This is an internal, incomplete preview of a proposed change to the ACL Anthology.
For efficiency reasons, we generate only three BibTeX files per volume, and the preview may be incomplete in other ways, or contain mistakes.
Do not treat this content as an official publication.
A snowclone is a customizable phrasal template that can be realized in multiple, instantly recognized variants. For example, “* is the new *" (Orange is the new black, 40 is the new 30). Snowclones are extensively used in social media. In this paper, we study snowclones originating from pop-culture quotes; our goal is to automatically detect cultural references in text. We introduce a new, publicly available data set of pop-culture quotes and their corresponding snowclone usages and train models on them. We publish code for Catchphrase, an internet browser plugin to automatically detect and mark references in real-time, and examine its performance via a user study. Aside from assisting people to better comprehend cultural references, we hope that detecting snowclones can complement work on paraphrasing and help tackling long-standing questions in social science about the dynamics of information propagation.
Large-scale pretrained language models have led to dramatic improvements in text generation. Impressive performance can be achieved by finetuning only on a small number of instances (few-shot setting). Nonetheless, almost all previous work simply applies random sampling to select the few-shot training instances. Little to no attention has been paid to the selection strategies and how they would affect model performance. In this work, we present a study on training instance selection in few-shot neural text generation. The selection decision is made based only on the unlabeled data so as to identify the most worthwhile data points that should be annotated under some budget of labeling cost. Based on the intuition that the few-shot training instances should be diverse and representative of the entire data distribution, we propose a simple selection strategy with K-means clustering. We show that even with the naive clustering-based approach, the generation models consistently outperform random sampling on three text generation tasks: data-to-text generation, document summarization and question generation. The code and training data are made available. We hope that this work will call for more attention on this largely unexplored area.
The introduction of pretrained language models has reduced many complex task-specific NLP models to simple lightweight layers. An exception to this trend is coreference resolution, where a sophisticated task-specific model is appended to a pretrained transformer encoder. While highly effective, the model has a very large memory footprint – primarily due to dynamically-constructed span and span-pair representations – which hinders the processing of complete documents and the ability to train on multiple instances in a single batch. We introduce a lightweight end-to-end coreference model that removes the dependency on span representations, handcrafted features, and heuristics. Our model performs competitively with the current standard model, while being simpler and more efficient.
In comparison with English, due to the lack of explicit word boundary and tenses information, Chinese Named Entity Recognition (NER) is much more challenging. In this paper, we propose a boundary enhanced approach for better Chinese NER. In particular, our approach enhances the boundary information from two perspectives. On one hand, we enhance the representation of the internal dependency of phrases by an additional Graph Attention Network(GAT) layer. On the other hand, taking the entity head-tail prediction (i.e., boundaries) as an auxiliary task, we propose an unified framework to learn the boundary information and recognize the NE jointly. Experiments on both the OntoNotes and the Weibo corpora show the effectiveness of our approach.
The high-quality translation results produced by machine translation (MT) systems still pose a huge challenge for automatic evaluation. Current MT evaluation pays the same attention to each sentence component, while the questions of real-world examinations (e.g., university examinations) have different difficulties and weightings. In this paper, we propose a novel difficulty-aware MT evaluation metric, expanding the evaluation dimension by taking translation difficulty into consideration. A translation that fails to be predicted by most MT systems will be treated as a difficult one and assigned a large weight in the final score function, and conversely. Experimental results on the WMT19 English-German Metrics shared tasks show that our proposed method outperforms commonly used MT metrics in terms of human correlation. In particular, our proposed method performs well even when all the MT systems are very competitive, which is when most existing metrics fail to distinguish between them. The source code is freely available at https://github.com/NLP2CT/Difficulty-Aware-MT-Evaluation.
Humor recognition has been widely studied as a text classification problem using data-driven approaches. However, most existing work does not examine the actual joke mechanism to understand humor. We break down any joke into two distinct components: the set-up and the punchline, and further explore the special relationship between them. Inspired by the incongruity theory of humor, we model the set-up as the part developing semantic uncertainty, and the punchline disrupting audience expectations. With increasingly powerful language models, we were able to feed the set-up along with the punchline into the GPT-2 language model, and calculate the uncertainty and surprisal values of the jokes. By conducting experiments on the SemEval 2021 Task 7 dataset, we found that these two features have better capabilities of telling jokes from non-jokes, compared with existing baselines.
Disentanglement of latent representations into content and style spaces has been a commonly employed method for unsupervised text style transfer. These techniques aim to learn the disentangled representations and tweak them to modify the style of a sentence. In this paper, we propose a counterfactual-based method to modify the latent representation, by posing a ‘what-if’ scenario. This simple and disciplined approach also enables a fine-grained control on the transfer strength. We conduct experiments with the proposed methodology on multiple attribute transfer tasks like Sentiment, Formality and Excitement to support our hypothesis.
Shapley Values, a solution to the credit assignment problem in cooperative game theory, are a popular type of explanation in machine learning, having been used to explain the importance of features, embeddings, and even neurons. In NLP, however, leave-one-out and attention-based explanations still predominate. Can we draw a connection between these different methods? We formally prove that — save for the degenerate case — attention weights and leave-one-out values cannot be Shapley Values. Attention flow is a post-processed variant of attention weights obtained by running the max-flow algorithm on the attention graph. Perhaps surprisingly, we prove that attention flows are indeed Shapley Values, at least at the layerwise level. Given the many desirable theoretical qualities of Shapley Values — which has driven their adoption among the ML community — we argue that NLP practitioners should, when possible, adopt attention flow explanations alongside more traditional ones.
Video paragraph captioning aims to generate a set of coherent sentences to describe a video that contains several events. Most previous methods simplify this task by using ground-truth event segments. In this work, we propose a novel framework by taking this task as a text summarization task. We first generate lots of sentence-level captions focusing on different video clips and then summarize these captions to obtain the final paragraph caption. Our method does not depend on ground-truth event segments. Experiments on two popular datasets ActivityNet Captions and YouCookII demonstrate the advantages of our new framework. On the ActivityNet dataset, our method even outperforms some previous methods using ground-truth event segment labels.
Deep learning algorithms have shown promising results in visual question answering (VQA) tasks, but a more careful look reveals that they often do not understand the rich signal they are being fed with. To understand and better measure the generalization capabilities of VQA systems, we look at their robustness to counterfactually augmented data. Our proposed augmentations are designed to make a focused intervention on a specific property of the question such that the answer changes. Using these augmentations, we propose a new robustness measure, Robustness to Augmented Data (RAD), which measures the consistency of model predictions between original and augmented examples. Through extensive experimentation, we show that RAD, unlike classical accuracy measures, can quantify when state-of-the-art systems are not robust to counterfactuals. We find substantial failure cases which reveal that current VQA systems are still brittle. Finally, we connect between robustness and generalization, demonstrating the predictive power of RAD for performance on unseen augmentations.
Existing approaches for the Table-to-Text task suffer from issues such as missing information, hallucination and repetition. Many approaches to this problem use Reinforcement Learning (RL), which maximizes a single manually defined reward, such as BLEU. In this work, we instead pose the Table-to-Text task as Inverse Reinforcement Learning (IRL) problem. We explore using multiple interpretable unsupervised reward components that are combined linearly to form a composite reward function. The composite reward function and the description generator are learned jointly. We find that IRL outperforms strong RL baselines marginally. We further study the generalization of learned IRL rewards in scenarios involving domain adaptation. Our experiments reveal significant challenges in using IRL for this task.
Most fact checking models for automatic fake news detection are based on reasoning: given a claim with associated evidence, the models aim to estimate the claim veracity based on the supporting or refuting content within the evidence. When these models perform well, it is generally assumed to be due to the models having learned to reason over the evidence with regards to the claim. In this paper, we investigate this assumption of reasoning, by exploring the relationship and importance of both claim and evidence. Surprisingly, we find on political fact checking datasets that most often the highest effectiveness is obtained by utilizing only the evidence, as the impact of including the claim is either negligible or harmful to the effectiveness. This highlights an important problem in what constitutes evidence in existing approaches for automatic fake news detection.
Despite end-to-end neural systems making significant progress in the last decade for task-oriented as well as chit-chat based dialogue systems, most dialogue systems rely on hybrid approaches which use a combination of rule-based, retrieval and generative approaches for generating a set of ranked responses. Such dialogue systems need to rely on a fallback mechanism to respond to out-of-domain or novel user queries which are not answerable within the scope of the dialogue system. While, dialogue systems today rely on static and unnatural responses like “I don’t know the answer to that question” or “I’m not sure about that”, we design a neural approach which generates responses which are contextually aware with the user query as well as say no to the user. Such customized responses provide paraphrasing ability and contextualization as well as improve the interaction with the user and reduce dialogue monotonicity. Our simple approach makes use of rules over dependency parses and a text-to-text transformer fine-tuned on synthetic data of question-response pairs generating highly relevant, grammatical as well as diverse questions. We perform automatic and manual evaluations to demonstrate the efficacy of the system.
Spoken Language Understanding (SLU) systems parse speech into semantic structures like dialog acts and slots. This involves the use of an Automatic Speech Recognizer (ASR) to transcribe speech into multiple text alternatives (hypotheses). Transcription errors, ordinary in ASRs, impact downstream SLU performance negatively. Common approaches to mitigate such errors involve using richer information from the ASR, either in form of N-best hypotheses or word-lattices. We hypothesize that transformer models will learn better with a simpler utterance representation using the concatenation of the N-best ASR alternatives, where each alternative is separated by a special delimiter [SEP]. In our work, we test our hypothesis by using the concatenated N-best ASR alternatives as the input to the transformer encoder models, namely BERT and XLM-RoBERTa, and achieve equivalent performance to the prior state-of-the-art model on DSTC2 dataset. We also show that our approach significantly outperforms the prior state-of-the-art when subjected to the low data regime. Additionally, this methodology is accessible to users of third-party ASR APIs which do not provide word-lattice information.
Is bias amplified when neural machine translation (NMT) models are optimized for speed and evaluated on generic test sets using BLEU? We investigate architectures and techniques commonly used to speed up decoding in Transformer-based models, such as greedy search, quantization, average attention networks (AANs) and shallow decoder models and show their effect on gendered noun translation. We construct a new gender bias test set, SimpleGEN, based on gendered noun phrases in which there is a single, unambiguous, correct answer. While we find minimal overall BLEU degradation as we apply speed optimizations, we observe that gendered noun translation performance degrades at a much faster rate.
State-of-the-art machine translation (MT) systems are typically trained to generate “standard” target language; however, many languages have multiple varieties (regional varieties, dialects, sociolects, non-native varieties) that are different from the standard language. Such varieties are often low-resource, and hence do not benefit from contemporary NLP solutions, MT included. We propose a general framework to rapidly adapt MT systems to generate language varieties that are close to, but different from, the standard target language, using no parallel (source–variety) data. This also includes adaptation of MT systems to low-resource typologically-related target languages. We experiment with adapting an English–Russian MT system to generate Ukrainian and Belarusian, an English–Norwegian Bokmål system to generate Nynorsk, and an English–Arabic system to generate four Arabic dialects, obtaining significant improvements over competitive baselines.
Sparse attention has been claimed to increase model interpretability under the assumption that it highlights influential inputs. Yet the attention distribution is typically over representations internal to the model rather than the inputs themselves, suggesting this assumption may not have merit. We build on the recent work exploring the interpretability of attention; we design a set of experiments to help us understand how sparsity affects our ability to use attention as an explainability tool. On three text classification tasks, we verify that only a weak relationship between inputs and co-indexed intermediate representations exists—under sparse attention and otherwise. Further, we do not find any plausible mappings from sparse attention distributions to a sparse set of influential inputs through other avenues. Rather, we observe in this setting that inducing sparsity may make it less plausible that attention can be used as a tool for understanding model behavior.
Mechanisms for encoding positional information are central for transformer-based language models. In this paper, we analyze the position embeddings of existing language models, finding strong evidence of translation invariance, both for the embeddings themselves and for their effect on self-attention. The degree of translation invariance increases during training and correlates positively with model performance. Our findings lead us to propose translation-invariant self-attention (TISA), which accounts for the relative position between tokens in an interpretable fashion without needing conventional position embeddings. Our proposal has several theoretical advantages over existing position-representation approaches. Proof-of-concept experiments show that it improves on regular ALBERT on GLUE tasks, while only adding orders of magnitude less positional parameters.
Determining the relative importance of the elements in a sentence is a key factor for effortless natural language understanding. For human language processing, we can approximate patterns of relative importance by measuring reading fixations using eye-tracking technology. In neural language models, gradient-based saliency methods indicate the relative importance of a token for the target objective. In this work, we compare patterns of relative importance in English language processing by humans and models and analyze the underlying linguistic patterns. We find that human processing patterns in English correlate strongly with saliency-based importance in language models and not with attention-based importance. Our results indicate that saliency could be a cognitively more plausible metric for interpreting neural language models. The code is available on github: https://github.com/beinborn/relative_importance.
Pretrained language models (PLM) achieve surprising performance on the Choice of Plausible Alternatives (COPA) task. However, whether PLMs have truly acquired the ability of causal reasoning remains a question. In this paper, we investigate the problem of semantic similarity bias and reveal the vulnerability of current COPA models by certain attacks. Previous solutions that tackle the superficial cues of unbalanced token distribution still encounter the same problem of semantic bias, even more seriously due to the utilization of more training data. We mitigate this problem by simply adding a regularization loss and experimental results show that this solution not only improves the model’s generalization ability, but also assists the models to perform more robustly on a challenging dataset, BCOPA-CE, which has unbiased token distribution and is more difficult for models to distinguish cause and effect.
A current open question in natural language processing is to what extent language models, which are trained with access only to the form of language, are able to capture the meaning of language. This question is challenging to answer in general, as there is no clear line between meaning and form, but rather meaning constrains form in consistent ways. The goal of this study is to offer insights into a narrower but critical subquestion: Under what conditions should we expect that meaning and form covary sufficiently, such that a language model with access only to form might nonetheless succeed in emulating meaning? Focusing on several formal languages (propositional logic and a set of programming languages), we generate training corpora using a variety of motivated constraints, and measure a distributional language model’s ability to differentiate logical symbols (AND, OR, and NOT). Our findings are largely negative: none of our simulated training corpora result in models which definitively differentiate meaningfully different symbols (e.g., AND vs. OR), suggesting a limitation to the types of semantic signals that current models are able to exploit.
The predominant challenge in weakly supervised semantic parsing is that of spurious programs that evaluate to correct answers for the wrong reasons. Prior work uses elaborate search strategies to mitigate the prevalence of spurious programs; however, they typically consider only one input at a time. In this work we explore the use of consistency between the output programs for related inputs to reduce the impact of spurious programs. We bias the program search (and thus the model’s training signal) towards programs that map the same phrase in related inputs to the same sub-parts in their respective programs. Additionally, we study the importance of designing logical formalisms that facilitate this kind of consistency-based training. We find that a more consistent formalism leads to improved model performance even without consistency-based training. When combined together, these two insights lead to a 10% absolute improvement over the best prior result on the Natural Language Visual Reasoning dataset.
In this paper, we present an improved model for voicing silent speech, where audio is synthesized from facial electromyography (EMG) signals. To give our model greater flexibility to learn its own input features, we directly use EMG signals as input in the place of hand-designed features used by prior work. Our model uses convolutional layers to extract features from the signals and Transformer layers to propagate information across longer distances. To provide better signal for learning, we also introduce an auxiliary task of predicting phoneme labels in addition to predicting speech audio features. On an open vocabulary intelligibility evaluation, our model improves the state of the art for this task by an absolute 25.8%.
Whereas much of the success of the current generation of neural language models has been driven by increasingly large training corpora, relatively little research has been dedicated to analyzing these massive sources of textual data. In this exploratory analysis, we delve deeper into the Common Crawl, a colossal web corpus that is extensively used for training language models. We find that it contains a significant amount of undesirable content, including hate speech and sexually explicit content, even after filtering procedures. We discuss the potential impacts of this content on language models and conclude with future research directions and a more mindful approach to corpus collection and analysis.
Most current quality estimation (QE) models for machine translation are trained and evaluated in a static setting where training and test data are assumed to be from a fixed distribution. However, in real-life settings, the test data that a deployed QE model would be exposed to may differ from its training data. In particular, training samples are often labelled by one or a small set of annotators, whose perceptions of translation quality and needs may differ substantially from those of end-users, who will employ predictions in practice. To address this challenge, we propose an online Bayesian meta-learning framework for the continuous training of QE models that is able to adapt them to the needs of different users, while being robust to distributional shifts in training and test data. Experiments on data with varying number of users and language characteristics validate the effectiveness of the proposed approach.
Sequential sentence classification aims to classify each sentence in the document based on the context in which sentences appear. Most existing work addresses this problem using a hierarchical sequence labeling network. However, they ignore considering the latent segment structure of the document, in which contiguous sentences often have coherent semantics. In this paper, we proposed a span-based dynamic local attention model that could explicitly capture the structural information by the proposed supervised dynamic local attention. We further introduce an auxiliary task called span-based classification to explore the span-level representations. Extensive experiments show that our model achieves better or competitive performance against state-of-the-art baselines on two benchmark datasets.
Ordered word sequences contain the rich structures that define language. However, it’s often not clear if or how modern pretrained language models utilize these structures. We show that the token representations and self-attention activations within BERT are surprisingly resilient to shuffling the order of input tokens, and that for several GLUE language understanding tasks, shuffling only minimally degrades performance, e.g., by 4% for QNLI. While bleak from the perspective of language understanding, our results have positive implications for cases where copyright or ethics necessitates the consideration of bag-of-words data (vs. full documents). We simulate such a scenario for three sensitive classification tasks, demonstrating minimal performance degradation vs. releasing full language sequences.
Recent works made significant advances on summarization tasks, facilitated by summarization datasets. Several existing datasets have the form of coherent-paragraph summaries. However, these datasets were curated from academic documents that were written for experts, thus making the essential step of assessing the summarization output through human-evaluation very demanding. To overcome these limitations, we present a dataset based on article summaries appearing on the WikiHow website, composed of how-to articles and coherent-paragraph summaries written in plain language. We compare our dataset attributes to existing ones, including readability and world-knowledge, showing our dataset makes human evaluation significantly easier and thus, more effective. A human evaluation conducted on PubMed and the proposed dataset reinforces our findings.
Despite the success of various text generation metrics such as BERTScore, it is still difficult to evaluate the image captions without enough reference captions due to the diversity of the descriptions. In this paper, we introduce a new metric UMIC, an Unreferenced Metric for Image Captioning which does not require reference captions to evaluate image captions. Based on Vision-and-Language BERT, we train UMIC to discriminate negative captions via contrastive learning. Also, we observe critical problems of the previous benchmark dataset (i.e., human annotations) on image captioning metric, and introduce a new collection of human annotations on the generated captions. We validate UMIC on four datasets, including our new dataset, and show that UMIC has a higher correlation than all previous metrics that require multiple references.
Good quality monolingual word embeddings (MWEs) can be built for languages which have large amounts of unlabeled text. MWEs can be aligned to bilingual spaces using only a few thousand word translation pairs. For low resource languages training MWEs monolingually results in MWEs of poor quality, and thus poor bilingual word embeddings (BWEs) as well. This paper proposes a new approach for building BWEs in which the vector space of the high resource source language is used as a starting point for training an embedding space for the low resource target language. By using the source vectors as anchors the vector spaces are automatically aligned during training. We experiment on English-German, English-Hiligaynon and English-Macedonian. We show that our approach results not only in improved BWEs and bilingual lexicon induction performance, but also in improved target language MWE quality as measured using monolingual word similarity.
Although multilingual neural machine translation (MNMT) enables multiple language translations, the training process is based on independent multilingual objectives. Most multilingual models can not explicitly exploit different language pairs to assist each other, ignoring the relationships among them. In this work, we propose a novel agreement-based method to encourage multilingual agreement among different translation directions, which minimizes the differences among them. We combine the multilingual training objectives with the agreement term by randomly substituting some fragments of the source language with their counterpart translations of auxiliary languages. To examine the effectiveness of our method, we conduct experiments on the multilingual translation task of 10 language pairs. Experimental results show that our method achieves significant improvements over the previous multilingual baselines.
Weighted finite-state machines are a fundamental building block of NLP systems. They have withstood the test of time—from their early use in noisy channel models in the 1990s up to modern-day neurally parameterized conditional random fields. This work examines the computation of higher-order derivatives with respect to the normalization constant for weighted finite-state machines. We provide a general algorithm for evaluating derivatives of all orders, which has not been previously described in the literature. In the case of second-order derivatives, our scheme runs in the optimal O(Aˆ2 Nˆ4) time where A is the alphabet size and N is the number of states. Our algorithm is significantly faster than prior algorithms. Additionally, our approach leads to a significantly faster algorithm for computing second-order expectations, such as covariance matrices and gradients of first-order expectations.
The growth of online consumer health questions has led to the necessity for reliable and accurate question answering systems. A recent study showed that manual summarization of consumer health questions brings significant improvement in retrieving relevant answers. However, the automatic summarization of long questions is a challenging task due to the lack of training data and the complexity of the related subtasks, such as the question focus and type recognition. In this paper, we introduce a reinforcement learning-based framework for abstractive question summarization. We propose two novel rewards obtained from the downstream tasks of (i) question-type identification and (ii) question-focus recognition to regularize the question generation model. These rewards ensure the generation of semantically valid questions and encourage the inclusion of key medical entities/foci in the question summary. We evaluated our proposed method on two benchmark datasets and achieved higher performance over state-of-the-art models. The manual evaluation of the summaries reveals that the generated questions are more diverse and have fewer factual inconsistencies than the baseline summaries. The source code is available here: https://github.com/shwetanlp/CHQ-Summ.
Relation linking is a crucial component of Knowledge Base Question Answering systems. Existing systems use a wide variety of heuristics, or ensembles of multiple systems, heavily relying on the surface question text. However, the explicit semantic parse of the question is a rich source of relation information that is not taken advantage of. We propose a simple transformer-based neural model for relation linking that leverages the AMR semantic parse of a sentence. Our system significantly outperforms the state-of-the-art on 4 popular benchmark datasets. These are based on either DBpedia or Wikidata, demonstrating that our approach is effective across KGs.
Early fusion models with cross-attention have shown better-than-human performance on some question answer benchmarks, while it is a poor fit for retrieval since it prevents pre-computation of the answer representations. We present a supervised data mining method using an accurate early fusion model to improve the training of an efficient late fusion retrieval model. We first train an accurate classification model with cross-attention between questions and answers. The cross-attention model is then used to annotate additional passages in order to generate weighted training examples for a neural retrieval model. The resulting retrieval model with additional data significantly outperforms retrieval models directly trained with gold annotations on Precision at N (P@N) and Mean Reciprocal Rank (MRR).
Generating descriptive sentences that convey non-trivial, detailed, and salient information about images is an important goal of image captioning. In this paper we propose a novel approach to encourage captioning models to produce more detailed captions using natural language inference, based on the motivation that, among different captions of an image, descriptive captions are more likely to entail less descriptive captions. Specifically, we construct directed inference graphs for reference captions based on natural language inference. A PageRank algorithm is then employed to estimate the descriptiveness score of each node. Built on that, we use reference sampling and weighted designated rewards to guide captioning to generate descriptive captions. The results on MSCOCO show that the proposed method outperforms the baselines significantly on a wide range of conventional and descriptiveness-related evaluation metrics.
We present an instance-based nearest neighbor approach to entity linking. In contrast to most prior entity retrieval systems which represent each entity with a single vector, we build a contextualized mention-encoder that learns to place similar mentions of the same entity closer in vector space than mentions of different entities. This approach allows all mentions of an entity to serve as “class prototypes” as inference involves retrieving from the full set of labeled entity mentions in the training set and applying the nearest mention neighbor’s entity label. Our model is trained on a large multilingual corpus of mention pairs derived from Wikipedia hyperlinks, and performs nearest neighbor inference on an index of 700 million mentions. It is simpler to train, gives more interpretable predictions, and outperforms all other systems on two multilingual entity linking benchmarks.
BERT has been shown to be extremely effective on a wide variety of natural language processing tasks, including sentiment analysis and emotion detection. However, the proposed pretraining objectives of BERT do not induce any sentiment or emotion-specific biases into the model. In this paper, we present Emotion Masked Language Modelling, a variation of Masked Language Modelling aimed at improving the BERT language representation model for emotion detection and sentiment analysis tasks. Using the same pre-training corpora as the original model, Wikipedia and BookCorpus, our BERT variation manages to improve the downstream performance on 4 tasks from emotion detection and sentiment analysis by an average of 1.2% F-1. Moreover, our approach shows an increased performance in our task-specific robustness tests.
Prior work has revealed that positive words occur more frequently than negative words in human expressions, which is typically attributed to positivity bias, a tendency for people to report positive views of reality. But what about the language used in negative reviews? Consistent with prior work, we show that English negative reviews tend to contain more positive words than negative words, using a variety of datasets. We reconcile this observation with prior findings on the pragmatics of negation, and show that negations are commonly associated with positive words in negative reviews. Furthermore, in negative reviews, the majority of sentences with positive words express negative opinions based on sentiment classifiers, indicating some form of negation.
Large pre-trained language generation models such as GPT-2 have demonstrated their effectiveness as language priors by reaching state-of-the-art results in various language generation tasks. However, the performance of pre-trained models on task-oriented dialog tasks is still under-explored. We propose a Pre-trainedRole Alternating Language model (PRAL), explicitly designed for task-oriented conversational systems. We design several techniques: start position randomization, knowledge distillation, and history discount to improve pre-training performance. In addition, we introduce a high-quality large-scale task-oriented dialog pre-training dataset by post-prossessing13 dialog datasets. We effectively adapt PRALon three downstream tasks. The results show that PRAL outperforms or is on par with state-of-the-art models.
Natural reading orders of words are crucial for information extraction from form-like documents. Despite recent advances in Graph Convolutional Networks (GCNs) on modeling spatial layout patterns of documents, they have limited ability to capture reading orders of given word-level node representations in a graph. We propose Reading Order Equivariant Positional Encoding (ROPE), a new positional encoding technique designed to apprehend the sequential presentation of words in documents. ROPE generates unique reading order codes for neighboring words relative to the target word given a word-level graph connectivity. We study two fundamental document entity extraction tasks including word labeling and word grouping on the public FUNSD dataset and a large-scale payment dataset. We show that ROPE consistently improves existing GCNs with a margin up to 8.4% F1-score.
Event extraction has long been a challenging task, addressed mostly with supervised methods that require expensive annotation and are not extensible to new event ontologies. In this work, we explore the possibility of zero-shot event extraction by formulating it as a set of Textual Entailment (TE) and/or Question Answering (QA) queries (e.g. “A city was attacked” entails “There is an attack”), exploiting pretrained TE/QA models for direct transfer. On ACE-2005 and ERE, our system achieves acceptable results, yet there is still a large gap from supervised approaches, showing that current QA and TE technologies fail in transferring to a different domain. To investigate the reasons behind the gap, we analyze the remaining key challenges, their respective impact, and possible improvement directions.
Pre-trained language models have achieved human-level performance on many Machine Reading Comprehension (MRC) tasks, but it remains unclear whether these models truly understand language or answer questions by exploiting statistical biases in datasets. Here, we demonstrate a simple yet effective method to attack MRC models and reveal the statistical biases in these models. We apply the method to the RACE dataset, for which the answer to each MRC question is selected from 4 options. It is found that several pre-trained language models, including BERT, ALBERT, and RoBERTa, show consistent preference to some options, even when these options are irrelevant to the question. When interfered by these irrelevant options, the performance of MRC models can be reduced from human-level performance to the chance-level performance. Human readers, however, are not clearly affected by these irrelevant options. Finally, we propose an augmented training method that can greatly reduce models’ statistical biases.
Extensive work has argued in favour of paying crowd workers a wage that is at least equivalent to the U.S. federal minimum wage. Meanwhile, research on collecting high quality annotations suggests using a qualification that requires workers to have previously completed a certain number of tasks. If most requesters who pay fairly require workers to have completed a large number of tasks already then workers need to complete a substantial amount of poorly paid work before they can earn a fair wage. Through analysis of worker discussions and guidance for researchers, we estimate that workers spend approximately 2.25 months of full time effort on poorly paid tasks in order to get the qualifications needed for better paid tasks. We discuss alternatives to this qualification and conduct a study of the correlation between qualifications and work quality on two NLP tasks. We find that it is possible to reduce the burden on workers while still collecting high quality data.
Human activities can be seen as sequences of events, which are crucial to understanding societies. Disproportional event distribution for different demographic groups can manifest and amplify social stereotypes, and potentially jeopardize the ability of members in some groups to pursue certain goals. In this paper, we present the first event-centric study of gender biases in a Wikipedia corpus. To facilitate the study, we curate a corpus of career and personal life descriptions with demographic information consisting of 7,854 fragments from 10,412 celebrities. Then we detect events with a state-of-the-art event detection model, calibrate the results using strategically generated templates, and extract events that have asymmetric associations with genders. Our study discovers that the Wikipedia pages tend to intermingle personal life events with professional events for females but not for males, which calls for the awareness of the Wikipedia community to formalize guidelines and train the editors to mind the implicit biases that contributors carry. Our work also lays the foundation for future works on quantifying and discovering event biases at the corpus level.
Neural machine translation has achieved great success in bilingual settings, as well as in multilingual settings. With the increase of the number of languages, multilingual systems tend to underperform their bilingual counterparts. Model capacity has been found crucial for massively multilingual NMT to support language pairs with varying typological characteristics. Previous work increases the modeling capacity by deepening or widening the Transformer. However, modeling cardinality based on aggregating a set of transformations with the same topology has been proven more effective than going deeper or wider when increasing capacity. In this paper, we propose to efficiently increase the capacity for multilingual NMT by increasing the cardinality. Unlike previous work which feeds the same input to several transformations and merges their outputs into one, we present a Multi-Input-Multi-Output (MIMO) architecture that allows each transformation of the block to have its own input. We also present a task-aware attention mechanism to learn to selectively utilize individual transformations from a set of transformations for different translation directions. Our model surpasses previous work and establishes a new state-of-the-art on the large scale OPUS-100 corpus while being 1.31 times as fast.
kNN-MT, recently proposed by Khandelwal et al. (2020a), successfully combines pre-trained neural machine translation (NMT) model with token-level k-nearest-neighbor (kNN) retrieval to improve the translation accuracy. However, the traditional kNN algorithm used in kNN-MT simply retrieves a same number of nearest neighbors for each target token, which may cause prediction errors when the retrieved neighbors include noises. In this paper, we propose Adaptive kNN-MT to dynamically determine the number of k for each target token. We achieve this by introducing a light-weight Meta-k Network, which can be efficiently trained with only a few training samples. On four benchmark machine translation datasets, we demonstrate that the proposed method is able to effectively filter out the noises in retrieval results and significantly outperforms the vanilla kNN-MT model. Even more noteworthy is that the Meta-k Network learned on one domain could be directly applied to other domains and obtain consistent improvements, illustrating the generality of our method. Our implementation is open-sourced at https://github.com/zhengxxn/adaptive-knn-mt.
Orthogonality constraints encourage matrices to be orthogonal for numerical stability. These plug-and-play constraints, which can be conveniently incorporated into model training, have been studied for popular architectures in natural language processing, such as convolutional neural networks and recurrent neural networks. However, a dedicated study on such constraints for transformers has been absent. To fill this gap, this paper studies orthogonality constraints for transformers, showing the effectiveness with empirical evidence from ten machine translation tasks and two dialogue generation tasks. For example, on the large-scale WMT’16 En→De benchmark, simply plugging-and-playing orthogonality constraints on the original transformer model (Vaswani et al., 2017) increases the BLEU from 28.4 to 29.6, coming close to the 29.7 BLEU achieved by the very competitive dynamic convolution (Wu et al., 2019).
Imagine you are in a supermarket. You have two bananas in your basket and want to buy four apples. How many fruits do you have in total? This seemingly straightforward question can be challenging for data-driven language models, even if trained at scale. However, we would expect such generic language models to possess some mathematical abilities in addition to typical linguistic competence. Towards this goal, we investigate if a commonly used language model, BERT, possesses such mathematical abilities and, if so, to what degree. For that, we fine-tune BERT on a popular dataset for word math problems, AQuA-RAT, and conduct several tests to understand learned representations better. Since we teach models trained on natural language to do formal mathematics, we hypothesize that such models would benefit from training on semi-formal steps that explain how math results are derived. To better accommodate such training, we also propose new pretext tasks for learning mathematical rules. We call them (Neighbor) Reasoning Order Prediction (ROP or NROP). With this new model, we achieve significantly better outcomes than data-driven baselines and even on-par with more tailored models.
Datasets with induced emotion labels are scarce but of utmost importance for many NLP tasks. We present a new, automated method for collecting texts along with their induced reaction labels. The method exploits the online use of reaction GIFs, which capture complex affective states. We show how to augment the data with induced emotion and induced sentiment labels. We use our method to create and publish ReactionGIF, a first-of-its-kind affective dataset of 30K tweets. We provide baselines for three new tasks, including induced sentiment prediction and multilabel classification of induced emotions. Our method and dataset open new research opportunities in emotion detection and affective computing.
This work explores a framework for fact verification that leverages pretrained sequence-to-sequence transformer models for sentence selection and label prediction, two key sub-tasks in fact verification. Most notably, improving on previous pointwise aggregation approaches for label prediction, we take advantage of T5 using a listwise approach coupled with data augmentation. With this enhancement, we observe that our label prediction stage is more robust to noise and capable of verifying complex claims by jointly reasoning over multiple pieces of evidence. Experimental results on the FEVER task show that our system attains a FEVER score of 75.87% on the blind test set. This puts our approach atop the competitive FEVER leaderboard at the time of our work, scoring higher than the second place submission by almost two points in label accuracy and over one point in FEVER score.
Sentence embedding methods using natural language inference (NLI) datasets have been successfully applied to various tasks. However, these methods are only available for limited languages due to relying heavily on the large NLI datasets. In this paper, we propose DefSent, a sentence embedding method that uses definition sentences from a word dictionary, which performs comparably on unsupervised semantics textual similarity (STS) tasks and slightly better on SentEval tasks than conventional methods. Since dictionaries are available for many languages, DefSent is more broadly applicable than methods using NLI datasets without constructing additional datasets. We demonstrate that DefSent performs comparably on unsupervised semantics textual similarity (STS) tasks and slightly better on SentEval tasks to the methods using large NLI datasets. Our code is publicly available at https://github.com/hpprc/defsent.
Modern sentence encoders are used to generate dense vector representations that capture the underlying linguistic characteristics for a sequence of words, including phrases, sentences, or paragraphs. These kinds of representations are ideal for training a classifier for an end task such as sentiment analysis, question answering and text classification. Different models have been proposed to efficiently generate general purpose sentence representations to be used in pretraining protocols. While averaging is the most commonly used efficient sentence encoder, Discrete Cosine Transform (DCT) was recently proposed as an alternative that captures the underlying syntactic characteristics of a given text without compromising practical efficiency compared to averaging. However, as with most other sentence encoders, the DCT sentence encoder was only evaluated in English. To this end, we utilize DCT encoder to generate universal sentence representation for different languages such as German, French, Spanish and Russian. The experimental results clearly show the superior effectiveness of DCT encoding in which consistent performance improvements are achieved over strong baselines on multiple standardized datasets
High-quality alignment between movie scripts and plot summaries is an asset for learning to summarize stories and to generate dialogues. The alignment task is challenging as scripts and summaries substantially differ in details and abstraction levels as well as in linguistic register. This paper addresses the alignment problem by devising a fully unsupervised approach based on a global optimization model. Experimental results on ten movies show the viability of our method with 76% F1-score and its superiority over a previous baseline. We publish alignments for 914 movies to foster research in this new topic.
Most studies on word-level Quality Estimation (QE) of machine translation focus on language-specific models. The obvious disadvantages of these approaches are the need for labelled data for each language pair and the high cost required to maintain several language-specific models. To overcome these problems, we explore different approaches to multilingual, word-level QE. We show that multilingual QE models perform on par with the current language-specific models. In the cases of zero-shot and few-shot QE, we demonstrate that it is possible to accurately predict word-level quality for any given new language pair from models trained on other language pairs. Our findings suggest that the word-level QE models based on powerful pre-trained transformers that we propose in this paper generalise well across languages, making them more useful in real-world scenarios.
A sequence-to-sequence learning with neural networks has empirically proven to be an effective framework for Chinese Spelling Correction (CSC), which takes a sentence with some spelling errors as input and outputs the corrected one. However, CSC models may fail to correct spelling errors covered by the confusion sets, and also will encounter unseen ones. We propose a method, which continually identifies the weak spots of a model to generate more valuable training instances, and apply a task-specific pre-training strategy to enhance the model. The generated adversarial examples are gradually added to the training set. Experimental results show that such an adversarial training method combined with the pre-training strategy can improve both the generalization and robustness of multiple CSC models across three different datasets, achieving state-of-the-art performance for CSC task.
Adaptive Computation (AC) has been shown to be effective in improving the efficiency of Open-Domain Question Answering (ODQA) systems. However, the current AC approaches require tuning of all model parameters, and training state-of-the-art ODQA models requires significant computational resources that may not be available for most researchers. We propose Adaptive Passage Encoder, an AC method that can be applied to an existing ODQA model and can be trained efficiently on a single GPU. It keeps the parameters of the base ODQA model fixed, but it overrides the default layer-by-layer computation of the encoder with an AC policy that is trained to optimise the computational efficiency of the model. Our experimental results show that our method improves upon a state-of-the-art model on two datasets, and is also more accurate than previous AC methods due to the stronger base ODQA model. All source code and datasets are available at https://github.com/uclnlp/APE.
In this paper, we empirically investigate adversarial attack on NMT from two aspects: languages (the source vs. the target language) and positions (front vs. rear). For autoregressive NMT models that generate target words from left to right, we observe that adversarial attack on the source language is more effective than on the target language, and that attacking front positions of target sentences or positions of source sentences aligned to the front positions of corresponding target sentences is more effective than attacking other positions. We further exploit the attention distribution of the victim model to attack source sentences at positions that have a strong association with front target words. Experiment results demonstrate that our attention-based adversarial attack is more effective than adversarial attacks by sampling positions randomly or according to gradients.
SOTA coreference resolution produces increasingly impressive scores on the OntoNotes benchmark. However lack of comparable data following the same scheme for more genres makes it difficult to evaluate generalizability to open domain data. This paper provides a dataset and comprehensive evaluation showing that the latest neural LM based end-to-end systems degrade very substantially out of domain. We make an OntoNotes-like coreference dataset called OntoGUM publicly available, converted from GUM, an English corpus covering 12 genres, using deterministic rules, which we evaluate. Thanks to the rich syntactic and discourse annotations in GUM, we are able to create the largest human-annotated coreference corpus following the OntoNotes guidelines, and the first to be evaluated for consistency with the OntoNotes scheme. Out-of-domain evaluation across 12 genres shows nearly 15-20% degradation for both deterministic and deep learning systems, indicating a lack of generalizability or covert overfitting in existing coreference resolution models.
Visual Question Answering (VQA) methods aim at leveraging visual input to answer questions that may require complex reasoning over entities. Current models are trained on labelled data that may be insufficient to learn complex knowledge representations. In this paper, we propose a new method to enhance the reasoning capabilities of a multi-modal pretrained model (Vision+Language BERT) by integrating facts extracted from an external knowledge base. Evaluation on the KVQA dataset benchmark demonstrates that our method outperforms competitive baselines by 19%, achieving new state-of-the-art results. We also perform an extensive analysis highlighting the limitations of our best performing model through an ablation study.
Neural models for automated fact verification have achieved promising results thanks to the availability of large, human-annotated datasets. However, for each new domain that requires fact verification, creating a dataset by manually writing claims and linking them to their supporting evidence is expensive. We develop QACG, a framework for training a robust fact verification model by using automatically generated claims that can be supported, refuted, or unverifiable from evidence from Wikipedia. QACG generates question-answer pairs from the evidence and then converts them into different types of claims. Experiments on the FEVER dataset show that our QACG framework significantly reduces the demand for human-annotated training data. In a zero-shot scenario, QACG improves a RoBERTa model’s F1 from 50% to 77%, equivalent in performance to 2K+ manually-curated examples. Our QACG code is publicly available.
Scarcity of parallel data causes formality style transfer models to have scarce success in preserving content. We show that fine-tuning pre-trained language (GPT-2) and sequence-to-sequence (BART) models boosts content preservation, and that this is possible even with limited amounts of parallel data. Augmenting these models with rewards that target style and content –the two core aspects of the task– we achieve a new state-of-the-art.
Existing works for aspect-based sentiment analysis (ABSA) have adopted a unified approach, which allows the interactive relations among subtasks. However, we observe that these methods tend to predict polarities based on the literal meaning of aspect and opinion terms and mainly consider relations implicitly among subtasks at the word level. In addition, identifying multiple aspect–opinion pairs with their polarities is much more challenging. Therefore, a comprehensive understanding of contextual information w.r.t. the aspect and opinion are further required in ABSA. In this paper, we propose Deep Contextualized Relation-Aware Network (DCRAN), which allows interactive relations among subtasks with deep contextual information based on two modules (i.e., Aspect and Opinion Propagation and Explicit Self-Supervised Strategies). Especially, we design novel self-supervised strategies for ABSA, which have strengths in dealing with multiple aspects. Experimental results show that DCRAN significantly outperforms previous state-of-the-art methods by large margins on three widely used benchmarks.
Aspect-based sentiment analysis (ABSA) has received increasing attention recently. Most existing work tackles ABSA in a discriminative manner, designing various task-specific classification networks for the prediction. Despite their effectiveness, these methods ignore the rich label semantics in ABSA problems and require extensive task-specific designs. In this paper, we propose to tackle various ABSA tasks in a unified generative framework. Two types of paradigms, namely annotation-style and extraction-style modeling, are designed to enable the training process by formulating each ABSA task as a text generation problem. We conduct experiments on four ABSA tasks across multiple benchmark datasets where our proposed generative approach achieves new state-of-the-art results in almost all cases. This also validates the strong generality of the proposed framework which can be easily adapted to arbitrary ABSA task without additional task-specific model design.
Recently, token-level adaptive training has achieved promising improvement in machine translation, where the cross-entropy loss function is adjusted by assigning different training weights to different tokens, in order to alleviate the token imbalance problem. However, previous approaches only use static word frequency information in the target language without considering the source language, which is insufficient for bilingual tasks like machine translation. In this paper, we propose a novel bilingual mutual information (BMI) based adaptive objective, which measures the learning difficulty for each target token from the perspective of bilingualism, and assigns an adaptive weight accordingly to improve token-level adaptive training. This method assigns larger training weights to tokens with higher BMI, so that easy tokens are updated with coarse granularity while difficult tokens are updated with fine granularity. Experimental results on WMT14 English-to-German and WMT19 Chinese-to-English demonstrate the superiority of our approach compared with the Transformer baseline and previous token-level adaptive training approaches. Further analyses confirm that our method can improve the lexical diversity.
This ability to learn consecutive tasks without forgetting how to perform previously trained problems is essential for developing an online dialogue system. This paper proposes an effective continual learning method for the task-oriented dialogue system with iterative network pruning, expanding, and masking (TPEM), which preserves performance on previously encountered tasks while accelerating learning progress on subsequent tasks. Specifically, TPEM (i) leverages network pruning to keep the knowledge for old tasks, (ii) adopts network expanding to create free weights for new tasks, and (iii) introduces task-specific network masking to alleviate the negative impact of fixed weights of old tasks on new tasks. We conduct extensive experiments on seven different tasks from three benchmark datasets and show empirically that TPEM leads to significantly improved results over the strong competitors.
We present TIMERS - a TIME, Rhetorical and Syntactic-aware model for document-level temporal relation classification in the English language. Our proposed method leverages rhetorical discourse features and temporal arguments from semantic role labels, in addition to traditional local syntactic features, trained through a Gated Relational-GCN. Extensive experiments show that the proposed model outperforms previous methods by 5-18% on the TDDiscourse, TimeBank-Dense, and MATRES datasets due to our discourse-level modeling.
Arabic diacritization is a fundamental task for Arabic language processing. Previous studies have demonstrated that automatically generated knowledge can be helpful to this task. However, these studies regard the auto-generated knowledge instances as gold references, which limits their effectiveness since such knowledge is not always accurate and inferior instances can lead to incorrect predictions. In this paper, we propose to use regularized decoding and adversarial training to appropriately learn from such noisy knowledge for diacritization. Experimental results on two benchmark datasets show that, even with quite flawed auto-generated knowledge, our model can still learn adequate diacritics and outperform all previous studies, on both datasets.
Subword segmentation algorithms have been a de facto choice when building neural machine translation systems. However, most of them need to learn a segmentation model based on some heuristics, which may produce sub-optimal segmentation. This can be problematic in some scenarios when the target language has rich morphological changes or there is not enough data for learning compact composition rules. Translating at fully character level has the potential to alleviate the issue, but empirical performances of character-based models has not been fully explored. In this paper, we present an in-depth comparison between character-based and subword-based NMT systems under three settings: translating to typologically diverse languages, training with low resource, and adapting to unseen domains. Experiment results show strong competitiveness of character-based models. Further analyses show that compared to subword-based models, character-based models are better at handling morphological phenomena, generating rare and unknown words, and more suitable for transferring to unseen domains.
Chinese word segmentation (CWS) is undoubtedly an important basic task in natural language processing. Previous works only focus on the textual modality, but there are often audio and video utterances (such as news broadcast and face-to-face dialogues), where textual, acoustic and visual modalities normally exist. To this end, we attempt to combine the multi-modality (mainly the converted text and actual voice information) to perform CWS. In this paper, we annotate a new dataset for CWS containing text and audio. Moreover, we propose a time-dependent multi-modal interactive model based on Transformer framework to integrate multi-modal information for word sequence labeling. The experimental results on three different training sets show the effectiveness of our approach with fusing text and audio.
Discrimination between antonyms and synonyms is an important and challenging NLP task. Antonyms and synonyms often share the same or similar contexts and thus are hard to make a distinction. This paper proposes two underlying hypotheses and employs the mixture-of-experts framework as a solution. It works on the basis of a divide-and-conquer strategy, where a number of localized experts focus on their own domains (or subspaces) to learn their specialties, and a gating mechanism determines the space partitioning and the expert mixture. Experimental results have shown that our method achieves the state-of-the-art performance on the task.
Injecting external domain-specific knowledge (e.g., UMLS) into pretrained language models (LMs) advances their capability to handle specialised in-domain tasks such as biomedical entity linking (BEL). However, such abundant expert knowledge is available only for a handful of languages (e.g., English). In this work, by proposing a novel cross-lingual biomedical entity linking task (XL-BEL) and establishing a new XL-BEL benchmark spanning 10 typologically diverse languages, we first investigate the ability of standard knowledge-agnostic as well as knowledge-enhanced monolingual and multilingual LMs beyond the standard monolingual English BEL task. The scores indicate large gaps to English performance. We then address the challenge of transferring domain-specific knowledge in resource-rich languages to resource-poor ones. To this end, we propose and evaluate a series of cross-lingual transfer methods for the XL-BEL task, and demonstrate that general-domain bitext helps propagate the available English knowledge to languages with little to no in-domain data. Remarkably, we show that our proposed domain-specific transfer methods yield consistent gains across all target languages, sometimes up to 20 Precision@1 points, without any in-domain knowledge in the target language, and without any in-domain parallel data.
The representation degeneration problem in Contextual Word Representations (CWRs) hurts the expressiveness of the embedding space by forming an anisotropic cone where even unrelated words have excessively positive correlations. Existing techniques for tackling this issue require a learning process to re-train models with additional objectives and mostly employ a global assessment to study isotropy. Our quantitative analysis over isotropy shows that a local assessment could be more accurate due to the clustered structure of CWRs. Based on this observation, we propose a local cluster-based method to address the degeneration issue in contextual embedding spaces. We show that in clusters including punctuations and stop words, local dominant directions encode structural information, removing which can improve CWRs performance on semantic tasks. Moreover, we find that tense information in verb representations dominates sense semantics. We show that removing dominant directions of verb representations can transform the space to better suit semantic applications. Our experiments demonstrate that the proposed cluster-based method can mitigate the degeneration problem on multiple tasks.
Humans often refer to personal narratives, life experiences, and events to make a conversation more engaging and rich. While persona-grounded dialog models are able to generate responses that follow a given persona, they often miss out on stating detailed experiences or events related to a persona, often leaving conversations shallow and dull. In this work, we equip dialog models with ‘background stories’ related to a persona by leveraging fictional narratives from existing story datasets (e.g. ROCStories). Since current dialog datasets do not contain such narratives as responses, we perform an unsupervised adaptation of a retrieved story for generating a dialog response using a gradient-based rewriting technique. Our proposed method encourages the generated response to be fluent (i.e., highly likely) with the dialog history, minimally different from the retrieved story to preserve event ordering and consistent with the original persona. We demonstrate that our method can generate responses that are more diverse, and are rated more engaging and human-like by human evaluators, compared to outputs from existing dialog models.
The famous “laurel/yanny” phenomenon references an audio clip that elicits dramatically different responses from different listeners. For the original clip, roughly half the population hears the word “laurel,” while the other half hears “yanny.” How common are such “polyperceivable” audio clips? In this paper we apply ML techniques to study the prevalence of polyperceivability in spoken language. We devise a metric that correlates with polyperceivability of audio clips, use it to efficiently find new “laurel/yanny”-type examples, and validate these results with human experiments. Our results suggest that polyperceivable examples are surprisingly prevalent in natural language, existing for >2% of English words.
Event language models represent plausible sequences of events. Most existing approaches train autoregressive models on text, which successfully capture event co-occurrence but unfortunately constrain the model to follow the discourse order in which events are presented. Other domains may employ different discourse orders, and for many applications, we may care about different notions of ordering (e.g., temporal) or not care about ordering at all (e.g., when predicting related events in a schema). We propose a simple yet surprisingly effective strategy for improving event language models by perturbing event sequences so we can relax model dependence on text order. Despite generating completely synthetic event orderings, we show that this technique improves the performance of the event language models on both applications and out-of-domain events data.
Information Retrieval using dense low-dimensional representations recently became popular and showed out-performance to traditional sparse-representations like BM25. However, no previous work investigated how dense representations perform with large index sizes. We show theoretically and empirically that the performance for dense representations decreases quicker than sparse representations for increasing index sizes. In extreme cases, this can even lead to a tipping point where at a certain index size sparse representations outperform dense representations. We show that this behavior is tightly connected to the number of dimensions of the representations: The lower the dimension, the higher the chance for false positives, i.e. returning irrelevant documents
Cross-lingual text classification aims at training a classifier on the source language and transferring the knowledge to target languages, which is very useful for low-resource languages. Recent multilingual pretrained language models (mPLM) achieve impressive results in cross-lingual classification tasks, but rarely consider factors beyond semantic similarity, causing performance degradation between some language pairs. In this paper we propose a simple yet effective method to incorporate heterogeneous information within and across languages for cross-lingual text classification using graph convolutional networks (GCN). In particular, we construct a heterogeneous graph by treating documents and words as nodes, and linking nodes with different relations, which include part-of-speech roles, semantic similarity, and document translations. Extensive experiments show that our graph-based method significantly outperforms state-of-the-art models on all tasks, and also achieves consistent performance gain over baselines in low-resource settings where external tools like translators are unavailable.
Question answering (QA) in English has been widely explored, but multilingual datasets are relatively new, with several methods attempting to bridge the gap between high- and low-resourced languages using data augmentation through translation and cross-lingual transfer. In this project we take a step back and study which approaches allow us to take the most advantage of existing resources in order to produce QA systems in many languages. Specifically, we perform extensive analysis to measure the efficacy of few-shot approaches augmented with automatic translations and permutations of context-question-answer pairs. In addition, we make suggestions for future dataset development efforts that make better use of a fixed annotation budget, with a goal of increasing the language coverage of QA datasets and systems.
We propose an effective context-sensitive neural model for time to event (TTE) prediction task, which aims to predict the amount of time to/from the occurrence of given events in streaming content. We investigate this problem in the context of a multi-task learning framework, which we enrich with time difference embeddings. In addition, we develop a multi-genre dataset of English events about soccer competitions and academy awards ceremonies, and their relevant tweets obtained from Twitter. Our model is 1.4 and 3.3 hours more accurate than the current state-of-the-art model in estimating TTE on English and Dutch tweets respectively. We examine different aspects of our model to illustrate its source of improvement.
Compositional generalization is the ability to generalize systematically to a new data distribution by combining known components. Although humans seem to have a great ability to generalize compositionally, state-of-the-art neural models struggle to do so. In this work, we study compositional generalization in classification tasks and present two main contributions. First, we study ways to convert a natural language sequence-to-sequence dataset to a classification dataset that also requires compositional generalization. Second, we show that providing structural hints (specifically, providing parse trees and entity links as attention masks for a Transformer model) helps compositional generalization.
Pre-trained text-to-text transformers such as BART have achieved impressive performance across a range of NLP tasks. Recent study further shows that they can learn to generalize to novel tasks, by including task descriptions as part of the source sequence and training the model with (source, target) examples. At test time, these fine-tuned models can make inferences on new tasks using the new task descriptions as part of the input. However, this approach has potential limitations, as the model learns to solve individual (source, target) examples (i.e., at the instance level), instead of learning to solve tasks by taking all examples within a task as a whole (i.e., at the task level). To this end, we introduce Hypter, a framework that improves text-to-text transformer’s generalization ability to unseen tasks by training a hypernetwork to generate task-specific, light-weight adapters from task descriptions. Experiments on ZEST dataset and a synthetic SQuAD dataset demonstrate that Hypter improves upon fine-tuning baselines. Notably, when using BART-Large as the main network, Hypter brings 11.3% comparative improvement on ZEST dataset.
Slot-filling is an essential component for building task-oriented dialog systems. In this work, we focus on the zero-shot slot-filling problem, where the model needs to predict slots and their values, given utterances from new domains without training on the target domain. Prior methods directly encode slot descriptions to generalize to unseen slot types. However, raw slot descriptions are often ambiguous and do not encode enough semantic information, limiting the models’ zero-shot capability. To address this problem, we introduce QA-driven slot filling (QASF), which extracts slot-filler spans from utterances with a span-based QA model. We use a linguistically motivated questioning strategy to turn descriptions into questions, allowing the model to generalize to unseen slot types. Moreover, our QASF model can benefit from weak supervision signals from QA pairs synthetically generated from unlabeled conversations. Our full system substantially outperforms baselines by over 5% on the SNIPS benchmark.
Language models like BERT and SpanBERT pretrained on open-domain data have obtained impressive gains on various NLP tasks. In this paper, we probe the effectiveness of domain-adaptive pretraining objectives on downstream tasks. In particular, three objectives, including a novel objective focusing on modeling predicate-argument relations, are evaluated on two challenging dialogue understanding tasks. Experimental results demonstrate that domain-adaptive pretraining with proper objectives can significantly improve the performance of a strong baseline on these tasks, achieving the new state-of-the-art performances.
It has become a common pattern in our field: One group introduces a language task, exemplified by a dataset, which they argue is challenging enough to serve as a benchmark. They also provide a baseline model for it, which then soon is improved upon by other groups. Often, research efforts then move on, and the pattern repeats itself. What is typically left implicit is the argumentation for why this constitutes progress, and progress towards what. In this paper, we try to step back for a moment from this pattern and work out possible argumentations and their parts.
In this work, we introduce : the largest publicly available multilingual dataset for factual verification of naturally existing real-world claims. The dataset contains short statements in 25 languages and is labeled for veracity by expert fact-checkers. The dataset includes a multilingual evaluation benchmark that measures both out-of-domain generalization, and zero-shot capabilities of the multilingual models. Using state-of-the-art multilingual transformer-based models, we develop several automated fact-checking models that, along with textual claims, make use of additional metadata and evidence from news stories retrieved using a search engine. Empirically, our best model attains an F-score of around 40%, suggesting that our dataset is a challenging benchmark for the evaluation of multilingual fact-checking models.
Recently, mT5 - a massively multilingual version of T5 - leveraged a unified text-to-text format to attain state-of-the-art results on a wide variety of multilingual NLP tasks. In this paper, we investigate the impact of incorporating parallel data into mT5 pre-training. We find that multi-tasking language modeling with objectives such as machine translation during pre-training is a straightforward way to improve performance on downstream multilingual and cross-lingual tasks. However, the gains start to diminish as the model capacity increases, suggesting that parallel data might not be as essential for larger models. At the same time, even at larger model sizes, we find that pre-training with parallel data still provides benefits in the limited labelled data regime
Intelligent and adaptive online education systems aim to make high-quality education available for a diverse range of students. However, existing systems usually depend on a pool of hand-made questions, limiting how fine-grained and open-ended they can be in adapting to individual students. We explore targeted question generation as a controllable sequence generation task. We first show how to fine-tune pre-trained language models for deep knowledge tracing (LM-KT). This model accurately predicts the probability of a student answering a question correctly, and generalizes to questions not seen in training. We then use LM-KT to specify the objective and data for training a model to generate questions conditioned on the student and target difficulty. Our results show we succeed at generating novel, well-calibrated language translation questions for second language learners from a real online education platform.
This paper presents a simple recipe to trainstate-of-the-art multilingual Grammatical Error Correction (GEC) models. We achieve this by first proposing a language-agnostic method to generate a large number of synthetic examples. The second ingredient is to use large-scale multilingual language models (up to 11B parameters). Once fine-tuned on language-specific supervised sets we surpass the previous state-of-the-art results on GEC benchmarks in four languages: English, Czech, German and Russian. Having established a new set of baselines for GEC, we make our results easily reproducible and accessible by releasing a CLANG-8 dataset. It is produced by using our best model, which we call gT5, to clean the targets of a widely used yet noisy Lang-8 dataset. cLang-8 greatly simplifies typical GEC training pipelines composed of multiple fine-tuning stages – we demonstrate that performing a single fine-tuning stepon cLang-8 with the off-the-shelf language models yields further accuracy improvements over an already top-performing gT5 model for English.
Pathology imaging is broadly used for identifying the causes and effects of diseases or injuries. Given a pathology image, being able to answer questions about the clinical findings contained in the image is very important for medical decision making. In this paper, we aim to develop a pathological visual question answering framework to analyze pathology images and answer medical questions related to these images. To build such a framework, we create PathVQA, a VQA dataset with 32,795 questions asked from 4,998 pathology images. We also propose a three-level optimization framework which performs self-supervised pretraining and VQA finetuning end-to-end to learn powerful visual and textual representations jointly and automatically identifies and excludes noisy self-supervised examples from pretraining. We perform experiments on our created PathVQA dataset and the results demonstrate the effectiveness of our proposed methods. The datasets and code are available at https://github.com/UCSD-AI4H/PathVQA
Text-based games (TBGs) have emerged as useful benchmarks for evaluating progress at the intersection of grounded language understanding and reinforcement learning (RL). Recent work has proposed the use of external knowledge to improve the efficiency of RL agents for TBGs. In this paper, we posit that to act efficiently in TBGs, an agent must be able to track the state of the game while retrieving and using relevant commonsense knowledge. Thus, we propose an agent for TBGs that induces a graph representation of the game state and jointly grounds it with a graph of commonsense knowledge from ConceptNet. This combination is achieved through bidirectional knowledge graph attention between the two symbolic representations. We show that agents that incorporate commonsense into the game state graph outperform baseline agents.
We introduce mTVR, a large-scale multilingual video moment retrieval dataset, containing 218K English and Chinese queries from 21.8K TV show video clips. The dataset is collected by extending the popular TVR dataset (in English) with paired Chinese queries and subtitles. Compared to existing moment retrieval datasets, mTVR is multilingual, larger, and comes with diverse annotations. We further propose mXML, a multilingual moment retrieval model that learns and operates on data from both languages, via encoder parameter sharing and language neighborhood constraints. We demonstrate the effectiveness of mXML on the newly collected mTVR dataset, where mXML outperforms strong monolingual baselines while using fewer parameters. In addition, we also provide detailed dataset analyses and model ablations. Data and code are publicly available at https://github.com/jayleicn/mTVRetrieval
Named entity recognition (NER) is well studied for the general domain, and recent systems have achieved human-level performance for identifying common entity types. However, the NER performance is still moderate for specialized domains that tend to feature complicated contexts and jargonistic entity types. To address these challenges, we propose explicitly connecting entity mentions based on both global coreference relations and local dependency relations for building better entity mention representations. In our experiments, we incorporate entity mention relations by Graph Neural Networks and show that our system noticeably improves the NER performance on two datasets from different domains. We further show that the proposed lightweight system can effectively elevate the NER performance to a higher level even when only a tiny amount of labeled data is available, which is desirable for domain-specific NER.
Accurate terminology translation is crucial for ensuring the practicality and reliability of neural machine translation (NMT) systems. To address this, lexically constrained NMT explores various methods to ensure pre-specified words and phrases appear in the translation output. However, in many cases, those methods are studied on general domain corpora, where the terms are mostly uni- and bi-grams (>98%). In this paper, we instead tackle a more challenging setup consisting of domain-specific corpora with much longer n-gram and highly specialized terms. Inspired by the recent success of masked span prediction models, we propose a simple and effective training strategy that achieves consistent improvements on both terminology and sentence-level translation for three domain-specific corpora in two language pairs.
To help individuals express themselves better, quotation recommendation is receiving growing attention. Nevertheless, most prior efforts focus on modeling quotations and queries separately and ignore the relationship between the quotations and the queries. In this work, we introduce a transformation matrix that directly maps the query representations to quotation representations. To better learn the mapping relationship, we employ a mapping loss that minimizes the distance of two semantic spaces (one for quotation and another for mapped-query). Furthermore, we explore using the words in history queries to interpret the figurative language of quotations, where quotation-aware attention is applied on top of history queries to highlight the indicator words. Experiments on two datasets in English and Chinese show that our model outperforms previous state-of-the-art models.
Topic models extract groups of words from documents, whose interpretation as a topic hopefully allows for a better understanding of the data. However, the resulting word groups are often not coherent, making them harder to interpret. Recently, neural topic models have shown improvements in overall coherence. Concurrently, contextual embeddings have advanced the state of the art of neural models in general. In this paper, we combine contextualized representations with neural topic models. We find that our approach produces more meaningful and coherent topics than traditional bag-of-words topic models and recent neural models. Our results indicate that future improvements in language models will translate into better topic models.
Neural semantic parsers have obtained acceptable results in the context of parsing DRSs (Discourse Representation Structures). In particular models with character sequences as input showed remarkable performance for English. But how does this approach perform on languages with a different writing system, like Chinese, a language with a large vocabulary of characters? Does rule-based tokenisation of the input help, and which granularity is preferred: characters, or words? The results are promising. Even with DRSs based on English, good results for Chinese are obtained. Tokenisation offers a small advantage for English, but not for Chinese. Overall, characters are preferred as input, both for English and Chinese.
Training datasets for semantic parsing are typically small due to the higher expertise required for annotation than most other NLP tasks. As a result, models for this application usually need additional prior knowledge to be built into the architecture or algorithm. The increased dependency on human experts hinders automation and raises the development and maintenance costs in practice. This work investigates whether a generic transformer-based seq2seq model can achieve competitive performance with minimal code-generation-specific inductive bias design. By exploiting a relatively sizeable monolingual corpus of the target programming language, which is cheap to mine from the web, we achieved 81.03% exact match accuracy on Django and 32.57 BLEU score on CoNaLa. Both are SOTA to the best of our knowledge. This positive evidence highlights a potentially easier path toward building accurate semantic parsers in practice.
The general format of natural language inference (NLI) makes it tempting to be used for zero-shot text classification by casting any target label into a sentence of hypothesis and verifying whether or not it could be entailed by the input, aiming at generic classification applicable on any specified label space. In this opinion piece, we point out a few overlooked issues that are yet to be discussed in this line of work. We observe huge variance across different classification datasets amongst standard BERT-based NLI models and surprisingly find that pre-trained BERT without any fine-tuning can yield competitive performance against BERT fine-tuned for NLI. With the concern that these models heavily rely on spurious lexical patterns for prediction, we also experiment with preliminary approaches for more robust NLI, but the results are in general negative. Our observations reveal implicit but challenging difficulties in entailment-based zero-shot text classification.
Commonsense reasoning aims to incorporate sets of commonsense facts, retrieved from Commonsense Knowledge Graphs (CKG), to draw conclusion about ordinary situations. The dynamic nature of commonsense knowledge postulates models capable of performing multi-hop reasoning over new situations. This feature also results in having large-scale sparse Knowledge Graphs, where such reasoning process is needed to predict relations between new events. However, existing approaches in this area are limited by considering CKGs as a limited set of facts, thus rendering them unfit for reasoning over new unseen situations and events. In this paper, we present a neural-symbolic reasoner, which is capable of reasoning over large-scale dynamic CKGs. The logic rules for reasoning over CKGs are learned during training by our model. In addition to providing interpretable explanation, the learned logic rules help to generalise prediction to newly introduced events. Experimental results on the task of link prediction on CKGs prove the effectiveness of our model by outperforming the state-of-the-art models.
According to the self-determination theory, the levels of satisfaction of three basic needs (competence, autonomy and relatedness) have implications on people’s everyday life and career. We benchmark the novel task of automatically detecting those needs on short posts in English, by modelling it as a ternary classification task, and as three binary classification tasks. A detailed manual analysis shows that the latter has advantages in the real-world scenario, and that our best models achieve similar performances as a trained human annotator.
Recent studies on semantic frame induction show that relatively high performance has been achieved by using clustering-based methods with contextualized word embeddings. However, there are two potential drawbacks to these methods: one is that they focus too much on the superficial information of the frame-evoking verb and the other is that they tend to divide the instances of the same verb into too many different frame clusters. To overcome these drawbacks, we propose a semantic frame induction method using masked word embeddings and two-step clustering. Through experiments on the English FrameNet data, we demonstrate that using the masked word embeddings is effective for avoiding too much reliance on the surface information of frame-evoking verbs and that two-step clustering can improve the number of resulting frame clusters for the instances of the same verb.
Adapter modules were recently introduced as an efficient alternative to fine-tuning in NLP. Adapter tuning consists in freezing pre-trained parameters of a model and injecting lightweight modules between layers, resulting in the addition of only a small number of task-specific trainable parameters. While adapter tuning was investigated for multilingual neural machine translation, this paper proposes a comprehensive analysis of adapters for multilingual speech translation (ST). Starting from different pre-trained models (a multilingual ST trained on parallel data or a multilingual BART (mBART) trained on non parallel multilingual data), we show that adapters can be used to: (a) efficiently specialize ST to specific language pairs with a low extra cost in terms of parameters, and (b) transfer from an automatic speech recognition (ASR) task and an mBART pre-trained model to a multilingual ST task. Experiments show that adapter tuning offer competitive results to full fine-tuning, while being much more parameter-efficient.
The importance of parameter selection in supervised learning is well known. However, due to the many parameter combinations, an incomplete or an insufficient procedure is often applied. This situation may cause misleading or confusing conclusions. In this opinion paper, through an intriguing example we point out that the seriousness goes beyond what is generally recognized. In the topic of multilabel classification for medical code prediction, one influential paper conducted a proper parameter selection on a set, but when moving to a subset of frequently occurring labels, the authors used the same parameters without a separate tuning. The set of frequent labels became a popular benchmark in subsequent studies, which kept pushing the state of the art. However, we discovered that most of the results in these studies cannot surpass the approach in the original paper if a parameter tuning had been conducted at the time. Thus it is unclear how much progress the subsequent developments have actually brought. The lesson clearly indicates that without enough attention on parameter selection, the research progress in our field can be uncertain or even illusive.
Few-shot text classification aims to classify inputs whose label has only a few examples. Previous studies overlooked the semantic relevance between label representations. Therefore, they are easily confused by labels that are relevant. To address this problem, we propose a method that generates distinct label representations that embed information specific to each label. Our method is applicable to conventional few-shot classification models. Experimental results show that our method significantly improved the performance of few-shot text classification across models and datasets.
In real scenarios, a multilingual model trained to solve NLP tasks on a set of languages can be required to support new languages over time. Unfortunately, the straightforward retraining on a dataset containing annotated examples for all the languages is both expensive and time-consuming, especially when the number of target languages grows. Moreover, the original annotated material may no longer be available due to storage or business constraints. Re-training only with the new language data will inevitably result in Catastrophic Forgetting of previously acquired knowledge. We propose a Continual Learning strategy that updates a model to support new languages over time, while maintaining consistent results on previously learned languages. We define a Teacher-Student framework where the existing model “teaches” to a student model its knowledge about the languages it supports, while the student is also trained on a new language. We report an experimental evaluation in several tasks including Sentence Classification, Relational Learning and Sequence Labeling.
Transformer is important for text modeling. However, it has difficulty in handling long documents due to the quadratic complexity with input text length. In order to handle this problem, we propose a hierarchical interactive Transformer (Hi-Transformer) for efficient and effective long document modeling. Hi-Transformer models documents in a hierarchical way, i.e., first learns sentence representations and then learns document representations. It can effectively reduce the complexity and meanwhile capture global document context in the modeling of each sentence. More specifically, we first use a sentence Transformer to learn the representations of each sentence. Then we use a document Transformer to model the global document context from these sentence representations. Next, we use another sentence Transformer to enhance sentence modeling using the global document context. Finally, we use hierarchical pooling method to obtain document embedding. Extensive experiments on three benchmark datasets validate the efficiency and effectiveness of Hi-Transformer in long document modeling.
Transfer learning with large pretrained transformer-based language models like BERT has become a dominating approach for most NLP tasks. Simply fine-tuning those large language models on downstream tasks or combining it with task-specific pretraining is often not robust. In particular, the performance considerably varies as the random seed changes or the number of pretraining and/or fine-tuning iterations varies, and the fine-tuned model is vulnerable to adversarial attack. We propose a simple yet effective adapter-based approach to mitigate these issues. Specifically, we insert small bottleneck layers (i.e., adapter) within each layer of a pretrained model, then fix the pretrained layers and train the adapter layers on the downstream task data, with (1) task-specific unsupervised pretraining and then (2) task-specific supervised training (e.g., classification, sequence labeling). Our experiments demonstrate that such a training scheme leads to improved stability and adversarial robustness in transfer learning to various downstream tasks.
Natural Language Inference (NLI) datasets contain examples with highly ambiguous labels. While many research works do not pay much attention to this fact, several recent efforts have been made to acknowledge and embrace the existence of ambiguity, such as UNLI and ChaosNLI. In this paper, we explore the option of training directly on the estimated label distribution of the annotators in the NLI task, using a learning loss based on this ambiguity distribution instead of the gold-labels. We prepare AmbiNLI, a trial dataset obtained from readily available sources, and show it is possible to reduce ChaosNLI divergence scores when finetuning on this data, a promising first step towards learning how to capture linguistic ambiguity. Additionally, we show that training on the same amount of data but targeting the ambiguity distribution instead of gold-labels can result in models that achieve higher performance and learn better representations for downstream tasks.
Detecting Out-of-Domain (OOD) or unknown intents from user queries is essential in a task-oriented dialog system. A key challenge of OOD detection is to learn discriminative semantic features. Traditional cross-entropy loss only focuses on whether a sample is correctly classified, and does not explicitly distinguish the margins between categories. In this paper, we propose a supervised contrastive learning objective to minimize intra-class variance by pulling together in-domain intents belonging to the same class and maximize inter-class variance by pushing apart samples from different classes. Besides, we employ an adversarial augmentation mechanism to obtain pseudo diverse views of a sample in the latent space. Experiments on two public datasets prove the effectiveness of our method capturing discriminative representations for OOD detection.
Existing dialog state tracking (DST) models are trained with dialog data in a random order, neglecting rich structural information in a dataset. In this paper, we propose to use curriculum learning (CL) to better leverage both the curriculum structure and schema structure for task-oriented dialogs. Specifically, we propose a model-agnostic framework called Schema-aware Curriculum Learning for Dialog State Tracking (SaCLog), which consists of a preview module that pre-trains a DST model with schema information, a curriculum module that optimizes the model with CL, and a review module that augments mispredicted data to reinforce the CL training. We show that our proposed approach improves DST performance over both a transformer-based and RNN-based DST model (TripPy and TRADE) and achieves new state-of-the-art results on WOZ2.0 and MultiWOZ2.1.
Under the pandemic of COVID-19, people experiencing COVID19-related symptoms have a pressing need to consult doctors. Because of the shortage of medical professionals, many people cannot receive online consultations timely. To address this problem, we aim to develop a medical dialog system that can provide COVID19-related consultations. We collected two dialog datasets – CovidDialog – (in English and Chinese respectively) containing conversations between doctors and patients about COVID-19. While the largest of their kind, these two datasets are still relatively small compared with general-domain dialog datasets. Training complex dialog generation models on small datasets bears high risk of overfitting. To alleviate overfitting, we develop a multi-task learning approach, which regularizes the data-deficient dialog generation task with a masked token prediction task. Experiments on the CovidDialog datasets demonstrate the effectiveness of our approach. We perform both human evaluation and automatic evaluation of dialogs generated by our method. Results show that the generated responses are promising in being doctor-like, relevant to conversation history, clinically informative and correct. The code and the data are available at https://github.com/UCSD-AI4H/COVID-Dialogue.
In multi-modal dialogue systems, it is important to allow the use of images as part of a multi-turn conversation. Training such dialogue systems generally requires a large-scale dataset consisting of multi-turn dialogues that involve images, but such datasets rarely exist. In response, this paper proposes a 45k multi-modal dialogue dataset created with minimal human intervention. Our method to create such a dataset consists of (1) preparing and pre-processing text dialogue datasets, (2) creating image-mixed dialogues by using a text-to-image replacement technique, and (3) employing a contextual-similarity-based filtering step to ensure the contextual coherence of the dataset. To evaluate the validity of our dataset, we devise a simple retrieval model for dialogue sentence prediction tasks. Automatic metrics and human evaluation results on such tasks show that our dataset can be effectively used as training data for multi-modal dialogue systems which require an understanding of images and text in a context-aware manner. Our dataset and generation code is available at https://github.com/shh1574/multi-modal-dialogue-dataset.
Reducing and counter-acting hate speech on Social Media is a significant concern. Most of the proposed automatic methods are conducted exclusively on English and very few consistently labeled, non-English resources have been proposed. Learning to detect hate speech on English and transferring to unseen languages seems an immediate solution. This work is the first to shed light on the limits of this zero-shot, cross-lingual transfer learning framework for hate speech detection. We use benchmark data sets in English, Italian, and Spanish to detect hate speech towards immigrants and women. Investigating post-hoc explanations of the model, we discover that non-hateful, language-specific taboo interjections are misinterpreted as signals of hate speech. Our findings demonstrate that zero-shot, cross-lingual models cannot be used as they are, but need to be carefully designed.
Neural machine translation models are often biased toward the limited translation references seen during training. To amend this form of overfitting, in this paper we propose fine-tuning the models with a novel training objective based on the recently-proposed BERTScore evaluation metric. BERTScore is a scoring function based on contextual embeddings that overcomes the typical limitations of n-gram-based metrics (e.g. synonyms, paraphrases), allowing translations that are different from the references, yet close in the contextual embedding space, to be treated as substantially correct. To be able to use BERTScore as a training objective, we propose three approaches for generating soft predictions, allowing the network to remain completely differentiable end-to-end. Experiments carried out over four, diverse language pairs show improvements of up to 0.58 pp (3.28%) in BLEU score and up to 0.76 pp (0.98%) in BERTScore (F_BERT) when fine-tuning a strong baseline.
Implicit discourse relation classification is a challenging task, in particular when the text domain is different from the standard Penn Discourse Treebank (PDTB; Prasad et al., 2008) training corpus domain (Wall Street Journal in 1990s). We here tackle the task of implicit discourse relation classification on the biomedical domain, for which the Biomedical Discourse Relation Bank (BioDRB; Prasad et al., 2011) is available. We show that entity information can be used to improve discourse relational argument representation. In a first step, we show that explicitly marked instances that are content-wise similar to the target relations can be used to achieve good performance in the cross-domain setting using a simple unsupervised voting pipeline. As a further step, we show that with the linked entity information from the first step, a transformer which is augmented with entity-related information (KBERT; Liu et al., 2020) sets the new state of the art performance on the dataset, outperforming the large pre-trained BioBERT (Lee et al., 2020) model by 2% points.
In this work, we propose Masked Noun-Phrase Prediction (MNPP), a pre-training strategy to tackle pronoun resolution in a fully unsupervised setting. Firstly, We evaluate our pre-trained model on various pronoun resolution datasets without any finetuning. Our method outperforms all previous unsupervised methods on all datasets by large margins. Secondly, we proceed to a few-shot setting where we finetune our pre-trained model on WinoGrande-S and XS separately. Our method outperforms RoBERTa-large baseline with large margins, meanwhile, achieving a higher AUC score after further finetuning on the remaining three official splits of WinoGrande.
Recently, question answering (QA) based on machine reading comprehension has become popular. This work focuses on generative QA which aims to generate an abstractive answer to a given question instead of extracting an answer span from a provided passage. Generative QA often suffers from two critical problems: (1) summarizing content irrelevant to a given question, (2) drifting away from a correct answer during generation. In this paper, we address these problems by a novel Rationale-Enriched Answer Generator (REAG), which incorporates an extractive mechanism into a generative model. Specifically, we add an extraction task on the encoder to obtain the rationale for an answer, which is the most relevant piece of text in an input document to a given question. Based on the extracted rationale and original input, the decoder is expected to generate an answer with high confidence. We jointly train REAG on the MS MARCO QA+NLG task and the experimental results show that REAG improves the quality and semantic accuracy of answers over baseline models.
In news articles the lead bias is a common phenomenon that usually dominates the learning signals for neural extractive summarizers, severely limiting their performance on data with different or even no bias. In this paper, we introduce a novel technique to demote lead bias and make the summarizer focus more on the content semantics. Experiments on two news corpora with different degrees of lead bias show that our method can effectively demote the model’s learned lead bias and improve its generality on out-of-distribution data, with little to no performance loss on in-distribution data.
Machine reading comprehension (MRC) is a crucial task in natural language processing and has achieved remarkable advancements. However, most of the neural MRC models are still far from robust and fail to generalize well in real-world applications. In order to comprehensively verify the robustness and generalization of MRC models, we introduce a real-world Chinese dataset – DuReader_robust . It is designed to evaluate the MRC models from three aspects: over-sensitivity, over-stability and generalization. Comparing to previous work, the instances in DuReader_robust are natural texts, rather than the altered unnatural texts. It presents the challenges when applying MRC models to real-world applications. The experimental results show that MRC models do not perform well on the challenge test set. Moreover, we analyze the behavior of existing models on the challenge test set, which may provide suggestions for future model development. The dataset and codes are publicly available at https://github.com/baidu/DuReader.
With the recent advancements in deep learning, neural solvers have gained promising results in solving math word problems. However, these SOTA solvers only generate binary expression trees that contain basic arithmetic operators and do not explicitly use the math formulas. As a result, the expression trees they produce are lengthy and uninterpretable because they need to use multiple operators and constants to represent one single formula. In this paper, we propose sequence-to-general tree (S2G) that learns to generate interpretable and executable operation trees where the nodes can be formulas with an arbitrary number of arguments. With nodes now allowed to be formulas, S2G can learn to incorporate mathematical domain knowledge into problem-solving, making the results more interpretable. Experiments show that S2G can achieve a better performance against strong baselines on problems that require domain knowledge.
Understanding the multi-scale visual information in a video is essential for Video Question Answering (VideoQA). Therefore, we propose a novel Multi-Scale Progressive Attention Network (MSPAN) to achieve relational reasoning between cross-scale video information. We construct clips of different lengths to represent different scales of the video. Then, the clip-level features are aggregated into node features by using max-pool, and a graph is generated for each scale of clips. For cross-scale feature interaction, we design a message passing strategy between adjacent scale graphs, i.e., top-down scale interaction and bottom-up scale interaction. Under the question’s guidance of progressive attention, we realize the fusion of all-scale video features. Experimental evaluations on three benchmarks: TGIF-QA, MSVD-QA and MSRVTT-QA show our method has achieved state-of-the-art performance.
Most state-of-the-art open-domain question answering systems use a neural retrieval model to encode passages into continuous vectors and extract them from a knowledge source. However, such retrieval models often require large memory to run because of the massive size of their passage index. In this paper, we introduce Binary Passage Retriever (BPR), a memory-efficient neural retrieval model that integrates a learning-to-hash technique into the state-of-the-art Dense Passage Retriever (DPR) to represent the passage index using compact binary codes rather than continuous vectors. BPR is trained with a multi-task objective over two tasks: efficient candidate generation based on binary codes and accurate reranking based on continuous vectors. Compared with DPR, BPR substantially reduces the memory cost from 65GB to 2GB without a loss of accuracy on two standard open-domain question answering benchmarks: Natural Questions and TriviaQA. Our code and trained models are available at https://github.com/studio-ousia/bpr.
Few-shot relation extraction (FSRE) is of great importance in long-tail distribution problem, especially in special domain with low-resource data. Most existing FSRE algorithms fail to accurately classify the relations merely based on the information of the sentences together with the recognized entity pairs, due to limited samples and lack of knowledge. To address this problem, in this paper, we proposed a novel entity CONCEPT-enhanced FEw-shot Relation Extraction scheme (ConceptFERE), which introduces the inherent concepts of entities to provide clues for relation prediction and boost the relations classification performance. Firstly, a concept-sentence attention module is developed to select the most appropriate concept from multiple concepts of each entity by calculating the semantic similarity between sentences and concepts. Secondly, a self-attention based fusion module is presented to bridge the gap of concept embedding and sentence embedding from different semantic spaces. Extensive experiments on the FSRE benchmark dataset FewRel have demonstrated the effectiveness and the superiority of the proposed ConceptFERE scheme as compared to the state-of-the-art baselines. Code is available at https://github.com/LittleGuoKe/ConceptFERE.
Generalization is an important ability that helps to ensure that a machine learning model can perform well on unseen data. In this paper, we study the effect of data bias on model generalization, using Chinese Named Entity Recognition (NER) as a case study. Specifically, we analyzed five benchmarking datasets for Chinese NER, and observed the following two types of data bias that can compromise model generalization ability. Firstly, the test sets of all the five datasets contain a significant proportion of entities that have been seen in the training sets. Such test data would therefore not be able to reflect the true generalization ability of a model. Secondly, all datasets are dominated by a few fat-head entities, i.e., entities appearing with particularly high frequency. As a result, a model might be able to produce high prediction accuracy simply by keyword memorization without leveraging context knowledge. To address these data biases, we first refine each test set by excluding seen entities from it, so as to better evaluate a model’s generalization ability. Then, we propose a simple yet effective entity resampling method to make entities within the same category distributed equally, encouraging a model to leverage both name and context knowledge in the training process. Experimental results demonstrate that the proposed entity resampling method significantly improves a model’s ability in detecting unseen entities, especially for company, organization and position categories.
Document-level Relation Extraction (RE) is a more challenging task than sentence RE as it often requires reasoning over multiple sentences. Yet, human annotators usually use a small number of sentences to identify the relationship between a given entity pair. In this paper, we present an embarrassingly simple but effective method to heuristically select evidence sentences for document-level RE, which can be easily combined with BiLSTM to achieve good performance on benchmark datasets, even better than fancy graph neural network based methods. We have released our code at https://github.com/AndrewZhe/Three-Sentences-Are-All-You-Need.
Learning prerequisite chains is an important task for one to pick up knowledge efficiently in both known and unknown domains. For example, one may be an expert in the natural language processing (NLP) domain, but want to determine the best order in which to learn new concepts in an unfamiliar Computer Vision domain (CV). Both domains share some common concepts, such as machine learning basics and deep learning models. In this paper, we solve the task of unsupervised cross-domain concept prerequisite chain learning, using an optimized variational graph autoencoder. Our model learns to transfer concept prerequisite relations from an information-rich domain (source domain) to an information-poor domain (target domain), substantially surpassing other baseline models. In addition, we expand an existing dataset by introducing two new domains—-CV and Bioinformatics (BIO). The annotated data and resources as well as the code will be made publicly available.
We present a text representation approach that can combine different views (representations) of the same input through effective data fusion and attention strategies for ranking purposes. We apply our model to the problem of differential diagnosis, which aims to find the most probable diseases that match with clinical descriptions of patients, using data from the Undiagnosed Diseases Network. Our model outperforms several ranking approaches (including a commercially-supported system) by effectively prioritizing and combining representations obtained from traditional and recent text representation techniques. We elaborate on several aspects of our model and shed light on its improved performance.
Crowdworker-constructed natural language inference (NLI) datasets have been found to contain statistical artifacts associated with the annotation process that allow hypothesis-only classifiers to achieve better-than-random performance (CITATION). We investigate whether MedNLI, a physician-annotated dataset with premises extracted from clinical notes, contains such artifacts (CITATION). We find that entailed hypotheses contain generic versions of specific concepts in the premise, as well as modifiers related to responsiveness, duration, and probability. Neutral hypotheses feature conditions and behaviors that co-occur with, or cause, the condition(s) in the premise. Contradiction hypotheses feature explicit negation of the premise and implicit negation via assertion of good health. Adversarial filtering demonstrates that performance degrades when evaluated on the difficult subset. We provide partition information and recommendations for alternative dataset construction strategies for knowledge-intensive domains.
With the explosion of chatbot applications, Conversational Question Answering (CQA) has generated a lot of interest in recent years. Among proposals, reading comprehension models which take advantage of the conversation history (previous QA) seem to answer better than those which only consider the current question. Nevertheless, we note that the CQA evaluation protocol has a major limitation. In particular, models are allowed, at each turn of the conversation, to access the ground truth answers of the previous turns. Not only does this severely prevent their applications in fully autonomous chatbots, it also leads to unsuspected biases in their behavior. In this paper, we highlight this effect and propose new tools for evaluation and training in order to guard against the noted issues. The new results that we bring come to reinforce methods of the current state of the art.
Existing models on Machine Reading Comprehension (MRC) require complex model architecture for effectively modeling long texts with paragraph representation and classification, thereby making inference computationally inefficient for production use. In this work, we propose VAULT: a light-weight and parallel-efficient paragraph representation for MRC based on contextualized representation from long document input, trained using a new Gaussian distribution-based objective that pays close attention to the partially correct instances that are close to the ground-truth. We validate our VAULT architecture showing experimental results on two benchmark MRC datasets that require long context modeling; one Wikipedia-based (Natural Questions (NQ)) and the other on TechNotes (TechQA). VAULT can achieve comparable performance on NQ with a state-of-the-art (SOTA) complex document modeling approach while being 16 times faster, demonstrating the efficiency of our proposed model. We also demonstrate that our model can also be effectively adapted to a completely different domain – TechQA – with large improvement over a model fine-tuned on a previously published large PLM.
Leveraging additional unlabeled data to boost model performance is common practice in machine learning and natural language processing. For generation tasks, if there is overlap between the additional data and the target text evaluation data, then training on the additional data is training on answers of the test set. This leads to overly-inflated scores with the additional data compared to real-world testing scenarios and problems when comparing models. We study the AMR dataset and Gigaword, which is popularly used for improving AMR-to-text generators, and find significant overlap between Gigaword and a subset of the AMR dataset. We propose methods for excluding parts of Gigaword to remove this overlap, and show that our approach leads to a more realistic evaluation of the task of AMR-to-text generation. Going forward, we give simple best-practice recommendations for leveraging additional data in AMR-to-text generation.
Social media has become a valuable resource for the study of suicidal ideation and the assessment of suicide risk. Among social media platforms, Reddit has emerged as the most promising one due to its anonymity and its focus on topic-based communities (subreddits) that can be indicative of someone’s state of mind or interest regarding mental health disorders such as r/SuicideWatch, r/Anxiety, r/depression. A challenge for previous work on suicide risk assessment has been the small amount of labeled data. We propose an empirical investigation into several classes of weakly-supervised approaches, and show that using pseudo-labeling based on related issues around mental health (e.g., anxiety, depression) helps improve model performance for suicide risk assessment.
The Shuffle Test is the most common task to evaluate whether NLP models can measure coherence in text. Most recent work uses direct supervision on the task; we show that by simply finetuning a RoBERTa model, we can achieve a near perfect accuracy of 97.8%, a state-of-the-art. We argue that this outstanding performance is unlikely to lead to a good model of text coherence, and suggest that the Shuffle Test should be approached in a Zero-Shot setting: models should be evaluated without being trained on the task itself. We evaluate common models in this setting, such as Generative and Bi-directional Transformers, and find that larger architectures achieve high-performance out-of-the-box. Finally, we suggest the k-Block Shuffle Test, a modification of the original by increasing the size of blocks shuffled. Even though human reader performance remains high (around 95% accuracy), model performance drops from 94% to 78% as block size increases, creating a conceptually simple challenge to benchmark NLP models.
In this paper, we present a conceptually simple while empirically powerful framework for abstractive summarization, SimCLS, which can bridge the gap between the learning objective and evaluation metrics resulting from the currently dominated sequence-to-sequence learning framework by formulating text generation as a reference-free evaluation problem (i.e., quality estimation) assisted by contrastive learning. Experimental results show that, with minor modification over existing top-scoring systems, SimCLS can improve the performance of existing top-performing models by a large margin. Particularly, 2.51 absolute improvement against BART and 2.50 over PEGASUS w.r.t ROUGE-1 on the CNN/DailyMail dataset, driving the state-of-the-art performance to a new level. We have open-sourced our codes and results: https://github.com/yixinL7/SimCLS. Results of our proposed models have been deployed into ExplainaBoard platform, which allows researchers to understand our systems in a more fine-grained way.
In this work, we introduce a corpus for satire detection in Romanian news. We gathered 55,608 public news articles from multiple real and satirical news sources, composing one of the largest corpora for satire detection regardless of language and the only one for the Romanian language. We provide an official split of the text samples, such that training news articles belong to different sources than test news articles, thus ensuring that models do not achieve high performance simply due to overfitting. We conduct experiments with two state-of-the-art deep neural models, resulting in a set of strong baselines for our novel corpus. Our results show that the machine-level accuracy for satire detection in Romanian is quite low (under 73% on the test set) compared to the human-level accuracy (87%), leaving enough room for improvement in future research.
Faceted summarization provides briefings of a document from different perspectives. Readers can quickly comprehend the main points of a long document with the help of a structured outline. However, little research has been conducted on this subject, partially due to the lack of large-scale faceted summarization datasets. In this study, we present FacetSum, a faceted summarization benchmark built on Emerald journal articles, covering a diverse range of domains. Different from traditional document-summary pairs, FacetSum provides multiple summaries, each targeted at specific sections of a long document, including the purpose, method, findings, and value. Analyses and empirical results on our dataset reveal the importance of bringing structure into summaries. We believe FacetSum will spur further advances in summarization research and foster the development of NLP systems that can leverage the structured information in both long texts and summaries.
Søgaard (2020) obtained results suggesting the fraction of trees occurring in the test data isomorphic to trees in the training set accounts for a non-trivial variation in parser performance. Similar to other statistical analyses in NLP, the results were based on evaluating linear regressions. However, the study had methodological issues and was undertaken using a small sample size leading to unreliable results. We present a replication study in which we also bin sentences by length and find that only a small subset of sentences vary in performance with respect to graph isomorphism. Further, the correlation observed between parser performance and graph isomorphism in the wild disappears when controlling for covariants. However, in a controlled experiment, where covariants are kept fixed, we do observe a correlation. We suggest that conclusions drawn from statistical analyses like this need to be tempered and that controlled experiments can complement them by more readily teasing factors apart.
High-performing machine translation (MT) systems can help overcome language barriers while making it possible for everyone to communicate and use language technologies in the language of their choice. However, such systems require large amounts of parallel sentences for training, and translators can be difficult to find and expensive. Here, we present a data collection strategy for MT which, in contrast, is cheap and simple, as it does not require bilingual speakers. Based on the insight that humans pay specific attention to movements, we use graphics interchange formats (GIFs) as a pivot to collect parallel sentences from monolingual annotators. We use our strategy to collect data in Hindi, Tamil and English. As a baseline, we also collect data using images as a pivot. We perform an intrinsic evaluation by manually evaluating a subset of the sentence pairs and an extrinsic evaluation by finetuning mBART (Liu et al., 2020) on the collected data. We find that sentences collected via GIFs are indeed of higher quality.
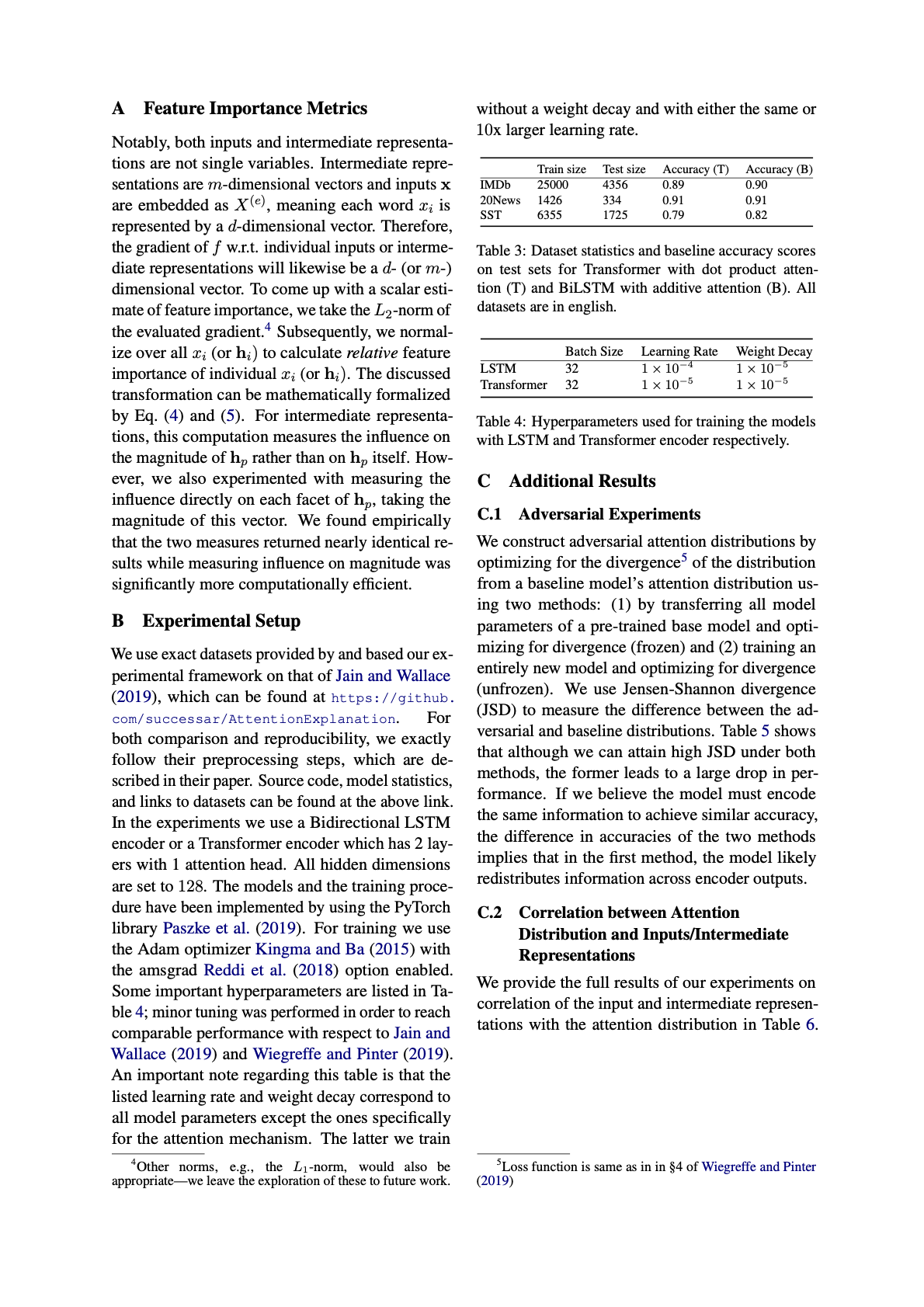{kind=link}