-based search mechanism, which is able to generate high-quality keywords for any products or product lists. We conduct human annotations, offline analysis, and online experiments to evaluate the performance of our method against benchmarks in terms of augmented keyword quality as well as lifted ad exposure. The experiment results demonstrate that our method is able to generate more valid keywords which can serve as an efficient addition to advertiser selected keywords.
The growing popularity of Virtual Assistants poses new challenges for Entity Resolution, the task of linking mentions in text to their referent entities in a knowledge base. Specifically, in the shopping domain, customers tend to mention the entities implicitly (e.g., “organic milk”) rather than use the entity names explicitly, leading to a large number of candidate products. Meanwhile, for the same query, different customers may expect different results. For example, with “add milk to my cart”, a customer may refer to a certain product from his/her favorite brand, while some customers may want to re-order products they regularly purchase. Moreover, new customers may lack persistent shopping history, which requires us to enrich the connections between customers through products and their attributes. To address these issues, we propose a new framework that leverages personalized features to improve the accuracy of product ranking. We first build a cross-source heterogeneous knowledge graph from customer purchase history and product knowledge graph to jointly learn customer and product embeddings. After that, we incorporate product, customer, and history representations into a neural reranking model to predict which candidate is most likely to be purchased by a specific customer. Experiment results show that our model substantially improves the accuracy of the top ranked candidates by 24.6% compared to the state-of-the-art product search model.
In the area of customer support, understanding customers’ intents is a crucial step. Machine learning plays a vital role in this type of intent classification. In reality, it is typical to collect confirmation from customer support representatives (CSRs) regarding the intent prediction, though it can unnecessarily incur prohibitive cost to ask CSRs to assign existing or new intents to the mis-classified cases. Apart from the confirmed cases with and without intent labels, there can be a number of cases with no human curation. This data composition (Positives + Unlabeled + multiclass Negatives) creates unique challenges for model development. In response to that, we propose a semi-supervised multi-task learning paradigm. In this manuscript, we share our experience in building text-based intent classification models for a customer support service on an E-commerce website. We improve the performance significantly by evolving the model from multiclass classification to semi-supervised multi-task learning by leveraging the negative cases, domain- and task-adaptively pretrained ALBERT on customer contact texts, and a number of un-curated data with no labels. In the evaluation, the final model boosts the average AUC ROC by almost 20 points compared to the baseline finetuned multiclass classification ALBERT model.
With the growing footprint of ecommerce worldwide, the role of contact center is becoming increasingly crucial for customer satisfaction. To effectively handle scale and manage operational cost, automation through chat-bots and voice-bots are getting rapidly adopted. With customers having multiple, often long list of active orders - the first task of a voice-bot is to identify which one they are calling about. Towards solving this problem which we refer to as order identification, we propose a two-staged real-time technique by combining search and prediction in a sequential manner. In the first stage, analogous to retrieval-based question-answering, a fuzzy search technique uses customized textual similarity measures on noisy transcripts of calls to retrieve the order of interest. The coverage of fuzzy search is limited by no or limited response from customers to voice prompts. Hence, in the second stage, a predictive solution that predict the most likely order a customer is calling about based on certain features of orders is introduced. We compare with multiple relevant techniques based on word embeddings as well as ecommerce product search to show that the proposed approach provides the best performance with 64% coverage and 87% accuracy on a large real-life data-set. A system based on the proposed technique is also deployed in production for a fraction of calls landing in the contact center of a large ecommerce provider; providing real evidence of operational benefits as well as increased customer delight.
Fake reviews and review manipulation are growing problems on online marketplaces globally. Review Hijacking is a new review manipulation tactic in which unethical sellers “hijack” an existing product page (usually one with many positive reviews), then update the product details like title, photo, and description with those of an entirely different product. With the earlier reviews still attached, the new item appears well-reviewed. So far, little knowledge about hijacked reviews has resulted in little academic research and an absence of labeled data. Hence, this paper proposes a three-part study: (i) we propose a framework to generate synthetically labeled data for review hijacking by swapping products and reviews; (ii) then, we evaluate the potential of both a Siamese LSTM network and BERT sequence pair classifier to distinguish legitimate reviews from hijacked ones using this data; and (iii) we then deploy the best performing model on a collection of 31K products (with 6.5 M reviews) in the original data, where we find 100s of previously unknown examples of review hijacking.
Automatic extraction of product attribute-value pairs from unstructured text like product descriptions is an important problem for e-commerce companies. The attribute schema typically varies from one category of products (which will be referred as vertical) to another. This leads to extreme annotation efforts for training of supervised deep sequence labeling models such as LSTM-CRF, and consequently not enough labeled data for some vertical-attribute pairs. In this work, we propose a technique for alleviating this problem by using annotated data from related verticals in a multi-task learning framework. Our approach relies on availability of similar attributes (labels) in another related vertical. Our model jointly learns the similarity between attributes of the two verticals along with the model parameters for the sequence tagging model. The main advantage of our approach is that it does not need any prior annotation of attribute similarity. Our system has been tested with datasets of size more than 10000 from a large e-commerce company in India. We perform detailed experiments to show that our method indeed increases the macro-F1 scores for attribute value extraction in general, and for labels with low training data in particular. We also report top labels from other verticals that contribute towards learning of particular labels.
Large-scale unsupervised abstractive summarization is sorely needed to automatically scan millions of customer reviews in today’s fast-paced e-commerce landscape. We address a key challenge in unsupervised abstractive summarization – reducing generic and uninformative content and producing useful information that relates to specific product aspects. To do so, we propose to model reviews in the context of some topical classes of interest. In particular, for any arbitrary set of topical classes of interest, the proposed model can learn to generate a set of class-specific summaries from multiple reviews of each product without ground-truth summaries, and the only required signal is class probabilities or class label for each review. The model combines a generative variational autoencoder, with an integrated class-correlation gating mechanism and a hierarchical structure capturing dependence among products, reviews and classes. Human evaluation shows that generated summaries are highly relevant, fluent, and representative. Evaluation using a reference dataset shows that our model outperforms state-of-the-art abstractive and extractive baselines.
In this paper, we present SANTA, a scalable framework to automatically normalize E-commerce attribute values (e.g. “Win 10 Pro”) to a fixed set of pre-defined canonical values (e.g. “Windows 10”). Earlier works on attribute normalization focused on fuzzy string matching (also referred as syntactic matching in this paper). In this work, we first perform an extensive study of nine syntactic matching algorithms and establish that ‘cosine’ similarity leads to best results, showing 2.7% improvement over commonly used Jaccard index. Next, we show that string similarity alone is not sufficient for attribute normalization as many surface forms require going beyond syntactic matching (e.g. “720p” and “HD” are synonyms). While semantic techniques like unsupervised embeddings (e.g. word2vec/fastText) have shown good results in word similarity tasks, we observed that they perform poorly to distinguish between close canonical forms, as these close forms often occur in similar contexts. We propose to learn token embeddings using a twin network with triplet loss. We propose an embedding learning task leveraging raw attribute values and product titles to learn these embeddings in a self-supervised fashion. We show that providing supervision using our proposed task improves over both syntactic and unsupervised embeddings based techniques for attribute normalization. Experiments on a real-world dataset of 50 attributes show that the embeddings trained using our proposed approach obtain 2.3% improvement over best string similarity and 19.3% improvement over best unsupervised embeddings.
The Transformer has proven to be a powerful feature extraction method and has gained widespread adoption in natural language processing (NLP). In this paper we propose a multimodal item categorization (MIC) system solely based on the Transformer for both text and image processing. On a multimodal product data set collected from a Japanese e-commerce giant, we tested a new image classification model based on the Transformer and investigated different ways of fusing bi-modal information. Our experimental results on real industry data showed that the Transformer-based image classifier has performance on par with ResNet-based classifiers and is four times faster to train. Furthermore, a cross-modal attention layer was found to be critical for the MIC system to achieve performance gains over text-only and image-only models.
In this paper, we explored different levels of textual representations for cross-lingual information retrieval. Beyond the traditional token level representation, we adopted the subword and character level representations for information retrieval that had shown to improve neural machine translation by reducing the out-of-vocabulary issues in machine translation. We found that crosslingual information retrieval performance can be improved by combining search results from subwords and token level representation.Additionally, we improved the search performance by combining and re-ranking the result sets from the different text representations for German, French and Japanese.
With the rapid growth of online video streaming, recent years have seen increasing concerns about profane language in their content. Detecting profane language in streaming services is challenging due to the long sentences appeared in a video. While recent research on handling long sentences has focused on developing deep learning modeling techniques, little work has focused on techniques on improving data pipelines. In this work, we develop a data collection pipeline to address long sequence of texts and integrate this pipeline with a multi-head self-attention model. With this pipeline, our experiments show the self-attention model offers 12.5% relative accuracy improvement over state-of-the-art distilBERT model on profane language detection while requiring only 3% of parameters. This research designs a better system for informing users of profane language in video streaming services.
We carry out a case study on the use of data programming to create data to train classifiers used for product moderation on a large e-commerce platform. Data programming is a recently-introduced technique that uses human-defined rules to generate training data sets without tedious item-by-item hand labeling. Our study investigates methods for allowing product moderators to quickly modify the rules given their knowledge of the domain and, especially, of textual item descriptions. Our results show promise that moderators can use this approach to steer the training data, making possible fast and close control of classifiers that detect policy violations.
Aspect extraction is not a well-explored topic in Hindi, with only one corpus having been developed for the task. In this paper, we discuss the merits of the existing corpus in terms of quality, size, sparsity, and performance in aspect extraction tasks using established models. To provide a better baseline corpus for aspect extraction, we translate the SemEval 2014 aspect-based sentiment analysis dataset and annotate the aspects in that data. We provide rigorous guidelines and a replicable methodology for this task. We quantitatively evaluate the translations and annotations using inter-annotator agreement scores. We also evaluate our dataset using state-of-the-art neural aspect extraction models in both monolingual and multilingual settings and show that the models perform far better on our corpus than on the existing Hindi dataset. With this, we establish our corpus as the gold-standard aspect extraction dataset in Hindi.
The accuracy of an online shopping system via voice commands is particularly important and may have a great impact on customer trust. This paper focuses on the problem of detecting if an utterance contains actual and purchasable products, thus referring to a shopping-related intent in a typical Spoken Language Understanding architecture consist- ing of an intent classifier and a slot detec- tor. Searching through billions of products to check if a detected slot is a purchasable item is prohibitively expensive. To overcome this problem, we present a framework that (1) uses a retrieval module that returns the most rele- vant products with respect to the detected slot, and (2) combines it with a twin network that decides if the detected slot is indeed a pur- chasable item or not. Through various exper- iments, we show that this architecture outper- forms a typical slot detector approach, with a gain of +81% in accuracy and +41% in F1 score.
E-commerce stores collect customer feedback to let sellers learn about customer concerns and enhance customer order experience. Because customer feedback often contains redundant information, a concise summary of the feedback can be generated to help sellers better understand the issues causing customer dissatisfaction. Previous state-of-the-art abstractive text summarization models make two major types of factual errors when producing summaries from customer feedback, which are wrong entity detection (WED) and incorrect product-defect description (IPD). In this work, we introduce a set of methods to enhance the factual consistency of abstractive summarization on customer feedback. We augment the training data with artificially corrupted summaries, and use them as counterparts of the target summaries. We add a contrastive loss term into the training objective so that the model learns to avoid certain factual errors. Evaluation results show that a large portion of WED and IPD errors are alleviated for BART and T5. Furthermore, our approaches do not depend on the structure of the summarization model and thus are generalizable to any abstractive summarization systems.
We improve customer experience and gain their trust when their issues are resolved rapidly with less friction. Existing work has focused on reducing the overall case resolution time by binning a case into predefined categories and routing it to the desired support engineer. However, the actions taken by the engineer during case analysis and resolution are altogether ignored, even though it forms the bulk of the case resolution time. In this work, we propose two systems that enable support engineers to resolve cases faster. The first, a guidance extraction model, mines historical cases and provides technical guidance phrases to the support engineers. The phrases can then be used to educate the customer or to obtain critical information needed to resolve the case and thus minimize the number of correspondences between the engineer and customer. The second, a summarization model, creates an abstractive summary of the case to provide better context to the support engineer. Through quantitative evaluation we obtain an F1 score of 0.64 on the guidance extraction model and a BertScore (F1) of 0.55 on the summarization model.
Reviews written by the users for a particular product or service play an influencing role for the customers to make an informative decision. Although online e-commerce portals have immensely impacted our lives, available contents predominantly are in English language- often limiting its widespread usage. There is an exponential growth in the number of e-commerce users who are not proficient in English. Hence, there is a necessity to make these services available in non-English languages, especially in a multilingual country like India. This can be achieved by an in-domain robust machine translation (MT) system. However, the reviews written by the users pose unique challenges to MT, such as misspelled words, ungrammatical constructions, presence of colloquial terms, lack of resources such as in-domain parallel corpus etc. We address the above challenges by presenting an English–Hindi review domain parallel corpus. We train an English–to–Hindi neural machine translation (NMT) system to translate the product reviews available on e-commerce websites. By training the Transformer based NMT model over the generated data, we achieve a score of 33.26 BLEU points for English–to–Hindi translation. In order to make our NMT model robust enough to handle the noisy tokens in the reviews, we integrate a character based language model to generate word vectors and map the noisy tokens with their correct forms. Experiments on four language pairs, viz. English-Hindi, English-German, English-French, and English-Czech show the BLUE scores of 35.09, 28.91, 34.68 and 14.52 which are the improvements of 1.61, 1.05, 1.63 and 1.94, respectively, over the baseline.
Languages differ in terms of the absence or presence of gender features, the number of gender classes and whether and where gender features are explicitly marked. These cross-linguistic differences can lead to ambiguities that are difficult to resolve, especially for sentence-level MT systems. The identification of ambiguity and its subsequent resolution is a challenging task for which currently there aren’t any specific resources or challenge sets available. In this paper, we introduce gENder-IT, an English–Italian challenge set focusing on the resolution of natural gender phenomena by providing word-level gender tags on the English source side and multiple gender alternative translations, where needed, on the Italian target side.
Gender bias in word embeddings gradually becomes a vivid research field in recent years. Most studies in this field aim at measurement and debiasing methods with English as the target language. This paper investigates gender bias in static word embeddings from a unique perspective, Chinese adjectives. By training word representations with different models, the gender bias behind the vectors of adjectives is assessed. Through a comparison between the produced results and a human scored data set, we demonstrate how gender bias encoded in word embeddings differentiates from people’s attitudes.
With language models being deployed increasingly in the real world, it is essential to address the issue of the fairness of their outputs. The word embedding representations of these language models often implicitly draw unwanted associations that form a social bias within the model. The nature of gendered languages like Hindi, poses an additional problem to the quantification and mitigation of bias, owing to the change in the form of the words in the sentence, based on the gender of the subject. Additionally, there is sparse work done in the realm of measuring and debiasing systems for Indic languages. In our work, we attempt to evaluate and quantify the gender bias within a Hindi-English machine translation system. We implement a modified version of the existing TGBI metric based on the grammatical considerations for Hindi. We also compare and contrast the resulting bias measurements across multiple metrics for pre-trained embeddings and the ones learned by our machine translation model.
Technology companies have produced varied responses to concerns about the effects of the design of their conversational AI systems. Some have claimed that their voice assistants are in fact not gendered or human-like—despite design features suggesting the contrary. We compare these claims to user perceptions by analysing the pronouns they use when referring to AI assistants. We also examine systems’ responses and the extent to which they generate output which is gendered and anthropomorphic. We find that, while some companies appear to be addressing the ethical concerns raised, in some cases, their claims do not seem to hold true. In particular, our results show that system outputs are ambiguous as to the humanness of the systems, and that users tend to personify and gender them as a result.
Gender inequality represents a considerable loss of human potential and perpetuates a culture of violence, higher gender wage gaps, and a lack of representation of women in higher and leadership positions. Applications powered by Artificial Intelligence (AI) are increasingly being used in the real world to provide critical decisions about who is going to be hired, granted a loan, admitted to college, etc. However, the main pillars of AI, Natural Language Processing (NLP) and Machine Learning (ML) have been shown to reflect and even amplify gender biases and stereotypes, which are mainly inherited from historical training data. In an effort to facilitate the identification and mitigation of gender bias in English text, we develop a comprehensive taxonomy that relies on the following gender bias types: Generic Pronouns, Sexism, Occupational Bias, Exclusionary Bias, and Semantics. We also provide a bottom-up overview of gender bias, from its societal origin to its spillover onto language. Finally, we link the societal implications of gender bias to their corresponding type(s) in the proposed taxonomy. The underlying motivation of our work is to help enable the technical community to identify and mitigate relevant biases from training corpora for improved fairness in NLP systems.
We analyze 6.7 million case law documents to determine the presence of gender bias within our judicial system. We find that current bias detection methods in NLP are insufficient to determine gender bias in our case law database and propose an alternative approach. We show that existing algorithms’ inconsistent results are consequences of prior research’s inconsistent definitions of biases themselves. Bias detection algorithms rely on groups of words to represent bias (e.g., ‘salary,’ ‘job,’ and ‘boss’ to represent employment as a potentially biased theme against women in text). However, the methods to build these groups of words have several weaknesses, primarily that the word lists are based on the researchers’ own intuitions. We suggest two new methods of automating the creation of word lists to represent biases. We find that our methods outperform current NLP bias detection methods. Our research improves the capabilities of NLP technology to detect bias and highlights gender biases present in influential case law. In order to test our NLP bias detection method’s performance, we regress our results of bias in case law against U.S census data of women’s participation in the workforce in the last 100 years.
Classifiers tend to propagate biases present in the data on which they are trained. Hence, it is important to understand how the demographic identities of the annotators of comments affect the fairness of the resulting model. In this paper, we focus on the differences in the ways men and women annotate comments for toxicity, investigating how these differences result in models that amplify the opinions of male annotators. We find that the BERT model associates toxic comments containing offensive words with male annotators, causing the model to predict 67.7% of toxic comments as having been annotated by men. We show that this disparity between gender predictions can be mitigated by removing offensive words and highly toxic comments from the training data. We then apply the learned associations between gender and language to toxic language classifiers, finding that models trained exclusively on female-annotated data perform 1.8% better than those trained solely on male-annotated data, and that training models on data after removing all offensive words reduces bias in the model by 55.5% while increasing the sensitivity by 0.4%.
In this work we explore the effect of incorporating demographic metadata in a text classifier trained on top of a pre-trained transformer language model. More specifically, we add information about the gender of critics and book authors when classifying the polarity of book reviews, and the polarity of the reviews when classifying the genders of authors and critics. We use an existing data set of Norwegian book reviews with ratings by professional critics, which has also been augmented with gender information, and train a document-level sentiment classifier on top of a recently released Norwegian BERT-model. We show that gender-informed models obtain substantially higher accuracy, and that polarity-informed models obtain higher accuracy when classifying the genders of book authors. For this particular data set, we take this result as a confirmation of the gender bias in the underlying label distribution, but in other settings we believe a similar approach can be used for mitigating bias in the model.
Potential gender biases existing in Wikipedia’s content can contribute to biased behaviors in a variety of downstream NLP systems. Yet, efforts in understanding what inequalities in portraying women and men occur in Wikipedia focused so far only on *biographies*, leaving open the question of how often such harmful patterns occur in other topics. In this paper, we investigate gender-related asymmetries in Wikipedia titles from *all domains*. We assess that for only half of gender-related articles, i.e., articles with words such as *women* or *male* in their titles, symmetrical counterparts describing the same concept for the other gender (and clearly stating it in their titles) exist. Among the remaining imbalanced cases, the vast majority of articles concern sports- and social-related issues. We provide insights on how such asymmetries can influence other Wikipedia components and propose steps towards reducing the frequency of observed patterns.
In this paper we question the impact of gender representation in training data on the performance of an end-to-end ASR system. We create an experiment based on the Librispeech corpus and build 3 different training corpora varying only the proportion of data produced by each gender category. We observe that if our system is overall robust to the gender balance or imbalance in training data, it is nonetheless dependant of the adequacy between the individuals present in the training and testing sets.
Gender bias is a frequent occurrence in NLP-based applications, especially pronounced in gender-inflected languages. Bias can appear through associations of certain adjectives and animate nouns with the natural gender of referents, but also due to unbalanced grammatical gender frequencies of inflected words. This type of bias becomes more evident in generating conversational utterances where gender is not specified within the sentence, because most current NLP applications still work on a sentence-level context. As a step towards more inclusive NLP, this paper proposes an automatic and generalisable re-writing approach for short conversational sentences. The rewriting method can be applied to sentences that, without extra-sentential context, have multiple equivalent alternatives in terms of gender. The method can be applied both for creating gender balanced outputs as well as for creating gender balanced training data. The proposed approach is based on a neural machine translation system trained to ‘translate’ from one gender alternative to another. Both the automatic and manual analysis of the approach show promising results with respect to the automatic generation of gender alternatives for conversational sentences in Spanish.
We observe an instance of gender-induced bias in a downstream application, despite the absence of explicit gender words in the test cases. We provide a test set, SoWinoBias, for the purpose of measuring such latent gender bias in coreference resolution systems. We evaluate the performance of current debiasing methods on the SoWinoBias test set, especially in reference to the method’s design and altered embedding space properties. See https://github.com/hillary-dawkins/SoWinoBias.
Sentence-level text simplification is currently evaluated using both automated metrics and human evaluation. For automatic evaluation, a combination of metrics is usually employed to evaluate different aspects of the simplification. Flesch-Kincaid Grade Level (FKGL) is one metric that has been regularly used to measure the readability of system output. In this paper, we argue that FKGL should not be used to evaluate text simplification systems. We provide experimental analyses on recent system output showing that the FKGL score can easily be manipulated to improve the score dramatically with only minor impact on other automated metrics (BLEU and SARI). Instead of using FKGL, we suggest that the component statistics, along with others, be used for posthoc analysis to understand system behavior.
We ask subjects whether they perceive as human-produced a bunch of texts, some of which are actually human-written, while others are automatically generated. We use this data to fine-tune a GPT-2 model to push it to generate more human-like texts, and observe that this fine-tuned model produces texts that are indeed perceived more human-like than the original model. Contextually, we show that our automatic evaluation strategy well correlates with human judgements. We also run a linguistic analysis to unveil the characteristics of human- vs machine-perceived language.
ROUGE is a widely used evaluation metric in text summarization. However, it is not suitable for the evaluation of abstractive summarization systems as it relies on lexical overlap between the gold standard and the generated summaries. This limitation becomes more apparent for agglutinative languages with very large vocabularies and high type/token ratios. In this paper, we present semantic similarity models for Turkish and apply them as evaluation metrics for an abstractive summarization task. To achieve this, we translated the English STSb dataset into Turkish and presented the first semantic textual similarity dataset for Turkish as well. We showed that our best similarity models have better alignment with average human judgments compared to ROUGE in both Pearson and Spearman correlations.
The MultiWOZ dataset (Budzianowski et al.,2018) is frequently used for benchmarkingcontext-to-response abilities of task-orienteddialogue systems. In this work, we identifyinconsistencies in data preprocessing and re-porting of three corpus-based metrics used onthis dataset, i.e., BLEU score and Inform &Success rates. We point out a few problemsof the MultiWOZ benchmark such as unsat-isfactory preprocessing, insufficient or under-specified evaluation metrics, or rigid database.We re-evaluate 7 end-to-end and 6 policy opti-mization models in as-fair-as-possible setups,and we show that their reported scores cannotbe directly compared. To facilitate compari-son of future systems, we release our stand-alone standardized evaluation scripts. We alsogive basic recommendations for corpus-basedbenchmarking in future works.
Personalized response generation is essential for more human-like conversations. However, how to model user personalization information with no explicit user persona descriptions or demographics still remains under-investigated. To tackle the data sparsity problem and the huge number of users, we utilize tensor factorization to model users’ personalization information with their posting histories. Specifically, we introduce the personalized response embedding for all question-user pairs and form them into a three-mode tensor, decomposed by Tucker decomposition. The personalized response embedding is fed to either the decoder of an LSTM-based Seq2Seq model or a transformer language model to help generate more personalized responses. To evaluate how personalized the generated responses are, we further propose a novel ranking-based metric called Per-Hits@k which measures how likely are the generated responses come from the corresponding users. Results on a large-scale conversation dataset show that our proposed tensor factorization based models generate more personalized and higher quality responses compared to baselines.
This paper reviews and summarizes human evaluation practices described in 97 style transfer papers with respect to three main evaluation aspects: style transfer, meaning preservation, and fluency. In principle, evaluations by human raters should be the most reliable. However, in style transfer papers, we find that protocols for human evaluations are often underspecified and not standardized, which hampers the reproducibility of research in this field and progress toward better human and automatic evaluation methods.
We propose an approach to automatically test for originality in generation tasks where no standard automatic measures exist. Our proposal addresses original uses of language, not necessarily original ideas. We provide an algorithm for our approach and a run-time analysis. The algorithm, which finds all of the original fragments in a ground-truth corpus and can reveal whether a generated fragment copies an original without attribution, has a run-time complexity of theta(nlogn) where n is the number of sentences in the ground truth.
We present an end-to-end neural approach to generate English sentences from formal meaning representations, Discourse Representation Structures (DRSs). We use a rather standard bi-LSTM sequence-to-sequence model, work with a linearized DRS input representation, and evaluate character-level and word-level decoders. We obtain very encouraging results in terms of reference-based automatic metrics such as BLEU. But because such metrics only evaluate the surface level of generated output, we develop a new metric, ROSE, that targets specific semantic phenomena. We do this with five DRS generation challenge sets focusing on tense, grammatical number, polarity, named entities and quantities. The aim of these challenge sets is to assess the neural generator’s systematicity and generalization to unseen inputs.
We survey human evaluation in papers presenting work on creative natural language generation that have been published in INLG 2020 and ICCC 2020. The most typical human evaluation method is a scaled survey, typically on a 5 point scale, while many other less common methods exist. The most commonly evaluated parameters are meaning, syntactic correctness, novelty, relevance and emotional value, among many others. Our guidelines for future evaluation include clearly defining the goal of the generative system, asking questions as concrete as possible, testing the evaluation setup, using multiple different evaluation setups, reporting the entire evaluation process and potential biases clearly, and finally analyzing the evaluation results in a more profound way than merely reporting the most typical statistics.
We introduce GEM, a living benchmark for natural language Generation (NLG), its Evaluation, and Metrics. Measuring progress in NLG relies on a constantly evolving ecosystem of automated metrics, datasets, and human evaluation standards. Due to this moving target, new models often still evaluate on divergent anglo-centric corpora with well-established, but flawed, metrics. This disconnect makes it challenging to identify the limitations of current models and opportunities for progress. Addressing this limitation, GEM provides an environment in which models can easily be applied to a wide set of tasks and in which evaluation strategies can be tested. Regular updates to the benchmark will help NLG research become more multilingual and evolve the challenge alongside models. This paper serves as the description of the data for the 2021 shared task at the associated GEM Workshop.
Developing documentation guidelines and easy-to-use templates for datasets and models is a challenging task, especially given the variety of backgrounds, skills, and incentives of the people involved in the building of natural language processing (NLP) tools. Nevertheless, the adoption of standard documentation practices across the field of NLP promotes more accessible and detailed descriptions of NLP datasets and models, while supporting researchers and developers in reflecting on their work. To help with the standardization of documentation, we present two case studies of efforts that aim to develop reusable documentation templates – the HuggingFace data card, a general purpose card for datasets in NLP, and the GEM benchmark data and model cards with a focus on natural language generation. We describe our process for developing these templates, including the identification of relevant stakeholder groups, the definition of a set of guiding principles, the use of existing templates as our foundation, and iterative revisions based on feedback.
We explore the use of self-training and acceptability classifiers with pre-trained models for natural language generation in structure-to-text settings using three GEM datasets (E2E, WebNLG-en, Schema-Guided Dialog). With the Schema-Guided Dialog dataset, we also experiment with including multiple turns of context in the input. We find that self-training with reconstruction matching along with acceptability classifier filtering can improve semantic correctness, though gains are limited in the full-data setting. With context-conditioning, we find that including multiple turns in the context encourages the model to align with the user’s word and phrasing choices as well as to generate more self-consistent responses. In future versions of the GEM challenge, we encourage the inclusion of few-shot tracks to encourage research on data efficiency.
This paper describes the submission by NUIG-DSI to the GEM benchmark 2021. We participate in the modeling shared task where we submit outputs on four datasets for data-to-text generation, namely, DART, WebNLG (en), E2E and CommonGen. We follow an approach similar to the one described in the GEM benchmark paper where we use the pre-trained T5-base model for our submission. We train this model on additional monolingual data where we experiment with different masking strategies specifically focused on masking entities, predicates and concepts as well as a random masking strategy for pre-training. In our results we find that random masking performs the best in terms of automatic evaluation metrics, though the results are not statistically significantly different compared to other masking strategies.
This paper describes SimpleNER, a model developed for the sentence simplification task at GEM-2021. Our system is a monolingual Seq2Seq Transformer architecture that uses control tokens pre-pended to the data, allowing the model to shape the generated simplifications according to user desired attributes. Additionally, we show that NER-tagging the training data before use helps stabilize the effect of the control tokens and significantly improves the overall performance of the system. We also employ pretrained embeddings to reduce data sparsity and allow the model to produce more generalizable outputs.
In a current experiment we were testing CommonGen dataset for structure-to-text task from GEM living benchmark with the constraint based POINTER model. POINTER represents a hybrid architecture, combining insertion-based and transformer paradigms, predicting the token and the insertion position at the same time. The text is therefore generated gradually in a parallel non-autoregressive manner, given the set of keywords. The pretrained model was fine-tuned on a training split of the CommonGen dataset and the generation result was compared to the validation and challenge splits. The received metrics outputs, which measure lexical equivalence, semantic similarity and diversity, are discussed in details in a present system description.
Narrative generation is an open-ended NLP task in which a model generates a story given a prompt. The task is similar to neural response generation for chatbots; however, innovations in response generation are often not applied to narrative generation, despite the similarity between these tasks. We aim to bridge this gap by applying and evaluating advances in decoding methods for neural response generation to neural narrative generation. In particular, we employ GPT-2 and perform ablations across nucleus sampling thresholds and diverse decoding hyperparameters—specifically, maximum mutual information—analyzing results over multiple criteria with automatic and human evaluation. We find that (1) nucleus sampling is generally best with thresholds between 0.7 and 0.9; (2) a maximum mutual information objective can improve the quality of generated stories; and (3) established automatic metrics do not correlate well with human judgments of narrative quality on any qualitative metric.
Biases and artifacts in training data can cause unwelcome behavior in text classifiers (such as shallow pattern matching), leading to lack of generalizability. One solution to this problem is to include users in the loop and leverage their feedback to improve models. We propose a novel explanatory debugging pipeline called HILDIF, enabling humans to improve deep text classifiers using influence functions as an explanation method. We experiment on the Natural Language Inference (NLI) task, showing that HILDIF can effectively alleviate artifact problems in fine-tuned BERT models and result in increased model generalizability.
We investigate the question of how adaptive feedback from a virtual agent impacts the linguistic input of the user in a shared world game environment. To do so, we carry out an exploratory pilot study to observe how individualized linguistic feedback affects the user’s speech input. We introduce a speech-controlled game, Apple Core-dination, in which an agent learns complex tasks using a base knowledge of simple actions. The agent is equipped with a learning mechanism for mapping new commands to sequences of simple actions, as well as the ability to incorporate user input into written responses. The agent repeatedly shares its internal knowledge state by responding to what it knows and does not know about language meaning and the shared environment. Our paper focuses on the linguistic feedback loop in order to analyze the nature of user input. Feedback from the agent is provided in the form of visual movement and written linguistic responses. Particular attention is given to incorporating user input into agent responses and updating the speech-to-action mappings based on commands provided by the user. Through our pilot study, we analyze task success and compare the lexical features of user input. Results show variation in input length and lexical variety across users, suggesting a correlation between the two that can be studied further.
We investigate if a model can learn natural language with minimal linguistic input through interaction. Addressing this question, we design and implement an interactive language learning game that learns logical semantic representations compositionally. Our game allows us to explore the benefits of logical inference for natural language learning. Evaluation shows that the model can accurately narrow down potential logical representations for words over the course of the game, suggesting that our model is able to learn lexical mappings from scratch successfully.
Timeline Summarisation (TLS) aims to generate a concise, time-ordered list of events described in sources such as news articles. However, current systems do not provide an adequate way to adapt to new domains nor to focus on the aspects of interest to a particular user. Therefore, we propose a method for interactively learning abstractive TLS using Reinforcement Learning (RL). We define a compound reward function and use RL to fine-tune an abstractive Multi-document Summarisation (MDS) model, which avoids the need to train using reference summaries. One of the sub-reward functions will be learned interactively from user feedback to ensure the consistency between users’ demands and the generated timeline. The other sub-reward functions contribute to topical coherence and linguistic fluency. We plan experiments to evaluate whether our approach could generate accurate and precise timelines tailored for each user.
Dynamic faceted search (DFS), an interactive query refinement technique, is a form of Human–computer information retrieval (HCIR) approach. It allows users to narrow down search results through facets, where the facets-documents mapping is determined at runtime based on the context of user query instead of pre-indexing the facets statically. In this paper, we propose a new unsupervised approach for dynamic facet generation, namely optimistic facets, which attempts to generate the best possible subset of facets, hence maximizing expected Discounted Cumulative Gain (DCG), a measure of ranking quality that uses a graded relevance scale. We also release code to generate a new evaluation dataset. Through empirical results on two datasets, we show that the proposed DFS approach considerably improves the document ranking in the search results.
This paper investigates and reveals the relationship between two closely related machine learning disciplines, namely Active Learning (AL) and Curriculum Learning (CL), from the lens of several novel curricula. This paper also introduces Active Curriculum Learning (ACL) which improves AL by combining AL with CL to benefit from the dynamic nature of the AL informativeness concept as well as the human insights used in the design of the curriculum heuristics. Comparison of the performance of ACL and AL on two public datasets for the Named Entity Recognition (NER) task shows the effectiveness of combining AL and CL using our proposed framework.
Easy access, variety of content, and fast widespread interactions are some of the reasons that have made social media increasingly popular in today’s society. However, this has also enabled the widespread propagation of fake news, text that is published with an intent to spread misinformation and sway beliefs. Detecting fake news is important to prevent misinformation and maintain a healthy society. While prior works have tackled this problem by building supervised learning systems, automatedly modeling the social media landscape that enables the spread of fake news is challenging. On the contrary, having humans fact check all news is not scalable. Thus, in this paper, we propose to approach this problem interactively, where human insight can be continually combined with an automated system, enabling better social media representation quality. Our experiments show performance improvements in this setting.
When learned without exploration, local models for structured prediction tasks are subject to exposure bias and cannot be trained without detailed guidance. Active Imitation Learning (AIL), also known in NLP as Dynamic Oracle Learning, is a general technique for working around these issues by allowing the exploration of different outputs at training time. AIL requires oracle feedback: an oracle is any algorithm which can, given a partial candidate solution and gold annotation, find the correct (minimum loss) next output to produce. This paper describes a general finite state technique for deriving oracles. The technique describe is also efficient and will greatly expand the tasks for which AIL can be used.
In this paper, we present the first statistical parser for Lambek categorial grammar (LCG), a grammatical formalism for which the graphical proof method known as *proof nets* is applicable. Our parser incorporates proof net structure and constraints into a system based on self-attention networks via novel model elements. Our experiments on an English LCG corpus show that incorporating term graph structure is helpful to the model, improving both parsing accuracy and coverage. Moreover, we derive novel loss functions by expressing proof net constraints as differentiable functions of our model output, enabling us to train our parser without ground-truth derivations.
The Reading Machine, is a parsing framework that takes as input raw text and performs six standard nlp tasks: tokenization, pos tagging, morphological analysis, lemmatization, dependency parsing and sentence segmentation. It is built upon Transition Based Parsing, and allows to implement a large number of parsing configurations, among which a fully incremental one. Three case studies are presented to highlight the versatility of the framework. The first one explores whether an incremental parser is able to take into account top-down dependencies (i.e. the influence of high level decisions on low level ones), the second compares the performances of an incremental and a pipe-line architecture and the third quantifies the impact of the right context on the predictions made by an incremental parser.
Strong and affordable in-domain data is a desirable asset when transferring trained semantic parsers to novel domains. As previous methods for semi-automatically constructing such data cannot handle the complexity of realistic SQL queries, we propose to construct SQL queries via context-dependent sampling, and introduce the concept of topic. Along with our SQL query construction method, we propose a novel pipeline of semi-automatic Text-to-SQL dataset construction that covers the broad space of SQL queries. We show that the created dataset is comparable with expert annotation along multiple dimensions, and is capable of improving domain transfer performance for SOTA semantic parsers.
Coupled with biaffine decoders, transformers have been effectively adapted to text-to-graph transduction and achieved state-of-the-art performance on AMR parsing. Many prior works, however, rely on the biaffine decoder for either or both arc and label predictions although most features used by the decoder may be learned by the transformer already. This paper presents a novel approach to AMR parsing by combining heterogeneous data (tokens, concepts, labels) as one input to a transformer to learn attention, and use only attention matrices from the transformer to predict all elements in AMR graphs (concepts, arcs, labels). Although our models use significantly fewer parameters than the previous state-of-the-art graph parser, they show similar or better accuracy on AMR 2.0 and 3.0.
In cross-lingual Abstract Meaning Representation (AMR) parsing, researchers develop models that project sentences from various languages onto their AMRs to capture their essential semantic structures: given a sentence in any language, we aim to capture its core semantic content through concepts connected by manifold types of semantic relations. Methods typically leverage large silver training data to learn a single model that is able to project non-English sentences to AMRs. However, we find that a simple baseline tends to be overlooked: translating the sentences to English and projecting their AMR with a monolingual AMR parser (translate+parse,T+P). In this paper, we revisit this simple two-step base-line, and enhance it with a strong NMT system and a strong AMR parser. Our experiments show that T+P outperforms a recent state-of-the-art system across all tested languages: German, Italian, Spanish and Mandarin with +14.6, +12.6, +14.3 and +16.0 Smatch points
Broad-coverage meaning representations in NLP mostly focus on explicitly expressed content. More importantly, the scarcity of datasets annotating diverse implicit roles limits empirical studies into their linguistic nuances. For example, in the web review “Great service!”, the provider and consumer are implicit arguments of different types. We examine an annotated corpus of fine-grained implicit arguments (Cui and Hershcovich, 2020) by carefully re-annotating it, resolving several inconsistencies. Subsequently, we present the first transition-based neural parser that can handle implicit arguments dynamically, and experiment with two different transition systems on the improved dataset. We find that certain types of implicit arguments are more difficult to parse than others and that the simpler system is more accurate in recovering implicit arguments, despite having a lower overall parsing score, attesting current reasoning limitations of NLP models. This work will facilitate a better understanding of implicit and underspecified language, by incorporating it holistically into meaning representations.
We evaluate the efficacy of predicted UPOS tags as input features for dependency parsers in lower resource settings to evaluate how treebank size affects the impact tagging accuracy has on parsing performance. We do this for real low resource universal dependency treebanks, artificially low resource data with varying treebank sizes, and for very small treebanks with varying amounts of augmented data. We find that predicted UPOS tags are somewhat helpful for low resource treebanks, especially when fewer fully-annotated trees are available. We also find that this positive impact diminishes as the amount of data increases.
This paper describes a methodology for syntactic knowledge transfer between high-resource languages to extremely low-resource languages. The methodology consists in leveraging multilingual BERT self-attention model pretrained on large datasets to develop a multilingual multi-task model that can predict Universal Dependencies annotations for three African low-resource languages. The UD annotations include universal part-of-speech, morphological features, lemmas, and dependency trees. In our experiments, we used multilingual word embeddings and a total of 11 Universal Dependencies treebanks drawn from three high-resource languages (English, French, Norwegian) and three low-resource languages (Bambara, Wolof and Yoruba). We developed various models to test specific language combinations involving contemporary contact languages or genetically related languages. The results of the experiments show that multilingual models that involve high-resource languages and low-resource languages with contemporary contact between each other can provide better results than combinations that only include unrelated languages. As far genetic relationships are concerned, we could not draw any conclusion regarding the impact of language combinations involving the selected low-resource languages, namely Wolof and Yoruba.
Domain adaption in syntactic parsing is still a significant challenge. We address the issue of data imbalance between the in-domain and out-of-domain treebank typically used for the problem. We define domain adaptation as a Multi-task learning (MTL) problem, which allows us to train two parsers, one for each do-main. Our results show that the MTL approach is beneficial for the smaller treebank. For the larger treebank, we need to use loss weighting in order to avoid a decrease in performance be-low the single task. In order to determine towhat degree the data imbalance between two domains and the domain differences affect results, we also carry out an experiment with two imbalanced in-domain treebanks and show that loss weighting also improves performance in an in-domain setting. Given loss weighting in MTL, we can improve results for both parsers.
We review two features of mixture of experts (MoE) models which we call averaging and clustering effects in the context of graph-based dependency parsers learned in a supervised probabilistic framework. Averaging corresponds to the ensemble combination of parsers and is responsible for variance reduction which helps stabilizing and improving parsing accuracy. Clustering describes the capacity of MoE models to give more credit to experts believed to be more accurate given an input. Although promising, this is difficult to achieve, especially without additional data. We design an experimental set-up to study the impact of these effects. Whereas averaging is always beneficial, clustering requires good initialization and stabilization techniques, but its advantages over mere averaging seem to eventually vanish when enough experts are present. As a by product, we show how this leads to state-of-the-art results on the PTB and the CoNLL09 Chinese treebank, with low variance across experiments.
We evaluate three leading dependency parser systems from different paradigms on a small yet diverse subset of languages in terms of their accuracy-efficiency Pareto front. As we are interested in efficiency, we evaluate core parsers without pretrained language models (as these are typically huge networks and would constitute most of the compute time) or other augmentations that can be transversally applied to any of them. Biaffine parsing emerges as a well-balanced default choice, with sequence-labelling parsing being preferable if inference speed (but not training energy cost) is the priority.
The introduction of pre-trained transformer-based contextualized word embeddings has led to considerable improvements in the accuracy of graph-based parsers for frameworks such as Universal Dependencies (UD). However, previous works differ in various dimensions, including their choice of pre-trained language models and whether they use LSTM layers. With the aims of disentangling the effects of these choices and identifying a simple yet widely applicable architecture, we introduce STEPS, a new modular graph-based dependency parser. Using STEPS, we perform a series of analyses on the UD corpora of a diverse set of languages. We find that the choice of pre-trained embeddings has by far the greatest impact on parser performance and identify XLM-R as a robust choice across the languages in our study. Adding LSTM layers provides no benefits when using transformer-based embeddings. A multi-task training setup outputting additional UD features may contort results. Taking these insights together, we propose a simple but widely applicable parser architecture and configuration, achieving new state-of-the-art results (in terms of LAS) for 10 out of 12 diverse languages.
Many neural end-to-end systems today do not rely on syntactic parse trees, as much of the information that parse trees provide is encoded in the parameters of pretrained models. Lessons learned from parsing technologies and from taking a multilingual perspective, however, are still relevant even for end-to-end models. This talk will describe work that relies on compositionality in semantic parsing and in reading comprehension requiring numerical reasoning. We’ll then describe a new dataset that requires advances in multilingual modeling, and some approaches designed to better model morphology than off-the-shelf subword models that make some progress on these challenges.
We describe the second IWPT task on end-to-end parsing from raw text to Enhanced Universal Dependencies. We provide details about the evaluation metrics and the datasets used for training and evaluation. We compare the approaches taken by participating teams and discuss the results of the shared task, also in comparison with the first edition of this task.
We introduce the COMBO-based approach for EUD parsing and its implementation, which took part in the IWPT 2021 EUD shared task. The goal of this task is to parse raw texts in 17 languages into Enhanced Universal Dependencies (EUD). The proposed approach uses COMBO to predict UD trees and EUD graphs. These structures are then merged into the final EUD graphs. Some EUD edge labels are extended with case information using a single language-independent expansion rule. In the official evaluation, the solution ranked fourth, achieving an average ELAS of 83.79%. The source code is available at https://gitlab.clarin-pl.eu/syntactic-tools/combo.
We present the system submission from the FASTPARSE team for the EUD Shared Task at IWPT 2021. We engaged in the task last year by focusing on efficiency. This year we have focused on experimenting with new ideas on a limited time budget. Our system is based on splitting the EUD graph into several trees, based on linguistic criteria. We predict these trees using a sequence-labelling parser and combine them into an EUD graph. The results were relatively poor, although not a total disaster and could probably be improved with some polishing of the system’s rough edges.
This paper describes a system proposed for the IWPT 2021 Shared Task on Parsing into Enhanced Universal Dependencies (EUD). We propose a Graph Rewriting based system for computing Enhanced Universal Dependencies, given the Basic Universal Dependencies (UD).
This paper presents the system used in our submission to the IWPT 2021 Shared Task. This year the official evaluation metrics was ELAS, therefore dependency parsing might have been avoided as well as other pipeline stages like POS tagging and lemmatization. We nevertheless chose to deploy a combination of a dependency parser and a graph parser. The dependency parser is a biaffine parser, that uses transformers for representing input sentences, with no other feature. The graph parser is a semantic parser that exploits a similar architecture except for using a sigmoid crossentropy loss function to return multiple values for the predicted arcs. The final output is obtained by merging the output of the two parsers. The dependency parser achieves top or close to top LAS performance with respect to other systems that report results on such metrics, except on low resource languages (Tamil, Estonian, Latvian).
This paper describe the system used in our submission to the IWPT 2021 Shared Task. Our system is a graph-based parser with the technique of Automated Concatenation of Embeddings (ACE). Because recent work found that better word representations can be obtained by concatenating different types of embeddings, we use ACE to automatically find the better concatenation of embeddings for the task of enhanced universal dependencies. According to official results averaged on 17 languages, our system rank 2nd over 9 teams.
This paper presents our multilingual dependency parsing system as used in the IWPT 2021 Shared Task on Parsing into Enhanced Universal Dependencies. Our system consists of an unfactorized biaffine classifier that operates directly on fine-tuned XLM-R embeddings and generates enhanced UD graphs by predicting the best dependency label (or absence of a dependency) for each pair of tokens. To avoid sparsity issues resulting from lexicalized dependency labels, we replace lexical items in relations with placeholders at training and prediction time, later retrieving them from the parse via a hybrid rule-based/machine-learning system. In addition, we utilize model ensembling at prediction time. Our system achieves high parsing accuracy on the blind test data, ranking 3rd out of 9 with an average ELAS F1 score of 86.97.
We describe the DCU-EPFL submission to the IWPT 2021 Parsing Shared Task: From Raw Text to Enhanced Universal Dependencies. The task involves parsing Enhanced UD graphs, which are an extension of the basic dependency trees designed to be more facilitative towards representing semantic structure. Evaluation is carried out on 29 treebanks in 17 languages and participants are required to parse the data from each language starting from raw strings. Our approach uses the Stanza pipeline to preprocess the text files, XLM-RoBERTa to obtain contextualized token representations, and an edge-scoring and labeling model to predict the enhanced graph. Finally, we run a postprocessing script to ensure all of our outputs are valid Enhanced UD graphs. Our system places 6th out of 9 participants with a coarse Enhanced Labeled Attachment Score (ELAS) of 83.57. We carry out additional post-deadline experiments which include using Trankit for pre-processing, XLM-RoBERTa LARGE, treebank concatenation, and multitask learning between a basic and an enhanced dependency parser. All of these modifications improve our initial score and our final system has a coarse ELAS of 88.04.
We present our contribution to the IWPT 2021 shared task on parsing into enhanced Universal Dependencies. Our main system component is a hybrid tree-graph parser that integrates (a) predictions of spanning trees for the enhanced graphs with (b) additional graph edges not present in the spanning trees. We also adopt a finetuning strategy where we first train a language-generic parser on the concatenation of data from all available languages, and then, in a second step, finetune on each individual language separately. Additionally, we develop our own complete set of pre-processing modules relevant to the shared task, including tokenization, sentence segmentation, and multiword token expansion, based on pre-trained XLM-R models and our own pre-training of character-level language models. Our submission reaches a macro-average ELAS of 89.24 on the test set. It ranks top among all teams, with a margin of more than 2 absolute ELAS over the next best-performing submission, and best score on 16 out of 17 languages.
We describe the NUIG solution for IWPT 2021 Shared Task of Enhanced Dependency (ED) parsing in multiple languages. For this shared task, we propose and evaluate an End-to-end Seq2seq mBERT-based ED parser which predicts the ED-parse tree of a given input sentence as a relative head-position tag-sequence. Our proposed model is a multitasking neural-network which performs five key tasks simultaneously namely UPOS tagging, UFeat tagging, Lemmatization, Dependency-parsing and ED-parsing. Furthermore we utilise the linguistic typology available in the WALS database to improve the ability of our proposed end-to-end parser to transfer across languages. Results show that our proposed Seq2seq ED-parser performs on par with state-of-the-art ED-parser despite having a much simpler de- sign.
The evaluation campaign of the International Conference on Spoken Language Translation (IWSLT 2021) featured this year four shared tasks: (i) Simultaneous speech translation, (ii) Offline speech translation, (iii) Multilingual speech translation, (iv) Low-resource speech translation. A total of 22 teams participated in at least one of the tasks. This paper describes each shared task, data and evaluation metrics, and reports results of the received submissions.
This paper describes USTC-NELSLIP’s submissions to the IWSLT2021 Simultaneous Speech Translation task. We proposed a novel simultaneous translation model, Cross-Attention Augmented Transducer (CAAT), which extends conventional RNN-T to sequence-to-sequence tasks without monotonic constraints, e.g., simultaneous translation. Experiments on speech-to-text (S2T) and text-to-text (T2T) simultaneous translation tasks shows CAAT achieves better quality-latency trade-offs compared to wait-k, one of the previous state-of-the-art approaches. Based on CAAT architecture and data augmentation, we build S2T and T2T simultaneous translation systems in this evaluation campaign. Compared to last year’s optimal systems, our S2T simultaneous translation system improves by an average of 11.3 BLEU for all latency regimes, and our T2T simultaneous translation system improves by an average of 4.6 BLEU.
This paper describes NAIST’s system for the English-to-Japanese Simultaneous Text-to-text Translation Task in IWSLT 2021 Evaluation Campaign. Our primary submission is based on wait-k neural machine translation with sequence-level knowledge distillation to encourage literal translation.
We describe our submission to the IWSLT 2021 shared task on simultaneous text-to-text English-German translation. Our system is based on the re-translation approach where the agent re-translates the whole source prefix each time it receives a new source token. This approach has the advantage of being able to use a standard neural machine translation (NMT) inference engine with beam search, however, there is a risk that incompatibility between successive re-translations will degrade the output. To improve the quality of the translations, we experiment with various approaches: we use a fixed size wait at the beginning of the sentence, we use a language model score to detect translatable units, and we apply dynamic masking to determine when the translation is unstable. We find that a combination of dynamic masking and language model score obtains the best latency-quality trade-off.
This paper describes the offline and simultaneous speech translation systems developed at AppTek for IWSLT 2021. Our offline ST submission includes the direct end-to-end system and the so-called posterior tight integrated model, which is akin to the cascade system but is trained in an end-to-end fashion, where all the cascaded modules are end-to-end models themselves. For simultaneous ST, we combine hybrid automatic speech recognition with a machine translation approach whose translation policy decisions are learned from statistical word alignments. Compared to last year, we improve general quality and provide a wider range of quality/latency trade-offs, both due to a data augmentation method making the MT model robust to varying chunk sizes. Finally, we present a method for ASR output segmentation into sentences that introduces a minimal additional delay.
This paper describes the systems submitted to IWSLT 2021 by the Volctrans team. We participate in the offline speech translation and text-to-text simultaneous translation tracks. For offline speech translation, our best end-to-end model achieves 7.9 BLEU improvements over the benchmark on the MuST-C test set and is even approaching the results of a strong cascade solution. For text-to-text simultaneous translation, we explore the best practice to optimize the wait-k model. As a result, our final submitted systems exceed the benchmark at around 7 BLEU on the same latency regime. We release our code and model to facilitate both future research works and industrial applications.
The paper describes BUT’s English to German offline speech translation (ST) systems developed for IWSLT2021. They are based on jointly trained Automatic Speech Recognition-Machine Translation models. Their performances is evaluated on MustC-Common test set. In this work, we study their efficiency from the perspective of having a large amount of separate ASR training data and MT training data, and a smaller amount of speech-translation training data. Large amounts of ASR and MT training data are utilized for pre-training the ASR and MT models. Speech-translation data is used to jointly optimize ASR-MT models by defining an end-to-end differentiable path from speech to translations. For this purpose, we use the internal continuous representations from the ASR-decoder as the input to MT module. We show that speech translation can be further improved by training the ASR-decoder jointly with the MT-module using large amount of text-only MT training data. We also show significant improvements by training an ASR module capable of generating punctuated text, rather than leaving the punctuation task to the MT module.
This paper describes FBK’s system submission to the IWSLT 2021 Offline Speech Translation task. We participated with a direct model, which is a Transformer-based architecture trained to translate English speech audio data into German texts. The training pipeline is characterized by knowledge distillation and a two-step fine-tuning procedure. Both knowledge distillation and the first fine-tuning step are carried out on manually segmented real and synthetic data, the latter being generated with an MT system trained on the available corpora. Differently, the second fine-tuning step is carried out on a random segmentation of the MuST-C v2 En-De dataset. Its main goal is to reduce the performance drops occurring when a speech translation model trained on manually segmented data (i.e. an ideal, sentence-like segmentation) is evaluated on automatically segmented audio (i.e. actual, more realistic testing conditions). For the same purpose, a custom hybrid segmentation procedure that accounts for both audio content (pauses) and for the length of the produced segments is applied to the test data before passing them to the system. At inference time, we compared this procedure with a baseline segmentation method based on Voice Activity Detection (VAD). Our results indicate the effectiveness of the proposed hybrid approach, shown by a reduction of the gap with manual segmentation from 8.3 to 1.4 BLEU points.
This paper describes the submission of the NiuTrans end-to-end speech translation system for the IWSLT 2021 offline task, which translates from the English audio to German text directly without intermediate transcription. We use the Transformer-based model architecture and enhance it by Conformer, relative position encoding, and stacked acoustic and textual encoding. To augment the training data, the English transcriptions are translated to German translations. Finally, we employ ensemble decoding to integrate the predictions from several models trained with the different datasets. Combining these techniques, we achieve 33.84 BLEU points on the MuST-C En-De test set, which shows the enormous potential of the end-to-end model.
This paper describes the ESPnet-ST group’s IWSLT 2021 submission in the offline speech translation track. This year we made various efforts on training data, architecture, and audio segmentation. On the data side, we investigated sequence-level knowledge distillation (SeqKD) for end-to-end (E2E) speech translation. Specifically, we used multi-referenced SeqKD from multiple teachers trained on different amounts of bitext. On the architecture side, we adopted the Conformer encoder and the Multi-Decoder architecture, which equips dedicated decoders for speech recognition and translation tasks in a unified encoder-decoder model and enables search in both source and target language spaces during inference. We also significantly improved audio segmentation by using the pyannote.audio toolkit and merging multiple short segments for long context modeling. Experimental evaluations showed that each of them contributed to large improvements in translation performance. Our best E2E system combined all the above techniques with model ensembling and achieved 31.4 BLEU on the 2-ref of tst2021 and 21.2 BLEU and 19.3 BLEU on the two single references of tst2021.
This paper describes the submission to the IWSLT 2021 offline speech translation task by the UPC Machine Translation group. The task consists of building a system capable of translating English audio recordings extracted from TED talks into German text. Submitted systems can be either cascade or end-to-end and use a custom or given segmentation. Our submission is an end-to-end speech translation system, which combines pre-trained models (Wav2Vec 2.0 and mBART) with coupling modules between the encoder and decoder, and uses an efficient fine-tuning technique, which trains only 20% of its total parameters. We show that adding an Adapter to the system and pre-training it, can increase the convergence speed and the final result, with which we achieve a BLEU score of 27.3 on the MuST-C test set. Our final model is an ensemble that obtains 28.22 BLEU score on the same set. Our submission also uses a custom segmentation algorithm that employs pre-trained Wav2Vec 2.0 for identifying periods of untranscribable text and can bring improvements of 2.5 to 3 BLEU score on the IWSLT 2019 test set, as compared to the result with the given segmentation.
In this technical report, we describe the fine-tuned ASR-MT pipeline used for the IWSLT shared task. We remove less useful speech samples by checking WER with an ASR model, and further train a wav2vec and Transformers-based ASR module based on the filtered data. In addition, we cleanse the errata that can interfere with the machine translation process and use it for Transformer-based MT module training. Finally, in the actual inference phase, we use a sentence boundary detection model trained with constrained data to properly merge fragment ASR outputs into full sentences. The merged sentences are post-processed using part of speech. The final result is yielded by the trained MT module. The performance using the dev set displays BLEU 20.37, and this model records the performance of BLEU 20.9 with the test set.
This paper describes KIT’submission to the IWSLT 2021 Offline Speech Translation Task. We describe a system in both cascaded condition and end-to-end condition. In the cascaded condition, we investigated different end-to-end architectures for the speech recognition module. For the text segmentation module, we trained a small transformer-based model on high-quality monolingual data. For the translation module, our last year’s neural machine translation model was reused. In the end-to-end condition, we improved our Speech Relative Transformer architecture to reach or even surpass the result of the cascade system.
In this paper, we describe our end-to-end multilingual speech translation system submitted to the IWSLT 2021 evaluation campaign on the Multilingual Speech Translation shared task. Our system is built by leveraging transfer learning across modalities, tasks and languages. First, we leverage general-purpose multilingual modules pretrained with large amounts of unlabelled and labelled data. We further enable knowledge transfer from the text task to the speech task by training two tasks jointly. Finally, our multilingual model is finetuned on speech translation task-specific data to achieve the best translation results. Experimental results show our system outperforms the reported systems, including both end-to-end and cascaded based approaches, by a large margin. In some translation directions, our speech translation results evaluated on the public Multilingual TEDx test set are even comparable with the ones from a strong text-to-text translation system, which uses the oracle speech transcripts as input.
This paper describes Maastricht University’s participation in the IWSLT 2021 multilingual speech translation track. The task in this track is to build multilingual speech translation systems in supervised and zero-shot directions. Our primary system is an end-to-end model that performs both speech transcription and translation. We observe that the joint training for the two tasks is complementary especially when the speech translation data is scarce. On the source and target side, we use data augmentation and pseudo-labels respectively to improve the performance of our systems. We also introduce an ensembling technique that consistently improves the quality of transcriptions and translations. The experiments show that the end-to-end system is competitive with its cascaded counterpart especially in zero-shot conditions.
In this paper, we describe Zhejiang University’s submission to the IWSLT2021 Multilingual Speech Translation Task. This task focuses on speech translation (ST) research across many non-English source languages. Participants can decide whether to work on constrained systems or unconstrained systems which can using external data. We create both cascaded and end-to-end speech translation constrained systems, using the provided data only. In the cascaded approach, we combine Conformer-based automatic speech recognition (ASR) with the Transformer-based neural machine translation (NMT). Our end-to-end direct speech translation systems use ASR pretrained encoder and multi-task decoders. The submitted systems are ensembled by different cascaded models.
This paper describes the system submitted to the IWSLT 2021 Multilingual Speech Translation (MultiST) task from Huawei Noah’s Ark Lab. We use a unified transformer architecture for our MultiST model, so that the data from different modalities (i.e., speech and text) and different tasks (i.e., Speech Recognition, Machine Translation, and Speech Translation) can be exploited to enhance the model’s ability. Specifically, speech and text inputs are firstly fed to different feature extractors to extract acoustic and textual features, respectively. Then, these features are processed by a shared encoder–decoder architecture. We apply several training techniques to improve the performance, including multi-task learning, task-level curriculum learning, data augmentation, etc. Our final system achieves significantly better results than bilingual baselines on supervised language pairs and yields reasonable results on zero-shot language pairs.
This paper contains the description for the submission of Karlsruhe Institute of Technology (KIT) for the multilingual TEDx translation task in the IWSLT 2021 evaluation campaign. Our main approach is to develop both cascade and end-to-end systems and eventually combine them together to achieve the best possible results for this extremely low-resource setting. The report also confirms certain consistent architectural improvement added to the Transformer architecture, for all tasks: translation, transcription and speech translation.
This paper describes Edinburgh’s submissions to the IWSLT2021 multilingual speech translation (ST) task. We aim at improving multilingual translation and zero-shot performance in the constrained setting (without using any extra training data) through methods that encourage transfer learning and larger capacity modeling with advanced neural components. We build our end-to-end multilingual ST model based on Transformer, integrating techniques including adaptive speech feature selection, language-specific modeling, multi-task learning, deep and big Transformer, sparsified linear attention and root mean square layer normalization. We adopt data augmentation using machine translation models for ST which converts the zero-shot problem into a zero-resource one. Experimental results show that these methods deliver substantial improvements, surpassing the official baseline by > 15 average BLEU and outperforming our cascading system by > 2 average BLEU. Our final submission achieves competitive performance (runner up).
This paper describes the ON-TRAC Consortium translation systems developed for two challenge tracks featured in the Evaluation Campaign of IWSLT 2021, low-resource speech translation and multilingual speech translation. The ON-TRAC Consortium is composed of researchers from three French academic laboratories and an industrial partner: LIA (Avignon Université), LIG (Université Grenoble Alpes), LIUM (Le Mans Université), and researchers from Airbus. A pipeline approach was explored for the low-resource speech translation task, using a hybrid HMM/TDNN automatic speech recognition system fed by wav2vec features, coupled to an NMT system. For the multilingual speech translation task, we investigated the us of a dual-decoder Transformer that jointly transcribes and translates an input speech. This model was trained in order to translate from multiple source languages to multiple target ones.
This paper describes the submission to the IWSLT 2021 Low-Resource Speech Translation Shared Task by IMS team. We utilize state-of-the-art models combined with several data augmentation, multi-task and transfer learning approaches for the automatic speech recognition (ASR) and machine translation (MT) steps of our cascaded system. Moreover, we also explore the feasibility of a full end-to-end speech translation (ST) model in the case of very constrained amount of ground truth labeled data. Our best system achieves the best performance among all submitted systems for Congolese Swahili to English and French with BLEU scores 7.7 and 13.7 respectively, and the second best result for Coastal Swahili to English with BLEU score 14.9.
This paper describes the University of Sydney & JD’s joint submission of the IWSLT 2021 low resource speech translation task. We participated in the Swahili->English direction and got the best scareBLEU (25.3) score among all the participants. Our constrained system is based on a pipeline framework, i.e. ASR and NMT. We trained our models with the officially provided ASR and MT datasets. The ASR system is based on the open-sourced tool Kaldi and this work mainly explores how to make the most of the NMT models. To reduce the punctuation errors generated by the ASR model, we employ our previous work SlotRefine to train a punctuation correction model. To achieve better translation performance, we explored the most recent effective strategies, including back translation, knowledge distillation, multi-feature reranking, and transductive finetuning. For model structure, we tried auto-regressive and non-autoregressive models, respectively. In addition, we proposed two novel pre-train approaches, i.e. de-noising training and bidirectional training to fully exploit the data. Extensive experiments show that adding the above techniques consistently improves the BLEU scores, and the final submission system outperforms the baseline (Transformer ensemble model trained with the original parallel data) by approximately 10.8 BLEU score, achieving the SOTA performance.
Data augmentation, which refers to manipulating the inputs (e.g., adding random noise,masking specific parts) to enlarge the dataset,has been widely adopted in machine learning. Most data augmentation techniques operate on a single input, which limits the diversity of the training corpus. In this paper, we propose a simple yet effective data augmentation technique for neural machine translation, mixSeq, which operates on multiple inputs and their corresponding targets. Specifically, we randomly select two input sequences,concatenate them together as a longer input aswell as their corresponding target sequencesas an enlarged target, and train models on theaugmented dataset. Experiments on nine machine translation tasks demonstrate that such asimple method boosts the baselines by a non-trivial margin. Our method can be further combined with single input based data augmentation methods to obtain further improvements.
Recent studies argue that knowledge distillation is promising for speech translation (ST) using end-to-end models. In this work, we investigate the effect of knowledge distillation with a cascade ST using automatic speech recognition (ASR) and machine translation (MT) models. We distill knowledge from a teacher model based on human transcripts to a student model based on erroneous transcriptions. Our experimental results demonstrated that knowledge distillation is beneficial for a cascade ST. Further investigation that combined knowledge distillation and fine-tuning revealed that the combination consistently improved two language pairs: English-Italian and Spanish-English.
In supervised learning, a well-trained model should be able to recover ground truth accurately, i.e. the predicted labels are expected to resemble the ground truth labels as much as possible. Inspired by this, we formulate a difficulty criterion based on the recovery degrees of training examples. Motivated by the intuition that after skimming through the training corpus, the neural machine translation (NMT) model “knows” how to schedule a suitable curriculum according to learning difficulty, we propose a self-guided curriculum learning strategy that encourages the NMT model to learn from easy to hard on the basis of recovery degrees. Specifically, we adopt sentence-level BLEU score as the proxy of recovery degree. Experimental results on translation benchmarks including WMT14 English-German and WMT17 Chinese-English demonstrate that our proposed method considerably improves the recovery degree, thus consistently improving the translation performance.
Speech translation (ST) has lately received growing interest for the generation of subtitles without the need for an intermediate source language transcription and timing (i.e. captions). However, the joint generation of source captions and target subtitles does not only bring potential output quality advantages when the two decoding processes inform each other, but it is also often required in multilingual scenarios. In this work, we focus on ST models which generate consistent captions-subtitles in terms of structure and lexical content. We further introduce new metrics for evaluating subtitling consistency. Our findings show that joint decoding leads to increased performance and consistency between the generated captions and subtitles while still allowing for sufficient flexibility to produce subtitles conforming to language-specific needs and norms.
This paper describes the construction of a new large-scale English-Japanese Simultaneous Interpretation (SI) corpus and presents the results of its analysis. A portion of the corpus contains SI data from three interpreters with different amounts of experience. Some of the SI data were manually aligned with the source speeches at the sentence level. Their latency, quality, and word order aspects were compared among the SI data themselves as well as against offline translations. The results showed that (1) interpreters with more experience controlled the latency and quality better, and (2) large latency hurt the SI quality.
Traditional translation systems trained on written documents perform well for text-based translation but not as well for speech-based applications. We aim to adapt translation models to speech by introducing actual lexical errors from ASR and segmentation errors from automatic punctuation into our translation training data. We introduce an inverted projection approach that projects automatically detected system segments onto human transcripts and then re-segments the gold translations to align with the projected human transcripts. We demonstrate that this overcomes the train-test mismatch present in other training approaches. The new projection approach achieves gains of over 1 BLEU point over a baseline that is exposed to the human transcripts and segmentations, and these gains hold for both IWSLT data and YouTube data.
In recent years, automatic speech-to-speech and speech-to-text translation has gained momentum thanks to advances in artificial intelligence, especially in the domains of speech recognition and machine translation. The quality of such applications is commonly tested with automatic metrics, such as BLEU, primarily with the goal of assessing improvements of releases or in the context of evaluation campaigns. However, little is known about how the output of such systems is perceived by end users or how they compare to human performances in similar communicative tasks. In this paper, we present the results of an experiment aimed at evaluating the quality of a real-time speech translation engine by comparing it to the performance of professional simultaneous interpreters. To do so, we adopt a framework developed for the assessment of human interpreters and use it to perform a manual evaluation on both human and machine performances. In our sample, we found better performance for the human interpreters in terms of intelligibility, while the machine performs slightly better in terms of informativeness. The limitations of the study and the possible enhancements of the chosen framework are discussed. Despite its intrinsic limitations, the use of this framework represents a first step towards a user-centric and communication-oriented methodology for evaluating real-time automatic speech translation.
We implemented a neural machine translation system that uses automatic sequence tagging to improve the quality of translation. Instead of operating on unannotated sentence pairs, our system uses pre-trained tagging systems to add linguistic features to source and target sentences. Our proposed neural architecture learns a combined embedding of tokens and tags in the encoder, and simultaneous token and tag prediction in the decoder. Compared to a baseline with unannotated training, this architecture increased the BLEU score of German to English film subtitle translation outputs by 1.61 points using named entity tags; however, the BLEU score decreased by 0.38 points using part-of-speech tags. This demonstrates that certain token-level tag outputs from off-the-shelf tagging systems can improve the output of neural translation systems using our combined embedding and simultaneous decoding extensions.
Sub-word segmentation is currently a standard tool for training neural machine translation (MT) systems and other NLP tasks. The goal is to split words (both in the source and target languages) into smaller units which then constitute the input and output vocabularies of the MT system. The aim of reducing the size of the input and output vocabularies is to increase the generalization capabilities of the translation model, enabling the system to translate and generate infrequent and new (unseen) words at inference time by combining previously seen sub-word units. Ideally, we would expect the created units to have some linguistic meaning, so that words are created in a compositional way. However, the most popular word-splitting method, Byte-Pair Encoding (BPE), which originates from the data compression literature, does not include explicit criteria to favor linguistic splittings nor to find the optimal sub-word granularity for the given training data. In this paper, we propose a statistically motivated extension of the BPE algorithm and an effective convergence criterion that avoids the costly experimentation cycle needed to select the best sub-word vocabulary size. Experimental results with morphologically rich languages show that our model achieves nearly-optimal BLEU scores and produces morphologically better word segmentations, which allows to outperform BPE’s generalization in the translation of sentences containing new words, as shown via human evaluation.
Complex natural language applications such as speech translation or pivot translation traditionally rely on cascaded models. However,cascaded models are known to be prone to error propagation and model discrepancy problems. Furthermore, there is no possibility of using end-to-end training data in conventional cascaded systems, meaning that the training data most suited for the task cannot be used.Previous studies suggested several approaches for integrated end-to-end training to overcome those problems, however they mostly rely on(synthetic or natural) three-way data. We propose a cascaded model based on the non-autoregressive Transformer that enables end-to-end training without the need for an explicit intermediate representation. This new architecture (i) avoids unnecessary early decisions that can cause errors which are then propagated throughout the cascaded models and (ii) utilizes the end-to-end training data directly. We conduct an evaluation on two pivot-based machine translation tasks, namely French→German and German→Czech. Our experimental results show that the proposed architecture yields an improvement of more than 2 BLEU for French→German over the cascaded baseline.
In this paper, we investigate the driving factors behind concatenation, a simple but effective data augmentation method for low-resource neural machine translation. Our experiments suggest that discourse context is unlikely the cause for concatenation improving BLEU by about +1 across four language pairs. Instead, we demonstrate that the improvement comes from three other factors unrelated to discourse: context diversity, length diversity, and (to a lesser extent) position shifting.
In this paper, we aim to address the challenges surrounding the translation of ancient Chinese text: (1) The linguistic gap due to the difference in eras results in translations that are poor in quality, and (2) most translations are missing the contextual information that is often very crucial to understanding the text. To this end, we improve upon past translation techniques by proposing the following: We reframe the task as a multi-label prediction task where the model predicts both the translation and its particular era. We observe that this helps to bridge the linguistic gap as chronological context is also used as auxiliary information. We validate our framework on a parallel corpus annotated with chronology information and show experimentally its efficacy in producing quality translation outputs. We release both the code and the data for future research.
We present a manually annotated lexical semantic change dataset for Russian: RuShiftEval. Its novelty is ensured by a single set of target words annotated for their diachronic semantic shifts across three time periods, while the previous work either used only two time periods, or different sets of target words. The paper describes the composition and annotation procedure for the dataset. In addition, it is shown how the ternary nature of RuShiftEval allows to trace specific diachronic trajectories: ‘changed at a particular time period and stable afterwards’ or ‘was changing throughout all time periods’. Based on the analysis of the submissions to the recent shared task on semantic change detection for Russian, we argue that correctly identifying such trajectories can be an interesting sub-task itself.
The use of automatic methods for the study of lexical semantic change (LSC) has led to the creation of evaluation benchmarks. Benchmark datasets, however, are intimately tied to the corpus used for their creation questioning their reliability as well as the robustness of automatic methods. This contribution investigates these aspects showing the impact of unforeseen social and cultural dimensions. We also identify a set of additional issues (OCR quality, named entities) that impact the performance of the automatic methods, especially when used to discover LSC.
In this study, we have normalized and lemmatized an Old Literary Finnish corpus using a lemmatization model trained on texts from Agricola. We analyse the error types that occur and appear in different decades, and use word error rate (WER) and different error types as a proxy for measuring linguistic innovation and change. We show that the proposed approach works, and the errors are connected to accumulating changes and innovations, which also results in a continuous decrease in the accuracy of the model. The described error types also guide further work in improving these models, and document the currently observed issues. We also have trained word embeddings for four centuries of lemmatized Old Literary Finnish, which are available on Zenodo.
The use of euphemisms is a known driver of language change. It has been proposed that women use euphemisms more than men. Although there have been several studies investigating gender differences in language, the claim about euphemism usage has not been tested comprehensively through time. If women do use euphemisms more, this could mean that women also lead the formation of new euphemisms and language change over time. Using four large diachronic text corpora of English, we evaluate the claim that women use euphemisms more than men through a quantitative analysis. We assembled a list of 106 euphemism-taboo pairs to analyze their relative use through time by each gender in the corpora. Contrary to the existing belief, our results show that women do not use euphemisms with a higher proportion than men. We repeated the analysis using different subsets of the euphemism-taboo pairs list and found that our result was robust. Our study indicates that in a broad range of settings involving both speech and writing, and with varying degrees of formality, women do not use or form euphemisms more than men.
This paper describes the GLAUx project (“the Greek Language Automated”), an ongoing effort to develop a large long-term diachronic corpus of Greek, covering sixteen centuries of literary and non-literary material annotated with NLP methods. After providing an overview of related corpus projects and discussing the general architecture of the corpus, it zooms in on a number of larger methodological issues in the design of historical corpora. These include the encoding of textual variants, handling extralinguistic variation and annotating linguistic ambiguity. Finally, the long- and short-term perspectives of this project are discussed.
We present Bhāṣācitra, a dialect mapping system for South Asia built on a database of linguistic studies of languages of the region annotated for topic and location data. We analyse language coverage and look towards applications to typology by visualising example datasets. The application is not only meant to be useful for feature mapping, but also serves as a new kind of interactive bibliography for linguists of South Asian languages.
Languages evolve over time and the meaning of words can shift. Furthermore, individual words can have multiple senses. However, existing language models often only reflect one word sense per word and do not reflect semantic changes over time. While there are language models that can either model semantic change of words or multiple word senses, none of them cover both aspects simultaneously. We propose a novel force-directed graph layout algorithm to draw a network of frequently co-occurring words. In this way, we are able to use the drawn graph to visualize the evolution of word senses. In addition, we hope that jointly modeling semantic change and multiple senses of words results in improvements for the individual tasks.
Semantic divergence in related languages is a key concern of historical linguistics. We cross-linguistically investigate the semantic divergence of cognate pairs in English and Romance languages, by means of word embeddings. To this end, we introduce a new curated dataset of cognates in all pairs of those languages. We describe the types of errors that occurred during the automated cognate identification process and manually correct them. Additionally, we label the English cognates according to their etymology, separating them into two groups: old borrowings and recent borrowings. On this curated dataset, we analyse word properties such as frequency and polysemy, and the distribution of similarity scores between cognate sets in different languages. We automatically identify different clusters of English cognates, setting a new direction of research in cognates, borrowings and possibly false friends analysis in related languages.
Text-based games can be used to develop task-oriented text agents for accomplishing tasks with high-level language instructions, which has potential applications in domains such as human-robot interaction. Given a text instruction, reinforcement learning is commonly used to train agents to complete the intended task owing to its convenience of learning policies automatically. However, because of the large space of combinatorial text actions, learning a policy network that generates an action word by word with reinforcement learning is challenging. Recent research works show that imitation learning provides an effective way of training a generation-based policy network. However, trained agents with imitation learning are hard to master a wide spectrum of task types or skills, and it is also difficult for them to generalize to new environments. In this paper, we propose a meta reinforcement learning based method to train text agents through learning-to-explore. In particular, the text agent first explores the environment to gather task-specific information and then adapts the execution policy for solving the task with this information. On the publicly available testbed ALFWorld, we conducted a comparison study with imitation learning and show the superiority of our method.
Multilingual pre-trained contextual embedding models (Devlin et al., 2019) have achieved impressive performance on zero-shot cross-lingual transfer tasks. Finding the most effective fine-tuning strategy to fine-tune these models on high-resource languages so that it transfers well to the zero-shot languages is a non-trivial task. In this paper, we propose a novel meta-optimizer to soft-select which layers of the pre-trained model to freeze during fine-tuning. We train the meta-optimizer by simulating the zero-shot transfer scenario. Results on cross-lingual natural language inference show that our approach improves over the simple fine-tuning baseline and X-MAML (Nooralahzadeh et al., 2020).
In this paper, we study the problem of recognizing compositional attribute-object concepts within the zero-shot learning (ZSL) framework. We propose an episode-based cross-attention (EpiCA) network which combines merits of cross-attention mechanism and episode-based training strategy to recognize novel compositional concepts. Firstly, EpiCA bases on cross-attention to correlate conceptvisual information and utilizes the gated pooling layer to build contextualized representations for both images and concepts. The updated representations are used for a more indepth multi-modal relevance calculation for concept recognition. Secondly, a two-phase episode training strategy, especially the ransductive phase, is adopted to utilize unlabeled test examples to alleviate the low-resource learning problem. Experiments on two widelyused zero-shot compositional learning (ZSCL) benchmarks have demonstrated the effectiveness of the model compared with recent approaches on both conventional and generalized ZSCL settings.
Text-style transfer aims to convert text given in one domain into another by paraphrasing the sentence or substituting the keywords without altering the content. By necessity, state-of-the-art methods have evolved to accommodate nonparallel training data, as it is frequently the case there are multiple data sources of unequal size, with a mixture of labeled and unlabeled sentences. Moreover, the inherent style defined within each source might be distinct. A generic bidirectional (e.g., formal ⇔ informal) style transfer regardless of different groups may not generalize well to different applications. In this work, we developed a task adaptive meta-learning framework that can simultaneously perform a multi-pair text-style transfer using a single model. The proposed method can adaptively balance the difference of meta-knowledge across multiple tasks. Results show that our method leads to better quantitative performance as well as coherent style variations. Common challenges of unbalanced data and mismatched domains are handled well by this method.
Supervised deep learning-based approaches have been applied to task-oriented dialog and have proven to be effective for limited domain and language applications when a sufficient number of training examples are available. In practice, these approaches suffer from the drawbacks of domain-driven design and under-resourced languages. Domain and language models are supposed to grow and change as the problem space evolves. On one hand, research on transfer learning has demonstrated the cross-lingual ability of multilingual Transformers-based models to learn semantically rich representations. On the other, in addition to the above approaches, meta-learning have enabled the development of task and language learning algorithms capable of far generalization. Through this context, this article proposes to investigate the cross-lingual transferability of using synergistically few-shot learning with prototypical neural networks and multilingual Transformers-based models. Experiments in natural language understanding tasks on MultiATIS++ corpus shows that our approach substantially improves the observed transfer learning performances between the low and the high resource languages. More generally our approach confirms that the meaningful latent space learned in a given language can be can be generalized to unseen and under-resourced ones using meta-learning.
Meta-learning has recently been proposed to learn models and algorithms that can generalize from a handful of examples. However, applications to structured prediction and textual tasks pose challenges for meta-learning algorithms. In this paper, we apply two meta-learning algorithms, Prototypical Networks and Reptile, to few-shot Named Entity Recognition (NER), including a method for incorporating language model pre-training and Conditional Random Fields (CRF). We propose a task generation scheme for converting classical NER datasets into the few-shot setting, for both training and evaluation. Using three public datasets, we show these meta-learning algorithms outperform a reasonable fine-tuned BERT baseline. In addition, we propose a novel combination of Prototypical Networks and Reptile.
Speech separation is a problem in the field of speech processing that has been studied in full swing recently. However, there has not been much work studying a multi-accent speech separation scenario. Unseen speakers with new accents and noise aroused the domain mismatch problem which cannot be easily solved by conventional joint training methods. Thus, we applied MAML and FOMAML to tackle this problem and obtained higher average Si-SNRi values than joint training on almost all the unseen accents. This proved that these two methods do have the ability to generate well-trained parameters for adapting to speech mixtures of new speakers and accents. Furthermore, we found out that FOMAML obtains similar performance compared to MAML while saving a lot of time.
Meta learning aims to optimize the model’s capability to generalize to new tasks and domains. Lacking a data-efficient way to create meta training tasks has prevented the application of meta-learning to the real-world few shot learning scenarios. Recent studies have proposed unsupervised approaches to create meta-training tasks from unlabeled data for free, e.g., the SMLMT method (Bansal et al., 2020a) constructs unsupervised multi-class classification tasks from the unlabeled text by randomly masking words in the sentence and let the meta learner choose which word to fill in the blank. This study proposes a semi-supervised meta-learning approach that incorporates both the representation power of large pre-trained language models and the generalization capability of prototypical networks enhanced by SMLMT. The semi-supervised meta training approach avoids overfitting prototypical networks on a small number of labeled training examples and quickly learns cross-domain task-specific representation only from a few supporting examples. By incorporating SMLMT with prototypical networks, the meta learner generalizes better to unseen domains and gains higher accuracy on out-of-scope examples without the heavy lifting of pre-training. We observe significant improvement in few-shot generalization after training only a few epochs on the intent classification tasks evaluated in a multi-domain setting.
In this paper, we place ourselves in a classification scenario in which the target classes and data type are not accessible during training. We use a meta-learning approach to determine whether or not meta-trained information from common social network data with fine-grained emotion labels can achieve competitive performance on messages labeled with different emotion categories. We leverage few-shot learning to match with the classification scenario and consider metric learning based meta-learning by setting up Prototypical Networks with a Transformer encoder, trained in an episodic fashion. This approach proves to be effective for capturing meta-information from a source emotional tag set to predict previously unseen emotional tags. Even though shifting the data type triggers an expected performance drop, our meta-learning approach achieves decent results when compared to the fully supervised one.
In recent years, language models (LMs) have become almost synonymous with NLP. Pre-trained to “read” a large text corpus, such models are useful as both a representation layer as well as a source of world knowledge. But how well do they represent MWEs? This talk will discuss various problems in representing MWEs, and the extent to which LMs address them: • Do LMs capture the implicit relationship between constituents in compositional MWEs (from baby oil through parsley cake to cheeseburger stabbing)? • Do LMs recognize when words are used nonliterally in non-compositional MWEs (e.g. do they know whether there are fleas in the flea market)? • Do LMs know idioms, and can they infer the meaning of new idioms from the context as humans often do?
Expressions with an aspectual variant of a light verb, e.g. ‘take on debt’ vs. ‘have debt’, are frequent in texts but often difficult to classify between verbal idioms, light verb constructions or compositional phrases. We investigate the properties of such expressions with a disputed membership and propose a selection of features that determine more satisfactory boundaries between the three categories in this zone, assigning the expressions to one of them.
The automatic recognition of idioms poses a challenging problem for NLP applications. Whereas native speakers can intuitively handle multiword expressions whose compositional meanings are hard to trace back to individual word semantics, there is still ample scope for improvement regarding computational approaches. We assume that idiomatic constructions can be characterized by gradual intensities of semantic non-compositionality, formal fixedness, and unusual usage context, and introduce a number of measures for these characteristics, comprising count-based and predictive collocation measures together with measures of context (un)similarity. We evaluate our approach on a manually labelled gold standard, derived from a corpus of German pop lyrics. To this end, we apply a Random Forest classifier to analyze the individual contribution of features for automatically detecting idioms, and study the trade-off between recall and precision. Finally, we evaluate the classifier on an independent dataset of idioms extracted from a list of Wikipedia idioms, achieving state-of-the art accuracy.
Potentially idiomatic expressions (PIEs) are ambiguous between non-compositional idiomatic interpretations and transparent literal interpretations. For example, “hit the road” can have an idiomatic meaning corresponding to ‘start a journey’ or have a literal interpretation. In this paper we propose a supervised model based on contextualized embeddings for predicting whether usages of PIEs are idiomatic or literal. We consider monolingual experiments for English and Russian, and show that the proposed model outperforms previous approaches, including in the case that the model is tested on instances of PIE types that were not observed during training. We then consider cross-lingual experiments in which the model is trained on PIE instances in one language, English or Russian, and tested on the other language. We find that the model outperforms baselines in this setting. These findings suggest that contextualized embeddings are able to learn representations that encode knowledge of idiomaticity that is not restricted to specific expressions, nor to a specific language.
Idiomatic expressions (IE) play an important role in natural language, and have long been a “pain in the neck” for NLP systems. Despite this, text generation tasks related to IEs remain largely under-explored. In this paper, we propose two new tasks of idiomatic sentence generation and paraphrasing to fill this research gap. We introduce a curated dataset of 823 IEs, and a parallel corpus with sentences containing them and the same sentences where the IEs were replaced by their literal paraphrases as the primary resource for our tasks. We benchmark existing deep learning models, which have state-of-the-art performance on related tasks using automated and manual evaluation with our dataset to inspire further research on our proposed tasks. By establishing baseline models, we pave the way for more comprehensive and accurate modeling of IEs, both for generation and paraphrasing.
In lexical semantics, full-sentence segmentation and segment labeling of various phenomena are generally treated separately, despite their interdependence. We hypothesize that a unified lexical semantic recognition task is an effective way to encapsulate previously disparate styles of annotation, including multiword expression identification / classification and supersense tagging. Using the STREUSLE corpus, we train a neural CRF sequence tagger and evaluate its performance along various axes of annotation. As the label set generalizes that of previous tasks (PARSEME, DiMSUM), we additionally evaluate how well the model generalizes to those test sets, finding that it approaches or surpasses existing models despite training only on STREUSLE. Our work also establishes baseline models and evaluation metrics for integrated and accurate modeling of lexical semantics, facilitating future work in this area.
Sentence embeddings encode information relating to the usage of idioms in a sentence. This paper reports a set of experiments that combine a probing methodology with input masking to analyse where in a sentence this idiomatic information is taken from, and what form it takes. Our results indicate that BERT’s idiomatic key is primarily found within an idiomatic expression, but also draws on information from the surrounding context. Also, BERT can distinguish between the disruption in a sentence caused by words missing and the incongruity caused by idiomatic usage.
The paper reports on a corpus study of German light verb constructions (LVCs). LVCs come in families which exemplify systematic interpretation patterns. The paper’s aim is to account for the properties determining these patterns on the basis of a corpus study on German LVCs of the type ‘stehen unter’ NP’ (‘stand under NP’).
Amidst rising mental health needs in society, virtual agents are increasingly deployed in counselling. In order to give pertinent advice, counsellors must first gain an understanding of the issues at hand by eliciting sharing from the counsellee. It is thus important for the counsellor chatbot to encourage the user to open up and talk. One way to sustain the conversation flow is to acknowledge the counsellee’s key points by restating them, or probing them further with questions. This paper applies models from two closely related NLP tasks — summarization and question generation — to restatement and question generation in the counselling context. We conducted experiments on a manually annotated dataset of Cantonese post-reply pairs on topics related to loneliness, academic anxiety and test anxiety. We obtained the best performance in both restatement and question generation by fine-tuning BertSum, a state-of-the-art summarization model, with the in-domain manual dataset augmented with a large-scale, automatically mined open-domain dataset.
The debate around climate change (CC)—its extent, its causes, and the necessary responses—is intense and of global importance. Yet, in the natural language processing (NLP) community, this domain has so far received little attention. In contrast, it is of enormous prominence in various social science disciplines, and some of that work follows the ”text-as-data” paradigm, seeking to employ quantitative methods for analyzing large amounts of CC-related text. Other research is qualitative in nature and studies details, nuances, actors, and motivations within CC discourses. Coming from both NLP and Political Science, and reviewing key works in both disciplines, we discuss how social science approaches to CC debates can inform advances in text-mining/NLP, and how, in return, NLP can support policy-makers and activists in making sense of large-scale and complex CC discourses across multiple genres, channels, topics, and communities. This is paramount for their ability to make rapid and meaningful impact on the discourse, and for shaping the necessary policy change.
The range of works that can be considered as developing NLP for social good (NLP4SG) is enormous. While many of them target the identification of hate speech or fake news, there are others that address, e.g., text simplification to alleviate consequences of dyslexia, or coaching strategies to fight depression. However, so far, there is no clear picture of what areas are targeted by NLP4SG, who are the actors, which are the main scenarios and what are the topics that have been left aside. In order to obtain a clearer view in this respect, we first propose a working definition of NLP4SG and identify some primary aspects that are crucial for NLP4SG, including, e.g., areas, ethics, privacy and bias. Then, we draw upon a corpus of around 50,000 articles downloaded from the ACL Anthology. Based on a list of keywords retrieved from the literature and revised in view of the task, we select from this corpus articles that can be considered to be on NLP4SG according to our definition and analyze them in terms of trends along the time line, etc. The result is a map of the current NLP4SG research and insights concerning the white spots on this map.
We introduce 9 guiding principles to integrate Participatory Design (PD) methods in the development of Natural Language Processing (NLP) systems. The adoption of PD methods by NLP will help to alleviate issues concerning the development of more democratic, fairer, less-biased technologies to process natural language data. This short paper is the outcome of an ongoing dialogue between designers and NLP experts and adopts a non-standard format following previous work by Traum (2000); Bender (2013); Abzianidze and Bos (2019). Every section is a guiding principle. While principles 1–3 illustrate assumptions and methods that inform community-based PD practices, we used two fictional design scenarios (Encinas and Blythe, 2018), which build on top of situations familiar to the authors, to elicit the identification of the other 6. Principles 4–6 describes the impact of PD methods on the design of NLP systems, targeting two critical aspects: data collection & annotation, and the deployment & evaluation. Finally, principles 7–9 guide a new reflexivity of the NLP research with respect to its context, actors and participants, and aims. We hope this guide will offer inspiration and a road-map to develop a new generation of PD-inspired NLP.
Conversational Agents (CAs) can be a proxy for disseminating information and providing support to the public, especially in times of crisis. CAs can scale to reach larger numbers of end-users than human operators, while they can offer information interactively and engagingly. In this work, we present Theano, a Greek-speaking virtual assistant for COVID-19. Theano presents users with COVID-19 statistics and facts and informs users about the best health practices as well as the latest COVID-19 related guidelines. Additionally, Theano provides support to end-users by helping them self-assess their symptoms and redirecting them to first-line health workers. The relevant, localized information that Theano provides, makes it a valuable tool for combating COVID-19 in Greece. Theano has already conversed with different users in more than 170 different conversations through a web interface as a chatbot and over the phone as a voice bot.
In this position paper, we present a research agenda and ideas for facilitating exposure to diverse viewpoints in news recommendation. Recommending news from diverse viewpoints is important to prevent potential filter bubble effects in news consumption, and stimulate a healthy democratic debate.To account for the complexity that is inherent to humans as citizens in a democracy, we anticipate (among others) individual-level differences in acceptance of diversity. We connect this idea to techniques in Natural Language Processing, where distributional language models would allow us to place different users and news articles in a multidimensional space based on semantic content, where diversity is operationalized as distance and variance. In this way, we can model individual “latitudes of diversity” for different users, and thus personalize viewpoint diversity in support of a healthy public debate. In addition, we identify technical, ethical and conceptual issues related to our presented ideas. Our investigation describes how NLP can play a central role in diversifying news recommendations.
To build automated simplification systems, corpora of complex sentences and their simplified versions is the first step to understand sentence complexity and enable the development of automatic text simplification systems. We present a lexical and syntactically simplified Urdu simplification corpus with a detailed analysis of the various simplification operations and human evaluation of corpus quality. We further analyze our corpora using text readability measures and present a comparison of the original, lexical simplified and syntactically simplified corpora. In addition, we compare our corpus with other existing simplification corpora by building simplification systems and evaluating these systems using BLEU and SARI scores. Our system achieves the highest BLEU score and comparable SARI score in comparison to other systems. We release our simplification corpora for the benefit of the research community.
Information extraction and question answering have the potential to introduce a new paradigm for how machine learning is applied to criminal law. Existing approaches generally use tabular data for predictive metrics. An alternative approach is needed for matters of equitable justice, where individuals are judged on a case-by-case basis, in a process involving verbal or written discussion and interpretation of case factors. Such discussions are individualized, but they nonetheless rely on underlying facts. Information extraction can play an important role in surfacing these facts, which are still important to understand. We analyze unsupervised, weakly supervised, and pre-trained models’ ability to extract such factual information from the free-form dialogue of California parole hearings. With a few exceptions, most F1 scores are below 0.85. We use this opportunity to highlight some opportunities for further research for information extraction and question answering. We encourage new developments in NLP to enable analysis and review of legal cases to be done in a post-hoc, not predictive, manner.
Social media has changed the way we engage in social activities. On Twitter, users can participate in social movements using hashtags such as #MeToo; this is known as hashtag activism. However, while these hashtags can help reshape social norms, they can also be used maliciously by spammers or troll communities for other purposes, such as signal boosting unrelated content, making a dent in a movement, or sharing hate speech. We present a Tweet-level hashtag hijacking detection framework focusing on hashtag activism. Our weakly-supervised framework uses bootstrapping to update itself as new Tweets are posted. Our experiments show that the system adapts to new topics in a social movement, as well as new hijacking strategies, maintaining strong performance over time.
Online shopping is an ever more important part of the global consumer economy, not just in times of a pandemic. When we place an order online as consumers, we regularly agree to the so-called “Terms and Conditions” (T&C), a contract unilaterally drafted by the seller. Often, consumers do not read these contracts and unwittingly agree to unfavourable and often void terms. Government and non-government organisations (NGOs) for consumer protection battle such terms on behalf of consumers, who often hesitate to take on legal actions themselves. However, the growing number of online shops and a lack of funding makes it increasingly difficult for such organisations to monitor the market effectively. This paper describes how Natural Language Processing (NLP) can be applied to support consumer advocates in their efforts to protect consumers. Together with two NGOs from Germany, we developed an NLP-based application that legally assesses clauses in T&C from German online shops under the European Union’s (EU) jurisdiction. We report that we could achieve an accuracy of 0.9 in the detection of void clauses by fine-tuning a pre-trained German BERT model. The approach is currently used by two NGOs and has already helped to challenge void clauses in T&C.
Understanding the gaps between job requirements and university curricula is crucial for improving student success and institutional effectiveness in higher education. In this context, natural language processing (NLP) can be leveraged to generate granular insights into where the gaps are and how they change. This paper proposes a three-dimensional research framework that combines NLP techniques with economic and educational research to quantify the alignment between course syllabi and job postings. We elaborate on key technical details of the framework and further discuss its potential positive impacts on practice, including unveiling the inequalities in and long-term consequences of education-occupation alignment to inform policymakers, and fostering information systems to support students, institutions and employers in the school-to-work pipeline.
Augmentative and Alternative Communication (AAC) devices and applications are intended to make it easier for individuals with complex communication needs to participate in conversations. However, these devices have low adoption and retention rates. We review prior work with text recommendation systems that have not been successful in mitigating these problems. To address these gaps, we propose applying Dialogue Act classification to AAC conversations. We evaluated the performance of a state of the art model on a limited AAC dataset that was trained on both AAC and non-AAC datasets. The one trained on AAC (accuracy = 38.6%) achieved better performance than that trained on a non-AAC corpus (accuracy = 34.1%). These results reflect the need to incorporate representative datasets in later experiments. We discuss the need to collect more labeled AAC datasets and propose areas of future work.
This article explores the potential for Natural Language Processing (NLP) to enable a more effective, prevention focused and less confrontational policing model that has hitherto been too resource consuming to implement at scale. Problem-Oriented Policing (POP) is a potential replacement, at least in part, for traditional policing which adopts a reactive approach, relying heavily on the criminal justice system. By contrast, POP seeks to prevent crime by manipulating the underlying conditions that allow crimes to be committed. Identifying these underlying conditions requires a detailed understanding of crime events - tacit knowledge that is often held by police officers but which can be challenging to derive from structured police data. One potential source of insight exists in unstructured free text data commonly collected by police for the purposes of investigation or administration. Yet police agencies do not typically have the skills or resources to analyse these data at scale. In this article we argue that NLP offers the potential to unlock these unstructured data and by doing so allow police to implement more POP initiatives. However we caution that using NLP models without adequate knowledge may either allow or perpetuate bias within the data potentially leading to unfavourable outcomes.
The ongoing COVID-19 pandemic resulted in significant ramifications for international relations ranging from travel restrictions, global ceasefires, and international vaccine production and sharing agreements. Amidst a wave of infections in India that resulted in a systemic breakdown of healthcare infrastructure, a social welfare organization based in Pakistan offered to procure medical-grade oxygen to assist India - a nation which was involved in four wars with Pakistan in the past few decades. In this paper, we focus on Pakistani Twitter users’ response to the ongoing healthcare crisis in India. While #IndiaNeedsOxygen and #PakistanStandsWithIndia featured among the top-trending hashtags in Pakistan, divisive hashtags such as #EndiaSaySorryToKashmir simultaneously started trending. Against the backdrop of a contentious history including four wars, divisive content of this nature, especially when a country is facing an unprecedented healthcare crisis, fuels further deterioration of relations. In this paper, we define a new task of detecting supportive content and demonstrate that existing NLP for social impact tools can be effectively harnessed for such tasks within a quick turnaround time. We also release the first publicly available data set at the intersection of geopolitical relations and a raging pandemic in the context of India and Pakistan.
In this overview article we describe an application designed to enable communication between health practitioners and patients who do not share a common language, in situations where professional interpreters are not available. Built on the principle of a fixed phrase translator, the application implements different natural language processing (NLP) technologies, such as speech recognition, neural machine translation and text-to-speech to improve usability. Its design allows easy portability to new domains and integration of different types of output for multiple target audiences. Even though BabelDr is far from solving the problem of miscommunication between patients and doctors, it is a clear example of NLP in a real world application designed to help minority groups to communicate in a medical context. It also gives some insights into the relevant criteria for the development of such an application.
Technologies for enhancing well-being, healthcare vigilance and monitoring are on the rise. However, despite patient interest, such technologies suffer from low adoption. One hypothesis for this limited adoption is loss of human interaction that is central to doctor-patient encounters. In this paper we seek to address this limitation via a conversational agent that adopts one aspect of in-person doctor-patient interactions: A human avatar to facilitate medical grounded question answering. This is akin to the in-person scenario where the doctor may point to the human body or the patient may point to their own body to express their conditions. Additionally, our agent has multiple interaction modes, that may give more options for the patient to use the agent, not just for medical question answering, but also to engage in conversations about general topics and current events. Both the avatar, and the multiple interaction modes could help improve adherence. We present a high level overview of the design of our agent, Marie Bot Wellbeing. We also report implementation details of our early prototype , and present preliminary results.
Automated source code summarization is a popular software engineering research topic wherein machine translation models are employed to “translate” code snippets into relevant natural language descriptions. Most evaluations of such models are conducted using automatic reference-based metrics. However, given the relatively large semantic gap between programming languages and natural language, we argue that this line of research would benefit from a qualitative investigation into the various error modes of current state-of-the-art models. Therefore, in this work, we perform both a quantitative and qualitative comparison of three recently proposed source code summarization models. In our quantitative evaluation, we compare the models based on the smoothed BLEU-4, METEOR, and ROUGE-L machine translation metrics, and in our qualitative evaluation, we perform a manual open-coding of the most common errors committed by the models when compared to ground truth captions. Our investigation reveals new insights into the relationship between metric-based performance and model prediction errors grounded in an error taxonomy that can be used to drive future research efforts.
We introduce CONTEST, a benchmark for NLP-based unit test completion, the task of predicting a test’s assert statements given its setup and focal method, i.e. the method to be tested. ConTest is large-scale (with 365k datapoints). Besides the test code and tested code, it also features context code called by either. We found context to be crucial for accurately predicting assertions. We also introduce baselines based on transformer encoder-decoders, and study the effects of including syntactic information and context. Overall, our models achieve a BLEU score of 38.2, while only generating unparsable code in 1.92% of cases.
Commit message is a document that summarizes source code changes in natural language. A good commit message clearly shows the source code changes, so this enhances collaboration between developers. Therefore, our work is to develop a model that automatically writes the commit message. To this end, we release 345K datasets consisting of code modification and commit messages in six programming languages (Python, PHP, Go, Java, JavaScript, and Ruby). Similar to the neural machine translation (NMT) model, using our dataset, we feed the code modification to the encoder input and the commit message to the decoder input and measure the result of the generated commit message with BLEU-4. Also, we propose the following two training methods to improve the result of generating the commit message: (1) A method of preprocessing the input to feed the code modification to the encoder input. (2) A method that uses an initial weight suitable for the code domain to reduce the gap in contextual representation between programming language (PL) and natural language (NL).
In this paper we present a deep learning code completion model for the R language. We introduce several techniques to utilize language modeling based architecture in the code completion task. With these techniques, the model requires low resources, but still achieves high quality. We also present an evaluation dataset for the R language completion task. Our dataset contains multiple autocompletion usage contexts that provides robust validation results. The dataset is publicly available.
We present CoTexT, a pre-trained, transformer-based encoder-decoder model that learns the representative context between natural language (NL) and programming language (PL). Using self-supervision, CoTexT is pre-trained on large programming language corpora to learn a general understanding of language and code. CoTexT supports downstream NL-PL tasks such as code summarizing/documentation, code generation, defect detection, and code debugging. We train CoTexT on different combinations of available PL corpus including both “bimodal” and “unimodal” data. Here, bimodal data is the combination of text and corresponding code snippets, whereas unimodal data is merely code snippets. We first evaluate CoTexT with multi-task learning: we perform Code Summarization on 6 different programming languages and Code Refinement on both small and medium size featured in the CodeXGLUE dataset. We further conduct extensive experiments to investigate CoTexT on other tasks within the CodeXGlue dataset, including Code Generation and Defect Detection. We consistently achieve SOTA results in these tasks, demonstrating the versatility of our models.
Decompiling binary executables to high-level code is an important step in reverse engineering scenarios, such as malware analysis and legacy code maintenance. However, the generated high-level code is difficult to understand since the original variable names are lost. In this paper, we leverage transformer models to reconstruct the original variable names from decompiled code. Inherent differences between code and natural language present certain challenges in applying conventional transformer-based architectures to variable name recovery. We propose DIRECT, a novel transformer-based architecture customized specifically for the task at hand. We evaluate our model on a dataset of decompiled functions and find that DIRECT outperforms the previous state-of-the-art model by up to 20%. We also present ablation studies evaluating the impact of each of our modifications. We make the source code of DIRECT available to encourage reproducible research.
We take the first step to address the task of automatically generating shellcodes, i.e., small pieces of code used as a payload in the exploitation of a software vulnerability, starting from natural language comments. We assemble and release a novel dataset (Shellcode_IA32), consisting of challenging but common assembly instructions with their natural language descriptions. We experiment with standard methods in neural machine translation (NMT) to establish baseline performance levels on this task.
Answering a programming question with only its title is difficult as salient contextual information is left out. To address this, we present a corpus of over 40,000 StackOverflow question texts to be used in conjunction with the corresponding intents from the CoNaLa dataset (Yin et al., 2018). Using both the intent and the question body, we use BART to establish a baseline BLEU score of 34.35 for this new task. We then find further improvements of 2.8% by combining the mined CoNaLa data with the labeled data to achieve a 35.32 BLEU score. We then evaluate the prior state-of-the-art CoNaLa models with this additional data. We find that our proposed method of using the body and mined data beats that of the previous state-of-the-art by a 71.96% BLEU score. Finally, we perform ablations that prove that BART is an unsupervised multimodal learner and examine its extractive behavior.
Most available semantic parsing datasets, comprising of pairs of natural utterances and logical forms, were collected solely for the purpose of training and evaluation of natural language understanding systems. As a result, they do not contain any of the richness and variety of natural-occurring utterances, where humans ask about data they need or are curious about. In this work, we release SEDE, a dataset with 12,023 pairs of utterances and SQL queries collected from real usage on the Stack Exchange website. We show that these pairs contain a variety of real-world challenges which were rarely reflected so far in any other semantic parsing dataset, propose an evaluation metric based on comparison of partial query clauses that is more suitable for real-world queries, and conduct experiments with strong baselines, showing a large gap between the performance on SEDE compared to other common datasets.
The task of semantic code search is to retrieve code snippets from a source code corpus based on an information need expressed in natural language. The semantic gap between natural language and programming languages has for long been regarded as one of the most significant obstacles to the effectiveness of keyword-based information retrieval (IR) methods. It is a common assumption that “traditional” bag-of-words IR methods are poorly suited for semantic code search: our work empirically investigates this assumption. Specifically, we examine the effectiveness of two traditional IR methods, namely BM25 and RM3, on the CodeSearchNet Corpus, which consists of natural language queries paired with relevant code snippets. We find that the two keyword-based methods outperform several pre-BERT neural models. We also compare several code-specific data pre-processing strategies and find that specialized tokenization improves effectiveness.
Cross-lingual text classification (CLTC) is a challenging task made even harder still due to the lack of labeled data in low-resource languages. In this paper, we propose zero-shot instance-weighting, a general model-agnostic zero-shot learning framework for improving CLTC by leveraging source instance weighting. It adds a module on top of pre-trained language models for similarity computation of instance weights, thus aligning each source instance to the target language. During training, the framework utilizes gradient descent that is weighted by instance weights to update parameters. We evaluate this framework over seven target languages on three fundamental tasks and show its effectiveness and extensibility, by improving on F1 score up to 4% in single-source transfer and 8% in multi-source transfer. To the best of our knowledge, our method is the first to apply instance weighting in zero-shot CLTC. It is simple yet effective and easily extensible into multi-source transfer.
Pre-trained multilingual language models have become an important building block in multilingual Natural Language Processing. In the present paper, we investigate a range of such models to find out how well they transfer discourse-level knowledge across languages. This is done with a systematic evaluation on a broader set of discourse-level tasks than has been previously been assembled. We find that the XLM-RoBERTa family of models consistently show the best performance, by simultaneously being good monolingual models and degrading relatively little in a zero-shot setting. Our results also indicate that model distillation may hurt the ability of cross-lingual transfer of sentence representations, while language dissimilarity at most has a modest effect. We hope that our test suite, covering 5 tasks with a total of 22 languages in 10 distinct families, will serve as a useful evaluation platform for multilingual performance at and beyond the sentence level.
Current pre-trained language models have lots of knowledge, but a more limited ability to use that knowledge. Bloom’s Taxonomy helps educators teach children how to use knowledge by categorizing comprehension skills, so we use it to analyze and improve the comprehension skills of large pre-trained language models. Our experiments focus on zero-shot question answering, using the taxonomy to provide proximal context that helps the model answer questions by being relevant to those questions. We show targeting context in this manner improves performance across 4 popular common sense question answer datasets.
Recent work has demonstrated the effectiveness of cross-lingual language model pretraining for cross-lingual understanding. In this study, we present the results of two larger multilingual masked language models, with 3.5B and 10.7B parameters. Our two new models dubbed and outperform XLM-R by 1.8% and 2.4% average accuracy on XNLI. Our model also outperforms the RoBERTa-Large model on several English tasks of the GLUE benchmark by 0.3% on average while handling 99 more languages. This suggests larger capacity models for language understanding may obtain strong performance on high-resource languages while greatly improving low-resource languages. We make our code and models publicly available.
It has been long known that sparsity is an effective inductive bias for learning efficient representation of data in vectors with fixed dimensionality, and it has been explored in many areas of representation learning. Of particular interest to this work is the investigation of the sparsity within the VAE framework which has been explored a lot in the image domain, but has been lacking even a basic level of exploration in NLP. Additionally, NLP is also lagging behind in terms of learning sparse representations of large units of text e.g., sentences. We use the VAEs that induce sparse latent representations of large units of text to address the aforementioned shortcomings. First, we move in this direction by measuring the success of unsupervised state-of-the-art (SOTA) and other strong VAE-based sparsification baselines for text and propose a hierarchical sparse VAE model to address the stability issue of SOTA. Then, we look at the implications of sparsity on text classification across 3 datasets, and highlight a link between performance of sparse latent representations on downstream tasks and its ability to encode task-related information.
Learning effective language representations from crowdsourced labels is crucial for many real-world machine learning tasks. A challenging aspect of this problem is that the quality of crowdsourced labels suffer high intra- and inter-observer variability. Since the high-capacity deep neural networks can easily memorize all disagreements among crowdsourced labels, directly applying existing supervised language representation learning algorithms may yield suboptimal solutions. In this paper, we propose TACMA, a temporal-aware language representation learning heuristic for crowdsourced labels with multiple annotators. The proposed approach (1) explicitly models the intra-observer variability with attention mechanism; (2) computes and aggregates per-sample confidence scores from multiple workers to address the inter-observer disagreements. The proposed heuristic is extremely easy to implement in around 5 lines of code. The proposed heuristic is evaluated on four synthetic and four real-world data sets. The results show that our approach outperforms a wide range of state-of-the-art baselines in terms of prediction accuracy and AUC. To encourage the reproducible results, we make our code publicly available at https://github.com/CrowdsourcingMining/TACMA.
Recently, impressive performance on various natural language understanding tasks has been achieved by explicitly incorporating syntax and semantic information into pre-trained models, such as BERT and RoBERTa. However, this approach depends on problem-specific fine-tuning, and as widely noted, BERT-like models exhibit weak performance, and are inefficient, when applied to unsupervised similarity comparison tasks. Sentence-BERT (SBERT) has been proposed as a general-purpose sentence embedding method, suited to both similarity comparison and downstream tasks. In this work, we show that by incorporating structural information into SBERT, the resulting model outperforms SBERT and previous general sentence encoders on unsupervised semantic textual similarity (STS) datasets and transfer classification tasks.
Recently, fine-tuning pre-trained language models (e.g., multilingual BERT) to downstream cross-lingual tasks has shown promising results. However, the fine-tuning process inevitably changes the parameters of the pre-trained model and weakens its cross-lingual ability, which leads to sub-optimal performance. To alleviate this problem, we leverage continual learning to preserve the original cross-lingual ability of the pre-trained model when we fine-tune it to downstream tasks. The experimental result shows that our fine-tuning methods can better preserve the cross-lingual ability of the pre-trained model in a sentence retrieval task. Our methods also achieve better performance than other fine-tuning baselines on the zero-shot cross-lingual part-of-speech tagging and named entity recognition tasks.
Learning a good latent representation is essential for text style transfer, which generates a new sentence by changing the attributes of a given sentence while preserving its content. Most previous works adopt disentangled latent representation learning to realize style transfer. We propose a novel text style transfer algorithm with entangled latent representation, and introduce a style classifier that can regulate the latent structure and transfer style. Moreover, our algorithm for style transfer applies to both single-attribute and multi-attribute transfer. Extensive experimental results show that our method generally outperforms state-of-the-art approaches.
Conventional Knowledge Graph Completion (KGC) assumes that all test entities appear during training. However, in real-world scenarios, Knowledge Graphs (KG) evolve fast with out-of-knowledge-graph (OOKG) entities added frequently, and we need to efficiently represent these entities. Most existing Knowledge Graph Embedding (KGE) methods cannot represent OOKG entities without costly retraining on the whole KG. To enhance efficiency, we propose a simple and effective method that inductively represents OOKG entities by their optimal estimation under translational assumptions. Moreover, given pretrained embeddings of the in-knowledge-graph (IKG) entities, our method even needs no additional learning. Experimental results on two KGC tasks with OOKG entities show that our method outperforms the previous methods by a large margin with higher efficiency.
Pretrained language models have served as the backbone for many state-of-the-art NLP results. These models are large and expensive to train. Recent work suggests that continued pretraining on task-specific data is worth the effort as pretraining leads to improved performance on downstream tasks. We explore alternatives to full-scale task-specific pretraining of language models through the use of adapter modules, a parameter-efficient approach to transfer learning. We find that adapter-based pretraining is able to achieve comparable results to task-specific pretraining while using a fraction of the overall trainable parameters. We further explore direct use of adapters without pretraining and find that the direct fine-tuning performs mostly on par with pretrained adapter models, contradicting previously proposed benefits of continual pretraining in full pretraining fine-tuning strategies. Lastly, we perform an ablation study on task-adaptive pretraining to investigate how different hyperparameter settings can change the effectiveness of the pretraining.
Strategies for improving the training and prediction quality of weakly supervised machine learning models vary in how much they are tailored to a specific task or integrated with a specific model architecture. In this work, we introduce Knodle, a software framework that treats weak data annotations, deep learning models, and methods for improving weakly supervised training as separate, modular components. This modularization gives the training process access to fine-grained information such as data set characteristics, matches of heuristic rules, or elements of the deep learning model ultimately used for prediction. Hence, our framework can encompass a wide range of training methods for improving weak supervision, ranging from methods that only look at correlations of rules and output classes (independently of the machine learning model trained with the resulting labels), to those that harness the interplay of neural networks and weakly labeled data. We illustrate the benchmarking potential of the framework with a performance comparison of several reference implementations on a selection of datasets that are already available in Knodle.
Task-oriented compositional semantic parsing (TCSP) handles complex nested user queries and serves as an essential component of virtual assistants. Current TCSP models rely on numerous training data to achieve decent performance but fail to generalize to low-resource target languages or domains. In this paper, we present X2Parser, a transferable Cross-lingual and Cross-domain Parser for TCSP. Unlike previous models that learn to generate the hierarchical representations for nested intents and slots, we propose to predict intents and slots separately and cast both prediction tasks into sequence labeling problems. After that, we further propose a fertility-based slot predictor that first learns to detect the number of labels for each token, and then predicts the slot types. Experimental results illustrate that our model can significantly outperform existing strong baselines in cross-lingual and cross-domain settings, and our model can also achieve a good generalization ability on target languages of target domains. Furthermore, we show that our model can reduce the latency by up to 66% compared to the generation-based model.
To highlight the challenges of achieving representation disentanglement for text domain in an unsupervised setting, in this paper we select a representative set of successfully applied models from the image domain. We evaluate these models on 6 disentanglement metrics, as well as on downstream classification tasks and homotopy. To facilitate the evaluation, we propose two synthetic datasets with known generative factors. Our experiments highlight the existing gap in the text domain and illustrate that certain elements such as representation sparsity (as an inductive bias), or representation coupling with the decoder could impact disentanglement. To the best of our knowledge, our work is the first attempt on the intersection of unsupervised representation disentanglement and text, and provides the experimental framework and datasets for examining future developments in this direction.
Existing supervised models for text clustering find it difficult to directly optimize for clustering results. This is because clustering is a discrete process and it is difficult to estimate meaningful gradient of any discrete function that can drive gradient based optimization algorithms. So, existing supervised clustering algorithms indirectly optimize for some continuous function that approximates the clustering process. We propose a scalable training strategy that directly optimizes for a discrete clustering metric. We train a BERT-based embedding model using our method and evaluate it on two publicly available datasets. We show that our method outperforms another BERT-based embedding model employing Triplet loss and other unsupervised baselines. This suggests that optimizing directly for the clustering outcome indeed yields better representations suitable for clustering.
We investigate the representations learned by vision and language models in tasks that require relational reasoning. Focusing on the problem of assessing the relative size of objects in abstract visual contexts, we analyse both one-step and two-step reasoning. For the latter, we construct a new dataset of three-image scenes and define a task that requires reasoning at the level of the individual images and across images in a scene. We probe the learned model representations using diagnostic classifiers. Our experiments show that pretrained multimodal transformer-based architectures can perform higher-level relational reasoning, and are able to learn representations for novel tasks and data that are very different from what was seen in pretraining.
We present an efficient training approach to text retrieval with dense representations that applies knowledge distillation using the ColBERT late-interaction ranking model. Specifically, we propose to transfer the knowledge from a bi-encoder teacher to a student by distilling knowledge from ColBERT’s expressive MaxSim operator into a simple dot product. The advantage of the bi-encoder teacher–student setup is that we can efficiently add in-batch negatives during knowledge distillation, enabling richer interactions between teacher and student models. In addition, using ColBERT as the teacher reduces training cost compared to a full cross-encoder. Experiments on the MS MARCO passage and document ranking tasks and data from the TREC 2019 Deep Learning Track demonstrate that our approach helps models learn robust representations for dense retrieval effectively and efficiently.
Word Embedding maps words to vectors of real numbers. It is derived from a large corpus and is known to capture semantic knowledge from the corpus. Word Embedding is a critical component of many state-of-the-art Deep Learning techniques. However, generating good Word Embeddings is a special challenge for low-resource languages such as Nepali due to the unavailability of large text corpus. In this paper, we present NPVec1 which consists of 25 state-of-art Word Embeddings for Nepali that we have derived from a large corpus using Glove, Word2Vec, FastText, and BERT. We further provide intrinsic and extrinsic evaluations of these Embeddings using well established metrics and methods. These models are trained using 279 million word tokens and are the largest Embeddings ever trained for Nepali language. Furthermore, we have made these Embeddings publicly available to accelerate the development of Natural Language Processing (NLP) applications in Nepali.
One of the long-standing challenges in lexical semantics consists in learning representations of words which reflect their semantic properties. The remarkable success of word embeddings for this purpose suggests that high-quality representations can be obtained by summarizing the sentence contexts of word mentions. In this paper, we propose a method for learning word representations that follows this basic strategy, but differs from standard word embeddings in two important ways. First, we take advantage of contextualized language models (CLMs) rather than bags of word vectors to encode contexts. Second, rather than learning a word vector directly, we use a topic model to partition the contexts in which words appear, and then learn different topic-specific vectors for each word. Finally, we use a task-specific supervision signal to make a soft selection of the resulting vectors. We show that this simple strategy leads to high-quality word vectors, which are more predictive of semantic properties than word embeddings and existing CLM-based strategies.
We investigate how sentence-level transformers can be modified into effective sequence labelers at the token level without any direct supervision. Existing approaches to zero-shot sequence labeling do not perform well when applied on transformer-based architectures. As transformers contain multiple layers of multi-head self-attention, information in the sentence gets distributed between many tokens, negatively affecting zero-shot token-level performance. We find that a soft attention module which explicitly encourages sharpness of attention weights can significantly outperform existing methods.
Transfer learning methods, and in particular domain adaptation, help exploit labeled data in one domain to improve the performance of a certain task in another domain. However, it is still not clear what factors affect the success of domain adaptation. This paper models adaptation success and selection of the most suitable source domains among several candidates in text similarity. We use descriptive domain information and cross-domain similarity metrics as predictive features. While mostly positive, the results also point to some domains where adaptation success was difficult to predict.
Selectional Preference (SP) captures the tendency of a word to semantically select other words to be in direct syntactic relation with it, and thus informs us about syntactic word configurations that are meaningful. Therefore SP is a valuable resource for Natural Language Processing (NLP) systems and for semanticists. Learning SP has generally been seen as a supervised task, because it requires a parsed corpus as a source of syntactically related word pairs. In this paper we show that simple distributional analysis can learn a good amount of SP without the need for an annotated corpus. We extend the general word embedding technique with directional word context windows giving word representations that better capture syntagmatic relations. We test on the SP-10K dataset and demonstrate that syntagmatic embeddings outperform the paradigmatic embeddings. We also evaluate supervised version of these embeddings and show that unsupervised syntagmatic embeddings can be as good as supervised embeddings. We also make available the source code of our implementation.
Most current quality estimation (QE) models for machine translation are trained and evaluated in a fully supervised setting requiring significant quantities of labelled training data. However, obtaining labelled data can be both expensive and time-consuming. In addition, the test data that a deployed QE model would be exposed to may differ from its training data in significant ways. In particular, training samples are often labelled by one or a small set of annotators, whose perceptions of translation quality and needs may differ substantially from those of end-users, who will employ predictions in practice. Thus, it is desirable to be able to adapt QE models efficiently to new user data with limited supervision data. To address these challenges, we propose a Bayesian meta-learning approach for adapting QE models to the needs and preferences of each user with limited supervision. To enhance performance, we further propose an extension to a state-of-the-art Bayesian meta-learning approach which utilizes a matrix-valued kernel for Bayesian meta-learning of quality estimation. Experiments on data with varying number of users and language characteristics demonstrates that the proposed Bayesian meta-learning approach delivers improved predictive performance in both limited and full supervision settings.
Smart assistants are tasked to answer various questions regarding world knowledge. These questions range from retrieval of simple facts to retrieval of complex, multi-hops question followed by various operators (i.e., filter, argmax). Semantic parsing has emerged as the state-of-the-art for answering these kinds of questions by forming queries to extract information from knowledge bases (KBs). Specially, neural semantic parsers (NSPs) effectively translate natural questions to logical forms, which execute on KB and give desirable answers. Yet, NSPs suffer from non-executable logical forms for some instances in the generated logical forms might be missing due to the incompleteness of KBs. Intuitively, knowing the KB structure informs NSP with changes of the global logical forms structures with respect to changes in KB instances. In this work, we propose a novel knowledge-informed decoder variant of NSP. We consider the conversational question answering settings, where a natural language query, its context and its final answers are available at training. Experimental results show that our method outperformed strong baselines by 1.8 F1 points overall across 10 types of questions of the CSQA dataset. Especially for the “Logical Reasoning” category, our model improves by 7 F1 points. Furthermore, our results are achieved with 90.3% fewer parameters, allowing faster training for large-scale datasets.
Pre-trained language models have emerged as highly successful methods for learning good text representations. However, the amount of structured knowledge retained in such models, and how (if at all) it can be extracted, remains an open question. In this work, we aim at directly learning text representations which leverage structured knowledge about entities mentioned in the text. This can be particularly beneficial for downstream tasks which are knowledge-intensive. Our approach utilizes self-attention between words in the text and knowledge graph (KG) entities mentioned in the text. While existing methods require entity-linked data for pre-training, we train using a mention-span masking objective and a candidate ranking objective – which doesn’t require any entity-links and only assumes access to an alias table for retrieving candidates, enabling large-scale pre-training. We show that the proposed model learns knowledge-informed text representations that yield improvements on the downstream tasks over existing methods.
Models based on the transformer architecture, such as BERT, have marked a crucial step forward in the field of Natural Language Processing. Importantly, they allow the creation of word embeddings that capture important semantic information about words in context. However, as single entities, these embeddings are difficult to interpret and the models used to create them have been described as opaque. Binder and colleagues proposed an intuitive embedding space where each dimension is based on one of 65 core semantic features. Unfortunately, the space only exists for a small data-set of 535 words, limiting its uses. Previous work (Utsumi, 2018, 2020; Turton et al., 2020) has shown that Binder features can be derived from static embeddings and successfully extrapolated to a large new vocabulary. Taking the next step, this paper demonstrates that Binder features can be derived from the BERT embedding space. This provides two things; (1) semantic feature values derived from contextualised word embeddings and (2) insights into how semantic features are represented across the different layers of the BERT model.
While vector-based language representations from pretrained language models have set a new standard for many NLP tasks, there is not yet a complete accounting of their inner workings. In particular, it is not entirely clear what aspects of sentence-level syntax are captured by these representations, nor how (if at all) they are built along the stacked layers of the network. In this paper, we aim to address such questions with a general class of interventional, input perturbation-based analyses of representations from pretrained language models. Importing from computational and cognitive neuroscience the notion of representational invariance, we perform a series of probes designed to test the sensitivity of these representations to several kinds of structure in sentences. Each probe involves swapping words in a sentence and comparing the representations from perturbed sentences against the original. We experiment with three different perturbations: (1) random permutations of n-grams of varying width, to test the scale at which a representation is sensitive to word position; (2) swapping of two spans which do or do not form a syntactic phrase, to test sensitivity to global phrase structure; and (3) swapping of two adjacent words which do or do not break apart a syntactic phrase, to test sensitivity to local phrase structure. Results from these probes collectively suggest that Transformers build sensitivity to larger parts of the sentence along their layers, and that hierarchical phrase structure plays a role in this process. More broadly, our results also indicate that structured input perturbations widens the scope of analyses that can be performed on often-opaque deep learning systems, and can serve as a complement to existing tools (such as supervised linear probes) for interpreting complex black-box models.
Learning representations of entities and relations in structured knowledge bases is an active area of research, with much emphasis placed on choosing the appropriate geometry to capture the hierarchical structures exploited in, for example, isa or haspart relations. Box embeddings (Vilnis et al., 2018; Li et al., 2019; Dasgupta et al., 2020), which represent concepts as n-dimensional hyperrectangles, are capable of embedding hierarchies when training on a subset of the transitive closure. In Patel et al., (2020), the authors demonstrate that only the transitive reduction is required and further extend box embeddings to capture joint hierarchies by augmenting the graph with new nodes. While it is possible to represent joint hierarchies with this method, the parameters for each hierarchy are decoupled, making generalization between hierarchies infeasible. In this work, we introduce a learned box-to-box transformation that respects the structure of each hierarchy. We demonstrate that this not only improves the capability of modeling cross-hierarchy compositional edges but is also capable of generalizing from a subset of the transitive reduction.
Recent advances in NLP systems, notably the pretraining-and-finetuning paradigm, have achieved great success in predictive accuracy. However, these systems are usually not well calibrated for uncertainty out-of-the-box. Many recalibration methods have been proposed in the literature for quantifying predictive uncertainty and calibrating model outputs, with varying degrees of complexity. In this work, we present a systematic study of a few of these methods. Focusing on the text classification task and finetuned large pretrained language models, we first show that many of the finetuned models are not well calibrated out-of-the-box, especially when the data come from out-of-domain settings. Next, we compare the effectiveness of a few widely-used recalibration methods (such as ensembles, temperature scaling). Then, we empirically illustrate a connection between distillation and calibration. We view distillation as a regularization term encouraging the student model to output uncertainties that match those of a teacher model. With this insight, we develop simple recalibration methods based on distillation with no additional inference-time cost. We show on the GLUE benchmark that our simple methods can achieve competitive out-of-domain (OOD) calibration performance w.r.t. more expensive approaches. Finally, we include ablations to understand the usefulness of components of our proposed method and examine the transferability of calibration via distillation.
Document-level relation extraction is a challenging task, requiring reasoning over multiple sentences to predict a set of relations in a document. In this paper, we propose a novel framework E2GRE (Entity and Evidence Guided Relation Extraction) that jointly extracts relations and the underlying evidence sentences by using large pretrained language model (LM) as input encoder. First, we propose to guide the pretrained LM’s attention mechanism to focus on relevant context by using attention probabilities as additional features for evidence prediction. Furthermore, instead of feeding the whole document into pretrained LMs to obtain entity representation, we concatenate document text with head entities to help LMs concentrate on parts of the document that are more related to the head entity. Our E2GRE jointly learns relation extraction and evidence prediction effectively, showing large gains on both these tasks, which we find are highly correlated.
Contrastive learning has been applied successfully to learn vector representations of text. Previous research demonstrated that learning high-quality representations benefits from batch-wise contrastive loss with a large number of negatives. In practice, the technique of in-batch negative is used, where for each example in a batch, other batch examples’ positives will be taken as its negatives, avoiding encoding extra negatives. This, however, still conditions each example’s loss on all batch examples and requires fitting the entire large batch into GPU memory. This paper introduces a gradient caching technique that decouples backpropagation between contrastive loss and the encoder, removing encoder backward pass data dependency along the batch dimension. As a result, gradients can be computed for one subset of the batch at a time, leading to almost constant memory usage.
The adoption of Transformer-based models in natural language processing (NLP) has led to great success using a massive number of parameters. However, due to deployment constraints in edge devices, there has been a rising interest in the compression of these models to improve their inference time and memory footprint. This paper presents a novel loss objective to compress token embeddings in the Transformer-based models by leveraging an AutoEncoder architecture. More specifically, we emphasize the importance of the direction of compressed embeddings with respect to original uncompressed embeddings. The proposed method is task-agnostic and does not require further language modeling pre-training. Our method significantly outperforms the commonly used SVD-based matrix-factorization approach in terms of initial language model Perplexity. Moreover, we evaluate our proposed approach over SQuAD v1.1 dataset and several downstream tasks from the GLUE benchmark, where we also outperform the baseline in most scenarios. Our code is public.
This paper presents the results and main findings of SemEval-2021 Task 1 - Lexical Complexity Prediction. We provided participants with an augmented version of the CompLex Corpus (Shardlow et al. 2020). CompLex is an English multi-domain corpus in which words and multi-word expressions (MWEs) were annotated with respect to their complexity using a five point Likert scale. SemEval-2021 Task 1 featured two Sub-tasks: Sub-task 1 focused on single words and Sub-task 2 focused on MWEs. The competition attracted 198 teams in total, of which 54 teams submitted official runs on the test data to Sub-task 1 and 37 to Sub-task 2.
We propose an ensemble model for predicting the lexical complexity of words and multiword expressions (MWEs). The model receives as input a sentence with a target word or MWE and outputs its complexity score. Given that a key challenge with this task is the limited size of annotated data, our model relies on pretrained contextual representations from different state-of-the-art transformer-based language models (i.e., BERT and RoBERTa), and on a variety of training methods for further enhancing model generalization and robustness: multi-step fine-tuning and multi-task learning, and adversarial training. Additionally, we propose to enrich contextual representations by adding hand-crafted features during training. Our model achieved competitive results and ranked among the top-10 systems in both sub-tasks.
In this paper, we introduce the first SemEval task on Multilingual and Cross-Lingual Word-in-Context disambiguation (MCL-WiC). This task allows the largely under-investigated inherent ability of systems to discriminate between word senses within and across languages to be evaluated, dropping the requirement of a fixed sense inventory. Framed as a binary classification, our task is divided into two parts. In the multilingual sub-task, participating systems are required to determine whether two target words, each occurring in a different context within the same language, express the same meaning or not. Instead, in the cross-lingual part, systems are asked to perform the task in a cross-lingual scenario, in which the two target words and their corresponding contexts are provided in two different languages. We illustrate our task, as well as the construction of our manually-created dataset including five languages, namely Arabic, Chinese, English, French and Russian, and the results of the participating systems. Datasets and results are available at: https://github.com/SapienzaNLP/mcl-wic.
This paper introduces the SemEval-2021 shared task 4: Reading Comprehension of Abstract Meaning (ReCAM). This shared task is designed to help evaluate the ability of machines in representing and understanding abstract concepts.Given a passage and the corresponding question, a participating system is expected to choose the correct answer from five candidates of abstract concepts in cloze-style machine reading comprehension tasks. Based on two typical definitions of abstractness, i.e., the imperceptibility and nonspecificity, our task provides three subtasks to evaluate models’ ability in comprehending the two types of abstract meaning and the models’ generalizability. Specifically, Subtask 1 aims to evaluate how well a participating system models concepts that cannot be directly perceived in the physical world. Subtask 2 focuses on models’ ability in comprehending nonspecific concepts located high in a hypernym hierarchy given the context of a passage. Subtask 3 aims to provide some insights into models’ generalizability over the two types of abstractness. During the SemEval-2021 official evaluation period, we received 23 submissions to Subtask 1 and 28 to Subtask 2. The participating teams additionally made 29 submissions to Subtask 3. The leaderboard and competition website can be found at https://competitions.codalab.org/competitions/26153. The data and baseline code are available at https://github.com/boyuanzheng010/SemEval2021-Reading-Comprehension-of-Abstract-Meaning.
This paper describes our system used in the SemEval-2021 Task4 Reading Comprehension of Abstract Meaning, achieving 1st for subtask 1 and 2nd for subtask 2 on the leaderboard. We propose an ensemble of ELECTRA-based models with task-adaptive pretraining and a multi-head attention multiple-choice classifier on top of the pre-trained model. The main contributions of our system are 1) revealing the performance discrepancy of different transformer-based pretraining models on the downstream task, 2) presentation of an efficient method to generate large task-adaptive corpora for pretraining. We also investigated several pretraining strategies and contrastive learning objectives. Our system achieves a test accuracy of 95.11 and 94.89 on subtask 1 and subtask 2 respectively.
The Toxic Spans Detection task of SemEval-2021 required participants to predict the spans of toxic posts that were responsible for the toxic label of the posts. The task could be addressed as supervised sequence labeling, using training data with gold toxic spans provided by the organisers. It could also be treated as rationale extraction, using classifiers trained on potentially larger external datasets of posts manually annotated as toxic or not, without toxic span annotations. For the supervised sequence labeling approach and evaluation purposes, posts previously labeled as toxic were crowd-annotated for toxic spans. Participants submitted their predicted spans for a held-out test set and were scored using character-based F1. This overview summarises the work of the 36 teams that provided system descriptions.
We describe SemEval-2021 task 6 on Detection of Persuasion Techniques in Texts and Images: the data, the annotation guidelines, the evaluation setup, the results, and the participating systems. The task focused on memes and had three subtasks: (i) detecting the techniques in the text, (ii) detecting the text spans where the techniques are used, and (iii) detecting techniques in the entire meme, i.e., both in the text and in the image. It was a popular task, attracting 71 registrations, and 22 teams that eventually made an official submission on the test set. The evaluation results for the third subtask confirmed the importance of both modalities, the text and the image. Moreover, some teams reported benefits when not just combining the two modalities, e.g., by using early or late fusion, but rather modeling the interaction between them in a joint model.
This paper describes our system participated in Task 6 of SemEval-2021: the task focuses on multimodal propaganda technique classification and it aims to classify given image and text into 22 classes. In this paper, we propose to use transformer based architecture to fuse the clues from both image and text. We explore two branches of techniques including fine-tuning the text pretrained transformer with extended visual features, and fine-tuning the multimodal pretrained transformers. For the visual features, we have tested both grid features based on ResNet and salient region features from pretrained object detector. Among the pretrained multimodal transformers, we choose ERNIE-ViL, a two-steam cross-attended transformers pretrained on large scale image-caption aligned data. Fine-tuing ERNIE-ViL for our task produce a better performance due to general joint multimodal representation for text and image learned by ERNIE-ViL. Besides, as the distribution of the classification labels is very unbalanced, we also make a further attempt on the loss function and the experiment result shows that focal loss would perform better than cross entropy loss. Last we have won first for subtask C in the final competition.
SemEval 2021 Task 7, HaHackathon, was the first shared task to combine the previously separate domains of humor detection and offense detection. We collected 10,000 texts from Twitter and the Kaggle Short Jokes dataset, and had each annotated for humor and offense by 20 annotators aged 18-70. Our subtasks were binary humor detection, prediction of humor and offense ratings, and a novel controversy task: to predict if the variance in the humor ratings was higher than a specific threshold. The subtasks attracted 36-58 submissions, with most of the participants choosing to use pre-trained language models. Many of the highest performing teams also implemented additional optimization techniques, including task-adaptive training and adversarial training. The results suggest that the participating systems are well suited to humor detection, but that humor controversy is a more challenging task. We discuss which models excel in this task, which auxiliary techniques boost their performance, and analyze the errors which were not captured by the best systems.
The present work aims at assigning a complexity score between 0 and 1 to a target word or phrase in a given sentence. For each Single Word Target, a Random Forest Regressor is trained on a feature set consisting of lexical, semantic, and syntactic information about the target. For each Multiword Target, a set of individual word features is taken along with single word complexities in the feature space. The system yielded the Pearson correlation of 0.7402 and 0.8244 on the test set for the Single and Multiword Targets, respectively.
This article describes a system to predict the complexity of words for the Lexical Complexity Prediction (LCP) shared task hosted at SemEval 2021 (Task 1) with a new annotated English dataset with a Likert scale. Located in the Lexical Semantics track, the task consisted of predicting the complexity value of the words in context. A machine learning approach was carried out based on the frequency of the words and several characteristics added at word level. Over these features, a supervised random forest regression algorithm was trained. Several runs were performed with different values to observe the performance of the algorithm. For the evaluation, our best results reported a M.A.E score of 0.07347, M.S.E. of 0.00938, and R.M.S.E. of 0.096871. Our experiments showed that, with a greater number of characteristics, the precision of the classification increases.
In this paper, we present our systems submitted to SemEval-2021 Task 1 on lexical complexity prediction.The aim of this shared task was to create systems able to predict the lexical complexity of word tokens and bigram multiword expressions within a given sentence context, a continuous value indicating the difficulty in understanding a respective utterance. Our approach relies on gradient boosted regression tree ensembles fitted using a heterogeneous feature set combining linguistic features, static and contextualized word embeddings, psycholinguistic norm lexica, WordNet, word- and character bigram frequencies and inclusion in wordlists to create a model able to assign a word or multiword expression a context-dependent complexity score. We can show that especially contextualised string embeddings can help with predicting lexical complexity.
In this paper, we present our contribution in SemEval-2021 Task 1: Lexical Complexity Prediction, where we integrate linguistic, statistical, and semantic properties of the target word and its context as features within a Machine Learning (ML) framework for predicting lexical complexity. In particular, we use BERT contextualized word embeddings to represent the semantic meaning of the target word and its context. We participated in the sub-task of predicting the complexity score of single words
This paper describes our submission to SemEval-2021 Task 1: predicting the complexity score for single words. Our model leverages standard morphosyntactic and frequency-based features that proved helpful for Complex Word Identification (a related task), and combines them with predictions made by Transformer-based pre-trained models that were fine-tuned on the Shared Task data. Our submission system stacks all previous models with a LightGBM at the top. One novelty of our approach is the use of multi-task learning for fine-tuning a pre-trained model for both Lexical Complexity Prediction and Word Sense Disambiguation. Our analysis shows that all independent models achieve a good performance in the task, but that stacking them obtains a Pearson correlation of 0.7704, merely 0.018 points behind the winning submission.
We describe the Uppsala NLP submission to SemEval-2021 Task 2 on multilingual and cross-lingual word-in-context disambiguation. We explore the usefulness of three pre-trained multilingual language models, XLM-RoBERTa (XLMR), Multilingual BERT (mBERT) and multilingual distilled BERT (mDistilBERT). We compare these three models in two setups, fine-tuning and as feature extractors. In the second case we also experiment with using dependency-based information. We find that fine-tuning is better than feature extraction. XLMR performs better than mBERT in the cross-lingual setting both with fine-tuning and feature extraction, whereas these two models give a similar performance in the multilingual setting. mDistilBERT performs poorly with fine-tuning but gives similar results to the other models when used as a feature extractor. We submitted our two best systems, fine-tuned with XLMR and mBERT.
In this paper, we present a system for the solution of the cross-lingual and multilingual word-in-context disambiguation task. Task organizers provided monolingual data in several languages, but no cross-lingual training data were available. To address the lack of the officially provided cross-lingual training data, we decided to generate such data ourselves. We describe a simple yet effective approach based on machine translation and back translation of the lexical units to the original language used in the context of this shared task. In our experiments, we used a neural system based on the XLM-R, a pre-trained transformer-based masked language model, as a baseline. We show the effectiveness of the proposed approach as it allows to substantially improve the performance of this strong neural baseline model. In addition, in this study, we present multiple types of the XLM-R based classifier, experimenting with various ways of mixing information from the first and second occurrences of the target word in two samples.
This paper presents our contribution to SemEval-2021 Task 2: Multilingual and Cross-lingual Word-in-Context Disambiguation (MCL-WiC). Our experiments cover English (EN-EN) sub-track from the multilingual setting of the task. We experiment with several pre-trained language models and investigate an impact of different top-layers on fine-tuning. We find the combination of Cosine Similarity and ReLU activation leading to the most effective fine-tuning procedure. Our best model results in accuracy 92.7%, which is the fourth-best score in EN-EN sub-track.
In this paper, we introduce our system that we participated with at the multilingual and cross-lingual word-in-context disambiguation SemEval 2021 shared task. In our experiments, we investigated the possibility of using an all-words fine-grained word sense disambiguation system trained purely on sense-annotated data in English and draw predictions on the semantic equivalence of words in context based on the similarity of the ranked lists of the (English) WordNet synsets returned for the target words decisions had to be made for. We overcame the multi,-and cross-lingual aspects of the shared task by applying a multilingual transformer for encoding the texts written in either Arabic, English, French, Russian and Chinese. While our results lag behind top scoring submissions, it has the benefit that it not only provides a binary flag whether two words in their context have the same meaning, but also provides a more tangible output in the form of a ranked list of (English) WordNet synsets irrespective of the language of the input texts. As our framework is designed to be as generic as possible, it can be applied as a baseline for basically any language (supported by the multilingual transformed architecture employed) even in the absence of any additional form of language specific training data.
This paper describes our system for Task 4 of SemEval-2021: Reading Comprehension of Abstract Meaning (ReCAM). We participated in all subtasks where the main goal was to predict an abstract word missing from a statement. We fine-tuned the pre-trained masked language models namely BERT and ALBERT and used an Ensemble of these as our submitted system on Subtask 1 (ReCAM-Imperceptibility) and Subtask 2 (ReCAM-Nonspecificity). For Subtask 3 (ReCAM-Intersection), we submitted the ALBERT model as it gives the best results. We tried multiple approaches and found that Masked Language Modeling(MLM) based approach works the best.
This paper describes our system for SemEval-2021 Task 4: Reading Comprehension of Abstract Meaning. To accomplish this task, we utilize the Knowledge-Enhanced Graph Attention Network (KEGAT) architecture with a novel semantic space transformation strategy. It leverages heterogeneous knowledge to learn adequate evidences, and seeks for an effective semantic space of abstract concepts to better improve the ability of a machine in understanding the abstract meaning of natural language. Experimental results show that our system achieves strong performance on this task in terms of both imperceptibility and nonspecificity.
We present our approaches and methods for SemEval-2021 Task-4 Reading Comprehension of Abstract Meaning. Given a question with a fill-in-the-blank, and a corresponding context, the task is to predict the most suitable word from a list of 5 options. There are three subtasks: Imperceptibility, Non-Specificity and Intersection. We use encoders of transformers-based models pretrained on the MLM task to build our Fill-in-the-blank (FitB) models. Moreover, to model imperceptibility, we define certain linguistic features, and to model non-specificity, we leverage information from hypernyms and hyponyms provided by a lexical database. Specifically, for non-specificity, we try out augmentation techniques, and other statistical techniques. We also propose variants, namely Chunk Voting and Max Context, to take care of input length restrictions for BERT, etc. Additionally, we perform a thorough ablation study, and use Integrated Gradients to explain our predictions on a few samples. Our models achieve accuracies of 75.31% and 77.84%, on the test sets for subtask-I and subtask-II, respectively. For subtask-III, we achieve accuracies of 65.64% and 64.27%.
This paper introduces our systems for all three subtasks of SemEval-2021 Task 4: Reading Comprehension of Abstract Meaning. To help our model better represent and understand abstract concepts in natural language, we well-design many simple and effective approaches adapted to the backbone model (RoBERTa). Specifically, we formalize the subtasks into the multiple-choice question answering format and add special tokens to abstract concepts, then, the final prediction of QA is considered as the result of subtasks. Additionally, we employ many finetuning tricks to improve the performance. Experimental results show that our approach gains significant performance compared with the baseline systems. Our system achieves eighth rank (87.51%) and tenth rank (89.64%) on the official blind test set of subtask 1 and subtask 2 respectively.
This paper presents a technical report of our submission to the 4th task of SemEval-2021, titled: Reading Comprehension of Abstract Meaning. In this task, we want to predict the correct answer based on a question given a context. Usually, contexts are very lengthy and require a large receptive field from the model. Thus, common contextualized language models like BERT miss fine representation and performance due to the limited capacity of the input tokens. To tackle this problem, we used the longformer model to better process the sequences. Furthermore, we utilized the method proposed in the longformer benchmark on wikihop dataset which improved the accuracy on our task data from (23.01% and 22.95%) achieved by the baselines for subtask 1 and 2, respectively, to (70.30% and 64.38%).
In this work, we present our approach and findings for SemEval-2021 Task 5 - Toxic Spans Detection. The task’s main aim was to identify spans to which a given text’s toxicity could be attributed. The task is challenging mainly due to two constraints: the small training dataset and imbalanced class distribution. Our paper investigates two techniques, semi-supervised learning and learning with Self-Adjusting Dice Loss, for tackling these challenges. Our submitted system (ranked ninth on the leader board) consisted of an ensemble of various pre-trained Transformer Language Models trained using either of the above-proposed techniques.
With the ever-increasing availability of digital information, toxic content is also on the rise. Therefore, the detection of this type of language is of paramount importance. We tackle this problem utilizing a combination of a state-of-the-art pre-trained language model (CharacterBERT) and a traditional bag-of-words technique. Since the content is full of toxic words that have not been written according to their dictionary spelling, attendance to individual characters is crucial. Therefore, we use CharacterBERT to extract features based on the word characters. It consists of a CharacterCNN module that learns character embeddings from the context. These are, then, fed into the well-known BERT architecture. The bag-of-words method, on the other hand, further improves upon that by making sure that some frequently used toxic words get labeled accordingly. With a ∼4 percent difference from the first team, our system ranked 36 th in the competition. The code is available for further research and reproduction of the results.
The real-world impact of polarization and toxicity in the online sphere marked the end of 2020 and the beginning of this year in a negative way. Semeval-2021, Task 5 - Toxic Spans Detection is based on a novel annotation of a subset of the Jigsaw Unintended Bias dataset and is the first language toxicity detection task dedicated to identifying the toxicity-level spans. For this task, participants had to automatically detect character spans in short comments that render the message as toxic. Our model considers applying Virtual Adversarial Training in a semi-supervised setting during the fine-tuning process of several Transformer-based models (i.e., BERT and RoBERTa), in combination with Conditional Random Fields. Our approach leads to performance improvements and more robust models, enabling us to achieve an F1-score of 65.73% in the official submission and an F1-score of 66.13% after further tuning during post-evaluation.
Toxicity detection of text has been a popular NLP task in the recent years. In SemEval-2021 Task-5 Toxic Spans Detection, the focus is on detecting toxic spans within English passages. Most state-of-the-art span detection approaches employ various techniques, each of which can be broadly classified into Token Classification or Span Prediction approaches. In our paper, we explore simple versions of both of these approaches and their performance on the task. Specifically, we use BERT-based models - BERT, RoBERTa, and SpanBERT for both approaches. We also combine these approaches and modify them to bring improvements for Toxic Spans prediction. To this end, we investigate results on four hybrid approaches - Multi-Span, Span+Token, LSTM-CRF, and a combination of predicted offsets using union/intersection. Additionally, we perform a thorough ablative analysis and analyze our observed results. Our best submission - a combination of SpanBERT Span Predictor and RoBERTa Token Classifier predictions - achieves an F1 score of 0.6753 on the test set. Our best post-eval F1 score is 0.6895 on intersection of predicted offsets from top-3 RoBERTa Token Classification checkpoints. These approaches improve the performance by 3% on average than those of the shared baseline models - RNNSL and SpaCy NER.
Toxicity is pervasive in social media and poses a major threat to the health of online communities. The recent introduction of pre-trained language models, which have achieved state-of-the-art results in many NLP tasks, has transformed the way in which we approach natural language processing. However, the inherent nature of pre-training means that they are unlikely to capture task-specific statistical information or learn domain-specific knowledge. Additionally, most implementations of these models typically do not employ conditional random fields, a method for simultaneous token classification. We show that these modifications can improve model performance on the Toxic Spans Detection task at SemEval-2021 to achieve a score within 4 percentage points of the top performing team.
Social network platforms are generally used to share positive, constructive, and insightful content. However, in recent times, people often get exposed to objectionable content like threat, identity attacks, hate speech, insults, obscene texts, offensive remarks or bullying. Existing work on toxic speech detection focuses on binary classification or on differentiating toxic speech among a small set of categories. This paper describes the system proposed by team Cisco for SemEval-2021 Task 5: Toxic Spans Detection, the first shared task focusing on detecting the spans in the text that attribute to its toxicity, in English language. We approach this problem primarily in two ways: a sequence tagging approach and a dependency parsing approach. In our sequence tagging approach we tag each token in a sentence under a particular tagging scheme. Our best performing architecture in this approach also proved to be our best performing architecture overall with an F1 score of 0.6922, thereby placing us 7th on the final evaluation phase leaderboard. We also explore a dependency parsing approach where we extract spans from the input sentence under the supervision of target span boundaries and rank our spans using a biaffine model. Finally, we also provide a detailed analysis of our results and model performance in our paper.
This paper describes the system submitted to SemEval 2021 Task 5: Toxic Spans Detection. The task concerns evaluating systems that detect the spans that make a text toxic when detecting such spans are possible. To address the possibly multi-span detection problem, we develop a start-to-end tagging framework on top of RoBERTa based language model. Besides, we design a custom loss function that takes distance into account. In comparison to other participating teams, our system has achieved 69.03% F1 score, which is slightly lower (-1.8 and -1.73) than the top 1(70.83%) and top 2 (70.77%), respectively.
This paper presents our system submission to task 5: Toxic Spans Detection of the SemEval-2021 competition. The competition aims at detecting the spans that make a toxic span toxic. In this paper, we demonstrate our system for detecting toxic spans, which includes expanding the toxic training set with Local Interpretable Model-Agnostic Explanations (LIME), fine-tuning RoBERTa model for detection, and error analysis. We found that feeding the model with an expanded training set using Reddit comments of polarized-toxicity and labeling with LIME on top of logistic regression classification could help RoBERTa more accurately learn to recognize toxic spans. We achieved a span-level F1 score of 0.6715 on the testing phase. Our quantitative and qualitative results show that the predictions from our system could be a good supplement to the gold training set’s annotations.
Simultaneous span detection and classification is a task not currently addressed in standard NLP frameworks. The present paper describes why and how an EncoderDecoder model was used to combine span detection and classification to address subtask 2 of SemEval-2021 Task 6.
In this paper, we describe our system submitted to SemEval 2021 Task 7: HaHackathon: Detecting and Rating Humor and Offense. The task aims at predicting whether the given text is humorous, the average humor rating given by the annotators, and whether the humor rating is controversial. In addition, the task also involves predicting how offensive the text is. Our approach adopts the DeBERTa architecture with disentangled attention mechanism, where the attention scores between words are calculated based on their content vectors and relative position vectors. We also took advantage of the pre-trained language models and fine-tuned the DeBERTa model on all the four subtasks. We experimented with several BERT-like structures and found that the large DeBERTa model generally performs better. During the evaluation phase, our system achieved an F-score of 0.9480 on subtask 1a, an RMSE of 0.5510 on subtask 1b, an F-score of 0.4764 on subtask 1c, and an RMSE of 0.4230 on subtask 2a (rank 3 on the leaderboard).
This paper introduces the result of Team Grenzlinie’s experiment in SemEval-2021 task 7: HaHackathon: Detecting and Rating Humor and Offense. This task has two subtasks. Subtask1 includes the humor detection task, the humor rating prediction task, and the humor controversy detection task. Subtask2 is an offensive rating prediction task. Detection task is a binary classification task, and the rating prediction task is a regression task between 0 to 5. 0 means the task is not humorous or not offensive, 5 means the task is very humorous or very offensive. For all the tasks, this paper chooses RoBERTa as the pre-trained model. In classification tasks, Bi-LSTM and adversarial training are adopted. In the regression task, the Bi-LSTM is also adopted. And then we propose a new approach named compare method. Finally, our system achieves an F1-score of 95.05% in the humor detection task, F1-score of 61.74% in the humor controversy detection task, 0.6143 RMSE in humor rating task, 0.4761 RMSE in the offensive rating task on the test datasets.
This paper describes our system participated in Task 7 of SemEval-2021: Detecting and Rating Humor and Offense. The task is designed to detect and score humor and offense which are influenced by subjective factors. In order to obtain semantic information from a large amount of unlabeled data, we applied unsupervised pre-trained language models. By conducting research and experiments, we found that the ERNIE 2.0 and DeBERTa pre-trained models achieved impressive performance in various subtasks. Therefore, we applied the above pre-trained models to fine-tune the downstream neural network. In the process of fine-tuning the model, we adopted multi-task training strategy and ensemble learning method. Based on the above strategy and method, we achieved RMSE of 0.4959 for subtask 1b, and finally won the first place.
Humor and Offense are highly subjective due to multiple word senses, cultural knowledge, and pragmatic competence. Hence, accurately detecting humorous and offensive texts has several compelling use cases in Recommendation Systems and Personalized Content Moderation. However, due to the lack of an extensive labeled dataset, most prior works in this domain haven’t explored large neural models for subjective humor understanding. This paper explores whether large neural models and their ensembles can capture the intricacies associated with humor/offense detection and rating. Our experiments on the SemEval-2021 Task 7: HaHackathon show that we can develop reasonable humor and offense detection systems with such models. Our models are ranked 3rd in subtask 1b and consistently ranked around the top 33% of the leaderboard for the remaining subtasks.
In this paper we describe the systems used by the RoMa team in the shared task on Detecting and Rating Humor and Offense (HaHackathon) at SemEval 2021. Our systems rely on data representations learned through fine-tuned neural language models. Particularly, we explore two distinct architectures. The first one is based on a Siamese Neural Network (SNN) combined with a graph-based clustering method. The SNN model is used for learning a latent space where instances of humor and non-humor can be distinguished. The clustering method is applied to build prototypes of both classes which are used for training and classifying new messages. The second one combines neural language model representations with a linear regression model which makes the final ratings. Our systems achieved the best results for humor classification using model one, whereas for offensive and humor rating the second model obtained better performance. In the case of the controversial humor prediction, the most significant improvement was achieved by a fine-tuning of the neural language model. In general, the results achieved are encouraging and give us a starting point for further improvements.
We describe MeasEval, a SemEval task of extracting counts, measurements, and related context from scientific documents, which is of significant importance to the creation of Knowledge Graphs that distill information from the scientific literature. This is a new task in 2021, for which over 75 submissions from 25 participants were received. We expect the data developed for this task and the findings reported to be valuable to the scientific knowledge extraction, metrology, and automated knowledge base construction communities.
Understanding tables is an important and relevant task that involves understanding table structure as well as being able to compare and contrast information within cells. In this paper, we address this challenge by presenting a new dataset and tasks that addresses this goal in a shared task in SemEval 2020 Task 9: Fact Verification and Evidence Finding for Tabular Data in Scientific Documents (SEM-TAB-FACTS). Our dataset contains 981 manually-generated tables and an auto-generated dataset of 1980 tables providing over 180K statement and over 16M evidence annotations. SEM-TAB-FACTS featured two sub-tasks. In sub-task A, the goal was to determine if a statement is supported, refuted or unknown in relation to a table. In sub-task B, the focus was on identifying the specific cells of a table that provide evidence for the statement. 69 teams signed up to participate in the task with 19 successful submissions to subtask A and 12 successful submissions to subtask B. We present our results and main findings from the competition.
Recently, there has been an interest in the research on factual verification and prediction over structured data like tables and graphs. To circumvent any false news incident, it is necessary to not only model and predict over structured data efficiently but also to explain those predictions. In this paper, as the part of the SemEval-2021 Task 9, we tackle the problem of fact verification and evidence finding over tabular data. There are two subtasks, in which given a table and a statement/fact, the subtask A is to determine whether the statement is inferred from the tabular data and the subtask B is to determine which cells in the table provide evidence for the former subtask. We make a comparison of the baselines and state of the art approaches over the given SemTabFact dataset. We also propose a novel approach CellBERT to solve the task of evidence finding, as a form of Natural Language Inference task. We obtain a 3-way F1 score of 0.69 on subtask A and an F1 score of 0.65 on subtask B.
Disagreement between coders is ubiquitous in virtually all datasets annotated with human judgements in both natural language processing and computer vision. However, most supervised machine learning methods assume that a single preferred interpretation exists for each item, which is at best an idealization. The aim of the SemEval-2021 shared task on learning with disagreements (Le-Wi-Di) was to provide a unified testing framework for methods for learning from data containing multiple and possibly contradictory annotations covering the best-known datasets containing information about disagreements for interpreting language and classifying images. In this paper we describe the shared task and its results.
This paper presents the Source-Free Domain Adaptation shared task held within SemEval-2021. The aim of the task was to explore adaptation of machine-learning models in the face of data sharing constraints. Specifically, we consider the scenario where annotations exist for a domain but cannot be shared. Instead, participants are provided with models trained on that (source) data. Participants also receive some labeled data from a new (development) domain on which to explore domain adaptation algorithms. Participants are then tested on data representing a new (target) domain. We explored this scenario with two different semantic tasks: negation detection (a text classification task) and time expression recognition (a sequence tagging task).
Domain adaptation assumes that samples from source and target domains are freely accessible during a training phase. However, such assumption is rarely plausible in the real-world and may causes data-privacy issues, especially when the label of the source domain can be a sensitive attribute as an identifier. SemEval-2021 task 10 focuses on these issues. We participate in the task and propose novel frameworks based on self-training method. In our systems, two different frameworks are designed to solve text classification and sequence labeling. These approaches are tested to be effective which ranks the third among all system in subtask A, and ranks the first among all system in subtask B.
There is currently a gap between the natural language expression of scholarly publications and their structured semantic content modeling to enable intelligent content search. With the volume of research growing exponentially every year, a search feature operating over semantically structured content is compelling. The SemEval-2021 Shared Task NLPContributionGraph (a.k.a. ‘the NCG task’) tasks participants to develop automated systems that structure contributions from NLP scholarly articles in the English language. Being the first-of-its-kind in the SemEval series, the task released structured data from NLP scholarly articles at three levels of information granularity, i.e. at sentence-level, phrase-level, and phrases organized as triples toward Knowledge Graph (KG) building. The sentence-level annotations comprised the few sentences about the article’s contribution. The phrase-level annotations were scientific term and predicate phrases from the contribution sentences. Finally, the triples constituted the research overview KG. For the Shared Task, participating systems were then expected to automatically classify contribution sentences, extract scientific terms and relations from the sentences, and organize them as KG triples. Overall, the task drew a strong participation demographic of seven teams and 27 participants. The best end-to-end task system classified contribution sentences at 57.27% F1, phrases at 46.41% F1, and triples at 22.28% F1. While the absolute performance to generate triples remains low, as conclusion to the article, the difficulty of producing such data and as a consequence of modeling it is highlighted.
We propose a cascade of neural models that performs sentence classification, phrase recognition, and triple extraction to automatically structure the scholarly contributions of NLP publications. To identify the most important contribution sentences in a paper, we used a BERT-based classifier with positional features (Subtask 1). A BERT-CRF model was used to recognize and characterize relevant phrases in contribution sentences (Subtask 2). We categorized the triples into several types based on whether and how their elements were expressed in text, and addressed each type using separate BERT-based classifiers as well as rules (Subtask 3). Our system was officially ranked second in Phase 1 evaluation and first in both parts of Phase 2 evaluation. After fixing a submission error in Pharse 1, our approach yields the best results overall. In this paper, in addition to a system description, we also provide further analysis of our results, highlighting its strengths and limitations. We make our code publicly available at https://github.com/Liu-Hy/nlp-contrib-graph.
SemEval-2021 Task 8: MeasEval aims at improving the machine understanding of measurements in scientific texts through a set of entity and semantic relation extraction sub-tasks on identifying quantity spans along with various attributes and relationships. This paper describes our system, consisting of a three-stage pipeline, that leverages pre-trained language models to extract the quantity spans in the text, followed by intelligent templates to identify units and modifiers. Finally, it identifies the quantity attributes and their relations using language models boosted with a feature re-using hierarchical architecture and multi-task learning. Our submission significantly outperforms the baseline, with the best model from the post-evaluation phase delivering more than 100% increase on F1 (Overall) from the baseline.
Scientific documents are replete with measurements mentioned in various formats and styles. As such, in a document with multiple quantities and measured entities, the task of associating each quantity to its corresponding measured entity is challenging. Thus, it is necessary to have a method to efficiently extract all measurements and attributes related to them. To this end, in this paper, we propose a novel model for the task of measurement relation extraction (MRE) whose goal is to recognize the relation between measured entities, quantities, and conditions mentioned in a document. Our model employs a deep translation-based architecture to dynamically induce the important words in the document to classify the relation between a pair of entities. Furthermore, we introduce a novel regularization technique based on Information Bottleneck (IB) to filter out the noisy information from the induced set of important words. Our experiments on the recent SemEval 2021 Task 8 datasets reveal the effectiveness of the proposed model.
MeasEval aims at identifying quantities along with the entities that are measured with additional properties within English scientific documents. The variety of styles used makes measurements, a most crucial aspect of scientific writing, challenging to extract. This paper presents ablation studies making the case for several preprocessing steps such as specialized tokenization rules. For linguistic structure, we encode dependency trees in a Deep Graph Convolution Network (DGCNN) for multi-task classification.
This paper explains the design of a heterogeneous system that ranked eighth in competition in SemEval2021 Task 8. We analyze ablation experiments and demonstrate how the system components, namely tokenizer, unit identifier, modifier classifier, and language model, affect the overall score. We compare our results to similar experiments from the literature and introduce a grouping algorithm developed in the post-evaluation phase that increased our system’s overall score, hypothetically elevating our competition rank from eight to six.
This paper describes our system for verifying statements with tables at SemEval-2021 Task 9. We developed a two-stage verifying system based on the latest table-based pre-trained model GraPPa. Multiple networks are devised to verify different types of statements in the competition dataset and an adaptive model ensembling technique is applied to ensemble models in both stages. A statement-slot-based symbolic operation module is also used in our system to further improve the performance and stability of the system. Our model achieves second place in the 3-way classification and fourth place in the 2-way classification evaluation. Several ablation experiments show the effectiveness of different modules proposed in this paper.
We present the TAPAS contribution to the Shared Task on Statement Verification and Evidence Finding with Tables (SemEval 2021 Task 9, Wang et al. (2021)). SEM TAB FACT Task A is a classification task of recognizing if a statement is entailed, neutral or refuted by the content of a given table. We adopt the binary TAPAS model of Eisenschlos et al. (2020) to this task. We learn two binary classification models: A first model to predict if a statement is neutral or non-neutral and a second one to predict if it is entailed or refuted. As the shared task training set contains only entailed or refuted examples, we generate artificial neutral examples to train the first model. Both models are pre-trained using a MASKLM objective, intermediate counter-factual and synthetic data (Eisenschlos et al., 2020) and TABFACT (Chen et al., 2020), a large table entailment dataset. We find that the artificial neutral examples are somewhat effective at training the first model, achieving 68.03 test F1 versus the 60.47 of a majority baseline. For the second stage, we find that the pre-training on the intermediate data and TABFACT improves the results over MASKLM pre-training (68.03 vs 57.01).
In this paper, we present our text augmentation based approach for the Table Statement Support Subtask (Phase A) of SemEval-2021 Task 9. We experiment with different text augmentation techniques such as back translation and synonym swapping using Word2Vec and WordNet. We show that text augmentation techniques lead to 2.5% improvement in F1 on the test set. Further, we investigate the impact of domain adaptation and joint learning on fact verification in tabular data by utilizing the SemTabFacts and TabFact datasets. We observe that joint learning improves the F1 scores on the SemTabFacts and TabFact test sets by 3.31% and 0.77%, respectively.
Recent progress in deep learning has primarily been fueled by the availability of large amounts of annotated data that is obtained from highly expensive manual annotating pro-cesses. To tackle this issue of availability of annotated data, a lot of research has been done on unsupervised domain adaptation that tries to generate systems for an unlabelled target domain data, given labeled source domain data. However, the availability of annotated or labelled source domain dataset can’t always be guaranteed because of data-privacy issues. This is especially the case with medical data, as it may contain sensitive information of the patients. Source-free domain adaptation (SFDA) aims to resolve this issue by us-ing models trained on the source data instead of using the original annotated source data. In this work, we try to build SFDA systems for semantic processing by specifically focusing on the negation detection subtask of the SemEval2021 Task 10. We propose two approaches -ProtoAUGandAdapt-ProtoAUGthat use the idea of self-entropy to choose reliable and high confidence samples, which are then used for data augmentation and subsequent training of the models. Our methods report an improvement of up to 7% in F1 score over the baseline for the Negation Detection subtask.
This paper describes PTST, a source-free unsupervised domain adaptation technique for sequence tagging, and its application to the SemEval-2021 Task 10 on time expression recognition. PTST is an extension of the cross-lingual parsimonious parser transfer framework, which uses high-probability predictions of the source model as a supervision signal in self-training. We extend the framework to a sequence prediction setting, and demonstrate its applicability to unsupervised domain adaptation. PTST achieves F1 score of 79.6% on the official test set, with the precision of 90.1%, the highest out of 14 submissions.
Source-free domain adaptation is an emerging line of work in deep learning research since it is closely related to the real-world environment. We study the domain adaption in the sequence labeling problem where the model trained on the source domain data is given. We propose two methods: Self-Adapter and Selective Classifier Training. Self-Adapter is a training method that uses sentence-level pseudo-labels filtered by the self-entropy threshold to provide supervision to the whole model. Selective Classifier Training uses token-level pseudo-labels and supervises only the classification layer of the model. The proposed methods are evaluated on data provided by SemEval-2021 task 10 and Self-Adapter achieves 2nd rank performance.
This paper describes our systems for negation detection and time expression recognition in SemEval 2021 Task 10, Source-Free Domain Adaptation for Semantic Processing. We show that self-training, active learning and data augmentation techniques can improve the generalization ability of the model on the unlabeled target domain data without accessing source domain data. We also perform detailed ablation studies and error analyses for our time expression recognition systems to identify the source of the performance improvement and give constructive feedback on the temporal normalization annotation guidelines.
Research in Natural Language Processing is making rapid advances, resulting in the publication of a large number of research papers. Finding relevant research papers and their contribution to the domain is a challenging problem. In this paper, we address this challenge via the SemEval 2021 Task 11: NLPContributionGraph, by developing a system for a research paper contributions-focused knowledge graph over Natural Language Processing literature. The task is divided into three sub-tasks: extracting contribution sentences that show important contributions in the research article, extracting phrases from the contribution sentences, and predicting the information units in the research article together with triplet formation from the phrases. The proposed system is agnostic to the subject domain and can be applied for building a knowledge graph for any area. We found that transformer-based language models can significantly improve existing techniques and utilized the SciBERT-based model. Our first sub-task uses Bidirectional LSTM (BiLSTM) stacked on top of SciBERT model layers, while the second sub-task uses Conditional Random Field (CRF) on top of SciBERT with BiLSTM. The third sub-task uses a combined SciBERT based neural approach with heuristics for information unit prediction and triplet formation from the phrases. Our system achieved F1 score of 0.38, 0.63 and 0.76 in end-to-end pipeline testing, phrase extraction testing and triplet extraction testing respectively.
This paper describes the system we built as the YNU-HPCC team in the SemEval-2021 Task 11: NLPContributionGraph. This task involves first identifying sentences in the given natural language processing (NLP) scholarly articles that reflect research contributions through binary classification; then identifying the core scientific terms and their relation phrases from these contribution sentences by sequence labeling; and finally, these scientific terms and relation phrases are categorized, identified, and organized into subject-predicate-object triples to form a knowledge graph with the help of multiclass classification and multi-label classification. We developed a system for this task using a pre-trained language representation model called BERT that stands for Bidirectional Encoder Representations from Transformers, and achieved good results. The average F1-score for Evaluation Phase 2, Part 1 was 0.4562 and ranked 7th, and the average F1-score for Evaluation Phase 2, Part 2 was 0.6541, and also ranked 7th.
This paper describes the winning system in the End-to-end Pipeline phase for the NLPContributionGraph task. The system is composed of three BERT-based models and the three models are used to extract sentences, entities and triples respectively. Experiments show that sampling and adversarial training can greatly boost the system. In End-to-end Pipeline phase, our system got an average F1 of 0.4703, significantly higher than the second-placed system which got an average F1 of 0.3828.
This paper describes the Duluth system that participated in SemEval-2021 Task 11, NLP Contribution Graph. It details the extraction of contribution sentences and scientific entities and their relations from scholarly articles in the domain of Natural Language Processing. Our solution uses deBERTa for multi-class sentence classification to extract the contributing sentences and their type, and dependency parsing to outline each sentence and extract subject-predicate-object triples. Our system ranked fifth of seven for Phase 1: end-to-end pipeline, sixth of eight for Phase 2 Part 1: phrases and triples, and fifth of eight for Phase 2 Part 2: triples extraction.
In this work, we describe our system submission to the SemEval 2021 Task 11: NLP Contribution Graph Challenge. We attempt all the three sub-tasks in the challenge and report our results. Subtask 1 aims to identify the contributing sentences in a given publication. Subtask 2 follows from Subtask 1 to extract the scientific term and predicate phrases from the identified contributing sentences. The final Subtask 3 entails extracting triples (subject, predicate, object) from the phrases and categorizing them under one or more defined information units. With the NLPContributionGraph Shared Task, the organizers formalized the building of a scholarly contributions-focused graph over NLP scholarly articles as an automated task. Our approaches include a BERT-based classification model for identifying the contributing sentences in a research publication, a rule-based dependency parsing for phrase extraction, followed by a CNN-based model for information units classification, and a set of rules for triples extraction. The quantitative results show that we obtain the 5th, 5th, and 7th rank respectively in three evaluation phases. We make our codes available at https://github.com/HardikArora17/SemEval-2021-INNOVATORS.
In this work, we present our approach for solving the SemEval 2021 Task 2: Multilingual and Cross-lingual Word-in-Context Disambiguation (MCL-WiC). The task is a sentence pair classification problem where the goal is to detect whether a given word common to both the sentences evokes the same meaning. We submit systems for both the settings - Multilingual (the pair’s sentences belong to the same language) and Cross-Lingual (the pair’s sentences belong to different languages). The training data is provided only in English. Consequently, we employ cross-lingual transfer techniques. Our approach employs fine-tuning pre-trained transformer-based language models, like ELECTRA and ALBERT, for the English task and XLM-R for all other tasks. To improve these systems’ performance, we propose adding a signal to the word to be disambiguated and augmenting our data by sentence pair reversal. We further augment the dataset provided to us with WiC, XL-WiC and SemCor 3.0. Using ensembles, we achieve strong performance in the Multilingual task, placing first in the EN-EN and FR-FR sub-tasks. For the Cross-Lingual setting, we employed translate-test methods and a zero-shot method, using our multilingual models, with the latter performing slightly better.
This paper presents the winning system that participated in SemEval-2021 Task 5: Toxic Spans Detection. This task aims to locate those spans that attribute to the text’s toxicity within a text, which is crucial for semi-automated moderation in online discussions. We formalize this task as the Sequence Labeling (SL) problem and the Span Boundary Detection (SBD) problem separately and employ three state-of-the-art models. Next, we integrate predictions of these models to produce a more credible and complement result. Our system achieves a char-level score of 70.83%, ranking 1/91. In addition, we also explore the lexicon-based method, which is strongly interpretable and flexible in practice.
This paper presents one of the top winning solution systems for task 7 at SemEval2021, HaHackathon: Detecting and Rating Humor and Offense. This competition is divided into two tasks, task1 with three sub-tasks 1a,1b, and 1c, and task2. The goal for task1 is to predict if the text would be considered humorous or not, and if it is yes, then predict how humorous it is and whether the humor rating would be perceived as controversial. The goal of the task2 is to predict how the text is considered offensive for users in general. Our solution has been developed using RoBERTa pre-trained model with ensemble techniques. The paper describes the submitted solution system’s architecture with the experiments and the hyperparameter tuning that led to this robust system. Our model ranked third and fourth places out of 50 teams in tasks 1c and 1a with F1-Score of 0.6270 and 0.9675, respectively. At the same time, the model ranked one of the top 10 models in task 1b and task 2 with an RMSE scores of 0.5446 and 0.4469, respectively.
Extracting semantic information on measurements and counts is an important topic in terms of analyzing scientific discourses. The 8th task of SemEval-2021: Counts and Measurements (MeasEval) aimed to boost research in this direction by providing a new dataset on which participants train their models to extract meaningful information on measurements from scientific texts. The competition is composed of five subtasks that build on top of each other: (1) quantity span identification, (2) unit extraction from the identified quantities and their value modifier classification, (3) span identification for measured entities and measured properties, (4) qualifier span identification, and (5) relation extraction between the identified quantities, measured entities, measured properties, and qualifiers. We approached these challenges by first identifying the quantities, extracting their units of measurement, classifying them with corresponding modifiers, and afterwards using them to jointly solve the last three subtasks in a multi-turn question answering manner. Our best performing model obtained an overlapping F1-score of 36.91% on the test set.
This paper describes our contribution to SemEval 2021 Task 1 (Shardlow et al., 2021): Lexical Complexity Prediction. In our approach, we leverage the ELECTRA model and attempt to mirror the data annotation scheme. Although the task is a regression task, we show that we can treat it as an aggregation of several classification and regression models. This somewhat counter-intuitive approach achieved an MAE score of 0.0654 for Sub-Task 1 and MAE of 0.0811 on Sub-Task 2. Additionally, we used the concept of weak supervision signals from Gloss-BERT in our work, and it significantly improved the MAE score in Sub-Task 1.
This paper describes team LCP-RIT’s submission to the SemEval-2021 Task 1: Lexical Complexity Prediction (LCP). The task organizers provided participants with an augmented version of CompLex (Shardlow et al., 2020), an English multi-domain dataset in which words in context were annotated with respect to their complexity using a five point Likert scale. Our system uses logistic regression and a wide range of linguistic features (e.g. psycholinguistic features, n-grams, word frequency, POS tags) to predict the complexity of single words in this dataset. We analyze the impact of different linguistic features on the classification performance and we evaluate the results in terms of mean absolute error, mean squared error, Pearson correlation, and Spearman correlation.
This paper revisits feature engineering approaches for predicting the complexity level of English words in a particular context using regression techniques. Our best submission to the Lexical Complexity Prediction (LCP) shared task was ranked 3rd out of 48 systems for sub-task 1 and achieved Pearson correlation coefficients of 0.779 and 0.809 for single words and multi-word expressions respectively. The conclusion is that a combination of lexical, contextual and semantic features can still produce strong baselines when compared against human judgement.
This paper describes the CompNa model that has been submitted to the Lexical Complexity Prediction (LCP) shared task hosted at SemEval 2021 (Task 1). The solution is based on combining features of different nature through an ensambling method based on Decision Trees and trained using Gradient Boosting. We discuss the results of the model and highlight the features with more predictive capabilities.
In this contribution, we describe the system presented by the PolyU CBS-Comp Team at the Task 1 of SemEval 2021, where the goal was the estimation of the complexity of words in a given sentence context. Our top system, based on a combination of lexical, syntactic, word embeddings and Transformers-derived features and on a Gradient Boosting Regressor, achieves a top correlation score of 0.754 on the subtask 1 for single words and 0.659 on the subtask 2 for multiword expressions.
This paper describes the system developed by the Laboratoire d’analyse statistique des textes (LAST) for the Lexical Complexity Prediction shared task at SemEval-2021. The proposed system is made up of a LightGBM model fed with features obtained from many word frequency lists, published lexical norms and psychometric data. For tackling the specificity of the multi-word task, it uses bigram association measures. Despite that the only contextual feature used was sentence length, the system achieved an honorable performance in the multi-word task, but poorer in the single word task. The bigram association measures were found useful, but to a limited extent.
Lexical complexity plays an important role in reading comprehension. lexical complexity prediction (LCP) can not only be used as a part of Lexical Simplification systems, but also as a stand-alone application to help people better reading. This paper presents the winning system we submitted to the LCP Shared Task of SemEval 2021 that capable of dealing with both two subtasks. We first perform fine-tuning on numbers of pre-trained language models (PLMs) with various hyperparameters and different training strategies such as pseudo-labelling and data augmentation. Then an effective stacking mechanism is applied on top of the fine-tuned PLMs to obtain the final prediction. Experimental results on the Complex dataset show the validity of our method and we rank first and second for subtask 2 and 1.
Lexical Complexity Prediction (LCP) involves assigning a difficulty score to a particular word or expression, in a text intended for a target audience. In this paper, we introduce a new deep learning-based system for this challenging task. The proposed system consists of a deep learning model, based on pre-trained transformer encoder, for word and Multi-Word Expression (MWE) complexity prediction. First, on top of the encoder’s contextualized word embedding, our model employs an attention layer on the input context and the complex word or MWE. Then, the attention output is concatenated with the pooled output of the encoder and passed to a regression module. We investigate both single-task and joint training on both Sub-Tasks data using multiple pre-trained transformer-based encoders. The obtained results are very promising and show the effectiveness of fine-tuning pre-trained transformers for LCP task.
This paper describes our submission to the SemEval-2021 shared task on Lexical Complexity Prediction. We approached it as a regression problem and present an ensemble combining four systems, one feature-based and three neural with fine-tuning, frequency pre-training and multi-task learning, achieving Pearson scores of 0.8264 and 0.7556 on the trial and test sets respectively (sub-task 1). We further present our analysis of the results and discuss our findings.
In this paper, we propose a method of fusing sentence information and word frequency information for the SemEval 2021 Task 1-Lexical Complexity Prediction (LCP) shared task. In our system, the sentence information comes from the RoBERTa model, and the word frequency information comes from the Tf-Idf algorithm. Use Inception block as a shared layer to learn sentence and word frequency information We described the implementation of our best system and discussed our methods and experiments in the task. The shared task is divided into two sub-tasks. The goal of the two sub-tasks is to predict the complexity of a predetermined word. The shared task is divided into two subtasks. The goal of the two subtasks is to predict the complexity of a predetermined word. The evaluation index of the task is the Pearson correlation coefficient. Our best performance system has Pearson correlation coefficients of 0.7434 and 0.8000 in the single-token subtask test set and the multi-token subtask test set, respectively.
We present two convolutional neural networks for predicting the complexity of words and phrases in context on a continuous scale. Both models utilize word and character embeddings alongside lexical features as inputs. Our system displays reasonable results with a Pearson correlation of 0.7754 on the task as a whole. We highlight the limitations of this method in properly assessing the context of the target text, and explore the effectiveness of both systems across a range of genres. Both models were submitted as part of LCP 2021, which focuses on the identification of complex words and phrases as a context dependent, regression based task.
Reading is a complex process which requires proper understanding of texts in order to create coherent mental representations. However, comprehension problems may arise due to hard-to-understand sections, which can prove troublesome for readers, while accounting for their specific language skills. As such, steps towards simplifying these sections can be performed, by accurately identifying and evaluating difficult structures. In this paper, we describe our approach for the SemEval-2021 Task 1: Lexical Complexity Prediction competition that consists of a mixture of advanced NLP techniques, namely Transformer-based language models, pre-trained word embeddings, Graph Convolutional Networks, Capsule Networks, as well as a series of hand-crafted textual complexity features. Our models are applicable on both subtasks and achieve good performance results, with a MAE below 0.07 and a Person correlation of .73 for single word identification, as well as a MAE below 0.08 and a Person correlation of .79 for multiple word targets. Our results are just 5.46% and 6.5% lower than the top scores obtained in the competition on the first and the second subtasks, respectively.
We describe the UTFPR systems submitted to the Lexical Complexity Prediction shared task of SemEval 2021. They perform complexity prediction by combining classic features, such as word frequency, n-gram frequency, word length, and number of senses, with BERT vectors. We test numerous feature combinations and machine learning models in our experiments and find that BERT vectors, even if not optimized for the task at hand, are a great complement to classic features. We also find that employing the principle of compositionality can potentially help in phrase complexity prediction. Our systems place 45th out of 55 for single words and 29th out of 38 for phrases.
In this paper we propose a contextual attention based model with two-stage fine-tune training using RoBERTa. First, we perform the first-stage fine-tune on corpus with RoBERTa, so that the model can learn some prior domain knowledge. Then we get the contextual embedding of context words based on the token-level embedding with the fine-tuned model. And we use Kfold cross-validation to get K models and ensemble them to get the final result. Finally, we attain the 2nd place in the final evaluation phase of sub-task 2 with pearson correlation of 0.8575.
Lexical complexity prediction (LCP) conveys the anticipation of the complexity level of a token or a set of tokens in a sentence. It plays a vital role in the improvement of various NLP tasks including lexical simplification, translations, and text generation. However, multiple meaning of a word in multiple circumstances, grammatical complex structure, and the mutual dependency of words in a sentence make it difficult to estimate the lexical complexity. To address these challenges, SemEval-2021 Task 1 introduced a shared task focusing on LCP and this paper presents our participation in this task. We proposed a transformer-based approach with sentence pair regression. We employed two fine-tuned transformer models. Including BERT and RoBERTa to train our model and fuse their predicted score to the complexity estimation. Experimental results demonstrate that our proposed method achieved competitive performance compared to the participants’ systems.
This paper presents the system we submitted to the first Lexical Complexity Prediction (LCP) Shared Task 2021. The Shared Task provides participants with a new English dataset that includes context of the target word. We participate in the single-word complexity prediction sub-task and focus on feature engineering. Our best system is trained on linguistic features and word embeddings (Pearson’s score of 0.7942). We demonstrate, however, that a simpler feature set achieves comparable results and submit a model trained on 36 linguistic features (Pearson’s score of 0.7925).
We present the technical report of the system called RS_GV at SemEval-2021 Task 1 on lexical complexity prediction of English words. RS_GV is a neural network using hand-crafted linguistic features in combination with character and word embeddings to predict target words’ complexity. For the generation of the hand-crafted features, we set the target words in relation to their senses. RS_GV predicts the complexity well of biomedical terms but it has problems with the complexity prediction of very complex and very simple target words.
In this paper, we present three supervised systems for English lexical complexity prediction of single and multiword expressions for SemEval-2021 Task 1. We explore the use of statistical baseline features, masked language models, and character-level encoders to predict the complexity of a target token in context. Our best system combines information from these three sources. The results indicate that information from masked language models and character-level encoders can be combined to improve lexical complexity prediction.
In this paper we describe our participation in the Lexical Complexity Prediction (LCP) shared task of SemEval 2021, which involved predicting subjective ratings of complexity for English single words and multi-word expressions, presented in context. Our approach relies on a combination of distributional models, both context-dependent and context-independent, together with behavioural norms and lexical resources.
Predicting the complexity level of a word or a phrase is considered a challenging task. It is even recognized as a crucial step in numerous NLP applications, such as text rearrangements and text simplification. Early research treated the task as a binary classification task, where the systems anticipated the existence of a word’s complexity (complex versus uncomplicated). Other studies had been designed to assess the level of word complexity using regression models or multi-labeling classification models. Deep learning models show a significant improvement over machine learning models with the rise of transfer learning and pre-trained language models. This paper presents our approach that won the first rank in the SemEval-task1 (sub stask1). We have calculated the degree of word complexity from 0-1 within a text. We have been ranked first place in the competition using the pre-trained language models Bert and RoBERTa, with a Pearson correlation score of 0.788.
This paper describes a system submitted by team BigGreen to LCP 2021 for predicting the lexical complexity of English words in a given context. We assemble a feature engineering-based model with a deep neural network model founded on BERT. While BERT itself performs competitively, our feature engineering-based model helps in extreme cases, eg. separating instances of easy and neutral difficulty. Our handcrafted features comprise a breadth of lexical, semantic, syntactic, and novel phonological measures. Visualizations of BERT attention maps offer insight into potential features that Transformers models may learn when fine-tuned for lexical complexity prediction. Our ensembled predictions score reasonably well for the single word subtask, and we demonstrate how they can be harnessed to perform well on the multi word expression subtask too.
The main contribution of this paper is to fine-tune transformer-based language models pre-trained on several text corpora, some being general (E.g., Wikipedia, BooksCorpus), some being the corpora from which the CompLex Dataset was extracted, and others being from other specific domains such as Finance, Law, etc. We perform ablation studies on selecting the transformer models and how their individual complexity scores are aggregated to get the resulting complexity scores. Our method achieves a best Pearson Correlation of 0.784 in sub-task 1 (single word) and 0.836 in sub-task 2 (multiple word expressions).
We present our approach to predicting lexical complexity of words in specific contexts, as entered LCP Shared Task 1 at SemEval 2021. The approach consists of separating sentences into smaller chunks, embedding them with Sent2Vec, and reducing the embeddings into a simpler vector used as input to a neural network, the latter for predicting the complexity of words and expressions. Results show that the pre-trained sentence embeddings are not able to capture lexical complexity from the language when applied in cross-domain applications.
This paper presents our system for the single- and multi-word lexical complexity prediction tasks of SemEval Task 1: Lexical Complexity Prediction. Text comprehension depends on the reader’s ability to understand the words present in it; evaluating the lexical complexity of such texts can enable readers to find an appropriate text and systems to tailor a text to an audience’s needs. We present our model pipeline, which applies a combination of embedding-based and manual features to predict lexical complexity on the CompLex English dataset using various tree-based and linear models. Our method is ranked 27 / 54 on single-word prediction and 14 / 37 on multi-word prediction.
Evaluating the complexity of a target word in a sentential context is the aim of the Lexical Complexity Prediction task at SemEval-2021. This paper presents the system created to assess single words lexical complexity, combining linguistic and psycholinguistic variables in a set of experiments involving random forest and XGboost regressors. Beyond encoding out-of-context information about the lemma, we implemented features based on pre-trained language models to model the target word’s in-context complexity.
This paper describes systems submitted to Se- mEval 2021 Task 1: Lexical Complexity Prediction (LCP). We compare a linear and a non-linear regression models trained to work for both tracks of the task. We show that both systems are able to generalize better when supplied with information about complexities of single word and multi-word expression (MWE) targets simultaneously. This approach proved to be the most beneficial for multi-word expression targets. We also demonstrate that some hand-crafted features differ in their importance for the target types.
This paper presents the GX system for the Multilingual and Cross-lingual Word-in-Context Disambiguation (MCL-WiC) task. The purpose of the MCL-WiC task is to tackle the challenge of capturing the polysemous nature of words without relying on a fixed sense inventory in a multilingual and cross-lingual setting. To solve the problems, we use context-specific word embeddings from BERT to eliminate the ambiguity between words in different contexts. For languages without an available training corpus, such as Chinese, we use neuron machine translation model to translate the English data released by the organizers to obtain available pseudo-data. In this paper, we apply our system to the English and Chinese multilingual setting and the experimental results show that our method has certain advantages.
This paper presents the PALI team’s winning system for SemEval-2021 Task 2: Multilingual and Cross-lingual Word-in-Context Disambiguation. We fine-tune XLM-RoBERTa model to solve the task of word in context disambiguation, i.e., to determine whether the target word in the two contexts contains the same meaning or not. In implementation, we first specifically design an input tag to emphasize the target word in the contexts. Second, we construct a new vector on the fine-tuned embeddings from XLM-RoBERTa and feed it to a fully-connected network to output the probability of whether the target word in the context has the same meaning or not. The new vector is attained by concatenating the embedding of the [CLS] token and the embeddings of the target word in the contexts. In training, we explore several tricks, such as the Ranger optimizer, data augmentation, and adversarial training, to improve the model prediction. Consequently, we attain the first place in all four cross-lingual tasks.
This paper introduces the system description of the hub team, which explains the related work and experimental results of our team’s participation in SemEval 2021 Task 2: Multilingual and Cross-lingual Word-in-Context Disambiguation (MCL-WiC). The data of this shared task is mainly some cross-language or multi-language sentence pair corpus. The languages covered in the corpus include English, Chinese, French, Russian, and Arabic. The task goal is to judge whether the same words in these sentence pairs have the same meaning in the sentence. This can be seen as a task of binary classification of sentence pairs. What we need to do is to use our method to determine as accurately as possible the meaning of the words in a sentence pair are the same or different. The model used by our team is mainly composed of RoBERTa and Tf-Idf algorithms. The result evaluation index of task submission is the F1 score. We only participated in the English language task. The final score of the test set prediction results submitted by our team was 84.60.
In this paper, we describe our proposed methods for the multilingual word-in-Context disambiguation task in SemEval-2021. In this task, systems should determine whether a word that occurs in two different sentences is used with the same meaning or not. We proposed several methods using a pre-trained BERT model. In two of them, we paraphrased sentences and add them as input to the BERT, and in one of them, we used WordNet to add some extra lexical information. We evaluated our proposed methods on test data in SemEval- 2021 task 2.
This paper describes the system of the Cambridge team submitted to the SemEval-2021 shared task on Multilingual and Cross-lingual Word-in-Context Disambiguation. Building on top of a pre-trained masked language model, our system is first pre-trained on out-of-domain data, and then fine-tuned on in-domain data. We demonstrate the effectiveness of the proposed two-step training strategy and the benefits of data augmentation from both existing examples and new resources. We further investigate different representations and show that the addition of distance-based features is helpful in the word-in-context disambiguation task. Our system yields highly competitive results in the cross-lingual track without training on any cross-lingual data; and achieves state-of-the-art results in the multilingual track, ranking first in two languages (Arabic and Russian) and second in French out of 171 submitted systems.
This paper describes our submission to SemEval 2021 Task 2. We compare XLM-RoBERTa Base and Large in the few-shot and zero-shot settings and additionally test the effectiveness of using a k-nearest neighbors classifier in the few-shot setting instead of the more traditional multi-layered perceptron. Our experiments on both the multi-lingual and cross-lingual data show that XLM-RoBERTa Large, unlike the Base version, seems to be able to more effectively transfer learning in a few-shot setting and that the k-nearest neighbors classifier is indeed a more powerful classifier than a multi-layered perceptron when used in few-shot learning.
We experiment with XLM RoBERTa for Word in Context Disambiguation in the Multi Lingual and Cross Lingual setting so as to develop a single model having knowledge about both settings. We solve the problem as a binary classification problem and also experiment with data augmentation and adversarial training techniques. In addition, we also experiment with a 2-stage training technique. Our approaches prove to be beneficial for better performance and robustness.
This paper presents a set of experiments to evaluate and compare between the performance of using CBOW Word2Vec and Lemma2Vec models for Arabic Word-in-Context (WiC) disambiguation without using sense inventories or sense embeddings. As part of the SemEval-2021 Shared Task 2 on WiC disambiguation, we used the dev.ar-ar dataset (2k sentence pairs) to decide whether two words in a given sentence pair carry the same meaning. We used two Word2Vec models: Wiki-CBOW, a pre-trained model on Arabic Wikipedia, and another model we trained on large Arabic corpora of about 3 billion tokens. Two Lemma2Vec models was also constructed based on the two Word2Vec models. Each of the four models was then used in the WiC disambiguation task, and then evaluated on the SemEval-2021 test.ar-ar dataset. At the end, we reported the performance of different models and compared between using lemma-based and word-based models.
Consulting a dictionary or a glossary is a familiar way for many humans to figure out what does a word in a particular context mean. We hypothesize that a system that can select a proper definition for a particular word occurrence can also naturally solve tasks related to word senses. To verify this hypothesis we developed a solution for the Multilingual and Cross-lingual Word-in-Context (MCL-WiC) task, that does not use any of the shared task data or other WiC data for training. Instead, it is trained to embed word definitions from English WordNet and word occurrences in English texts into the same vector space following an approach previously proposed for Word Sense Disambiguation (WSD). To estimate the similarity in meaning of two word occurrences, we compared different metrics in this shared vector space and found that L1-distance between normalized contextualized word embeddings outperforms traditionally employed cosine similarity and several other metrics. To solve the task for languages other than English, we rely on zero-shot cross-lingual transfer capabilities of the multilingual XLM-R masked language model. Despite not using MCL-WiC training data, in the shared task our approach achieves an accuracy of 89.5% on the English test set, which is only 4% less than the best system. In the multilingual subtask zero-shot cross-lingual transfer shows competitive results, that are within 2% from the best systems for Russian, French, and Arabic. In the cross-lingual subtask are within 2-4% from the best systems.
We describe the University of Alberta systems for the SemEval-2021 Word-in-Context (WiC) disambiguation task. We explore the use of translation information for deciding whether two different tokens of the same word correspond to the same sense of the word. Our focus is on developing principled theoretical approaches which are grounded in linguistic phenomena, leading to more explainable models. We show that translations from multiple languages can be leveraged to improve the accuracy on the WiC task.
Identifying whether a word carries the same meaning or different meaning in two contexts is an important research area in natural language processing which plays a significant role in many applications such as question answering, document summarisation, information retrieval and information extraction. Most of the previous work in this area rely on language-specific resources making it difficult to generalise across languages. Considering this limitation, our approach to SemEval-2021 Task 2 is based only on pretrained transformer models and does not use any language-specific processing and resources. Despite that, our best model achieves 0.90 accuracy for English-English subtask which is very compatible compared to the best result of the subtask; 0.93 accuracy. Our approach also achieves satisfactory results in other monolingual and cross-lingual language pairs as well.
This paper presents our approaches to SemEval-2021 Task 2: Multilingual and Cross-lingual Word-in-Context Disambiguation task. The first approach attempted to reformulate the task as a question answering problem, while the second one framed it as a binary classification problem. Our best system, which is an ensemble of XLM-R based binary classifiers trained with data augmentation, is among the 3 best-performing systems for Russian, French and Arabic in the multilingual subtask. In the post-evaluation period, we experimented with batch normalization, subword pooling and target word occurrence aggregation methods, resulting in further performance improvements.
This paper presents a word-in-context disambiguation system. The task focuses on capturing the polysemous nature of words in a multilingual and cross-lingual setting, without considering a strict inventory of word meanings. The system applies Natural Language Processing algorithms on datasets from SemEval 2021 Task 2, being able to identify the meaning of words for the languages Arabic, Chinese, English, French and Russian, without making use of any additional mono- or multilingual resources.
This paper presents our submitted system to SemEval 2021 Task 4: Reading Comprehension of Abstract Meaning. Our system uses a large pre-trained language model as the encoder and an additional dual multi-head co-attention layer to strengthen the relationship between passages and question-answer pairs, following the current state-of-the-art model DUMA. The main difference is that we stack the passage-question and question-passage attention modules instead of calculating parallelly to simulate re-considering process. We also add a layer normalization module to improve the performance of our model. Furthermore, to incorporate our known knowledge about abstract concepts, we retrieve the definitions of candidate answers from WordNet and feed them to the model as extra inputs. Our system, called WordNet-enhanced DUal Multi-head Co-Attention (WN-DUMA), achieves 86.67% and 89.99% accuracy on the official blind test set of subtask 1 and subtask 2 respectively.
Most question answering tasks focuses on predicting concrete answers, e.g., named entities. These tasks can be normally achieved by understanding the contexts without additional information required. In Reading Comprehension of Abstract Meaning (ReCAM) task, the abstract answers are introduced. To understand abstract meanings in the context, additional knowledge is essential. In this paper, we propose an approach that leverages the pre-trained BERT Token embeddings as a prior knowledge resource. According to the results, our approach using the pre-trained BERT outperformed the baselines. It shows that the pre-trained BERT token embeddings can be used as additional knowledge for understanding abstract meanings in question answering.
This paper presents the system developed by our team for Semeval 2021 Task 4: Reading Comprehension of Abstract Meaning. The aim of the task was to benchmark the NLP techniques in understanding the abstract concepts present in a passage, and then predict the missing word in a human written summary of the passage. We trained a Roberta-Large model trained with a masked language modeling objective. In cases where this model failed to predict one of the available options, another Roberta-Large model trained as a binary classifier was used to predict correct and incorrect options. We used passage summary generated by Pegasus model and question as inputs. Our best solution was an ensemble of these 2 systems. We achieved an accuracy of 86.22% on subtask 1 and 87.10% on subtask 2.
This paper presents our systems for the three Subtasks of SemEval Task4: Reading Comprehension of Abstract Meaning (ReCAM). We explain the algorithms used to learn our models and the process of tuning the algorithms and selecting the best model. Inspired by the similarity of the ReCAM task and the language pre-training, we propose a simple yet effective technology, namely, negative augmentation with language model. Evaluation results demonstrate the effectiveness of our proposed approach. Our models achieve the 4th rank on both official test sets of Subtask 1 and Subtask 2 with an accuracy of 87.9% and an accuracy of 92.8%, respectively. We further conduct comprehensive model analysis and observe interesting error cases, which may promote future researches. The code and dataset used in our paper can be found at https://github.com/CheaSim/SemEval2021. The leaderboard can be found at https://competitions.codalab.org/competitions/26153.
This paper describes the winning system for subtask 2 and the second-placed system for subtask 1 in SemEval 2021 Task 4: ReadingComprehension of Abstract Meaning. We propose to use pre-trianed Electra discriminator to choose the best abstract word from five candidates. An upper attention and auto denoising mechanism is introduced to process the long sequences. The experiment results demonstrate that this contribution greatly facilitatesthe contextual language modeling in reading comprehension task. The ablation study is also conducted to show the validity of our proposed methods.
SemEval task 4 aims to find a proper option from multiple candidates to resolve the task of machine reading comprehension. Most existing approaches propose to concat question and option together to form a context-aware model. However, we argue that straightforward concatenation can only provide a coarse-grained context for the MRC task, ignoring the specific positions of the option relative to the question. In this paper, we propose a novel MRC model by filling options into the question to produce a fine-grained context (defined as summary) which can better reveal the relationship between option and question. We conduct a series of experiments on the given dataset, and the results show that our approach outperforms other counterparts to a large extent.
In recent years, the widespread use of social media has led to an increase in the generation of toxic and offensive content on online platforms. In response, social media platforms have worked on developing automatic detection methods and employing human moderators to cope with this deluge of offensive content. While various state-of-the-art statistical models have been applied to detect toxic posts, there are only a few studies that focus on detecting the words or expressions that make a post offensive. This motivates the organization of the SemEval-2021 Task 5: Toxic Spans Detection competition, which has provided participants with a dataset containing toxic spans annotation in English posts. In this paper, we present the WLV-RIT entry for the SemEval-2021 Task 5. Our best performing neural transformer model achieves an 0.68 F1-Score. Furthermore, we develop an open-source framework for multilingual detection of offensive spans, i.e., MUDES, based on neural transformers that detect toxic spans in texts.
Toxic span detection requires the detection of spans that make a text toxic instead of simply classifying the text. In this paper, a transformer-based model with auxiliary information is proposed for SemEval-2021 Task 5. The proposed model was implemented based on the BERT-CRF architecture. It consists of three parts: a transformer-based model that can obtain the token representation, an auxiliary information module that combines features from different layers, and an output layer used for the classification. Various BERT-based models, such as BERT, ALBERT, RoBERTa, and XLNET, were used to learn contextual representations. The predictions of these models were assembled to improve the sequence labeling tasks by using a voting strategy. Experimental results showed that the introduced auxiliary information can improve the performance of toxic spans detection. The proposed model ranked 5th of 91 in the competition. The code of this study is available at https://github.com/Chenrj233/semeval2021_task5
We present our works on SemEval-2021 Task 5 about Toxic Spans Detection. This task aims to build a model for identifying toxic words in whole posts. We use the BiLSTM-CRF model combining with ToxicBERT Classification to train the detection model for identifying toxic words in posts. Our model achieves 62.23% by F1-score on the Toxic Spans Detection task.
This paper discusses different approaches to the Toxic Spans Detection task. The problem posed by the task was to determine which words contribute mostly to recognising a document as toxic. As opposed to binary classification of entire texts, word-level assessment could be of great use during comment moderation, also allowing for a more in-depth comprehension of the model’s predictions. As the main goal was to ensure transparency and understanding, this paper focuses on the current state-of-the-art approaches based on the explainable AI concepts and compares them to a supervised learning solution with word-level labels. The work consists of two xAI approaches that automatically provide the explanation for models trained for binary classification of toxic documents: an LSTM model with attention as a model-specific approach and the Shapley values for interpreting BERT predictions as a model-agnostic method. The competing approach considers this problem as supervised token classification, where models like BERT and its modifications were tested. The paper aims to explore, compare and assess the quality of predictions for different methods on the task. The advantages of each approach and further research direction are also discussed.
Many new developments to detect and mitigate toxicity are currently being evaluated. We are particularly interested in the correlation between toxicity and the emotions expressed in online posts. While toxicity may be disguised by amending the wording of posts, emotions will not. Therefore, we describe here an ensemble method to identify toxicity and classify the emotions expressed on a corpus of annotated posts published by Task 5 of SemEval 2021–our analysis shows that the majority of such posts express anger, sadness and fear. Our method to identify toxicity combines a lexicon-based approach, which on its own achieves an F1 score of 61.07%, with a supervised learning approach, which on its own achieves an F1 score of 60%. When both methods are combined, the ensemble achieves an F1 score of 66.37%.
Toxic spans detection is an emerging challenge that aims to find toxic spans within a toxic text. In this paper, we describe our solutions to tackle toxic spans detection. The first solution, which follows a supervised approach, is based on SpanBERT model. This latter is intended to better embed and predict spans of text. The second solution, which adopts an unsupervised approach, combines linear support vector machine with the Local Interpretable Model-Agnostic Explanations (LIME). This last is used to interpret predictions of learning-based models. Our supervised model outperformed the unsupervised model and achieved the f-score of 67,84% (ranked 22/85) in Task 5 at SemEval-2021: Toxic Spans Detection.
This paper introduces our system at SemEval-2021 Task 5: Toxic Spans Detection. The task aims to accurately locate toxic spans within a text. Using BIO tagging scheme, we model the task as a token-level sequence labeling task. Our system uses a single model built on the model of multi-layer bidirectional transformer encoder. And we introduce conditional random field (CRF) to make the model learn the constraints between tags. We use ERNIE as pre-trained model, which is more suitable for the task accroding to our experiments. In addition, we use adversarial training with the fast gradient method (FGM) to improve the robustness of the system. Our system obtains 69.85% F1 score, ranking 3rd for the official evaluation.
This paper describes our contribution to SemEval-2021 Task 5: Toxic Spans Detection. Our solution is built upon RoBERTa language model and Conditional Random Fields (CRF). We pre-trained RoBERTa on Civil Comments dataset, enabling it to create better contextual representation for this task. We also employed the semi-supervised learning technique of self-training, which allowed us to extend our training dataset. In addition to these, we also identified some pre-processing steps that significantly improved our F1 score. Our proposed system achieved a rank of 41 with an F1 score of 66.16%.
We leverage a BLSTM with attention to identify toxic spans in texts. We explore different dimensions which affect the model’s performance. The first dimension explored is the toxic set the model is trained on. Besides the provided dataset, we explore the transferability of 5 different toxic related sets, including offensive, toxic, abusive, and hate sets. We find that the solely offensive set shows the highest promise of transferability. The second dimension we explore is methodology, including leveraging attention, employing a greedy remove method, using a frequency ratio, and examining hybrid combinations of multiple methods. We conduct an error analysis to examine which types of toxic spans were missed and which were wrongly inferred as toxic along with the main reasons why they occurred. Finally, we extend our method via ensembles, which achieves our highest F1 score of 55.1.
The SemEval 2021 task 5: Toxic Spans Detection is a task of identifying considered-toxic spans in text, which provides a valuable, automatic tool for moderating online contents. This paper represents the second-place method for the task, an ensemble of two approaches. While one approach relies on combining different embedding methods to extract diverse semantic and syntactic representations of words in context; the other utilizes extra data with a slightly customized Self-training, a semi-supervised learning technique, for sequence tagging problems. Both of our architectures take advantage of a strong language model, which was fine-tuned on a toxic classification task. Although experimental evidence indicates higher effectiveness of the first approach than the second one, combining them leads to our best results of 70.77 F1-score on the test dataset.
This paper describes the system developed by the Antwerp Centre for Digital humanities and literary Criticism [UAntwerp] for toxic span detection. We used a stacked generalisation ensemble of five component models, with two distinct interpretations of the task. Two models attempted to predict binary word toxicity based on ngram sequences, whilst 3 categorical span based models were trained to predict toxic token labels based on complete sequence tokens. The five models’ predictions were ensembled within an LSTM model. As well as describing the system, we perform error analysis to explore model performance in relation to textual features. The system described in this paper scored 0.6755 and ranked 26th.
This article introduces the system description of the hub team, which explains the related work and experimental results of our team’s participation in SemEval 2021 Task 5: Toxic Spans Detection. The data for this shared task comes from some posts on the Internet. The task goal is to identify the toxic content contained in these text data. We need to find the span of the toxic text in the text data as accurately as possible. In the same post, the toxic text may be one paragraph or multiple paragraphs. Our team uses a classification scheme based on word-level to accomplish this task. The system we used to submit the results is ALBERT+BILSTM+CRF. The result evaluation index of the task submission is the F1 score, and the final score of the prediction result of the test set submitted by our team is 0.6640226029.
This paper describes our contribution to SemEval-2021 Task 5: Toxic Spans Detection. Our approach considers toxic spans detection as a segmentation problem. The system, Waw-unet, consists of a 1-D convolutional neural network adopted from U-Net architecture commonly applied for semantic segmentation. We customize existing architecture by adding a special network block considering for text segmentation, as an essential component of the model. We compared the model with two transformers-based systems RoBERTa and XLM-RoBERTa to see its performance against pre-trained language models. We obtained 0.6251 f1 score with Waw-unet while 0.6390 and 0.6601 with the compared models respectively.
This paper describes our system for SemEval-2021 Task 5 on Toxic Spans Detection. We developed ensemble models using BERT-based neural architectures and post-processing to combine tokens into spans. We evaluated several pre-trained language models using various ensemble techniques for toxic span identification and achieved sizable improvements over our baseline fine-tuned BERT models. Finally, our system obtained a F1-score of 67.55% on test data.
The increment of toxic comments on online space is causing tremendous effects on other vulnerable users. For this reason, considerable efforts are made to deal with this, and SemEval-2021 Task 5: Toxic Spans Detection is one of those. This task asks competitors to extract spans that have toxicity from the given texts, and we have done several analyses to understand its structure before doing experiments. We solve this task by two approaches, Named Entity Recognition with spaCy’s library and Question-Answering with RoBERTa combining with ToxicBERT, and the former gains the highest F1-score of 66.99%.
This work describes the participation of the Skoltech NLP group team (Sk) in the Toxic Spans Detection task at SemEval-2021. The goal of the task is to identify the most toxic fragments of a given sentence, which is a binary sequence tagging problem. We show that fine-tuning a RoBERTa model for this problem is a strong baseline. This baseline can be further improved by pre-training the RoBERTa model on a large dataset labeled for toxicity at the sentence level. While our solution scored among the top 20% participating models, it is only 2 points below the best result. This suggests the viability of our approach.
Detection of toxic spans - detecting toxicity of contents in the granularity of tokens - is crucial for effective moderation of online discussions. The baseline approach for this problem using the transformer model is to add a token classification head to the language model and fine-tune the layers with the token labeled dataset. One of the limitations of such a baseline approach is the scarcity of labeled data. To improve the results, We studied leveraging existing public datasets for a related but different task of entire comment/sentence classification. We propose two approaches: the first approach fine-tunes transformer models that are pre-trained on sentence classification samples. In the second approach, we perform weak supervision with soft attention to learn token level labels from sentence labels. Our experiments show improvements in the F1 score over the baseline approach. The implementation has been released publicly.
With the rapid growth in technology, social media activity has seen a boom across all age groups. It is humanly impossible to check all the tweets, comments and status manually whether they follow proper community guidelines. A lot of toxicity is regularly posted on these social media platforms. This research aims to find toxic words in a sentence so that a healthy social community is built across the globe and the users receive censored content with specific warnings and facts. To solve this challenging problem, authors have combined concepts of Linked List for pre-processing and then used the idea of stacked embeddings like BERT Embeddings, Flair Embeddings and Word2Vec on the flairNLP framework to get the desired results. F1 metric was used to evaluate the model. The authors were able to produce a 0.74 F1 score on their test set.
Toxic Spans Detection(TSD) task is defined as highlighting spans that make a text toxic. Many works have been done to classify a given comment or document as toxic or non-toxic. However, none of those proposed models work at the token level. In this paper, we propose a self-attention-based bidirectional gated recurrent unit(BiGRU) with a multi-embedding representation of the tokens. Our proposed model enriches the representation by a combination of GPT-2, GloVe, and RoBERTa embeddings, which led to promising results. Experimental results show that our proposed approach is very effective in detecting span tokens.
In this paper, we describe our system used for SemEval 2021 Task 5: Toxic Spans Detection. Our proposed system approaches the problem as a token classification task. We trained our model to find toxic words and concatenate their spans to predict the toxic spans within a sentence. We fine-tuned Pre-trained Language Models (PLMs) for identifying the toxic words. For fine-tuning, we stacked the classification layer on top of the PLM features of each word to classify if it is toxic or not. PLMs are pre-trained using different objectives and their performance may differ on downstream tasks. We, therefore, compare the performance of BERT, ELECTRA, RoBERTa, XLM-RoBERTa, T5, XLNet, and MPNet for identifying toxic spans within a sentence. Our best performing system used RoBERTa. It performed well, achieving an F1 score of 0.6841 and secured a rank of 16 on the official leaderboard.
This paper presents our submission to SemEval-2021 Task 5: Toxic Spans Detection. The purpose of this task is to detect the spans that make a text toxic, which is a complex labour for several reasons. Firstly, because of the intrinsic subjectivity of toxicity, and secondly, due to toxicity not always coming from single words like insults or offends, but sometimes from whole expressions formed by words that may not be toxic individually. Following this idea of focusing on both single words and multi-word expressions, we study the impact of using a multi-depth DistilBERT model, which uses embeddings from different layers to estimate the final per-token toxicity. Our quantitative results show that using information from multiple depths boosts the performance of the model. Finally, we also analyze our best model qualitatively.
This paper describes our approach to the Toxic Spans Detection problem (SemEval-2021 Task 5). We propose BERToxic, a system that fine-tunes a pre-trained BERT model to locate toxic text spans in a given text and utilizes additional post-processing steps to refine the boundaries. The post-processing steps involve (1) labeling character offsets between consecutive toxic tokens as toxic and (2) assigning a toxic label to words that have at least one token labeled as toxic. Through experiments, we show that these two post-processing steps improve the performance of our model by 4.16% on the test set. We also studied the effects of data augmentation and ensemble modeling strategies on our system. Our system significantly outperformed the provided baseline and achieved an F1-score of 0.683, placing Lone Pine in the 17th place out of 91 teams in the competition. Our code is made available at https://github.com/Yakoob-Khan/Toxic-Spans-Detection
This paper presents a system used for SemEval-2021 Task 5: Toxic Spans Detection. Our system is an ensemble of BERT-based models for binary word classification, trained on a dataset extended by toxic comments modified and generated by two language models. For the toxic word classification, the prediction threshold value was optimized separately for every comment, in order to maximize the expected F1 value.
This paper describes the participation of SINAI team at Task 5: Toxic Spans Detection which consists of identifying spans that make a text toxic. Although several resources and systems have been developed so far in the context of offensive language, both annotation and tasks have mainly focused on classifying whether a text is offensive or not. However, detecting toxic spans is crucial to identify why a text is toxic and can assist human moderators to locate this type of content on social media. In order to accomplish the task, we follow a deep learning-based approach using a Bidirectional variant of a Long Short Term Memory network along with a stacked Conditional Random Field decoding layer (BiLSTM-CRF). Specifically, we test the performance of the combination of different pre-trained word embeddings for recognizing toxic entities in text. The results show that the combination of word embeddings helps in detecting offensive content. Our team ranks 29th out of 91 participants.
The upsurge of prolific blogging and microblogging platforms enabled the abusers to spread negativity and threats greater than ever. Detecting the toxic portions substantially aids to moderate or exclude the abusive parts for maintaining sound online platforms. This paper describes our participation in the SemEval 2021 toxic span detection task. The task requires detecting spans that convey toxic remarks from the given text. We explore an ensemble of sequence labeling models including the BiLSTM-CRF, spaCy NER model with custom toxic tags, and fine-tuned BERT model to identify the toxic spans. Finally, a majority voting ensemble method is used to determine the unified toxic spans. Experimental results depict the competitive performance of our model among the participants.
Detecting which parts of a sentence contribute to that sentence’s toxicity—rather than providing a sentence-level verdict of hatefulness— would increase the interpretability of models and allow human moderators to better understand the outputs of the system. This paper presents our team’s, UTNLP, methodology and results in the SemEval-2021 shared task 5 on toxic spans detection. We test multiple models and contextual embeddings and report the best setting out of all. The experiments start with keyword-based models and are followed by attention-based, named entity- based, transformers-based, and ensemble models. Our best approach, an ensemble model, achieves an F1 of 0.684 in the competition’s evaluation phase.
Toxic language is often present in online forums, especially when politics and other polarizing topics arise, and can lead to people becoming discouraged from joining or continuing conversations. In this paper, we use data consisting of comments with the indices of toxic text labelled to train an RNN to deter-mine which parts of the comments make them toxic, which could aid online moderators. We compare results using both the original dataset and an augmented set, as well as GRU versus LSTM RNN models.
Recurrent Neural Networks (RNN) have been widely used in various Natural Language Processing (NLP) tasks such as text classification, sequence tagging, and machine translation. Long Short Term Memory (LSTM), a special unit of RNN, has the benefit of memorizing past and even future information in a sentence (especially for bidirectional LSTM). In the shared task of detecting spans which make texts toxic, we first apply pretrained word embedding (GloVe) to generate the word vectors after tokenization. And then we construct Bidirectional Long Short Term Memory-Conditional Random Field (Bi-LSTM-CRF) model by Baidu research to predict whether each word in the sentence is toxic or not. We tune hyperparameters of dropout rate, number of LSTM units, embedding size with 10 epochs and choose the best epoch with validation recall. Our model achieves an F1 score of 66.99 percent in test dataset.
We describe our approach for SemEval-2021 task 6 on detection of persuasion techniques in multimodal content (memes). Our system combines pretrained multimodal models (CLIP) and chained classifiers. Also, we propose to enrich the data by a data augmentation technique. Our submission achieves a rank of 8/16 in terms of F1-micro and 9/16 with F1-macro on the test set.
This paper describes the system used by the AIMH Team to approach the SemEval Task 6. We propose an approach that relies on an architecture based on the transformer model to process multimodal content (text and images) in memes. Our architecture, called DVTT (Double Visual Textual Transformer), approaches Subtasks 1 and 3 of Task 6 as multi-label classification problems, where the text and/or images of the meme are processed, and the probabilities of the presence of each possible persuasion technique are returned as a result. DVTT uses two complete networks of transformers that work on text and images that are mutually conditioned. One of the two modalities acts as the main one and the second one intervenes to enrich the first one, thus obtaining two distinct ways of operation. The two transformers outputs are merged by averaging the inferred probabilities for each possible label, and the overall network is trained end-to-end with a binary cross-entropy loss.
Among the tasks motivated by the proliferation of misinformation, propaganda detection is particularly challenging due to the deficit of fine-grained manual annotations required to train machine learning models. Here we show how data from other related tasks, including credibility assessment, can be leveraged in multi-task learning (MTL) framework to accelerate the training process. To that end, we design a BERT-based model with multiple output layers, train it in several MTL scenarios and perform evaluation against the SemEval gold standard.
This paper presents the solution proposed by the 1213Li team for subtask 3 in SemEval-2021 Task 6: identifying the multiple persuasion techniques used in the multi-modal content of the meme. We explored various approaches in feature extraction and the detection of persuasion labels. Our final model employs pre-trained models including RoBERTa and ResNet-50 as a feature extractor for texts and images, respectively, and adopts a label embedding layer with multi-modal attention mechanism to measure the similarity of labels with the multi-modal information and fuse features for label prediction. Our proposed method outperforms the provided baseline method and achieves 3rd out of 16 participants with 0.54860/0.22830 for Micro/Macro F1 scores.
The following system description presents our approach to the detection of persuasion techniques in texts and images. The given task has been framed as a multi-label classification problem with the different techniques serving as class labels. The multi-label classification problem is one in which a list of target variables such as our class labels is associated with every input chunk and assumes that a document can simultaneously and independently be assigned to multiple labels or classes. In order to assign class labels to the given memes, we opted for RoBERTa (A Robustly Optimized BERT Pretraining Approach) as a neural network architecture for token and sequence classification. Starting off with a pre-trained model for language representation we fine-tuned this model on the given classification task with the provided annotated data in supervised training steps. To incorporate image features in the multi-modal setting, we rely on the pre-trained VGG-16 model architecture.
In recent years, memes combining image and text have been widely used in social media, and memes are one of the most popular types of content used in online disinformation campaigns. In this paper, our study on the detection of persuasion techniques in texts and images in SemEval-2021 Task 6 is summarized. For propaganda technology detection in text, we propose a combination model of both ALBERT and Text CNN for text classification, as well as a BERT-based multi-task sequence labeling model for propaganda technology coverage span detection. For the meme classification task involved in text understanding and visual feature extraction, we designed a parallel channel model divided into text and image channels. Our method achieved a good performance on subtasks 1 and 3. The micro F1-scores of 0.492, 0.091, and 0.446 achieved on the test sets of the three subtasks ranked 12th, 7th, and 11th, respectively, and all are higher than the baseline model.
Internet memes have become ubiquitous in social media networks today. Due to their popularity, they are also a widely used mode of expression to spread disinformation online. As memes consist of a mixture of text and image, they require a multi-modal approach for automatic analysis. In this paper, we describe our contribution to the SemEval-2021 Detection of Persuasian Techniques in Texts and Images Task. We propose a Multi-Modal learning system, which incorporates “memebeddings”, viz. joint text and vision features by combining them with compact bilinear pooling, to automatically identify rhetorical and psychological disinformation techniques. The experimental results show that the proposed system constantly outperforms the competition’s baseline, and achieves the 2nd best Macro F1-score and 14th best Micro F1-score out of all participants.
The objective of subtask 2 of SemEval-2021 Task 6 is to identify techniques used together with the span(s) of text covered by each technique. This paper describes the system and model we developed for the task. We first propose a pipeline system to identify spans, then to classify the technique in the input sequence. But it severely suffers from handling the overlapping in nested span. Then we propose to formulize the task as a question answering task by MRC framework which achieves a better result compared to the pipeline method. Moreover, data augmentation and loss design techniques are also explored to alleviate the problem of data sparse and imbalance. Finally, we attain the 3rd place in the final evaluation phase.
This paper describes and examines different systems to address Task 6 of SemEval-2021: Detection of Persuasion Techniques In Texts And Images, Subtask 1. The task aims to build a model for identifying rhetorical and psycho- logical techniques (such as causal oversimplification, name-calling, smear) in the textual content of a meme which is often used in a disinformation campaign to influence the users. The paper provides an extensive comparison among various machine learning systems as a solution to the task. We elaborate on the pre-processing of the text data in favor of the task and present ways to overcome the class imbalance. The results show that fine-tuning a RoBERTa model gave the best results with an F1-Micro score of 0.51 on the development set.
We developed a system for task 6 sub-task 1 for detecting propaganda in memes. An external dataset and augmentation data-set were used to extend the official competition data-set. Data augmentation techniques were applied on the external data-set and competition data-set to come up with the augmented data-set. We trained 5 transformers (DeBERTa, and 4 RoBERTa) and ensembled them to make the prediction. We trained 1 RoBERTa model initially on the augmented data-set for a few epochs and then fine-tuned it on the competition data-set which improved the f1-micro up to 0.1 scores. After that, another initial RoBERTa model was trained on the external data-set merged with the augmented data-set for few epochs and fine-tuned it on the competition data-set. Furthermore, we ensembled the initial models with the models after fine-tuning. For the final model in the ensemble, we trained a DeBERTa model on the augmented data-set without fine-tuning it on the competition data-set. Finally, we averaged the output of each model in the ensemble to make the prediction.
Memes are one of the most popular types of content used to spread information online. They can influence a large number of people through rhetorical and psychological techniques. The task, Detection of Persuasion Techniques in Texts and Images, is to detect these persuasive techniques in memes. It consists of three subtasks: (A) Multi-label classification using textual content, (B) Multi-label classification and span identification using textual content, and (C) Multi-label classification using visual and textual content. In this paper, we propose a transfer learning approach to fine-tune BERT-based models in different modalities. We also explore the effectiveness of ensembles of models trained in different modalities. We achieve an F1-score of 57.0, 48.2, and 52.1 in the corresponding subtasks.
We describe our systems of subtask1 and subtask3 for SemEval-2021 Task 6 on Detection of Persuasion Techniques in Texts and Images. The purpose of subtask1 is to identify propaganda techniques given textual content, and the goal of subtask3 is to detect them given both textual and visual content. For subtask1, we investigate transfer learning based on pre-trained language models (PLMs) such as BERT, RoBERTa to solve data sparsity problems. For subtask3, we extract heterogeneous visual representations (i.e., face features, OCR features, and multimodal representations) and explore various multimodal fusion strategies to combine the textual and visual representations. The official evaluation shows our ensemble model ranks 1st for subtask1 and 2nd for subtask3.
Inscribing persuasion techniques in memes is the most impactful way to influence peoples’ mindsets. People are more inclined to memes as they are more stimulating and convincing and hence memes are often exploited by tactfully engraving propaganda in its context with the intent of attaining specific agenda. This paper describes our participation in the three subtasks featured by SemEval 2021 task 6 on the detection of persuasion techniques in texts and images. We utilize a fusion of logistic regression, decision tree, and fine-tuned DistilBERT for tackling subtask 1. As for subtask 2, we propose a system that consolidates a span identification model and a multi-label classification model based on pre-trained BERT. We address the multi-modal multi-label classification of memes defined in subtask 3 by utilizing a ResNet50 based image model, DistilBERT based text model, and a multi-modal architecture based on multikernel CNN+LSTM and MLP model. The outcomes illustrated the competitive performance of our systems.
In writing, humor is mainly based on figurative language in which words and expressions change their conventional meaning to refer to something without saying it directly. This flip in the meaning of the words prevents Natural Language Processing from revealing the real intention of a communication and, therefore, reduces the effectiveness of tasks such as Sentiment Analysis or Emotion Detection. In this manuscript we describe the participation of the UMUTeam in HaHackathon 2021, whose objective is to detect and rate humorous and controversial content. Our proposal is based on the combination of linguistic features with contextual and non-contextual word embeddings. We participate in all the proposed subtasks achieving our best result in the controversial humor subtask.
This research presents the work of the team’s ES-JUST at semEval-2021 task 7 for detecting and rating humor and offensive text using deep learning. The team evaluates several approaches (i.e.Bert, Roberta, XLM-Roberta, and Bert embedding + Bi-LSTM) that employ in four sub-tasks. The first sub-task deal with whether the text is humorous or not. The second sub-task is the degree of humor in the text if the first sub-task is humorous. The third sub-task represents the text is controversial or not if it is humorous. While in the last task is the degree of an offensive in the text. However, Roberta pre-trained model outperforms other approaches and score the highest in all sub-tasks. We rank on the leader board at the evaluation phase are 14, 15, 20, and 5 through 0.9564 F-score, 0.5709 RMSE, 0.4888 F-score, and 0.4467 RMSE results, respectively, for each of the first, second, third, and fourth sub-task, respectively.
This paper describes our contribution to SemEval-2021 Task 7: Detecting and Rating Humor and Of-fense.This task contains two sub-tasks, sub-task 1and sub-task 2. Among them, sub-task 1 containsthree sub-tasks, sub-task 1a ,sub-task 1b and sub-task 1c.Sub-task 1a is to predict if the text would beconsidered humorous.Sub-task 1c is described asfollows: if the text is classed as humorous, predictif the humor rating would be considered controver-sial, i.e. the variance of the rating between annota-tors is higher than the median.we combined threepre-trained model with CNN to complete these twoclassification sub-tasks.Sub-task 1b is to judge thedegree of humor.Sub-task 2 aims to predict how of-fensive a text would be with values between 0 and5.We use the idea of regression to deal with thesetwo sub-tasks.We analyze the performance of ourmethod and demonstrate the contribution of eachcomponent of our architecture.We have achievedgood results under the combination of multiple pre-training models and optimization methods.
Humor detection and rating poses interesting linguistic challenges to NLP; it is highly subjective depending on the perceptions of a joke and the context in which it is used. This paper utilizes and compares transformers models; BERT base and Large, BERTweet, RoBERTa base and Large, and RoBERTa base irony, for detecting and rating humor and offense. The proposed models, where given a text in cased and uncased type obtained from SemEval-2021 Task7: HaHackathon: Linking Humor and Offense Across Different Age Groups. The highest scored model for the first subtask: Humor Detection, is BERTweet base cased model with 0.9540 F1-score, for the second subtask: Average Humor Rating Score, it is BERT Large cased with the minimum RMSE of 0.5555, for the fourth subtask: Average Offensiveness Rating Score, it is BERTweet base cased model with minimum RMSE of 0.4822.
Humor recognition is a challenging task in natural language processing. This document presents my approaches to detect and rate humor and offense from the given text. This task includes 2 tasks: task 1 which contains 3 subtasks (1a, 1b, and 1c), and task 2. Subtask 1a and 1c can be regarded as classification problems and take ALBERT as the basic model. Subtask 1b and 2 can be viewed as regression issues and take RoBERTa as the basic model.
This paper describes the approach that was developed for SemEval 2021 Task 7 (Hahackathon: Incorporating Demographic Factors into Shared Humor Tasks) by the DUTH Team. We used and compared a variety of preprocessing techniques, vectorization methods, and numerous conventional machine learning algorithms, in order to construct classification and regression models for the given tasks. We used majority voting to combine the models’ outputs with small Neural Networks (NN) for classification tasks and their mean for regression for improving our system’s performance. While these methods proved weaker than modern, deep learning models, they are still relevant in research tasks because of their low requirements on computational power and faster training.
This paper describes the winning system for SemEval-2021 Task 7: Detecting and Rating Humor and Offense. Our strategy is stacking diverse pre-trained language models (PLMs) such as RoBERTa and ALBERT. We first perform fine-tuning on these two PLMs with various hyperparameters and different training strategies. Then a valid stacking mechanism is applied on top of the fine-tuned PLMs to get the final prediction. Experimental results on the dataset released by the organizer of the task show the validity of our method and we win first place and third place for subtask 2 and 1a.
Humor detection has become a topic of interest for several research teams, especially those involved in socio-psychological studies, with the aim to detect the humor and the temper of a targeted population (e.g. a community, a city, a country, the employees of a given company). Most of the existing studies have formulated the humor detection problem as a binary classification task, whereas it revolves around learning the sense of humor by evaluating its different degrees. In this paper, we propose an end-to-end deep Multi-Task Learning (MTL) model to detect and rate humor and offense. It consists of a pre-trained transformer encoder and task-specific attention layers. The model is trained using MTL uncertainty loss weighting to adaptively combine all sub-tasks objective functions. Our MTL model tackles all sub-tasks of the SemEval-2021 Task-7 in one end-to-end deep learning system and shows very promising results.
This paper introduces the system description of the hub team, which explains the related work and experimental results of our team’s participation in SemEval 2021 Task 7: HaHackathon: Detecting and Rating Humor and Offense. We successfully submitted the test set prediction results of the two subtasks in the task. The goal of the task is to perform humor detection, grade evaluation, and offensive evaluation on each English text data in the data set. Tasks can be divided into two types of subtasks. One is a text classification task, and the other is a text regression task. What we need to do is to use our method to detect the humor and offensive information of the sentence as accurately as possible. The methods used in the results submitted by our team are mainly composed of ALBERT, CNN, and Tf-Idf algorithms. The result evaluation indicators submitted by the classification task are F1 score and Accuracy. The result evaluation index of the regression task submission is the RMSE. The final scores of the prediction results of the two subtask test sets submitted by our team are task1a 0.921 (F1), task1a 0.9364 (Accuracy), task1b 0.6288 (RMSE), task1c 0.5333 (F1), task1c 0.0.5591 (Accuracy), and task2 0.5027 (RMSE) respectively.
In this paper, we describe our system used for SemEval 2021 Task 7: HaHackathon: Detecting and Rating Humor and Offense. We used a simple fine-tuning approach using different Pre-trained Language Models (PLMs) to evaluate their performance for humor and offense detection. For regression tasks, we averaged the scores of different models leading to better performance than the original models. We participated in all SubTasks. Our best performing system was ranked 4 in SubTask 1-b, 8 in SubTask 1-c, 12 in SubTask 2, and performed well in SubTask 1-a. We further show comprehensive results using different pre-trained language models which will help as baselines for future work.
This paper describes MagicPai’s system for SemEval 2021 Task 7, HaHackathon: Detecting and Rating Humor and Offense. This task aims to detect whether the text is humorous and how humorous it is. There are four subtasks in the competition. In this paper, we mainly present our solution, a multi-task learning model based on adversarial examples, for task 1a and 1b. More specifically, we first vectorize the cleaned dataset and add the perturbation to obtain more robust embedding representations. We then correct the loss via the confidence level. Finally, we perform interactive joint learning on multiple tasks to capture the relationship between whether the text is humorous and how humorous it is. The final result shows the effectiveness of our system.
Detecting humor is a challenging task since words might share multiple valences and, depending on the context, the same words can be even used in offensive expressions. Neural network architectures based on Transformer obtain state-of-the-art results on several Natural Language Processing tasks, especially text classification. Adversarial learning, combined with other techniques such as multi-task learning, aids neural models learn the intrinsic properties of data. In this work, we describe our adversarial multi-task network, AMTL-Humor, used to detect and rate humor and offensive texts from Task 7 at SemEval-2021. Each branch from the model is focused on solving a related task, and consists of a BiLSTM layer followed by Capsule layers, on top of BERTweet used for generating contextualized embeddings. Our best model consists of an ensemble of all tested configurations, and achieves a 95.66% F1-score and 94.70% accuracy for Task 1a, while obtaining RMSE scores of 0.6200 and 0.5318 for Tasks 1b and 2, respectively.
This paper describes the system submitted to SemEval-2021 Task-7 for all four subtasks. Two subtasks focus on detecting humor and offense from the text (binary classification). On the other hand, the other two subtasks predict humor and offense ratings of the text (linear regression). In this paper, we present two different types of fine-tuning methods by using linear layers and bi-LSTM layers on top of the pre-trained BERT model. Results show that our system is able to outperform baseline models by a significant margin. We report F1 scores of 0.90 for the first subtask and 0.53 for the third subtask, while we report an RMSE of 0.57 and 0.58 for the second and fourth subtasks, respectively.
This article introduces the submission of subtask 1 and subtask 2 that we participate in SemEval-2021 Task 7: HaHackathon: Detecting and Rating Humor and Offense, we use a model based on ALBERT that uses ALBERT as the module for extracting text features. We modify the upper layer structure by adding specific networks to better summarize the semantic information. Finally, our system achieves an F-Score of 0.9348 in subtask 1a, RMSE of 0.7214 in subtask 1b, F-Score of 0.4603 in subtask 1c, and RMSE of 0.5204 in subtask 2.
Humour detection is an interesting but difficult task in NLP. Because humorous might not be obvious in text, it can be embedded into context, hide behind the literal meaning and require prior knowledge to understand. We explored different shallow and deep methods to create a humour detection classifier for task 7-1a. Models like Logistic Regression, LSTM, MLP, CNN were used, and pre-trained models like DistilBert were introduced to generate accurate vector representation for textual data. We focused on applying multi-scale strategy on modelling, and compared different models. Our best model is the DistilBERT+MultiScale CNN, it used different sizes of CNN kernel to get multiple scales of features, which achieved 93.7% F1-score and 92.1% accuracy on the test set.
This paper describes the system used for detecting humor in text. The system developed by the team TECHSSN uses binary classification techniques to classify the text. The data undergoes preprocessing and is given to ColBERT (Contextualized Late Interaction over BERT), a modification of Bidirectional Encoder Representations from Transformers (BERT). The model is re-trained and the weights are learned for the dataset. This system was developed for the task 7 of the competition, SemEval 2021.
This paper describes our submission to theSemEval’21: Task 7- HaHackathon: Detecting and Rating Humor and Offense. In this challenge, we explore intermediate finetuning, backtranslation augmentation, multitask learning, and ensembling of different language models. Curiously, intermediate finetuning and backtranslation do not improve performance, while multitask learning and ensembling do improve performance. We explore why intermediate finetuning and backtranslation do not provide the same benefit as other natural language processing tasks and offer insight into the errors that our model makes. Our best performing system ranks 7th on Task 1bwith an RMSE of 0.5339
This paper presents the DuluthNLP submission to Task 7 of the SemEval 2021 competition on Detecting and Rating Humor and Offense. In it, we explain the approach used to train the model together with the process of fine-tuning our model in getting the results. We focus on humor detection, rating, and of-fense rating, representing three out of the four subtasks that were provided. We show that optimizing hyper-parameters for learning rate, batch size and number of epochs can increase the accuracy and F1 score for humor detection
With the emerging trends of using online platforms, peoples are increasingly interested in express their opinion through humorous texts. Identifying and rating humorous texts poses unique challenges to NLP due to subjective phenomena i.e. humor may vary to gender, profession, age, and classes of people. Besides, words with multiple senses, cultural domain, and pragmatic competence also need to be considered. A humorous text may be offensive to others. To address these challenges SemEval-2021 introduced a HaHackathon task focusing on detecting and rating humorous and offensive texts. This paper describes our participation in this task. We employed a stacked embedding and fine-tuned transformer models based classification and regression approach from the features from GPT2 medium, BERT, and RoBERTa transformer models. Besides, we utilized the fine-tuned BERT and RoBERTa models to examine the performances. Our method achieved competitive performances in this task.
An understanding of humor is an essential component of human-facing NLP systems. In this paper, we investigate several methods for detecting humor in short statements as part of Semeval-2021 Shared Task 7. For Task 1a, we apply an ensemble of fine-tuned pre-trained language models; for Tasks 1b, 1c, and 2a, we investigate various tree-based and linear machine learning models. Our final system achieves an F1-score of 0.9571 (ranked 24 / 58) on Task 1a, an RMSE of 0.5580 (ranked 18 / 50) on Task 1b, an F1-score of 0.5024 (ranked 26 / 36) on Task 1c, and an RMSE of 0.7229 (ranked 45 / 48) on Task 2a.
This paper describes Humor-BERT, a set of BERT Large based models that we used in the SemEval-2021 Task 7: Detecting and Rating Humor and Offense. It presents pre and post processing techniques, variable threshold learning, meta learning and Ensemble approach to solve various sub-tasks that were part of the challenge. We also present a comparative analysis of various models we tried. Our method was ranked 4th in Humor Controversy Detection, 8th in Humor Detection, 19th in Average Offense Score prediction and 40th in Average Humor Score prediction globally. F1 score obtained for Humor classification was 0.9655 and for Controversy detection it was 0.6261. Our user name on the leader board is ThisIstheEnd and team name is EndTimes.
This paper describes our approach (IIITH) for SemEval-2021 Task 5: HaHackathon: Detecting and Rating Humor and Offense. Our results focus on two major objectives: (i) Effect of task adaptive pretraining on the performance of transformer based models (ii) How does lexical and hurtlex features help in quantifying humour and offense. In this paper, we provide a detailed description of our approach along with comparisions mentioned above.
The “HaHackathon: Detecting and Rating Humor and Offense” task at the SemEval 2021 competition focuses on detecting and rating the humor level in sentences, as well as the level of offensiveness contained in these texts with humoristic tones. In this paper, we present an approach based on recent Deep Learning techniques by both trying to train the models based on the dataset solely and by trying to fine-tune pre-trained models on the gigantic corpus.
This paper presents the system for SemEval 2021 Task 8 (MeasEval). MeasEval is a novel span extraction, classification, and relation extraction task focused on finding quantities, attributes of these quantities, and additional information, including the related measured entities, properties, and measurement contexts. Our submitted system, which placed fifth (team rank) on the leaderboard, consisted of SciBERT with [CLS] token embedding and CRF layer on top. We were also placed first in Quantity (tied) and Unit subtasks, second in MeasuredEntity, Modifier and Qualifies subtasks, and third in Qualifier subtask.
This paper presents our wining contribution to SemEval 2021 Task 8: MeasEval. The purpose of this task is identifying the counts and measurements from clinical scientific discourse, including quantities, entities, properties, qualifiers, units, modifiers, and their mutual relations. This task can be induced to a joint entity and relation extraction problem. Accordingly, we propose CONNER, a cascade count and measurement extraction tool that can identify entities and the corresponding relations in a two-step pipeline model. We provide a detailed description of the proposed model hereinafter. Furthermore, the impact of the essential modules and our in-process technical schemes are also investigated.
This paper presents our system for the Quantity span identification, Unit of measurement identification and Value modifier classification subtasks of the MeasEval 2021 task. The purpose of the Quantity span identification task was to locate spans of text that contain a count or measurement, consisting of a value, usually followed by a unit and occasionally additional modifiers. The goal of the modifier classification task was to determine whether an associated text fragment served to indicate range, tolerance, mean value, etc. of a quantity. The developed systems used pre-trained BERT models which were fine-tuned for the task at hand. We present our system, investigate how architectural decisions affected model predictions, and conduct an error analysis. Overall, our system placed 12 / 19 in the shared task and in the 2nd place for the Unit subcategory.
This work describes our approach for subtasks of SemEval-2021 Task 8: MeasEval: Counts and Measurements which took the official first place in the competition. To solve all subtasks we use multi-task learning in a question-answering-like manner. We also use learnable scalar weights to weight subtasks’ contribution to the final loss in multi-task training. We fine-tune LUKE to extract quantity spans and we fine-tune RoBERTa to extract everything related to found quantities, including quantities themselves.
Question answering from semi-structured tables can be seen as a semantic parsing task and is significant and practical for pushing the boundary of natural language understanding. Existing research mainly focuses on understanding contents from unstructured evidence, e.g., news, natural language sentences and documents. The task of verification from structured evidence, such as tables, charts, and databases, is still less-explored. This paper describes sattiy team’s system in SemEval-2021 task 9: Statement Verification and Evidence Finding with Tables (SEM-TAB-FACT)(CITATION). This competition aims to verify statements and to find evidence from tables for scientific articles and to promote proper interpretation of the surrounding article. In this paper we exploited ensemble models of pre-trained language models over tables, TaPas and TaBERT, for Task A and adjust the result based on some rules extracted for Task B. Finally, in the leadboard, we attain the F1 scores of 0.8496 and 0.7732 in Task A for the 2-way and 3-way evaluation, respectively, and the F1 score of 0.4856 in Task B.
Tables are widely used in various kinds of documents to present information concisely. Understanding tables is a challenging problem that requires an understanding of language and table structure, along with numerical and logical reasoning. In this paper, we present our systems to solve Task 9 of SemEval-2021: Statement Verification and Evidence Finding with Tables (SEM-TAB-FACTS). The task consists of two subtasks: (A) Given a table and a statement, predicting whether the table supports the statement and (B) Predicting which cells in the table provide evidence for/against the statement. We fine-tune TAPAS (a model which extends BERT’s architecture to capture tabular structure) for both the subtasks as it has shown state-of-the-art performance in various table understanding tasks. In subtask A, we evaluate how transfer learning and standardizing tables to have a single header row improves TAPAS’ performance. In subtask B, we evaluate how different fine-tuning strategies can improve TAPAS’ performance. Our systems achieve an F1 score of 67.34 in subtask A three-way classification, 72.89 in subtask A two-way classification, and 62.95 in subtask B.
This paper describes the system submitted in the SemEval-2021 Statement Verification and Evidence Finding with Tables task. The system relies on candidate generation for logical forms on the table based on keyword matching and dependency parsing on the claim statements.
This paper describes our approach for Task 9 of SemEval 2021: Statement Verification and Evidence Finding with Tables. We participated in both subtasks, namely statement verification and evidence finding. For the subtask of statement verification, we extend the TAPAS model to adapt to the ‘unknown’ class of statements by finetuning it on an augmented version of the task data. For the subtask of evidence finding, we finetune the DistilBERT model in a Siamese setting.
Due to the increasing concerns for data privacy, source-free unsupervised domain adaptation attracts more and more research attention, where only a trained source model is assumed to be available, while the labeled source data remain private. To get promising adaptation results, we need to find effective ways to transfer knowledge learned in source domain and leverage useful domain specific information from target domain at the same time. This paper describes our winning contribution to SemEval 2021 Task 10: Source-Free Domain Adaptation for Semantic Processing. Our key idea is to leverage the model trained on source domain data to generate pseudo labels for target domain samples. Besides, we propose Negation-aware Pre-training (NAP) to incorporate negation knowledge into model. Our method win the 1st place with F1-score of 0.822 on the official blind test set of Negation Detection Track.
Data sharing restrictions are common in NLP datasets. The purpose of this task is to develop a model trained in a source domain to make predictions for a target domain with related domain data. To address the issue, the organizers provided the models that fine-tuned a large number of source domain data on pre-trained models and the dev data for participants. But the source domain data was not distributed. This paper describes the provided model to the NER (Name entity recognition) task and the ways to develop the model. As a little data provided, pre-trained models are suitable to solve the cross-domain tasks. The models fine-tuned by large number of another domain could be effective in new domain because the task had no change.
This paper presents our endeavor for solving task11, NLPContributionGraph, of SemEval-2021. The purpose of the task was to extract triples from a paper in the Nature Language Processing field for constructing an Open Research Knowledge Graph. The task includes three sub-tasks: detecting the contribution sentences in papers, identifying scientific terms and predicate phrases from the contribution sentences; and inferring triples in the form of (subject, predicate, object) as statements for Knowledge Graph building. In this paper, we apply an ensemble of various fine-tuned pre-trained language models (PLM) for tasks one and two. In addition, self-training methods are adopted for tackling the shortage of annotated data. For the third task, rather than using classic neural open information extraction (OIE) architectures, we generate potential triples via manually designed rules and develop a binary classifier to differentiate positive ones from others. The quantitative results show that we obtain the 4th, 2nd, and 2nd rank in three evaluation phases.
Crowdsourcing has been ubiquitously used for annotating enormous collections of data. However, the major obstacles to using crowd-sourced labels are noise and errors from non-expert annotations. In this work, two approaches dealing with the noise and errors in crowd-sourced labels are proposed. The first approach uses Sharpness-Aware Minimization (SAM), an optimization technique robust to noisy labels. The other approach leverages a neural network layer called softmax-Crowdlayer specifically designed to learn from crowd-sourced annotations. According to the results, the proposed approaches can improve the performance of the Wide Residual Network model and Multi-layer Perception model applied on crowd-sourced datasets in the image processing domain. It also has similar and comparable results with the majority voting technique when applied to the sequential data domain whereby the Bidirectional Encoder Representations from Transformers (BERT) is used as the base model in both instances.
Reducing communication breakdown is critical to success in interactive NLP applications, such as dialogue systems. To this end, we propose a confusion-mitigation framework for the detection and remediation of communication breakdown. In this work, as a first step towards implementing this framework, we focus on detecting phonemic sources of confusion. As a proof-of-concept, we evaluate two neural architectures in predicting the probability that a listener will misunderstand phonemes in an utterance. We show that both neural models outperform a weighted n-gram baseline, showing early promise for the broader framework.
This paper investigates bounds on the generative capacity of prosodic processes, by focusing on the complexity of recursive prosody in coordination contexts in English (Wagner, 2010). Although all phonological processes and most prosodic processes are computationally regular string languages, we show that recursive prosody is not. The output string language is instead parallel multiple context-free (Seki et al., 1991). We evaluate the complexity of the pattern over strings, and then move on to a characterization over trees that requires the expressivity of multi bottom-up tree transducers. In doing so, we provide a foundation for future mathematically grounded investigations of the syntax-prosody interface.
Raimy (1999; 2000a; 2000b) proposed a graphical formalism for modeling reduplication, originallymostly focused on phonological overapplication in a derivational framework. This framework is now known as Precedence-based phonology or Multiprecedence phonology. Raimy’s idea is that the segments at the input to the phonology are not totally ordered by precedence. This paper tackles a challenge that arose with Raimy’s work, the development of a deterministic serialization algorithm as part of the derivation of surface forms. The Match-Extend algorithm introduced here requires fewer assumptions and sticks tighter to the attested typology. The algorithm also contains no parameter or constraint specific to individual graphs or topologies, unlike previous proposals. Match-Extend requires nothing except knowing the last added set of links.
This paper investigates how the ordering of tone relative to the segmental string influences the calculation of phonotactic probability. Trigram and recurrent neural network models were trained on syllable lexicons of four Asian syllable-tone languages (Mandarin, Thai, Vietnamese, and Cantonese) in which tone was treated as a segment occurring in different positions in the string. For trigram models, the optimal permutation interacted with language, while neural network models were relatively unaffected by tone position in all languages. In addition to providing a baseline for future evaluation, these results suggest that phonotactic probability is robust to choices of how tone is ordered with respect to other elements in the syllable.
Large-scale morphological databases provide essential input to a wide range of NLP applications. Inflectional data is of particular importance for morphologically rich (agglutinative and highly inflecting) languages, and derivations can be used, e.g. to infer the semantics of out-of-vocabulary words. Extending the scope of state-of-the-art multilingual morphological databases, we announce the release of MorphyNet, a high-quality resource with 15 languages, 519k derivational and 10.1M inflectional entries, and a rich set of morphological features. MorphyNet was extracted from Wiktionary using both hand-crafted and automated methods, and was manually evaluated to be of a precision higher than 98%. Both the resource generation logic and the resulting database are made freely available and are reusable as stand-alone tools or in combination with existing resources.
In this work, we analyze the robustness of neural machine translation systems towards grammatical perturbations in the source. In particular, we focus on morphological inflection related perturbations. While this has been recently studied for English→French (MORPHEUS) (Tan et al., 2020), it is unclear how this extends to Any→English translation systems. We propose MORPHEUS-MULTILINGUAL that utilizes UniMorph dictionaries to identify morphological perturbations to source that adversely affect the translation models. Along with an analysis of state-of-the-art pretrained MT systems, we train and analyze systems for 11 language pairs using the multilingual TED corpus (Qi et al., 2018). We also compare this to actual errors of non-native speakers using Grammatical Error Correction datasets. Finally, we present a qualitative and quantitative analysis of the robustness of Any→English translation systems.
Neural models excel at extracting statistical patterns from large amounts of data, but struggle to learn patterns or reason about language from only a few examples. In this paper, we ask: Can we learn explicit rules that generalize well from only a few examples? We explore this question using program synthesis. We develop a synthesis model to learn phonology rules as programs in a domain-specific language. We test the ability of our models to generalize from few training examples using our new dataset of problems from the Linguistics Olympiad, a challenging set of tasks that require strong linguistic reasoning ability. In addition to being highly sample-efficient, our approach generates human-readable programs, and allows control over the generalizability of the learnt programs.
We describe the second SIGMORPHON shared task on unsupervised morphology: the goal of the SIGMORPHON 2021 Shared Task on Unsupervised Morphological Paradigm Clustering is to cluster word types from a raw text corpus into paradigms. To this end, we release corpora for 5 development and 9 test languages, as well as gold partial paradigms for evaluation. We receive 14 submissions from 4 teams that follow different strategies, and the best performing system is based on adaptor grammars. Results vary significantly across languages. However, all systems are outperformed by a supervised lemmatizer, implying that there is still room for improvement.
This work describes the Edinburgh submission to the SIGMORPHON 2021 Shared Task 2 on unsupervised morphological paradigm clustering. Given raw text input, the task was to assign each token to a cluster with other tokens from the same paradigm. We use Adaptor Grammar segmentations combined with frequency-based heuristics to predict paradigm clusters. Our system achieved the highest average F1 score across 9 test languages, placing first out of 15 submissions.
This paper presents two different systems for unsupervised clustering of morphological paradigms, in the context of the SIGMORPHON 2021 Shared Task 2. The goal of this task is to correctly cluster words in a given language by their inflectional paradigm, without any previous knowledge of the language and without supervision from labeled data of any sort. The words in a single morphological paradigm are different inflectional variants of an underlying lemma, meaning that the words share a common core meaning. They also - usually - show a high degree of orthographical similarity. Following these intuitions, we investigate KMeans clustering using two different types of word representations: one focusing on orthographical similarity and the other focusing on semantic similarity.Additionally, we discuss the merits of randomly initialized centroids versus pre-defined centroids for clustering. Pre-defined centroids are identified based on either a standard longest common substring algorithm or a connected graph method built off of longest common substring. For all development languages, the character-based embeddings perform similarly to the baseline, and the semantic embeddings perform well below the baseline.Analysis of the systems’ errors suggests that clustering based on orthographic representations is suitable for a wide range of morphological mechanisms, particularly as part of a larger system.
This paper describes the submission of the CU-UBC team for the SIGMORPHON 2021 Shared Task 2: Unsupervised morphological paradigm clustering. Our system generates paradigms using morphological transformation rules which are discovered from raw data. We experiment with two methods for discovering rules. Our first approach generates prefix and suffix transformations between similar strings. Secondly, we experiment with more general rules which can apply transformations inside the input strings in addition to prefix and suffix transformations. We find that the best overall performance is delivered by prefix and suffix rules but more general transformation rules perform better for languages with templatic morphology and very high morpheme-to-word ratios.
This paper describes our system for the SIGMORPHON 2021 Shared Task on Unsupervised Morphological Paradigm Clustering, which asks participants to group inflected forms together according their underlying lemma without the aid of annotated training data. We employ agglomerative clustering to group word forms together using a metric that combines an orthographic distance and a semantic distance from word embeddings. We experiment with two variations of an edit distance-based model for quantifying orthographic distance, but, due to time constraints, our system does not improve over the shared task’s baseline system.
Grapheme-to-phoneme conversion is an important component in many speech technologies, but until recently there were no multilingual benchmarks for this task. The second iteration of the SIGMORPHON shared task on multilingual grapheme-to-phoneme conversion features many improvements from the previous year’s task (Gorman et al. 2020), including additional languages, a stronger baseline, three subtasks varying the amount of available resources, extensive quality assurance procedures, and automated error analyses. Four teams submitted a total of thirteen systems, at best achieving relative reductions of word error rate of 11% in the high-resource subtask and 4% in the low-resource subtask.
In this paper we explore a very simple neural approach to mapping orthography to phonetic transcription in a low-resource context. The basic idea is to start from a baseline system and focus all efforts on data augmentation. We will see that some techniques work, but others do not.
This paper documents the UBC Linguistics team’s approach to the SIGMORPHON 2021 Grapheme-to-Phoneme Shared Task, concentrating on the low-resource setting. Our systems expand the baseline model with simple modifications informed by syllable structure and error analysis. In-depth investigation of test-set predictions shows that our best model rectifies a significant number of mistakes compared to the baseline prediction, besting all other submissions. Our results validate the view that careful error analysis in conjunction with linguistic knowledge can lead to more effective computational modeling.
We describe three baseline beating systems for the high-resource English-only sub-task of the SIGMORPHON 2021 Shared Task 1: a small ensemble that Dialpad’s speech recognition team uses internally, a well-known off-the-shelf model, and a larger ensemble model comprising these and others. We additionally discuss the challenges related to the provided data, along with the processing steps we took.
This paper describes the submission by the team from the Department of Computational Linguistics, Zurich University, to the Multilingual Grapheme-to-Phoneme Conversion (G2P) Task 1 of the SIGMORPHON 2021 challenge in the low and medium settings. The submission is a variation of our 2020 G2P system, which serves as the baseline for this year’s challenge. The system is a neural transducer that operates over explicit edit actions and is trained with imitation learning. For this challenge, we experimented with the following changes: a) emitting phoneme segments instead of single character phonemes, b) input character dropout, c) a mogrifier LSTM decoder (Melis et al., 2019), d) enriching the decoder input with the currently attended input character, e) parallel BiLSTM encoders, and f) an adaptive batch size scheduler. In the low setting, our best ensemble improved over the baseline, however, in the medium setting, the baseline was stronger on average, although for certain languages improvements could be observed.
We investigate how abstract processes like suffixation can be learned from morphological inflection task data using an analogical memory-based framework. In this framework, the inflection target form is specified by providing an example inflection of another word in the language. We show that this model is capable of near-baseline performance on the SigMorphon 2020 inflection challenge. Such a model can make predictions for unseen languages, allowing us to perform one-shot inflection on natural languages and investigate morphological transfer with synthetic probes. Accuracy for one-shot transfer can be unexpectedly high for some target languages (88% in Shona) and language families (53% across Romance). Probe experiments show that the model learns partially generalizable representations of prefixation, suffixation and reduplication, aiding its ability to transfer. We argue that the degree of generality of these process representations also helps to explain transfer results from previous research.
We introduce a simple and highly general phonotactic learner which induces a probabilistic finite-state automaton from word-form data. We describe the learner and show how to parameterize it to induce unrestricted regular languages, as well as how to restrict it to certain subregular classes such as Strictly k-Local and Strictly k-Piecewise languages. We evaluate the learner on its ability to learn phonotactic constraints in toy examples and in datasets of Quechua and Navajo. We find that an unrestricted learner is the most accurate overall when modeling attested forms not seen in training; however, only the learner restricted to the Strictly Piecewise language class successfully captures certain nonlocal phonotactic constraints. Our learner serves as a baseline for more sophisticated methods.
Total reduplication is common in natural language phonology and morphology. However, formally as copying on reduplicants of unbounded size, unrestricted total reduplication requires computational power beyond context-free, while other phonological and morphological patterns are regular, or even sub-regular. Thus, existing language classes characterizing reduplicated strings inevitably include typologically unattested context-free patterns, such as reversals. This paper extends regular languages to incorporate reduplication by introducing a new computational device: finite state buffered machine (FSBMs). We give its mathematical definitions and discuss some closure properties of the corresponding set of languages. As a result, the class of regular languages and languages derived from them through a copying mechanism is characterized. Suggested by previous literature, this class of languages should approach the characterization of natural language word sets.
This paper presents a finite-state morphological analyzer for the Gitksan language. The analyzer draws from a 1250-token Eastern dialect wordlist. It is based on finite-state technology and additionally includes two extensions which can provide analyses for out-of-vocabulary words: rules for generating predictable dialect variants, and a neural guesser component. The pre-neural analyzer, tested against interlinear-annotated texts from multiple dialects, achieves coverage of (75-81%), and maintains high precision (95-100%). The neural extension improves coverage at the cost of lowered precision.
Traditionally, character-level transduction problems have been solved with finite-state models designed to encode structural and linguistic knowledge of the underlying process, whereas recent approaches rely on the power and flexibility of sequence-to-sequence models with attention. Focusing on the less explored unsupervised learning scenario, we compare the two model classes side by side and find that they tend to make different types of errors even when achieving comparable performance. We analyze the distributions of different error classes using two unsupervised tasks as testbeds: converting informally romanized text into the native script of its language (for Russian, Arabic, and Kannada) and translating between a pair of closely related languages (Serbian and Bosnian). Finally, we investigate how combining finite-state and sequence-to-sequence models at decoding time affects the output quantitatively and qualitatively.
Shupamem, a language of Western Cameroon, is a tonal language which also exhibits the morpho-phonological process of full reduplication. This creates two challenges for finite-state model of its morpho-syntax and morphophonology: how to manage the full reduplication and the autosegmental nature of lexical tone. Dolatian and Heinz (2020) explain how 2-way finite-state transducers can model full reduplication without an exponential increase in states, and finite-state transducers with multiple tapes have been used to model autosegmental tiers, including tone (Wiebe, 1992; Dolatian and Rawski, 2020a). Here we synthesize 2-way finite-state transducers and multitape transducers, resulting in a finite-state formalism that subsumes both, to account for the full reduplicative processes in Shupamem which also affect tone.
Pronunciation lexicons and prediction models are a key component in several speech synthesis and recognition systems. We know that morphologically related words typically follow a fixed pattern of pronunciation which can be described by language-specific paradigms. In this work we explore how deep recurrent neural networks can be used to automatically learn and exploit this pattern to improve the pronunciation prediction quality of words related by morphological inflection. We propose two novel approaches for supplying morphological information, using the word’s morphological class and its lemma, which are typically annotated in standard lexicons. We report improvements across a number of European languages with varying degrees of phonological and morphological complexity, and two language families, with greater improvements for languages where the pronunciation prediction task is inherently more challenging. We also observe that combining bidirectional LSTM networks with attention mechanisms is an effective neural approach for the computational problem considered, across languages. Our approach seems particularly beneficial in the low resource setting, both by itself and in conjunction with transfer learning.
This year's iteration of the SIGMORPHON Shared Task on morphological reinflection focuses on typological diversity and cross-lingual variation of morphosyntactic features. In terms of the task, we enrich UniMorph with new data for 32 languages from 13 language families, with most of them being under-resourced: Kunwinjku, Classical Syriac, Arabic (Modern Standard, Egyptian, Gulf), Hebrew, Amharic, Aymara, Magahi, Braj, Kurdish (Central, Northern, Southern), Polish, Karelian, Livvi, Ludic, Veps, Võro, Evenki, Xibe, Tuvan, Sakha, Turkish, Indonesian, Kodi, Seneca, Asháninka, Yanesha, Chukchi, Itelmen, Eibela. We evaluate six systems on the new data and conduct an extensive error analysis of the systems' predictions. Transformer-based models generally demonstrate superior performance on the majority of languages, achieving >90% accuracy on 65% of them. The languages on which systems yielded low accuracy are mainly under-resourced, with a limited amount of data. Most errors made by the systems are due to allomorphy, honorificity, and form variation. In addition, we observe that systems especially struggle to inflect multiword lemmas. The systems also produce misspelled forms or end up in repetitive loops (e.g., RNN-based models). Finally, we report a large drop in systems' performance on previously unseen lemmas.
This paper presents the submission of team GUCLASP to SIGMORPHON 2021 Shared Task on Generalization in Morphological Inflection Generation. We develop a multilingual model for Morphological Inflection and primarily focus on improving the model by using various training strategies to improve accuracy and generalization across languages.
We present the BME submission for the SIGMORPHON 2021 Task 0 Part 1, Generalization Across Typologically Diverse Languages shared task. We use an LSTM encoder-decoder model with three step training that is first trained on all languages, then fine-tuned on each language family and finally fine-tuned on individual languages. We use a different type of data augmentation technique in the first two steps. Our system outperformed the only other submission. Although it remains worse than the Transformer baseline released by the organizers, our model is simpler and our data augmentation techniques are easily applicable to new languages. We perform ablation studies and show that the augmentation techniques and the three training steps often help but sometimes have a negative effect. Our code is publicly available.
The paper presents four models submitted to Part 2 of the SIGMORPHON 2021 Shared Task 0, which aims at replicating human judgements on the inflection of nonce lexemes. Our goal is to explore the usefulness of combining pre-compiled analogical patterns with an encoder-decoder architecture. Two models are designed using such patterns either in the input or the output of the network. Two extra models controlled for the role of raw similarity of nonce inflected forms to existing inflected forms in the same paradigm cell, and the role of the type frequency of analogical patterns. Our strategy is entirely endogenous in the sense that the models appealing solely to the data provided by the SIGMORPHON organisers, without using external resources. Our model 2 ranks second among all submitted systems, suggesting that the inclusion of analogical patterns in the network architecture is useful in mimicking speakers’ predictions.
Morphological rules with various levels of specificity can be learned from example lexemes by recursive application of minimal generalization (Albright and Hayes, 2002, 2003).A model that learns rules solely through minimal generalization was used to predict average human wug-test ratings from German, English, and Dutch in the SIGMORPHON-UniMorph 2021 Shared Task, with competitive results. Some formal properties of the minimal generalization operation were proved. An automatic method was developed to create wug-test stimuli for future experiments that investigate whether the model’s morphological generalizations are too minimal.
This paper describes a method for learning from a teacher’s potentially unreliable corrective feedback in an interactive task learning setting. The graphical model uses discourse coherence to jointly learn symbol grounding, domain concepts and valid plans. Our experiments show that the agent learns its domain-level task in spite of the teacher’s mistakes.
Robust situated dialog requires the ability to process instructions based on spatial information, which may or may not be available. We propose a model, based on LXMERT, that can extract spatial information from text instructions and attend to landmarks on OpenStreetMap (OSM) referred to in a natural language instruction. Whilst, OSM is a valuable resource, as with any open-sourced data, there is noise and variation in the names referred to on the map, as well as, variation in natural language instructions, hence the need for data-driven methods over rule-based systems. This paper demonstrates that the gold GPS location can be accurately predicted from the natural language instruction and metadata with 72% accuracy for previously seen maps and 64% for unseen maps.
In this paper, we define and evaluate a methodology for extracting history-dependent spatial questions from visual dialogues. We say that a question is history-dependent if it requires (parts of) its dialogue history to be interpreted. We argue that some kinds of visual questions define a context upon which a follow-up spatial question relies. We call the question that restricts the context: trigger, and we call the spatial question that requires the trigger question to be answered: zoomer. We automatically extract different trigger and zoomer pairs based on the visual property that the questions rely on (e.g. color, number). We manually annotate the automatically extracted trigger and zoomer pairs to verify which zoomers require their trigger. We implement a simple baseline architecture based on a SOTA multimodal encoder. Our results reveal that there is much room for improvement for answering history-dependent questions.
Understanding spatial expressions and using them appropriately is necessary for seamless and natural human-machine interaction. However, capturing the semantics and appropriate usage of spatial prepositions is notoriously difficult, because of their vagueness and polysemy. Although modern data-driven approaches are good at capturing statistical regularities in the usage, they usually require substantial sample sizes, often do not generalize well to unseen instances and, most importantly, their structure is essentially opaque to analysis, which makes diagnosing problems and understanding their reasoning process difficult. In this work, we discuss our attempt at modeling spatial senses of prepositions in English using a combination of rule-based and statistical learning approaches. Each preposition model is implemented as a tree where each node computes certain intuitive relations associated with the preposition, with the root computing the final value of the prepositional relation itself. The models operate on a set of artificial 3D “room world” environments, designed in Blender, taking the scene itself as an input. We also discuss our annotation framework used to collect human judgments employed in the model training. Both our factored models and black-box baseline models perform quite well, but the factored models will enable reasoned explanations of spatial relation judgements.
We deal with the navigation problem where the agent follows natural language instructions while observing the environment. Focusing on language understanding, we show the importance of spatial semantics in grounding navigation instructions into visual perceptions. We propose a neural agent that uses the elements of spatial configurations and investigate their influence on the navigation agent’s reasoning ability. Moreover, we model the sequential execution order and align visual objects with spatial configurations in the instruction. Our neural agent improves strong baselines on the seen environments and shows competitive performance on the unseen environments. Additionally, the experimental results demonstrate that explicit modeling of spatial semantic elements in the instructions can improve the grounding and spatial reasoning of the model.
In semantic parsing of geographical queries against real-world databases such as OpenStreetMap (OSM), unique correct answers do not necessarily exist. Instead, the truth might be lying in the eye of the user, who needs to enter an interactive setup where ambiguities can be resolved and parsing mistakes can be corrected. Our work presents an approach to interactive semantic parsing where an explicit error detection is performed, and a clarification question is generated that pinpoints the suspected source of ambiguity or error and communicates it to the human user. Our experimental results show that a combination of entropy-based uncertainty detection and beam search, together with multi-source training on clarification question, initial parse, and user answer, results in improvements of 1.2% F1 score on a parser that already performs at 90.26% on the NLMaps dataset for OSM semantic parsing.
Ideally, people who navigate together in a complex indoor space share a mental model that facilitates explanation. This paper reports on a robot control system whose cognitive world model is based on spatial affordances that generalize over its perceptual data. Given a target, the control system formulates multiple plans, each with a model-relevant metric, and selects among them. As a result, it can provide readily understandable natural language about the robot’s intentions and confidence, and generate diverse, contrastive explanations that reference the acquired spatial model. Empirical results in large, complex environments demonstrate the robot’s ability to provide human-friendly explanations in natural language.
With the development of robotics, the use of robots in daily life is increasing, which has led to the need for anyone to easily train robots to improve robot use. Interactive reinforcement learning(IARL) is a method for robot training based on human–robot interaction; prior studies on IARL provide only limited types of feedback or require appropriately designed shaping rewards, which is known to be difficult and time-consuming. Therefore, in this study, we propose interactive deep reinforcement learning models based on voice feedback. In the proposed system, a robot learns the task of cooperative table balancing through deep Q-network using voice feedback provided by humans in real-time, with automatic speech recognition(ASR) and sentiment analysis to understand human voice feedback. As a result, an optimal policy convergence rate of up to 96% was realized, and performance was improved in all voice feedback-based models
We present a multi-level geocoding model (MLG) that learns to associate texts to geographic coordinates. The Earth’s surface is represented using space-filling curves that decompose the sphere into a hierarchical grid. MLG balances classification granularity and accuracy by combining losses across multiple levels and jointly predicting cells at different levels simultaneously. It obtains large gains without any gazetteer metadata, demonstrating that it can effectively learn the connection between text spans and coordinates—and thus makes it a gazetteer-free geocoder. Furthermore, MLG obtains state-of-the-art results for toponym resolution on three English datasets without any dataset-specific tuning.
To date, most abstractive summarisation models have relied on variants of the negative log-likelihood (NLL) as their training objective. In some cases, reinforcement learning has been added to train the models with an objective that is closer to their evaluation measures (e.g. ROUGE). However, the reward function to be used within the reinforcement learning approach can play a key role for performance and is still partially unexplored. For this reason, in this paper, we propose two reward functions for the task of abstractive summarisation: the first function, referred to as RwB-Hinge, dynamically selects the samples for the gradient update. The second function, nicknamed RISK, leverages a small pool of strong candidates to inform the reward. In the experiments, we probe the proposed approach by fine-tuning an NLL pre-trained model over nine summarisation datasets of diverse size and nature. The experimental results show a consistent improvement over the negative log-likelihood baselines.
The de-facto standard decoding method for semantic parsing in recent years has been to autoregressively decode the abstract syntax tree of the target program using a top-down depth-first traversal. In this work, we propose an alternative approach: a Semi-autoregressive Bottom-up Parser (SmBoP) that constructs at decoding step t the top-K sub-trees of height ≤ t. Our parser enjoys several benefits compared to top-down autoregressive parsing. From an efficiency perspective, bottom-up parsing allows to decode all sub-trees of a certain height in parallel, leading to logarithmic runtime complexity rather than linear. From a modeling perspective, a bottom-up parser learns representations for meaningful semantic sub-programs at each step, rather than for semantically-vacuous partial trees. We apply SmBoP on Spider, a challenging zero-shot semantic parsing benchmark, and show that SmBoP leads to a 2.2x speed-up in decoding time and a ~5x speed-up in training time, compared to a semantic parser that uses autoregressive decoding. SmBoP obtains 71.1 denotation accuracy on Spider, establishing a new state-of-the-art, and 69.5 exact match, comparable to the 69.6 exact match of the autoregressive RAT-SQL+Grappa.
AM dependency parsing is a method for neural semantic graph parsing that exploits the principle of compositionality. While AM dependency parsers have been shown to be fast and accurate across several graphbanks, they require explicit annotations of the compositional tree structures for training. In the past, these were obtained using complex graphbank-specific heuristics written by experts. Here we show how they can instead be trained directly on the graphs with a neural latent-variable model, drastically reducing the amount and complexity of manual heuristics. We demonstrate that our model picks up on several linguistic phenomena on its own and achieves comparable accuracy to supervised training, greatly facilitating the use of AM dependency parsing for new sembanks.
Large volumes of interaction logs can be collected from NLP systems that are deployed in the real world. How can this wealth of information be leveraged? Using such interaction logs in an offline reinforcement learning (RL) setting is a promising approach. However, due to the nature of NLP tasks and the constraints of production systems, a series of challenges arise. We present a concise overview of these challenges and discuss possible solutions.
Despite its wide use, recent studies have revealed unexpected and undesirable properties of neural autoregressive sequence models trained with maximum likelihood, such as an unreasonably high affinity to short sequences after training and to infinitely long sequences at decoding time. We propose to study these phenomena by investigating how the modes, or local maxima, of a distribution are maintained throughout the full learning chain of the ground-truth, empirical, learned and decoding-induced distributions, via the newly proposed mode recovery cost. We design a tractable testbed where we build three types of ground-truth distributions: (1) an LSTM based structured distribution, (2) an unstructured distribution where probability of a sequence does not depend on its content, and (3) a product of these two which we call a semi-structured distribution. Our study reveals both expected and unexpected findings. First, starting with data collection, mode recovery cost strongly relies on the ground-truth distribution and is most costly with the semi-structured distribution. Second, after learning, mode recovery cost from the ground-truth distribution may increase or decrease compared to data collection, with the largest cost degradation occurring with the semi-structured ground-truth distribution. Finally, the ability of the decoding-induced distribution to recover modes from the learned distribution is highly impacted by the choices made earlier in the learning chain. We conclude that future research must consider the entire learning chain in order to fully understand the potentials and perils and to further improve neural autoregressive sequence models.
The analysis of public debates crucially requires the classification of political demands according to hierarchical claim ontologies (e.g. for immigration, a supercategory “Controlling Migration” might have subcategories “Asylum limit” or “Border installations”). A major challenge for automatic claim classification is the large number and low frequency of such subclasses. We address it by jointly predicting pairs of matching super- and subcategories. We operationalize this idea by (a) encoding soft constraints in the claim classifier and (b) imposing hard constraints via Integer Linear Programming. Our experiments with different claim classifiers on a German immigration newspaper corpus show consistent performance increases for joint prediction, in particular for infrequent categories and discuss the complementarity of the two approaches.
In this paper, we propose a globally normalized model for context-free grammar (CFG)-based semantic parsing. Instead of predicting a probability, our model predicts a real-valued score at each step and does not suffer from the label bias problem. Experiments show that our approach outperforms locally normalized models on small datasets, but it does not yield improvement on a large dataset.
In this work, we empirically compare span extraction methods for the task of semantic role labeling (SRL). While recent progress incorporating pre-trained contextualized representations into neural encoders has greatly improved SRL F1 performance on popular benchmarks, the potential costs and benefits of structured decoding in these models have become less clear. With extensive experiments on PropBank SRL datasets, we find that more structured decoding methods outperform BIO-tagging when using static (word type) embeddings across all experimental settings. However, when used in conjunction with pre-trained contextualized word representations, the benefits are diminished. We also experiment in cross-genre and cross-lingual settings and find similar trends. We further perform speed comparisons and provide analysis on the accuracy-efficiency trade-offs among different decoding methods.
Prior research has explored the ability of computational models to predict a word semantic fit with a given predicate. While much work has been devoted to modeling the typicality relation between verbs and arguments in isolation, in this paper we take a broader perspective by assessing whether and to what extent computational approaches have access to the information about the typicality of entire events and situations described in language (Generalized Event Knowledge). Given the recent success of Transformers Language Models (TLMs), we decided to test them on a benchmark for the dynamic estimation of thematic fit. The evaluation of these models was performed in comparison with SDM, a framework specifically designed to integrate events in sentence meaning representations, and we conducted a detailed error analysis to investigate which factors affect their behavior. Our results show that TLMs can reach performances that are comparable to those achieved by SDM. However, additional analysis consistently suggests that TLMs do not capture important aspects of event knowledge, and their predictions often depend on surface linguistic features, such as frequent words, collocations and syntactic patterns, thereby showing sub-optimal generalization abilities.
Transformer-based language models (LMs) continue to advance state-of-the-art performance on NLP benchmark tasks, including tasks designed to mimic human-inspired “commonsense” competencies. To better understand the degree to which LMs can be said to have certain linguistic reasoning skills, researchers are beginning to adapt the tools and concepts of the field of psychometrics. But to what extent can the benefits flow in the other direction? I.e., can LMs be of use in predicting what the psychometric properties of test items will be when those items are given to human participants? We gather responses from numerous human participants and LMs (transformer- and non-transformer-based) on a broad diagnostic test of linguistic competencies. We then use the responses to calculate standard psychometric properties of the items in the diagnostic test, using the human responses and the LM responses separately. We then determine how well these two sets of predictions match. We find cases in which transformer-based LMs predict psychometric properties consistently well in certain categories but consistently poorly in others, thus providing new insights into fundamental similarities and differences between human and LM reasoning.
Just as the meaning of words is tied to the communities in which they are used, so too is semantic change. But how does lexical semantic change manifest differently across different communities? In this work, we investigate the relationship between community structure and semantic change in 45 communities from the social media website Reddit. We use distributional methods to quantify lexical semantic change and induce a social network on communities, based on interactions between members. We explore the relationship between semantic change and the clustering coefficient of a community’s social network graph, as well as community size and stability. While none of these factors are found to be significant on their own, we report a significant effect of their three-way interaction. We also report on significant word-level effects of frequency and change in frequency, which replicate previous findings.
Many new books get published every year, and only a fraction of them become popular among the readers. So the prediction of a book success can be a very useful parameter for publishers to make a reliable decision. This article presents the study of semantic word associations using the word embedding of book content for a set of Roget’s thesaurus concepts for book success prediction. In this work, we discuss the method to represent a book as a spectrum of concepts based on the association score between its content embedding and a global embedding (i.e. fastText) for a set of semantically linked word clusters. We show that the semantic word associations outperform the previous methods for book success prediction. In addition, we present that semantic word associations also provide better results than using features like the frequency of word groups in Roget’s thesaurus, LIWC (a popular tool for linguistic inquiry and word count), NRC (word association emotion lexicon), and part of speech (PoS). Our study reports that concept associations based on Roget’s Thesaurus using word embedding of individual novel resulted in the state-of-the-art performance of 0.89 average weighted F1-score for book success prediction. Finally, we present a set of dominant themes that contribute towards the popularity of a book for a specific genre.
Writers often repurpose material from existing texts when composing new documents. Because most documents have more than one source, we cannot trace these connections using only models of document-level similarity. Instead, this paper considers methods for local text reuse detection (LTRD), detecting localized regions of lexically or semantically similar text embedded in otherwise unrelated material. In extensive experiments, we study the relative performance of four classes of neural and bag-of-words models on three LTRD tasks – detecting plagiarism, modeling journalists’ use of press releases, and identifying scientists’ citation of earlier papers. We conduct evaluations on three existing datasets and a new, publicly-available citation localization dataset. Our findings shed light on a number of previously-unexplored questions in the study of LTRD, including the importance of incorporating document-level context for predictions, the applicability of of-the-shelf neural models pretrained on “general” semantic textual similarity tasks such as paraphrase detection, and the trade-offs between more efficient bag-of-words and feature-based neural models and slower pairwise neural models.
Abductive reasoning starts from some observations and aims at finding the most plausible explanation for these observations. To perform abduction, humans often make use of temporal and causal inferences, and knowledge about how some hypothetical situation can result in different outcomes. This work offers the first study of how such knowledge impacts the Abductive NLI task – which consists in choosing the more likely explanation for given observations. We train a specialized language model LMI that is tasked to generate what could happen next from a hypothetical scenario that evolves from a given event. We then propose a multi-task model MTL to solve the Abductive NLI task, which predicts a plausible explanation by a) considering different possible events emerging from candidate hypotheses – events generated by LMI – and b) selecting the one that is most similar to the observed outcome. We show that our MTL model improves over prior vanilla pre-trained LMs fine-tuned on Abductive NLI. Our manual evaluation and analysis suggest that learning about possible next events from different hypothetical scenarios supports abductive inference.
Deep learning (DL) based language models achieve high performance on various benchmarks for Natural Language Inference (NLI). And at this time, symbolic approaches to NLI are receiving less attention. Both approaches (symbolic and DL) have their advantages and weaknesses. However, currently, no method combines them in a system to solve the task of NLI. To merge symbolic and deep learning methods, we propose an inference framework called NeuralLog, which utilizes both a monotonicity-based logical inference engine and a neural network language model for phrase alignment. Our framework models the NLI task as a classic search problem and uses the beam search algorithm to search for optimal inference paths. Experiments show that our joint logic and neural inference system improves accuracy on the NLI task and can achieve state-of-art accuracy on the SICK and MED datasets.
We present InferBert, a method to enhance transformer-based inference models with relevant relational knowledge. Our approach facilitates learning generic inference patterns requiring relational knowledge (e.g. inferences related to hypernymy) during training, while injecting on-demand the relevant relational facts (e.g. pangolin is an animal) at test time. We apply InferBERT to the NLI task over a diverse set of inference types (hypernymy, location, color, and country of origin), for which we collected challenge datasets. In this setting, InferBert succeeds to learn general inference patterns, from a relatively small number of training instances, while not hurting performance on the original NLI data and substantially outperforming prior knowledge enhancement models on the challenge data. It further applies its inferences successfully at test time to previously unobserved entities. InferBert is computationally more efficient than most prior methods, in terms of number of parameters, memory consumption and training time.
Training and evaluation of automatic fact extraction and verification techniques require large amounts of annotated data which might not be available for low-resource languages. This paper presents ParsFEVER: the first publicly available Farsi dataset for fact extraction and verification. We adopt the construction procedure of the standard English dataset for the task, i.e., FEVER, and improve it for the case of low-resource languages. Specifically, claims are extracted from sentences that are carefully selected to be more informative. The dataset comprises nearly 23K manually-annotated claims. Over 65% of the claims in ParsFEVER are many-hop (require evidence from multiple sources), making the dataset a challenging benchmark (only 13% of the claims in FEVER are many-hop). Also, despite having a smaller training set (around one-ninth of that in Fever), a model trained on ParsFEVER attains similar downstream performance, indicating the quality of the dataset. We release the dataset and the annotation guidelines at https://github.com/Zarharan/ParsFEVER.
Recent question answering and machine reading benchmarks frequently reduce the task to one of pinpointing spans within a certain text passage that answers the given question. Typically, these systems are not required to actually understand the text on a deeper level that allows for more complex reasoning on the information contained. We introduce a new dataset called BiQuAD that requires deeper comprehension in order to answer questions in both extractive and deductive fashion. The dataset consist of 4,190 closed-domain texts and a total of 99,149 question-answer pairs. The texts are synthetically generated soccer match reports that verbalize the main events of each match. All texts are accompanied by a structured Datalog program that represents a (logical) model of its information. We show that state-of-the-art QA models do not perform well on the challenging long form contexts and reasoning requirements posed by the dataset. In particular, transformer based state-of-the-art models achieve F1-scores of only 39.0. We demonstrate how these synthetic datasets align structured knowledge with natural text and aid model introspection when approaching complex text understanding.
Accurate recovery of predicate-argument structure from a Universal Dependency (UD) parse is central to downstream tasks such as extraction of semantic roles or event representations. This study introduces compchains, a categorization of the hierarchy of predicate dependency relations present within a UD parse. Accuracy of compchain classification serves as a proxy for measuring accurate recovery of predicate-argument structure from sentences with embedding. We analyzed the distribution of compchains in three UD English treebanks, EWT, GUM and LinES, revealing that these treebanks are sparse with respect to sentences with predicate-argument structure that includes predicate-argument embedding. We evaluated the CoNLL 2018 Shared Task UDPipe (v1.2) baseline (dependency parsing) models as compchain classifiers for the EWT, GUMS and LinES UD treebanks. Our results indicate that these three baseline models exhibit poorer performance on sentences with predicate-argument structure with more than one level of embedding; we used compchains to characterize the errors made by these parsers and present examples of erroneous parses produced by the parser that were identified using compchains. We also analyzed the distribution of compchains in 58 non-English UD treebanks and then used compchains to evaluate the CoNLL’18 Shared Task baseline model for each of these treebanks. Our analysis shows that performance with respect to compchain classification is only weakly correlated with the official evaluation metrics (LAS, MLAS and BLEX). We identify gaps in the distribution of compchains in several of the UD treebanks, thus providing a roadmap for how these treebanks may be supplemented. We conclude by discussing how compchains provide a new perspective on the sparsity of training data for UD parsers, as well as the accuracy of the resulting UD parses.
We propose a structured extension to bidirectional-context conditional language generation, or “infilling,” inspired by Frame Semantic theory. Guidance is provided through one of two approaches: (1) model fine-tuning, conditioning directly on observed symbolic frames, and (2) a novel extension to disjunctive lexically constrained decoding that leverages frame semantic lexical units. Automatic and human evaluations confirm that frame-guided generation allows for explicit manipulation of intended infill semantics, with minimal loss in distinguishability from human-generated text. Our methods flexibly apply to a variety of use scenarios, and we provide an interactive web demo.
We point out that common evaluation practices for cross-document coreference resolution have been unrealistically permissive in their assumed settings, yielding inflated results. We propose addressing this issue via two evaluation methodology principles. First, as in other tasks, models should be evaluated on predicted mentions rather than on gold mentions. Doing this raises a subtle issue regarding singleton coreference clusters, which we address by decoupling the evaluation of mention detection from that of coreference linking. Second, we argue that models should not exploit the synthetic topic structure of the standard ECB+ dataset, forcing models to confront the lexical ambiguity challenge, as intended by the dataset creators. We demonstrate empirically the drastic impact of our more realistic evaluation principles on a competitive model, yielding a score which is 33 F1 lower compared to evaluating by prior lenient practices.
Many modern messaging systems allow fast and synchronous textual communication among many users. The resulting sequence of messages hides a more complicated structure in which independent sub-conversations are interwoven with one another. This poses a challenge for any task aiming to understand the content of the chat logs or gather information from them. The ability to disentangle these conversations is then tantamount to the success of many downstream tasks such as summarization and question answering. Structured information accompanying the text such as user turn, user mentions, timestamps, is used as a cue by the participants themselves who need to follow the conversation and has been shown to be important for disentanglement. DAG-LSTMs, a generalization of Tree-LSTMs that can handle directed acyclic dependencies, are a natural way to incorporate such information and its non-sequential nature. In this paper, we apply DAG-LSTMs to the conversation disentanglement task. We perform our experiments on the Ubuntu IRC dataset. We show that the novel model we propose achieves state of the art status on the task of recovering reply-to relations and it is competitive on other disentanglement metrics.
A typical goal for language understanding is to logically connect the events of a discourse, but often connective events are not described due to their commonsense nature. In order to address this deficit, we focus here on generating precondition events. Precondition generation can be framed as a sequence-to-sequence problem: given a target event, generate a possible precondition. However, in most real-world scenarios, an event can have several preconditions, which is not always suitable for standard seq2seq frameworks. We propose DiP, the Diverse Precondition generation system that can generate unique and diverse preconditions. DiP consists of three stages of the generative process – an event sampler, a candidate generator, and a post-processor. The event sampler provides control codes (precondition triggers) which the candidate generator uses to focus its generation. Post-processing further improves the results through re-ranking and filtering. Unlike other conditional generation systems, DiP automatically generates control codes without training on diverse examples. Analysis reveals that DiP improves the diversity of preconditions significantly compared to a beam search baseline. Also, manual evaluation shows that DiP generates more preconditions than a strong nucleus sampling baseline.
Semantic parsers map natural language utterances to meaning representations. The lack of a single standard for meaning representations led to the creation of a plethora of semantic parsing datasets. To unify different datasets and train a single model for them, we investigate the use of Multi-Task Learning (MTL) architectures. We experiment with five datasets (Geoquery, NLMaps, TOP, Overnight, AMR). We find that an MTL architecture that shares the entire network across datasets yields competitive or better parsing accuracies than the single-task baselines, while reducing the total number of parameters by 68%. We further provide evidence that MTL has also better compositional generalization than single-task models. We also present a comparison of task sampling methods and propose a competitive alternative to widespread proportional sampling strategies.
Multilingual semantic parsing is a cost-effective method that allows a single model to understand different languages. However, researchers face a great imbalance of availability of training data, with English being resource rich, and other languages having much less data. To tackle the data limitation problem, we propose using machine translation to bootstrap multilingual training data from the more abundant English data. To compensate for the data quality of machine translated training data, we utilize transfer learning from pretrained multilingual encoders to further improve the model. To evaluate our multilingual models on human-written sentences as opposed to machine translated ones, we introduce a new multilingual semantic parsing dataset in English, Italian and Japanese based on the Facebook Task Oriented Parsing (TOP) dataset. We show that joint multilingual training with pretrained encoders substantially outperforms our baselines on the TOP dataset and outperforms the state-of-the-art model on the public NLMaps dataset. We also establish a new baseline for zero-shot learning on the TOP dataset. We find that a semantic parser trained only on English data achieves a zero-shot performance of 44.9% exact-match accuracy on Italian sentences.
Scripts capture commonsense knowledge about everyday activities and their participants. Script knowledge proved useful in a number of NLP tasks, such as referent prediction, discourse classification, and story generation. A crucial step for the exploitation of script knowledge is script parsing, the task of tagging a text with the events and participants from a certain activity. This task is challenging: it requires information both about the ways events and participants are usually uttered in surface language as well as the order in which they occur in the world. We show how to do accurate script parsing with a hierarchical sequence model and transfer learning. Our model improves the state of the art of event parsing by over 16 points F-score and, for the first time, accurately tags script participants.
AMR (Abstract Meaning Representation) and EDS (Elementary Dependency Structures) are two popular meaning representations in NLP/NLU. AMR is more abstract and conceptual, while EDS is more low level, closer to the lexical structures of the given sentences. It is thus not surprising that EDS parsing is easier than AMR parsing. In this work, we consider using information from EDS parsing to help improve the performance of AMR parsing. We adopt a transition-based parser and propose to add EDS graphs as additional semantic features using a graph encoder composed of LSTM layer and GCN layer. Our experimental results show that the additional information from EDS parsing indeed gives a boost to the performance of the base AMR parser used in our experiments.
Abstract Meaning Representation (AMR) is a sentence-level meaning representation based on predicate argument structure. One of the challenges we find in AMR parsing is to capture the structure of complex sentences which expresses the relation between predicates. Knowing the core part of the sentence structure in advance may be beneficial in such a task. In this paper, we present a list of dependency patterns for English complex sentence constructions designed for AMR parsing. With a dedicated pattern matcher, all occurrences of complex sentence constructions are retrieved from an input sentence. While some of the subordinators have semantic ambiguities, we deal with this problem through training classification models on data derived from AMR and Wikipedia corpus, establishing a new baseline for future works. The developed complex sentence patterns and the corresponding AMR descriptions will be made public.
We present new results for the problem of sequence metaphor labeling, using the recently developed Visibility Embeddings. We show that concatenating such embeddings to the input of a BiLSTM obtains consistent and significant improvements at almost no cost, and we present further improved results when visibility embeddings are combined with BERT.
Cross-lingual representations have the potential to make NLP techniques available to the vast majority of languages in the world. However, they currently require large pretraining corpora or access to typologically similar languages. In this work, we address these obstacles by removing language identity signals from multilingual embeddings. We examine three approaches for this: (i) re-aligning the vector spaces of target languages (all together) to a pivot source language; (ii) removing language-specific means and variances, which yields better discriminativeness of embeddings as a by-product; and (iii) increasing input similarity across languages by removing morphological contractions and sentence reordering. We evaluate on XNLI and reference-free MT evaluation across 19 typologically diverse languages. Our findings expose the limitations of these approaches—unlike vector normalization, vector space re-alignment and text normalization do not achieve consistent gains across encoders and languages. Due to the approaches’ additive effects, their combination decreases the cross-lingual transfer gap by 8.9 points (m-BERT) and 18.2 points (XLM-R) on average across all tasks and languages, however.
We suggest to model human-annotated Word Usage Graphs capturing fine-grained semantic proximity distinctions between word uses with a Bayesian formulation of the Weighted Stochastic Block Model, a generative model for random graphs popular in biology, physics and social sciences. By providing a probabilistic model of graded word meaning we aim to approach the slippery and yet widely used notion of word sense in a novel way. The proposed framework enables us to rigorously compare models of word senses with respect to their fit to the data. We perform extensive experiments and select the empirically most adequate model.
Predicting the difficulty of domain-specific vocabulary is an important task towards a better understanding of a domain, and to enhance the communication between lay people and experts. We investigate German closed noun compounds and focus on the interaction of compound-based lexical features (such as frequency and productivity) and terminology-based features (contrasting domain-specific and general language) across word representations and classifiers. Our prediction experiments complement insights from classification using (a) manually designed features to characterise termhood and compound formation and (b) compound and constituent word embeddings. We find that for a broad binary distinction into ‘easy’ vs. ‘difficult’ general-language compound frequency is sufficient, but for a more fine-grained four-class distinction it is crucial to include contrastive termhood features and compound and constituent features.
Recent work in cross-topic argument mining attempts to learn models that generalise across topics rather than merely relying on within-topic spurious correlations. We examine the effectiveness of this approach by analysing the output of single-task and multi-task models for cross-topic argument mining, through a combination of linear approximations of their decision boundaries, manual feature grouping, challenge examples, and ablations across the input vocabulary. Surprisingly, we show that cross-topic models still rely mostly on spurious correlations and only generalise within closely related topics, e.g., a model trained only on closed-class words and a few common open-class words outperforms a state-of-the-art cross-topic model on distant target topics.
Word embedding techniques depend heavily on the frequencies of words in the corpus, and are negatively impacted by failures in providing reliable representations for low-frequency words or unseen words during training. To address this problem, we propose an algorithm to learn embeddings for rare words based on an Internet search engine and the spatial location relationships. Our algorithm proceeds in two steps. We firstly retrieve webpages corresponding to the rare word through the search engine and parse the returned results to extract a set of most related words. We average the vectors of the related words as the initial vector of the rare word. Then, the location of the rare word in the vector space is iteratively fine-tuned according to the order of its relevances to the related words. Compared to other approaches, our algorithm can learn more accurate representations for a wider range of vocabulary. We evaluate our learned rare-word embeddings on the word relatedness task, and the experimental results show that our algorithm achieves state-of-the-art performance.
Modern natural language understanding models depend on pretrained subword embeddings, but applications may need to reason about words that were never or rarely seen during pretraining. We show that examples that depend critically on a rarer word are more challenging for natural language inference models. Then we explore how a model could learn to use definitions, provided in natural text, to overcome this handicap. Our model’s understanding of a definition is usually weaker than a well-modeled word embedding, but it recovers most of the performance gap from using a completely untrained word.
We introduce a new approach for smoothing and improving the quality of word embeddings. We consider a method of fusing word embeddings that were trained on the same corpus but with different initializations. We project all the models to a shared vector space using an efficient implementation of the Generalized Procrustes Analysis (GPA) procedure, previously used in multilingual word translation. Our word representation demonstrates consistent improvements over the raw models as well as their simplistic average, on a range of tasks. As the new representations are more stable and reliable, there is a noticeable improvement in rare word evaluations.
Cross-lingual word embeddings provide a way for information to be transferred between languages. In this paper we evaluate an extension of a joint training approach to learning cross-lingual embeddings that incorporates sub-word information during training. This method could be particularly well-suited to lower-resource and morphologically-rich languages because it can be trained on modest size monolingual corpora, and is able to represent out-of-vocabulary words (OOVs). We consider bilingual lexicon induction, including an evaluation focused on OOVs. We find that this method achieves improvements over previous approaches, particularly for OOVs.
Adversarial training (AT) as a regularization method has proved its effectiveness on various tasks. Though there are successful applications of AT on some NLP tasks, the distinguishing characteristics of NLP tasks have not been exploited. In this paper, we aim to apply AT on machine reading comprehension (MRC) tasks. Furthermore, we adapt AT for MRC tasks by proposing a novel adversarial training method called PQAT that perturbs the embedding matrix instead of word vectors. To differentiate the roles of passages and questions, PQAT uses additional virtual P/Q-embedding matrices to gather the global perturbations of words from passages and questions separately. We test the method on a wide range of MRC tasks, including span-based extractive RC and multiple-choice RC. The results show that adversarial training is effective universally, and PQAT further improves the performance.
In implicit discourse relation classification, we want to predict the relation between adjacent sentences in the absence of any overt discourse connectives. This is challenging even for humans, leading to shortage of annotated data, a fact that makes the task even more difficult for supervised machine learning approaches. In the current study, we perform implicit discourse relation classification without relying on any labeled implicit relation. We sidestep the lack of data through explicitation of implicit relations to reduce the task to two sub-problems: language modeling and explicit discourse relation classification, a much easier problem. Our experimental results show that this method can even marginally outperform the state-of-the-art, in spite of being much simpler than alternative models of comparable performance. Moreover, we show that the achieved performance is robust across domains as suggested by the zero-shot experiments on a completely different domain. This indicates that recent advances in language modeling have made language models sufficiently good at capturing inter-sentence relations without the help of explicit discourse markers.
Short-answer scoring is the task of assessing the correctness of a short text given as response to a question that can come from a variety of educational scenarios. As only content, not form, is important, the exact wording including the explicitness of an answer should not matter. However, many state-of-the-art scoring models heavily rely on lexical information, be it word embeddings in a neural network or n-grams in an SVM. Thus, the exact wording of an answer might very well make a difference. We therefore quantify to what extent implicit language phenomena occur in short answer datasets and examine the influence they have on automatic scoring performance. We find that the level of implicitness depends on the individual question, and that some phenomena are very frequent. Resolving implicit wording to explicit formulations indeed tends to improve automatic scoring performance.
Data-to-text generation systems are trained on large datasets, such as WebNLG, Ro-toWire, E2E or DART. Beyond traditional token-overlap evaluation metrics (BLEU or METEOR), a key concern faced by recent generators is to control the factuality of the generated text with respect to the input data specification. We report on our experience when developing an automatic factuality evaluation system for data-to-text generation that we are testing on WebNLG and E2E data. We aim to prepare gold data annotated manually to identify cases where the text communicates more information than is warranted based on the in-put data (extra) or fails to communicate data that is part of the input (missing). While analyzing reference (data, text) samples, we encountered a range of systematic uncertainties that are related to cases on implicit phenomena in text, and the nature of non-linguistic knowledge we expect to be involved when assessing factuality. We derive from our experience a set of evaluation guidelines to reach high inter-annotator agreement on such cases.
This paper describes the data, task setup, and results of the shared task at the First Workshop on Understanding Implicit and Underspecified Language (UnImplicit). The task requires computational models to predict whether a sentence contains aspects of meaning that are contextually unspecified and thus require clarification. Two teams participated and the best scoring system achieved an accuracy of 68%.
Metaphors are ubiquitous in human language. The metaphor detection task (MD) aims at detecting and interpreting metaphors from written language, which is crucial in natural language understanding (NLU) research. In this paper, we introduce a pre-trained Transformer-based model into MD. Our model outperforms the previous state-of-the-art models by large margins in our evaluations, with relative improvements on the F-1 score from 5.33% to 28.39%. Second, we extend MD to a classification task about the metaphoricity of an entire piece of text to make MD applicable in more general NLU scenes. Finally, we clean up the improper or outdated annotations in one of the MD benchmark datasets and re-benchmark it with our Transformer-based model. This approach could be applied to other existing MD datasets as well, since the metaphoricity annotations in these benchmark datasets may be outdated. Future research efforts are also necessary to build an up-to-date and well-annotated dataset consisting of longer and more complex texts.
While aggregate performance metrics can generate valuable insights at a large scale, their dominance means more complex and nuanced language phenomena, such as vagueness, may be overlooked. Focusing on vague terms (e.g. sunny, cloudy, young, etc.) we inspect the behavior of visually grounded and text-only models, finding systematic divergences from human judgments even when a model’s overall performance is high. To help explain this disparity, we identify two assumptions made by the datasets and models examined and, guided by the philosophy of vagueness, isolate cases where they do not hold.
Exploring aspects of sentential meaning that are implicit or underspecified in context is important for sentence understanding. In this paper, we propose a novel architecture based on mentions for revision requirements detection. The goal is to improve understandability, addressing some types of revisions, especially for the Replaced Pronoun type. We show that our mention-based system can predict replaced pronouns well on the mention-level. However, our combined sentence-level system does not improve on the sentence-level BERT baseline. We also present additional contrastive systems, and show results for each type of edit.
In this report, we describe our transformers for text classification baseline (TTCB) submissions to a shared task on implicit and underspecified language 2021. We cast the task of predicting revision requirements in collaboratively edited instructions as text classification. We considered transformer-based models which are the current state-of-the-art methods for text classification. We explored different training schemes, loss functions, and data augmentations. Our best result of 68.45% test accuracy (68.84% validation accuracy), however, consists of an XLNet model with a linear annealing scheduler and a cross-entropy loss. We do not observe any significant gain on any validation metric based on our various design choices except the MiniLM which has a higher validation F1 score and is faster to train by a half but also a lower validation accuracy score.
This paper presents the results of the shared tasks from the 8th workshop on Asian translation (WAT2021). For the WAT2021, 28 teams participated in the shared tasks and 24 teams submitted their translation results for the human evaluation. We also accepted 5 research papers. About 2,100 translation results were submitted to the automatic evaluation server, and selected submissions were manually evaluated.
This paper describes the system of our team (NHK) for the WAT 2021 Japanese-English restricted machine translation task. In this task, the aim is to improve quality while maintaining consistent terminology for scientific paper translation. This task has a unique feature, where some words in a target sentence are given in addition to a source sentence. In this paper, we use a lexically-constrained neural machine translation (NMT), which concatenates the source sentence and constrained words with a special token to input them into the encoder of NMT. The key to the successful lexically-constrained NMT is the way to extract constraints from a target sentence of training data. We propose two extraction methods: proper-noun constraint and mistranslated-word constraint. These two methods consider the importance of words and fallibility of NMT, respectively. The evaluation results demonstrate the effectiveness of our lexical-constraint method.
This paper describes our systems that were submitted to the restricted translation task at WAT 2021. In this task, the systems are required to output translated sentences that contain all given word constraints. Our system combined input augmentation and constrained beam search algorithms. Through experiments, we found that this combination significantly improves translation accuracy and can save inference time while containing all the constraints in the output. For both En->Ja and Ja->En, our systems obtained the best evaluation performances in automatic and human evaluation.
This paper describes our system (Team ID: nictrb) for participating in the WAT’21 restricted machine translation task. In our submitted system, we designed a new training approach for restricted machine translation. By sampling from the translation target, we can solve the problem that ordinary training data does not have a restricted vocabulary. With the further help of constrained decoding in the inference phase, we achieved better results than the baseline, confirming the effectiveness of our solution. In addition, we also tried the vanilla and sparse Transformer as the backbone network of the model, as well as model ensembling, which further improved the final translation performance.
We introduce our TMU Japanese-to-English system, which employs a semi-autoregressive model, to tackle the WAT 2021 restricted translation task. In this task, we translate an input sentence with the constraint that some words, called restricted target vocabularies (RTVs), must be contained in the output sentence. To satisfy this constraint, we use a semi-autoregressive model, namely, RecoverSAT, due to its ability (known as “forced translation”) to insert specified words into the output sentence. When using “forced translation,” the order of inserting RTVs is a critical problem. In this work, we aligned the source sentence and the corresponding RTVs using GIZA++. In our system, we obtain word alignment between a source sentence and the corresponding RTVs and then sort the RTVs in the order of their corresponding words or phrases in the source sentence. Using the model with sorted order RTVs, we succeeded in inserting all the RTVs into output sentences in more than 96% of the test sentences. Moreover, we confirmed that sorting RTVs improved the BLEU score compared with random order RTVs.
In this paper, we report the experimental results of Machine Translation models conducted by a NECTEC team for the translation tasks of WAT-2021. Basically, our models are based on neural methods for both directions of English-Myanmar and Myanmar-English language pairs. Most of the existing Neural Machine Translation (NMT) models mainly focus on the conversion of sequential data and do not directly use syntactic information. However, we conduct multi-source neural machine translation (NMT) models using the multilingual corpora such as string data corpus, tree data corpus, or POS-tagged data corpus. The multi-source translation is an approach to exploit multiple inputs (e.g. in two different formats) to increase translation accuracy. The RNN-based encoder-decoder model with attention mechanism and transformer architectures have been carried out for our experiment. The experimental results showed that the proposed models of RNN-based architecture outperform the baseline model for English-to-Myanmar translation task, and the multi-source and shared-multi-source transformer models yield better translation results than the baseline.
In this paper we describe our submissions to WAT-2021 (Nakazawa et al., 2021) for English-to-Myanmar language (Burmese) task. Our team, ID: “YCC-MT1”, focused on bringing transliteration knowledge to the decoder without changing the model. We manually extracted the transliteration word/phrase pairs from the ALT corpus and applying XML markup feature of Moses decoder (i.e. -xml-input exclusive, -xml-input inclusive). We demonstrate that hybrid translation technique can significantly improve (around 6 BLEU scores) the baseline of three well-known “Phrase-based SMT”, “Operation Sequence Model” and “Hierarchical Phrase-based SMT”. Moreover, this simple hybrid method achieved the second highest results among the submitted MT systems for English-to-Myanmar WAT2021 translation share task according to BLEU (Papineni et al., 2002) and AMFM scores (Banchs et al., 2015).
In this paper, we present the NICT system (NICT-2) submitted to the NICT-SAP shared task at the 8th Workshop on Asian Translation (WAT-2021). A feature of our system is that we used a pretrained multilingual BART (Bidirectional and Auto-Regressive Transformer; mBART) model. Because publicly available models do not support some languages in the NICT-SAP task, we added these languages to the mBART model and then trained it using monolingual corpora extracted from Wikipedia. We fine-tuned the expanded mBART model using the parallel corpora specified by the NICT-SAP task. The BLEU scores greatly improved in comparison with those of systems without the pretrained model, including the additional languages.
This paper introduces our neural machine translation systems’ participation in the WAT 2021 shared translation tasks (team ID: sakura). We participated in the (i) NICT-SAP, (ii) Japanese-English multimodal translation, (iii) Multilingual Indic, and (iv) Myanmar-English translation tasks. Multilingual approaches such as mBART (Liu et al., 2020) are capable of pre-training a complete, multilingual sequence-to-sequence model through denoising objectives, making it a great starting point for building multilingual translation systems. Our main focus in this work is to investigate the effectiveness of multilingual finetuning on such a multilingual language model on various translation tasks, including low-resource, multimodal, and mixed-domain translation. We further explore a multimodal approach based on universal visual representation (Zhang et al., 2019) and compare its performance against a unimodal approach based on mBART alone.
With the growing popularity of smart speakers, such as Amazon Alexa, speech is becoming one of the most important modes of human-computer interaction. Automatic speech recognition (ASR) is arguably the most critical component of such systems, as errors in speech recognition propagate to the downstream components and drastically degrade the user experience. A simple and effective way to improve the speech recognition accuracy is to apply automatic post-processor to the recognition result. However, training a post-processor requires parallel corpora created by human annotators, which are expensive and not scalable. To alleviate this problem, we propose Back TranScription (BTS), a denoising-based method that can create such corpora without human labor. Using a raw corpus, BTS corrupts the text using Text-to-Speech (TTS) and Speech-to-Text (STT) systems. Then, a post-processing model can be trained to reconstruct the original text given the corrupted input. Quantitative and qualitative evaluations show that a post-processor trained using our approach is highly effective in fixing non-trivial speech recognition errors such as mishandling foreign words. We present the generated parallel corpus and post-processing platform to make our results publicly available.
For Japanese-to-English translation, zero pronouns in Japanese pose a challenge, since the model needs to infer and produce the corresponding pronoun in the target side of the English sentence. However, although fully resolving zero pronouns often needs discourse context, in some cases, the local context within a sentence gives clues to the inference of the zero pronoun. In this study, we propose a data augmentation method that provides additional training signals for the translation model to learn correlations between local context and zero pronouns. We show that the proposed method significantly improves the accuracy of zero pronoun translation with machine translation experiments in the conversational domain.
For updating the translations of Japanese statutes based on their amendments, we need to consider the translation “focality;” that is, we should only modify expressions that are relevant to the amendment and retain the others to avoid misconstruing its contents. In this paper, we introduce an evaluation metric and a corpus to improve focality evaluations. Our metric is called an Inclusive Score for DIfferential Translation: (ISDIT). ISDIT consists of two factors: (1) the n-gram recall of expressions unaffected by the amendment and (2) the n-gram precision of the output compared to the reference. This metric supersedes an existing one for focality by simultaneously calculating the translation quality of the changed expressions in addition to that of the unchanged expressions. We also newly compile a corpus for Japanese partially amendment translation that secures the focality of the post-amendment translations, while an existing evaluation corpus does not. With the metric and the corpus, we examine the performance of existing translation methods for Japanese partially amendment translations.
In this paper, we introduce our TMU Neural Machine Translation (NMT) system submitted for the Patent task (Korean Japanese and English Japanese) of 8th Workshop on Asian Translation (Nakazawa et al., 2021). Recently, several studies proposed pre-trained encoder-decoder models using monolingual data. One of the pre-trained models, BART (Lewis et al., 2020), was shown to improve translation accuracy via fine-tuning with bilingual data. However, they experimented only Romanian!English translation using English BART. In this paper, we examine the effectiveness of Japanese BART using Japan Patent Office Corpus 2.0. Our experiments indicate that Japanese BART can also improve translation accuracy in both Korean Japanese and English Japanese translations.
In this paper, we describe our participation in the 2021 Workshop on Asian Translation (team ID: tpt_wat). We submitted results for all six directions of the JPC2 patent task. As a first-time participant in the task, we attempted to identify a single configuration that provided the best overall results across all language pairs. All our submissions were created using single base transformer models, trained on only the task-specific data, using a consistent configuration of hyperparameters. In contrast to the uniformity of our methods, our results vary widely across the six language pairs.
This paper presents the Bering Lab’s submission to the shared tasks of the 8th Workshop on Asian Translation (WAT 2021) on JPC2 and NICT-SAP. We participated in all tasks on JPC2 and IT domain tasks on NICT-SAP. Our approach for all tasks mainly focused on building NMT systems in domain-specific corpora. We crawled patent document pairs for English-Japanese, Chinese-Japanese, and Korean-Japanese. After cleaning noisy data, we built parallel corpus by aligning those sentences with the sentence-level similarity scores. Also, for SAP test data, we collected the OPUS dataset including three IT domain corpora. We then trained transformer on the collected dataset. Our submission ranked 1st in eight out of fourteen tasks, achieving up to an improvement of 2.87 for JPC2 and 8.79 for NICT-SAP in BLEU score .
This paper provides the description of shared tasks to the WAT 2021 by our team “NLPHut”. We have participated in the English→Hindi Multimodal translation task, English→Malayalam Multimodal translation task, and Indic Multi-lingual translation task. We have used the state-of-the-art Transformer model with language tags in different settings for the translation task and proposed a novel “region-specific” caption generation approach using a combination of image CNN and LSTM for the Hindi and Malayalam image captioning. Our submission tops in English→Malayalam Multimodal translation task (text-only translation, and Malayalam caption), and ranks second-best in English→Hindi Multimodal translation task (text-only translation, and Hindi caption). Our submissions have also performed well in the Indic Multilingual translation tasks.
Machine translation performs automatic translation from one natural language to another. Neural machine translation attains a state-of-the-art approach in machine translation, but it requires adequate training data, which is a severe problem for low-resource language pairs translation. The concept of multimodal is introduced in neural machine translation (NMT) by merging textual features with visual features to improve low-resource pair translation. WAT2021 (Workshop on Asian Translation 2021) organizes a shared task of multimodal translation for English to Hindi. We have participated the same with team name CNLP-NITS-PP in two submissions: multimodal and text-only NMT. This work investigates phrase pairs injection via data augmentation approach and attains improvement over our previous work at WAT2020 on the same task in both text-only and multimodal NMT. We have achieved second rank on the challenge test set for English to Hindi multimodal translation where Bilingual Evaluation Understudy (BLEU) score of 39.28, Rank-based Intuitive Bilingual Evaluation Score (RIBES) 0.792097, and Adequacy-Fluency Metrics (AMFM) score 0.830230 respectively.
Neural Machine Translation (NMT) is a predominant machine translation technology nowadays because of its end-to-end trainable flexibility. However, NMT still struggles to translate properly in low-resource settings specifically on distant language pairs. One way to overcome this is to use the information from other modalities if available. The idea is that despite differences in languages, both the source and target language speakers see the same thing and the visual representation of both the source and target is the same, which can positively assist the system. Multimodal information can help the NMT system to improve the translation by removing ambiguity on some phrases or words. We participate in the 8th Workshop on Asian Translation (WAT - 2021) for English-Hindi multimodal translation task and achieve 42.47 and 37.50 BLEU points for Evaluation and Challenge subset, respectively.
Multimodal Machine Translation (MMT) enriches the source text with visual information for translation. It has gained popularity in recent years, and several pipelines have been proposed in the same direction. Yet, the task lacks quality datasets to illustrate the contribution of visual modality in the translation systems. In this paper, we propose our system under the team name Volta for the Multimodal Translation Task of WAT 2021 from English to Hindi. We also participate in the textual-only subtask of the same language pair for which we use mBART, a pretrained multilingual sequence-to-sequence model. For multimodal translation, we propose to enhance the textual input by bringing the visual information to a textual domain by extracting object tags from the image. We also explore the robustness of our system by systematically degrading the source text. Finally, we achieve a BLEU score of 44.6 and 51.6 on the test set and challenge set of the multimodal task.
We introduce our TMEKU system submitted to the English-Japanese Multimodal Translation Task for WAT 2021. We participated in the Flickr30kEnt-JP task and Ambiguous MSCOCO Multimodal task under the constrained condition using only the officially provided datasets. Our proposed system employs soft alignment of word-region for multimodal neural machine translation (MNMT). The experimental results evaluated on the BLEU metric provided by the WAT 2021 evaluation site show that the TMEKU system has achieved the best performance among all the participated systems. Further analysis of the case study demonstrates that leveraging word-region alignment between the textual and visual modalities is the key to performance enhancement in our TMEKU system, which leads to better visual information use.
Dravidian languages, such as Kannada and Tamil, are notoriously difficult to translate by state-of-the-art neural models. This stems from the fact that these languages are morphologically very rich as well as being low-resourced. In this paper, we focus on subword segmentation and evaluate Linguistically Motivated Vocabulary Reduction (LMVR) against the more commonly used SentencePiece (SP) for the task of translating from English into four different Dravidian languages. Additionally we investigate the optimal subword vocabulary size for each language. We find that SP is the overall best choice for segmentation, and that larger dictionary sizes lead to higher translation quality.
This work introduces Itihasa, a large-scale translation dataset containing 93,000 pairs of Sanskrit shlokas and their English translations. The shlokas are extracted from two Indian epics viz., The Ramayana and The Mahabharata. We first describe the motivation behind the curation of such a dataset and follow up with empirical analysis to bring out its nuances. We then benchmark the performance of standard translation models on this corpus and show that even state-of-the-art transformer architectures perform poorly, emphasizing the complexity of the dataset.
In this paper we describe our submission to the multilingual Indic language translation wtask “MultiIndicMT” under the team name “NICT-5”. This task involves translation from 10 Indic languages into English and vice-versa. The objective of the task was to explore the utility of multilingual approaches using a variety of in-domain and out-of-domain parallel and monolingual corpora. Given the recent success of multilingual NMT pre-training we decided to explore pre-training an MBART model on a large monolingual corpus collection covering all languages in this task followed by multilingual fine-tuning on small in-domain corpora. Firstly, we observed that a small amount of pre-training followed by fine-tuning on small bilingual corpora can yield large gains over when pre-training is not used. Furthermore, multilingual fine-tuning leads to further gains in translation quality which significantly outperforms a very strong multilingual baseline that does not rely on any pre-training.
This work shows that competitive translation results can be obtained in a constrained setting by incorporating the latest advances in memory and compute optimization. We train and evaluate large multilingual translation models using a single GPU for a maximum of 100 hours and get within 4-5 BLEU points of the top submission on the leaderboard. We also benchmark standard baselines on the PMI corpus and re-discover well-known shortcomings of translation systems and metrics.
This paper describes the work and the systems submitted by the IIIT-Hyderbad team in the WAT 2021 MultiIndicMT shared task. The task covers 10 major languages of the Indian subcontinent. For the scope of this task, we have built multilingual systems for 20 translation directions namely English-Indic (one-to- many) and Indic-English (many-to-one). Individually, Indian languages are resource poor which hampers translation quality but by leveraging multilingualism and abundant monolingual corpora, the translation quality can be substantially boosted. But the multilingual systems are highly complex in terms of time as well as computational resources. Therefore, we are training our systems by efficiently se- lecting data that will actually contribute to most of the learning process. Furthermore, we are also exploiting the language related- ness found in between Indian languages. All the comparisons were made using BLEU score and we found that our final multilingual sys- tem significantly outperforms the baselines by an average of 11.3 and 19.6 BLEU points for English-Indic (en-xx) and Indic-English (xx- en) directions, respectively.
Multilingual Neural Machine Translation has achieved remarkable performance by training a single translation model for multiple languages. This paper describes our submission (Team ID: CFILT-IITB) for the MultiIndicMT: An Indic Language Multilingual Task at WAT 2021. We train multilingual NMT systems by sharing encoder and decoder parameters with language embedding associated with each token in both encoder and decoder. Furthermore, we demonstrate the use of transliteration (script conversion) for Indic languages in reducing the lexical gap for training a multilingual NMT system. Further, we show improvement in performance by training a multilingual NMT system using languages of the same family, i.e., related languages.
This paper describes the submission to the WAT 2021 Indic Language Multilingual Task by Samsung R&D Institute Poland. The task covered translation between 10 Indic Languages (Bengali, Gujarati, Hindi, Kannada, Malayalam, Marathi, Oriya, Punjabi, Tamil and Telugu) and English. We combined a variety of techniques: transliteration, filtering, backtranslation, domain adaptation, knowledge-distillation and finally ensembling of NMT models. We applied an effective approach to low-resource training that consist of pretraining on backtranslations and tuning on parallel corpora. We experimented with two different domain-adaptation techniques which significantly improved translation quality when applied to monolingual corpora. We researched and applied a novel approach for finding the best hyperparameters for ensembling a number of translation models. All techniques combined gave significant improvement - up to +8 BLEU over baseline results. The quality of the models has been confirmed by the human evaluation where SRPOL models scored best for all 5 manually evaluated languages.
In this paper, we present the details of the systems that we have submitted for the WAT 2021 MultiIndicMT: An Indic Language Multilingual Task. We have submitted two separate multilingual NMT models: one for English to 10 Indic languages and another for 10 Indic languages to English. We discuss the implementation details of two separate multilingual NMT approaches, namely one-to-many and many-to-one, that makes use of a shared decoder and a shared encoder, respectively. From our experiments, we observe that the multilingual NMT systems outperforms the bilingual baseline MT systems for each of the language pairs under consideration.
This paper describes the systems submitted to WAT 2021 MultiIndicMT shared task by IITP-MT team. We submit two multilingual Neural Machine Translation (NMT) systems (Indic-to-English and English-to-Indic). We romanize all Indic data and create subword vocabulary which is shared between all Indic languages. We use back-translation approach to generate synthetic data which is appended to parallel corpus and used to train our models. The models are evaluated using BLEU, RIBES and AMFM scores with Indic-to-English model achieving 40.08 BLEU for Hindi-English pair and English-to-Indic model achieving 34.48 BLEU for English-Hindi pair. However, we observe that the shared romanized subword vocabulary is not helping English-to-Indic model at the time of generation, leading it to produce poor quality translations for Tamil, Telugu and Malayalam to English pairs with BLEU score of 8.51, 6.25 and 3.79 respectively.
This paper describes ANVITA-1.0 MT system, architected for submission to WAT2021 MultiIndicMT shared task by mcairt team, where the team participated in 20 translation directions: English→Indic and Indic→English; Indic set comprised of 10 Indian languages. ANVITA-1.0 MT system comprised of two multi-lingual NMT models one for the English→Indic directions and other for the Indic→English directions with shared encoder-decoder, catering 10 language pairs and twenty translation directions. The base models were built based on Transformer architecture and trained over MultiIndicMT WAT 2021 corpora and further employed back translation and transliteration for selective data augmentation, and model ensemble for better generalization. Additionally, MultiIndicMT WAT 2021 corpora was distilled using a series of filtering operations before putting up for training. ANVITA-1.0 achieved highest AM-FM score for English→Bengali, 2nd for English→Tamil and 3rd for English→Hindi, Bengali→English directions on official test set. In general, performance achieved by ANVITA for the Indic→English directions are relatively better than that of English→Indic directions for all the 10 language pairs when evaluated using BLEU and RIBES, although the same trend is not observed consistently when AM-FM based evaluation was carried out. As compared to BLEU, RIBES and AM-FM based scoring placed ANVITA relatively better among all the task participants.
Offensive language detection (OLD) has received increasing attention due to its societal impact. Recent work shows that bidirectional transformer based methods obtain impressive performance on OLD. However, such methods usually rely on large-scale well-labeled OLD datasets for model training. To address the issue of data/label scarcity in OLD, in this paper, we propose a simple yet effective domain adaptation approach to train bidirectional transformers. Our approach introduces domain adaptation (DA) training procedures to ALBERT, such that it can effectively exploit auxiliary data from source domains to improve the OLD performance in a target domain. Experimental results on benchmark datasets show that our approach, ALBERT (DA), obtains the state-of-the-art performance in most cases. Particularly, our approach significantly benefits underrepresented and under-performing classes, with a significant improvement over ALBERT.
Hate speech and profanity detection suffer from data sparsity, especially for languages other than English, due to the subjective nature of the tasks and the resulting annotation incompatibility of existing corpora. In this study, we identify profane subspaces in word and sentence representations and explore their generalization capability on a variety of similar and distant target tasks in a zero-shot setting. This is done monolingually (German) and cross-lingually to closely-related (English), distantly-related (French) and non-related (Arabic) tasks. We observe that, on both similar and distant target tasks and across all languages, the subspace-based representations transfer more effectively than standard BERT representations in the zero-shot setting, with improvements between F1 +10.9 and F1 +42.9 over the baselines across all tested monolingual and cross-lingual scenarios.
We introduce HateBERT, a re-trained BERT model for abusive language detection in English. The model was trained on RAL-E, a large-scale dataset of Reddit comments in English from communities banned for being offensive, abusive, or hateful that we have curated and made available to the public. We present the results of a detailed comparison between a general pre-trained language model and the retrained version on three English datasets for offensive, abusive language and hate speech detection tasks. In all datasets, HateBERT outperforms the corresponding general BERT model. We also discuss a battery of experiments comparing the portability of the fine-tuned models across the datasets, suggesting that portability is affected by compatibility of the annotated phenomena.
Hateful memes pose a unique challenge for current machine learning systems because their message is derived from both text- and visual-modalities. To this effect, Facebook released the Hateful Memes Challenge, a dataset of memes with pre-extracted text captions, but it is unclear whether these synthetic examples generalize to ‘memes in the wild’. In this paper, we collect hateful and non-hateful memes from Pinterest to evaluate out-of-sample performance on models pre-trained on the Facebook dataset. We find that ‘memes in the wild’ differ in two key aspects: 1) Captions must be extracted via OCR, injecting noise and diminishing performance of multimodal models, and 2) Memes are more diverse than ‘traditional memes’, including screenshots of conversations or text on a plain background. This paper thus serves as a reality-check for the current benchmark of hateful meme detection and its applicability for detecting real world hate.
Content moderation is often performed by a collaboration between humans and machine learning models. However, it is not well understood how to design the collaborative process so as to maximize the combined moderator-model system performance. This work presents a rigorous study of this problem, focusing on an approach that incorporates model uncertainty into the collaborative process. First, we introduce principled metrics to describe the performance of the collaborative system under capacity constraints on the human moderator, quantifying how efficiently the combined system utilizes human decisions. Using these metrics, we conduct a large benchmark study evaluating the performance of state-of-the-art uncertainty models under different collaborative review strategies. We find that an uncertainty-based strategy consistently outperforms the widely used strategy based on toxicity scores, and moreover that the choice of review strategy drastically changes the overall system performance. Our results demonstrate the importance of rigorous metrics for understanding and developing effective moderator-model systems for content moderation, as well as the utility of uncertainty estimation in this domain.
As socially unacceptable language become pervasive in social media platforms, the need for automatic content moderation become more pressing. This contribution introduces the Dutch Abusive Language Corpus (DALC v1.0), a new dataset with tweets manually an- notated for abusive language. The resource ad- dress a gap in language resources for Dutch and adopts a multi-layer annotation scheme modeling the explicitness and the target of the abusive messages. Baselines experiments on all annotation layers have been conducted, achieving a macro F1 score of 0.748 for binary classification of the explicitness layer and .489 for target classification.
Social media texts such as blog posts, comments, and tweets often contain offensive languages including racial hate speech comments, personal attacks, and sexual harassment. Detecting inappropriate use of language is, therefore, of utmost importance for the safety of the users as well as for suppressing hateful conduct and aggression. Existing approaches to this problem are mostly available for resource-rich languages such as English and German. In this paper, we characterize the offensive language in Nepali, a low-resource language, highlighting the challenges that need to be addressed for processing Nepali social media text. We also present experiments for detecting offensive language using supervised machine learning. Besides contributing the first baseline approaches of detecting offensive language in Nepali, we also release human annotated data sets to encourage future research on this crucial topic.
Hate speech-related lexicons have been proved to be useful for many tasks such as data collection and classification. However, existing Portuguese lexicons do not distinguish between European and Brazilian Portuguese, and do not include neutral terms that are potentially useful to detect a broader spectrum of content referring to minorities. In this work, we present MIN_PT, a new European Portuguese Lexicon for Minorities-Related Terms specifically designed to tackle the limitations of existing resources. We describe the data collection and annotation process, discuss the limitation and ethical concerns, and prove the utility of the resource by applying it to a use case for the Portuguese 2021 presidential elections.
Current abusive language detection systems have demonstrated unintended bias towards sensitive features such as nationality or gender. This is a crucial issue, which may harm minorities and underrepresented groups if such systems were integrated in real-world applications. In this paper, we create ad hoc tests through the CheckList tool (Ribeiro et al., 2020) to detect biases within abusive language classifiers for English. We compare the behaviour of two BERT-based models, one trained on a generic hate speech dataset and the other on a dataset for misogyny detection. Our evaluation shows that, although BERT-based classifiers achieve high accuracy levels on a variety of natural language processing tasks, they perform very poorly as regards fairness and bias, in particular on samples involving implicit stereotypes, expressions of hate towards minorities and protected attributes such as race or sexual orientation. We release both the notebooks implemented to extend the Fairness tests and the synthetic datasets usable to evaluate systems bias independently of CheckList.
Bias mitigation approaches reduce models’ dependence on sensitive features of data, such as social group tokens (SGTs), resulting in equal predictions across the sensitive features. In hate speech detection, however, equalizing model predictions may ignore important differences among targeted social groups, as hate speech can contain stereotypical language specific to each SGT. Here, to take the specific language about each SGT into account, we rely on counterfactual fairness and equalize predictions among counterfactuals, generated by changing the SGTs. Our method evaluates the similarity in sentence likelihoods (via pre-trained language models) among counterfactuals, to treat SGTs equally only within interchangeable contexts. By applying logit pairing to equalize outcomes on the restricted set of counterfactuals for each instance, we improve fairness metrics while preserving model performance on hate speech detection.
There have been several attempts to create an accurate and thorough emotion lexicon in English, which identifies the emotional content of words. Of the several commonly used resources, the NRC emotion lexicon (Mohammad and Turney, 2013b) has received the most attention due to its availability, size, and its choice of Plutchik’s expressive 8-class emotion model. In this paper we identify a large number of troubling entries in the NRC lexicon, where words that should in most contexts be emotionally neutral, with no affect (e.g., ‘lesbian’, ‘stone’, ‘mountain’), are associated with emotional labels that are inaccurate, nonsensical, pejorative, or, at best, highly contingent and context-dependent (e.g., ‘lesbian’ labeled as Disgust and Sadness, ‘stone’ as Anger, or ‘mountain’ as Anticipation). We describe a procedure for semi-automatically correcting these problems in the NRC, which includes disambiguating POS categories and aligning NRC entries with other emotion lexicons to infer the accuracy of labels. We demonstrate via an experimental benchmark that the quality of the resources is thus improved. We release the revised resource and our code to enable other researchers to reproduce and build upon results.
Automatic detection of toxic language plays an essential role in protecting social media users, especially minority groups, from verbal abuse. However, biases toward some attributes, including gender, race, and dialect, exist in most training datasets for toxicity detection. The biases make the learned models unfair and can even exacerbate the marginalization of people. Considering that current debiasing methods for general natural language understanding tasks cannot effectively mitigate the biases in the toxicity detectors, we propose to use invariant rationalization (InvRat), a game-theoretic framework consisting of a rationale generator and a predictor, to rule out the spurious correlation of certain syntactic patterns (e.g., identity mentions, dialect) to toxicity labels. We empirically show that our method yields lower false positive rate in both lexical and dialectal attributes than previous debiasing methods.
We present a data set consisting of German news articles labeled for political bias on a five-point scale in a semi-supervised way. While earlier work on hyperpartisan news detection uses binary classification (i.e., hyperpartisan or not) and English data, we argue for a more fine-grained classification, covering the full political spectrum (i.e., far-left, left, centre, right, far-right) and for extending research to German data. Understanding political bias helps in accurately detecting hate speech and online abuse. We experiment with different classification methods for political bias detection. Their comparatively low performance (a macro-F1 of 43 for our best setup, compared to a macro-F1 of 79 for the binary classification task) underlines the need for more (balanced) data annotated in a fine-grained way.
Online abuse and offensive language on social media have become widespread problems in today’s digital age. In this paper, we contribute a Reddit-based dataset, consisting of 68,159 insults and 51,102 compliments targeted at individuals instead of targeting a particular community or race. Secondly, we benchmark multiple existing state-of-the-art models for both classification and unsupervised style transfer on the dataset. Finally, we analyse the experimental results and conclude that the transfer task is challenging, requiring the models to understand the high degree of creativity exhibited in the data.
User posts whose perceived toxicity depends on the conversational context are rare in current toxicity detection datasets. Hence, toxicity detectors trained on current datasets will also disregard context, making the detection of context-sensitive toxicity a lot harder when it occurs. We constructed and publicly release a dataset of 10k posts with two kinds of toxicity labels per post, obtained from annotators who considered (i) both the current post and the previous one as context, or (ii) only the current post. We introduce a new task, context-sensitivity estimation, which aims to identify posts whose perceived toxicity changes if the context (previous post) is also considered. Using the new dataset, we show that systems can be developed for this task. Such systems could be used to enhance toxicity detection datasets with more context-dependent posts or to suggest when moderators should consider the parent posts, which may not always be necessary and may introduce additional costs.
In this paper, we introduce a new English Twitter-based dataset for cyberbullying detection and online abuse. Comprising 62,587 tweets, this dataset was sourced from Twitter using specific query terms designed to retrieve tweets with high probabilities of various forms of bullying and offensive content, including insult, trolling, profanity, sarcasm, threat, porn and exclusion. We recruited a pool of 17 annotators to perform fine-grained annotation on the dataset with each tweet annotated by three annotators. All our annotators are high school educated and frequent users of social media. Inter-rater agreement for the dataset as measured by Krippendorff’s Alpha is 0.67. Analysis performed on the dataset confirmed common cyberbullying themes reported by other studies and revealed interesting relationships between the classes. The dataset was used to train a number of transformer-based deep learning models returning impressive results.
With the rise of research on toxic comment classification, more and more annotated datasets have been released. The wide variety of the task (different languages, different labeling processes and schemes) has led to a large amount of heterogeneous datasets that can be used for training and testing very specific settings. Despite recent efforts to create web pages that provide an overview, most publications still use only a single dataset. They are not stored in one central database, they come in many different data formats and it is difficult to interpret their class labels and how to reuse these labels in other projects. To overcome these issues, we present a collection of more than thirty datasets in the form of a software tool that automatizes downloading and processing of the data and presents them in a unified data format that also offers a mapping of compatible class labels. Another advantage of that tool is that it gives an overview of properties of available datasets, such as different languages, platforms, and class labels to make it easier to select suitable training and test data.
Community-level bans are a common tool against groups that enable online harassment and harmful speech. Unfortunately, the efficacy of community bans has only been partially studied and with mixed results. Here, we provide a flexible unsupervised methodology to identify in-group language and track user activity on Reddit both before and after the ban of a community (subreddit). We use a simple word frequency divergence to identify uncommon words overrepresented in a given community, not as a proxy for harmful speech but as a linguistic signature of the community. We apply our method to 15 banned subreddits, and find that community response is heterogeneous between subreddits and between users of a subreddit. Top users were more likely to become less active overall, while random users often reduced use of in-group language without decreasing activity. Finally, we find some evidence that the effectiveness of bans aligns with the content of a community. Users of dark humor communities were largely unaffected by bans while users of communities organized around white supremacy and fascism were the most affected. Altogether, our results show that bans do not affect all groups or users equally, and pave the way to understanding the effect of bans across communities.
Mainstream research on hate speech focused so far predominantly on the task of classifying mainly social media posts with respect to predefined typologies of rather coarse-grained hate speech categories. This may be sufficient if the goal is to detect and delete abusive language posts. However, removal is not always possible due to the legislation of a country. Also, there is evidence that hate speech cannot be successfully combated by merely removing hate speech posts; they should be countered by education and counter-narratives. For this purpose, we need to identify (i) who is the target in a given hate speech post, and (ii) what aspects (or characteristics) of the target are attributed to the target in the post. As the first approximation, we propose to adapt a generic state-of-the-art concept extraction model to the hate speech domain. The outcome of the experiments is promising and can serve as inspiration for further work on the task
Abusive language is a growing phenomenon on social media platforms. Its effects can reach beyond the online context, contributing to mental or emotional stress on users. Automatic tools for detecting abuse can alleviate the issue. In practice, developing automated methods to detect abusive language relies on good quality data. However, there is currently a lack of standards for creating datasets in the field. These standards include definitions of what is considered abusive language, annotation guidelines and reporting on the process. This paper introduces an annotation framework inspired by legal concepts to define abusive language in the context of online harassment. The framework uses a 7-point Likert scale for labelling instead of class labels. We also present ALYT – a dataset of Abusive Language on YouTube. ALYT includes YouTube comments in English extracted from videos on different controversial topics and labelled by Law students. The comments were sampled from the actual collected data, without artificial methods for increasing the abusive content. The paper describes the annotation process thoroughly, including all its guidelines and training steps.
We present the results and main findings of the shared task at WOAH 5 on hateful memes detection. The task include two subtasks relating to distinct challenges in the fine-grained detection of hateful memes: (1) the protected category attacked by the meme and (2) the attack type. 3 teams submitted system description papers. This shared task builds on the hateful memes detection task created by Facebook AI Research in 2020.
This paper describes our submission (winning solution for Task A) to the Shared Task on Hateful Meme Detection at WOAH 2021. We build our system on top of a state-of-the-art system for binary hateful meme classification that already uses image tags such as race, gender, and web entities. We add further metadata such as emotions and experiment with data augmentation techniques, as hateful instances are underrepresented in the data set.
Memes are the combinations of text and images that are often humorous in nature. But, that may not always be the case, and certain combinations of texts and images may depict hate, referred to as hateful memes. This work presents a multimodal pipeline that takes both visual and textual features from memes into account to (1) identify the protected category (e.g. race, sex etc.) that has been attacked; and (2) detect the type of attack (e.g. contempt, slurs etc.). Our pipeline uses state-of-the-art pre-trained visual and textual representations, followed by a simple logistic regression classifier. We employ our pipeline on the Hateful Memes Challenge dataset with additional newly created fine-grained labels for protected category and type of attack. Our best model achieves an AUROC of 0.96 for identifying the protected category, and 0.97 for detecting the type of attack. We release our code at https://github.com/harisbinzia/HatefulMemes
The Shared Task on Hateful Memes is a challenge that aims at the detection of hateful content in memes by inviting the implementation of systems that understand memes, potentially by combining image and textual information. The challenge consists of three detection tasks: hate, protected category and attack type. The first is a binary classification task, while the other two are multi-label classification tasks. Our participation included a text-based BERT baseline (TxtBERT), the same but adding information from the image (ImgBERT), and neural retrieval approaches. We also experimented with retrieval augmented classification models. We found that an ensemble of TxtBERT and ImgBERT achieves the best performance in terms of ROC AUC score in two out of the three tasks on our development set.
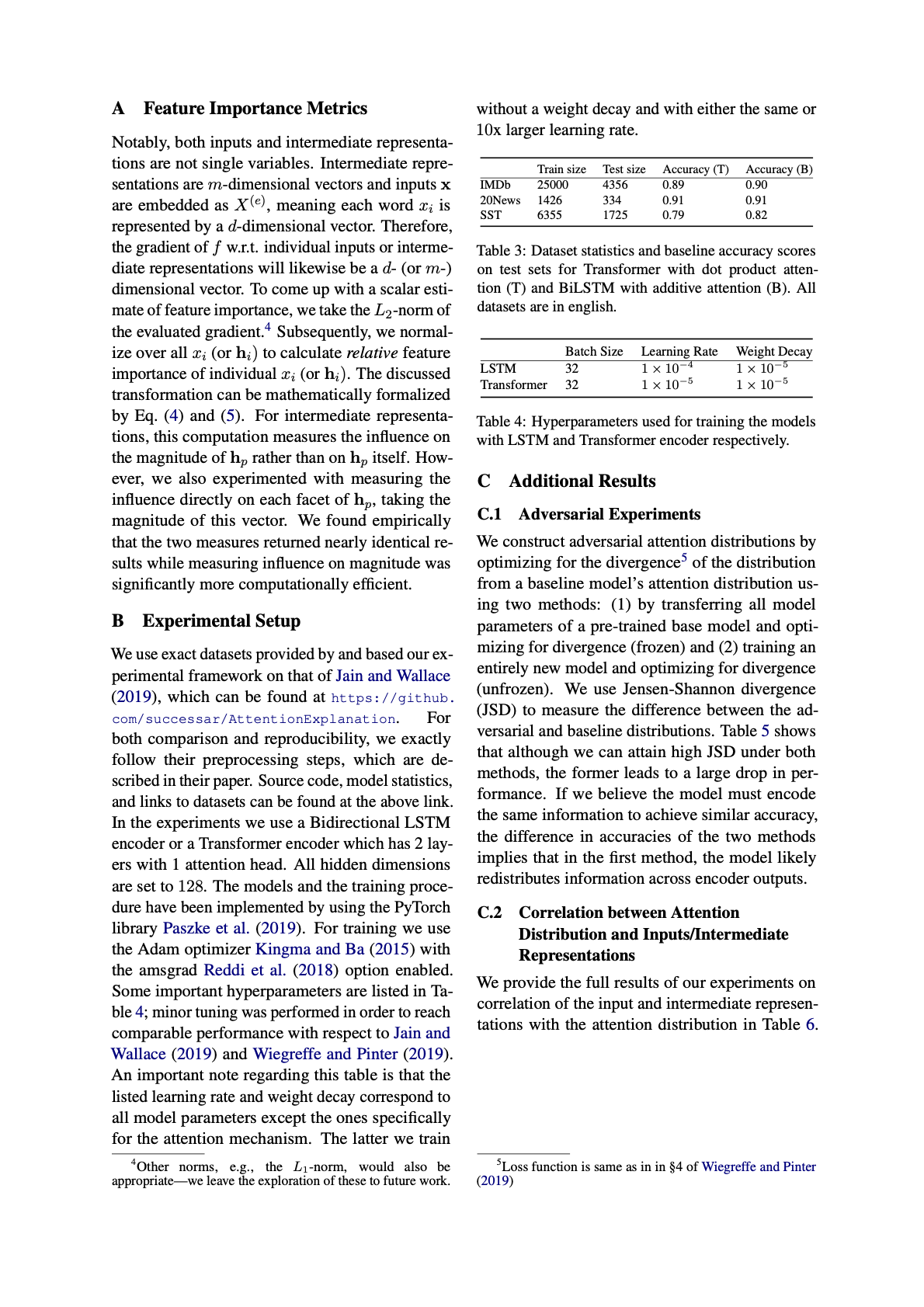{kind=link}